**1.abs(x):**返回
数字的绝对值,x可以是整数、浮点数、复数;
注:若
x是复数,则返回其大小
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
2a = -1
3b = -1.3232
4c = b
5d = 1+1.0j
6e = 3+4.0j
7f="a"
8g=[1,2]
9print ("a的绝对值是:",abs(a)) # 1
10print("b的绝对值是:",abs(b)) # 1.3232
11print("c的绝对值是:",math.fabs(c)) # 1.3232
12print("d的的绝对值是:",abs(d)) # 1.4142135623730951
13# print("e的绝对值是:",math.fabs(e)) # 报错:TypeError: can't convert complex to float
14# print("f的的绝对值是:",abs(f)) # 报错:TypeError: bad operand type for abs(): 'str'
15# print("g的的绝对值是:",abs(g)) # 报错:TypeError: bad operand type for abs(): 'list'
16
2.all(iterable):(1)
iterable非空的前提下,并且iterable里的元素全为true,则返回True,否则返回False;(2)
iterable为空,则返回True
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
2print(all(["a",[],1,True])) # False
3print(all(["a",[2,3],0,True])) # False
4print(all(["a",[2,3],10,False])) # False
5
6print(all(("a",[2,3],1,True))) # True
7print(all(("a",[],1,True))) # False
8print(all(("a",[2,3],0,True))) # False
9print(all(("a",[2,3],10,False))) # False
10
11print(all("dsajf")) # True
12# print(all(12345)) # 报错:TypeError: 'int' object is not iterable
13print(all([1,2,3])) # True
14
15
16print(all([])) # True
17print(all(())) # True
18print(all({})) # True
19print(all("")) # True
20
3.any(iterable):(1)
iterable非空的前提下,并且iterable里的元素只要有1个为true,则返回True,否则返回False;(2)
iterable为空,则返回False
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
2print(any(["a",[],1,True])) # True
3print(any(["a",[2,3],0,True])) # True
4print(any(["a",[2,3],10,False])) # True
5
6print(any(("a",[2,3],1,True))) # True
7print(any(("a",[],1,True))) # True
8print(any(("a",[2,3],0,True))) # True
9print(any(("a",[2,3],10,False))) # True
10
11print(any("dsajf")) # True
12# print(all(12345)) # 报错:TypeError: 'int' object is not iterable
13print(any([1,2,3])) # True
14
15
16print(any([])) # False
17print(any(())) # False
18print(any({})) # False
19print(any("")) # False
20
**4.ascii(obj):**返回一个对象可打印的字符串,与repr(obj)略有区别, repr() 返回的字符串中非 ASCII 编码的字符,会使用 \x、\u 和 \U 来转义,而ascii()不会
2
3
4
5
6
7
8
9
10
11
12
13
14
2print(ascii("1")) # '1'
3print(ascii("a")) # 'a'
4print(ascii([1,2,3])) # [1, 2, 3]
5print(ascii((2,3,4))) # (2, 3, 4)
6print(ascii("点击")) # '\u70b9\u51fb'
7
8print(repr(1)) # 1
9print(repr("1")) # '1'
10print(repr("a")) # 'a'
11print(repr([1,2,3])) # [1, 2, 3]
12print(repr((2,3,4))) # (2, 3, 4)
13print(repr("点击")) # '点击'
14
**5.bin(x):**将一个整数转变为一个前缀为“0b”的二进制字符串
2
3
4
5
6
7
2# print(bin(1.1)) # 报错:TypeError: 'float' object cannot be interpreted as an integer
3print(bin(0)) # 0b0
4# print(bin(0.0)) # 报错:TypeError: 'float' object cannot be interpreted as an integer
5print(bin(-2)) # -0b10
6# print(bin("a")) # 报错:TypeError: 'str' object cannot be interpreted as an integer
7
**6.bool(x):**返回一个布尔值,True 或者 False。如果 x 是假的或者被省略,返回 False;其他情况返回 True。bool 类是 int 的子类,其他类不能继承自它,它只有 False 和 True 两个实例。在 3.7 版中,x 现在只能作为位置参数。
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
2print(bool(0.0)) # False
3print(bool(1)) # True
4print(bool(1.1)) # True
5print(bool()) # False
6print(bool(())) # False
7print(bool([])) # False
8print(bool(None)) # False
9print(bool(1.1)) # True
10print(bool(True)) # True
11print(bool(False)) # False
12print(bool(0+0j)) # False
13print(bool(set())) # False
14print(bool(range(0))) # False
15print(bool("a")) # True
16print(bool) # <class 'bool'>
17print(True) # True
18print(True+1) # 2
19print(False) # False
20print(False+1) # 1
21
**7.breakpoint(*args, **kws):**运行到此函数时,会陷入到调试器中。实际调用的是 sys.breakpointhook() ,直接传递 args 和 kws 。默认情况下, sys.breakpointhook() 调用 pdb.set_trace() 且没有参数。
2
3
4
5
6
7
8
9
10
11
12
13
14
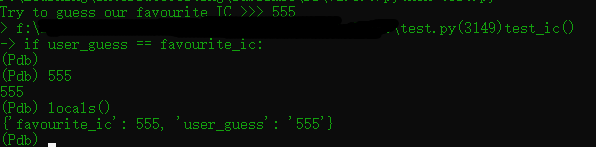
2 user_guess = input("Try to guess our favourite IC >>> ")
3 breakpoint()
4
5 if user_guess == favourite_ic:
6 return "Yup, that's our favourite!"
