一、系统的瓶颈
压测的目的就是跑垮系统,达到系统承受最大值。本次压测考虑的方面:
1、CPU利用率、磁盘IO利用率
2、达到系统瓶颈后,再次增大并发和最大连接数吞吐量和延迟反而会下降
3、压测的机器选择,我是在服务器本机上跑的,这会使得压测程序占用一部分CPU,网络延迟几乎为0;而在笔记本上跑,网络延迟占很大部分。
二、python脚本
关于ab的参数分析在上一篇文章中介绍了,网上关于ab都是基于一行命令实现的:ab -n 1000 -c 400 http://baidu.com/,测一次这样的命令根本没有对比,无法达到条件二。于是写了一个python脚本,逐渐加大每个连接的并发数,找到吞吐量的峰值。
模拟场景是1000个请求,在每一个请求保持i个连接,i从1到500
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
2import xlwt
3import xlrd
4from xlutils.copy import copy
5
6
7ip = 'http://192.168.25.76:3102/'
8
9#创建excel,并写入标题
10workbook = xlwt.Workbook(encoding='ascii')
11worksheet = workbook.add_sheet("My WorkSheet",cell_overwrite_ok = True)
12worksheet.write(0,0,label='请求数')
13worksheet.write(0,1,label='失败数')
14worksheet.write(0,2,label='并发数')
15worksheet.write(0,3,label='TPS')
16worksheet.write(0,4,label='90%的响应时间')
17
18
19
20#追加到xls中
21'''
22excel = xlrd.open_workbook("E:\\QJBZ\\76.xls")
23#获得当前行数
24sheet = excel.sheet_by_index(0)
25oldrows= sheet.nrows
26#创建新的workbook
27workbook = copy(excel)
28worksheet = workbook.get_sheet(0)
29'''
30
31#如果是新创建的文档,则current为1,否则就读取之前文档的最后一行
32currentrows=1;
33for i in range(1,500):
34 myres = os.popen("ab -n 1000 -c "+str(i)+" "+ip).readlines()
35
36 #对应项写入excel中
37 comreq = myres[16].split(":")[1]
38 worksheet.write(currentrows+i-1,0,label=comreq)
39 failreq =myres[17].split(":")[1]
40 worksheet.write(currentrows+i-1,1,label=failreq)
41 conlevel = myres[14].split(":")[1]
42 worksheet.write(currentrows+i-1,2,label=conlevel)
43 tps = myres[20].split(":")[1]
44 tps = tps.split("[")[0]
45 worksheet.write(currentrows+i-1,3,label=tps)
46 responsetime= filter(None,myres[37].split(" "))
47 worksheet.write(currentrows+i-1,4,list(responsetime)[1])
48
49
50
51workbook.save('E:\\QJBZ\\76_v0.2.xls')
52
53
注意:脚本中没有更改路径,则应在apache24/bin/下运行,简单点的直接将py文件拖在该目录下,直接python test.py即可。
三、结果分析
测试这方面我是小白一枚,参考大佬的建议,首先测试http接口的tps,包括经过DB的和不经过DB的。再测试一遍所有的html界面即可。
1、http+db
ab测试http+db接口,选取的页面是登录界面,(经过DB):
2
3
2
3
post.txt中是post中传输的param值,格式如下:
2
3
2
3
2、仅http
代码和1一样,只是选取不经过db的界面,并且修改post.txt的内容,携带参数要调整。
通过1和2对比就可以得到访问DB的延迟。
3、结果
对登录界面分析
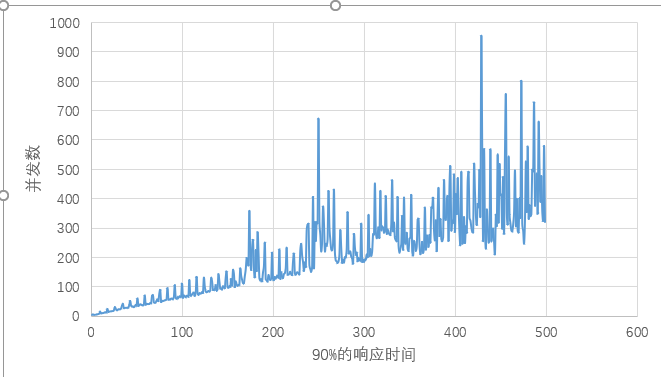
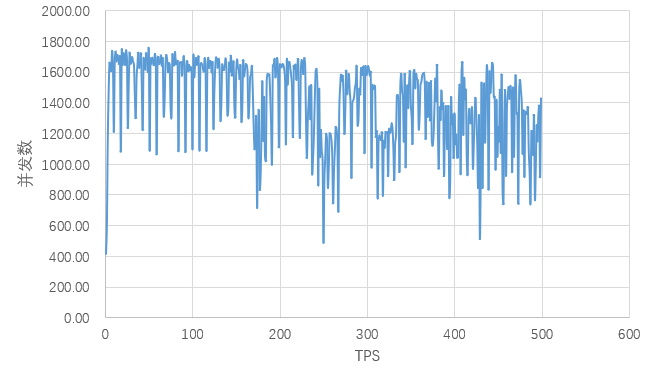
可以看到中间有一些振荡点,但不知是什么原因引起的,所以暂时没调整。
当并发数在100~200之间时,tps最大在1600req/s左右。延迟在140ms左右。
小白就测到这里了,测试的目的是为了验证框架和设计的优点,接下来一步是将后台引入线程池优化,并且测试EF框架的性能!!