7 else:
8 return "Sorry, that's not our favourite IC"
9
10
11if __name__ == '__main__':
12 favourite_ic = 555
13 print(test_ic(favourite_ic))
14
运行截图:

**8.bytearray([source[, encoding[, errors]]]):**返回一个新的 bytes 数组。 bytearray 类是一个
可变序列,包含范围为
0 <= x < 256 的整数。它有可变序列大部分常见的方法,见 可变序列类型 的描述;同时有 bytes 类型的大部分方法,参见 bytes 和 bytearray 操作。
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
2b=bytearray(2)
3print(b) # bytearray(b'\x00\x00')
4print(len(b)) # 2
5
6b=bytearray(0)
7print(b) # bytearray(b'')
8print(len(b)) # 0
9
10# b=bytearray(-2) # 报错:ValueError: negative count
11
12
13# 如果是一个字符串,还必须给出编码,否则会报错
14# 当source参数为实现了buffer接口的object对象时,那么将使用只读方式将字节读取到字节数组后返回
15b=bytearray("abc","utf-8")
16print(b) # bytearray(b'abc')
17print(len(b)) # 3
18# b=bytearray("abc") # 报错:TypeError: string argument without an encoding
19
20# 如果是一个 iterable 可迭代对象(列表(list),元组(tuple),range()方法以及for循环),它的元素的范围必须是 0 <= x < 256 的整数,它会被用作数组的初始内容
21b=bytearray([1,2])
22print(b) # bytearray(b'\x01\x02')
23print(len(b)) # 2
24
25b=bytearray((1,2))
26print(b) # bytearray(b'\x01\x02')
27print(len(b)) # 2
28
29b=bytearray(set((1,2)))
30print(b) # bytearray(b'\x01\x02')
31print(len(b)) # 2
32
33b=bytearray(range(1,2))
34print(b) # bytearray(b'\x01')
35print(len(b)) # 1
36
37b=bytearray(i for i in range(1,5))
38print(b) # bytearray(b'\x01\x02\x03\x04')
39print(len(b)) # 4
40
41# 如果没有参数,则创建一个大小为0的数组。
42b=bytearray()
43print(b) # bytearray(b'')
44print(len(b)) # 0
45
以下是常见方法:
(1)**clear():**该方法无返回值
2
3
4
5
6
7
8
9
2print(b.clear()) # None
3print(b) # bytearray(b'')
4
5b=bytearray()
6b.clear()
7print(b) # bytearray(b'')
8print(len(b)) # 0
9
(2)append(x):
0≤x<256,x为整数,该方法无返回值
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
2print(b.append(7)) # None
3print(b) # bytearray(b'\x01\x02\x03\x04\x07')
4
5b=bytearray()
6b.append(1)
7print(b) # bytearray(b'\x01')
8print(len(b)) # 1
9b.append(0)
10print(b) # bytearray(b'\x01\x00')
11b.append(255)
12print(b) # bytearray(b'\x01\x00\xff')
13
14# b.append(-1) #报错:ValueError: byte must be in range(0, 256)
15# b.append((2,3)) # 报错:TypeError: an integer is required
16
**9.bytes([source[, encoding[, errors]]]):**返回一个新的 bytes 数组。 bytearray 类是一个
不可变序列,包含范围为
0 <= x < 256 的整数。
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
2print(b) # b'\x00\x00'
3print(len(b)) # 2
4
5b=bytes("abc","utf-8")
6print(b) # b'abc'
7print(len(b)) # 3
8
9# b=bytes("abc") # 报错:TypeError: string argument without an encoding
10
11b=bytes("啦","utf-8")
12print(b) # b'\xe5\x95\xa6'
13print(len(b)) # 3
14
15b=bytes("你好","utf-8")
16print(b) # b'\xe4\xbd\xa0\xe5\xa5\xbd'
17print(len(b)) # 6
18
19b=bytes(2)
20print(b) # b'\x00\x00'
21print(len(b)) # 2
22b=bytes("abc","utf-8")
23print(b) # b'abc'
24print(len(b)) # 3
25
26b=bytes([1,2])
27print(b) # b'\x01\x02'
28print(len(b)) # 2
29
30b=bytes((1,2))
31print(b) # bb'\x01\x02'
32print(len(b)) # 2
33
34b=bytes(set((1,2)))
35print(b) # b'\x01\x02'
36print(len(b)) # 2
37
38b=bytes(range(1,2))
39print(b) # b'\x01'
40print(len(b)) # 1
41
42b=bytes()
43print(b) # b''
44print(len(b)) # 0
45
46# b=bytes(range(1,257)) #报错: ValueError: bytes must be in range(0, 256)
47
**10.callable(obj):**检测obj是否可调用
(1)对于
函数、方法、lambda 函式、 类、实现了 call 方法的类实例, 都是可调用
(2)对于整数,字符串,列表,元组,字典等不可调用
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
2print(callable(1)) # False
3print(callable("abc")) # False
4print(callable([1,2])) # False
5print(callable((2,3))) # False
6print(callable(set([1,2]))) # False
7
8def add(a,b):
9 return a+b
10print(callable(add)) # True
11
12
13class A:
14 """docstring for A"""
15 def abc(self):
16 return 0
17print(callable(A)) # True
18
19a=A()
20print(callable(a)) # False
21
22
23class B:
24 def __call__(self):
25 return 0
26print(callable(B)) # True
27
28b=B()
29print(callable(b)) # True
30
31
32f=lambda x: x+1
33print(callable(f)) # True
34
11.chr(i):返回 Unicode 码位为整数 i 的字符的字符串格式
(1)实参的合法范围是 0 到 1,114,111(16 进制表示是 0x10FFFF)。如果 i 超过这个范围,会触发 ValueError 异常
2
3
4
5
6
7
8
2print(chr(90)) # Z
3print(chr(0)) #
4print(chr(8364)) # €
5print(chr(125)) # }
6print(chr(0x30)) # 0
7# print(chr(12345678)) # 报错:ValueError: chr() arg not in range(0x110000)
8
**12.@classmethod:**把一个方法封装成类方法
(1)3种类定义方法:常规方法、@classmethod修饰方法、@staticmethod修饰方法
2
3
4
5
6
7
8
9
10
11
12
13
2 def foo(self, x):
3 print("1-executing foo(%s,%s)" % (self, x))
4 print('1-self:', self)
5 @classmethod
6 def class_foo(cls, x):
7 print("2-executing class_foo(%s,%s)" % (cls, x))
8 print('2-cls:', cls)
9 @staticmethod
10 def static_foo(x):
11 print("3-executing static_foo(%s)" % x)
12a = A()
13
1)
普通的类方法foo()需要通过self参数隐式的传递当前类对象的实例;
@classmethod修饰的方法class_foo()需要通过cls参数传递当前类对象;
@staticmethod修饰的方法定义与普通函数一样。self和cls的区别不是强制的,只是PEP8中一种编程风格,self通常用作实例方法的第一参数,cls通常用作类方法的第一参数。即通常用self来传递当前类对象的实例,cls传递当前类对象
2)foo方法绑定对象A的实例,class_foo方法绑定对象A,static_foo没有参数绑定
2
3
4
2print(a.class_foo) # <bound method A.class_foo of <class '__main__.A'>>
3print(a.static_foo) # <function A.static_foo at 0x0000028D5AAD2840>
4
3)foo可通过实例a调用,类对像A直接调用会参数错误
2
3
4
5
6
2 # 1-self: <__main__.A object at 0x0000017229EC0BA8>
3 # None
4
5# print(A.foo(1)) # 报错:TypeError: foo() missing 1 required positional argument: 'x'
6
4)但foo如下方式可以使用正常,显式的传递实例参数a
2
3
4
2 # 1-self: <__main__.A object at 0x000002608CDD0BA8>
3 # None
4
5)class_foo通过类对象或对象实例调用
2
3
4
5
6
7
2 # 2-cls: <class '__main__.A'>
3 # None
4print(a.class_foo(1)) # 2-executing class_foo(<class '__main__.A'>,1)
5 # 2-cls: <class '__main__.A'>
6 # None
7
6)static_foo通过类对象或对象实例调用
2
3
4
5
2 # None
3print(a.static_foo(1)) # 3-executing static_foo(1)
4 # None
5
7)继承与覆盖普通类函数是一样的
2
3
4
5
6
7
8
9
2 pass
3b = B()
4b.foo(1) # 1-executing foo(<__main__.B object at 0x0000018E5FF10FD0>,1)
5 # 1-self: <__main__.B object at 0x0000018E5FF10FD0>
6b.class_foo(1) # 2-executing class_foo(<class '__main__.B'>,1)
7 # 2-cls: <class '__main__.B'>
8b.static_foo(1) # 3-executing static_foo(1)
9
8)@staticmethod是把函数嵌入到类中的一种方式,函数就属于类,同时表明函数不需要访问这个类。通过子类的继承覆盖,能更好的组织代码
9)区别:@staticmethod 会硬编码,就是说,方法中返回的类名必须与当前的 class 名称一致
@classmethod 是软编码,该方法传递的第一个参数使 cls ,cls 默认绑定了当前的类名
具体例子可见:https://blog.csdn.net/grace666/article/details/100990469
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
2 sex = '每日' #这就是非绑定的属性
3 @staticmethod
4 def sta():
5 return Fuck.sex
6 @classmethod
7 def cla(cls):
8 return cls.sex #@classmethod里面必须要传入一个参数,这个参数代表就是当前的类
9class Fuck_everybody(Fuck): #因为Fuck_everybody继承了父类Fuck,所以Fuck_everybody可以调用父类的sta()方法与cla()方法
10 pass
11
12print(Fuck_everybody.sta()) # 每日
13print(Fuck_everybody.cla()) # 每日
14
15# 然后我突然不爽,把Fuck删掉了
16del Fuck
17#那么,你再试试
18# print(Fuck_everybody.sta()) # 报错:NameError: name 'Fuck' is not defined
19print(Fuck_everybody.cla()) # 每日
20#虽然删掉,但是仍能执行
21
https://www.zhihu.com/question/20021164?sort=created
13.compile(source, filename, mode, flags=0, dont_inherit=False, optimize=-1):
(1)source:常规的字符串、字节字符串,或者 AST (抽象语法树)对象
filename:实参需要是代码读取的文件名;如果代码不需要从文件中读取,可以传入一些可辨识的值(经常会使用 '<string>')
mode:指定编译代码必须用的模式。如果 source 是语句序列,可以是 'exec';如果是单一表达式,可以是 'eval';如果是单个交互式语句,可以是 'single'。(在最后一种情况下,如果表达式执行结果不是 None 将会被打印出来。)
flags:变量作用域,局部命名空间,如果被提供,可以是任何映射对象
flags和dont_inherit是用来控制编译源码时的标志,如果两者都未提供(或都为零)则会使用调用 compile() 的代码中有效的 future 语句来编译代码。 如果给出了 flags 参数但没有 dont_inherit (或是为零) 则 flags 参数所指定的 以及那些无论如何都有效的 future 语句会被使用。 如果 dont_inherit 为一个非零整数,则只使用 flags 参数 — 在调用外围有效的 future 语句将被忽略
optimize:实参指定编译器的优化级别;默认值 -1 选择与解释器的 -O 选项相同的优化级别;显式级别为 0 (没有优化;debug 为真)、1 (断言被删除, debug 为假)或 2 (文档字符串也被删除)
如果编译的源码不合法,此函数会触发 SyntaxError 异常;如果源码包含 null 字节,则会触发 ValueError 异常
14.complex([real[, imag]]) 复数
real—int、float、long、
字符串
imag—int、float、long
当real为int、float、long时,imag可缺省或同样为int、float、long
当real为字符串时,则imag必须为能表示复数的字符串形式,如“1+2j”、“1-3j”,但是中间的“+”或“-”号两边不能有空格,并且imag必须缺省
当real和imag都缺省,返回0j
2
3
4
5
6
7
8
9
10
11
12
13
14
15
2print(complex(1, 2)) # (1+2j)
3print(complex(3)) # (3+0j)
4print(complex("4")) # (4+0j)
5print(complex(5 + 3j)) # (5+3j)
6print(complex("6+5j")) # (6+5j)
7print(complex("6-5j")) # (6-5j)
8print(complex("6.1+5.2j")) # (6.1+5.2j)
9print(complex("6.1")) # (6.1+0j)
10
11print(complex("1+2j")) # (1+2j)
12print(complex(" 1+2j")) # (1+2j)
13print(complex(" 1+2j ")) # (1+2j)
14# print(complex("1 +2j")) # 报错:ValueError: complex() arg is a malformed string
15
可以使用
下划线将代码文字中的数字进行分组:
2
3
4
5
6
7
8
9
10
2print(complex("1_1")) # (11+0j)
3print(complex("0_10")) # (10+0j)
4print(complex("1_0")) # (10+0j)
5print(complex("0_0")) # 0j
6print(complex("1_2_3")) # (123+0j)
7print(complex("1_2_3_4")) # (1234+0j)
8print(complex("1_2+3j")) # (12+3j)
9print(complex("0_2+3j")) # (2+3j)
10
15.dir():
(1)如果没有实参,则返回当前本地作用域中的名称列表
2
2
(2)如果有实参,它会尝试返回该对象的有效属性列表
2
3
4
5
6
7
8
9
10
11
12
2
3def x():
4 return 1
5print(dir(x)) # ['__annotations__', '__call__', '__class__', '__closure__', '__code__', '__defaults__', '__delattr__', '__dict__', '__dir__', '__doc__', '__eq__', '__format__', '__ge__', '__get__', '__getattribute__', '__globals__', '__gt__', '__hash__', '__init__', '__init_subclass__', '__kwdefaults__', '__le__', '__lt__', '__module__', '__name__', '__ne__', '__new__', '__qualname__', '__reduce__', '__reduce_ex__', '__repr__', '__setattr__', '__sizeof__', '__str__', '__subclasshook__']
6
7class A():
8 pass
9print(dir(A)) # ['__class__', '__delattr__', '__dict__', '__dir__', '__doc__', '__eq__', '__format__', '__ge__', '__getattribute__', '__gt__', '__hash__', '__init__', '__init_subclass__', '__le__', '__lt__', '__module__', '__ne__', '__new__', '__reduce__', '__reduce_ex__', '__repr__', '__setattr__', '__sizeof__', '__str__', '__subclasshook__', '__weakref__']
10s=A()
11print(dir(s)) # ['__class__', '__delattr__', '__dict__', '__dir__', '__doc__', '__eq__', '__format__', '__ge__', '__getattribute__', '__gt__', '__hash__', '__init__', '__init_subclass__', '__le__', '__lt__', '__module__', '__ne__', '__new__', '__reduce__', '__reduce_ex__', '__repr__', '__setattr__', '__sizeof__', '__str__', '__subclasshook__', '__weakref__']
12
(3)如果对象有一个名为 dir() 的方法,那么该方法将被调用,并且必须返回一个属性列表
2
3
4
5
6
7
2 def __dir__(self):
3 return "yyy"
4print(dir(A)) # ['__class__', '__delattr__', '__dict__', '__dir__', '__doc__', '__eq__', '__format__', '__ge__', '__getattribute__', '__gt__', '__hash__', '__init__', '__init_subclass__', '__le__', '__lt__', '__module__', '__ne__', '__new__', '__reduce__', '__reduce_ex__', '__repr__', '__setattr__', '__sizeof__', '__str__', '__subclasshook__', '__weakref__']
5s=A()
6print(dir(s)) # ['y', 'y', 'y']
7
**16.divmod(a, b):**它将两个(非复数)数字作为实参,并在执行整数除法时返回一对商和余数
(1)若a和b都为整数,函数返回的结果相当于 (a // b, a % b)
2
3
4
5
6
7
8
9
10
11
12
2b=20
3print(divmod(a,b)) # (5, 0)
4
5a=100
6b=30
7print(divmod(a,b)) # (3, 10)
8
9a=0
10b=5
11print(divmod(a,b)) # (0, 0)
12
(2)若a和b中有1个浮点数,函数返回的结果相当于 (q, a % b),q 通常是 math.floor(a / b),但也有可能是 1 ,比小,不过 q * b + a % b 的值会非常接近 a
2
3
4
5
6
7
8
2b=20
3print(divmod(a,b)) # (5.0, 0.25)
4
5a=100.25
6b=21.1
7print(divmod(a,b)) # (4.0, 15.849999999999994)
8
(3)如果 a % b 的求余结果不为 0 ,则余数的正负符号跟参数 b 是一样的,若 b 是正数,余数为正数,若 b 为负数,余数也为负数,并且 0 <= abs(a % b) < abs(b)
2
3
4
5
6
7
8
9
10
11
12
2b=5
3print(divmod(a,b)) # (-2, 2)
4
5a=8
6b=-5
7print(divmod(a,b)) # (-2, -2)
8
9a=-8
10b=-5
11print(divmod(a,b)) # (1, -3)
12
(4)除数不能为0,或者a/b不能为复数
2
3
4
5
6
7
8
2# b=0
3# print(divmod(a,b)) # 报错:ZeroDivisionError: integer division or modulo by zero
4
5# a=100+5j
6# b=20
7# print(divmod(a,b)) # 报错:TypeError: can't take floor or mod of complex number.
8
**17.enumerate(iterable, start=0):**用于将一个可遍历的数据对象(如列表、元组或字符串)组合为一个索引序列,同时列出数据和数据下标,一般用在 for 循环当中,默认下标从0开始,也可自定义
2
3
4
5
6
7
8
9
10
2print(enumerate(seasons)) # <enumerate object at 0x00000226EEC4ABD0>
3print(list(enumerate(seasons))) # [(0, 'Spring'), (1, 'Summer'), (2, 'Fall'), (3, 'Winter')]
4print(tuple(enumerate(seasons))) # ((0, 'Spring'), (1, 'Summer'), (2, 'Fall'), (3, 'Winter'))
5print(set(enumerate(seasons))) # {(0, 'Spring'), (1, 'Summer'), (2, 'Fall'), (3, 'Winter')}
6
7seasons = ['Spring', 'Summer', 'Fall', 'Winter']
8print(list(enumerate(seasons))) # [(0, 'Spring'), (1, 'Summer'), (2, 'Fall'), (3, 'Winter')]
9print(list(enumerate(seasons,1))) # [(1, 'Spring'), (2, 'Summer'), (3, 'Fall'), (4, 'Winter')]
10
**18.delattr(object, name):**删除对象object的属性name,object是对象,name是字符串,name必须是object的某个属性。如果对象允许,该函数将删除指定的属性
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
2 x=1
3 y=-2
4 z=3
5 def aa(self):
6 print("hello")
7
8a=A()
9print("x = ",a.x) # x = 1
10print("y = ",a.y) # y = -2
11print("z = ",a.z) # z = 3
12a.aa() # hello
13
14delattr(A, 'z')
15print("x = ",a.x) # x = 1
16print("y = ",a.y) # y = -2
17# print("z = ",a.z) # 报错:AttributeError: 'A' object has no attribute 'z'
18# delattr(A, 't') # 报错:AttributeError: t
19delattr(A, 'aa')
20# a.aa() # 报错:AttributeError: 'A' object has no attribute 'aa'
21
delattr(x, 'foobar')
等价于 del x.foobar
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
2 x=1
3 y=-2
4 z=3
5 def aa(self):
6 print("hello")
7
8a=A()
9print("x = ",a.x) # x = 1
10print("y = ",a.y) # y = -2
11print("z = ",a.z) # z = 3
12a.aa() # hello
13
14del A.z
15print("x = ",a.x) # x = 1
16print("y = ",a.y) # y = -2
17# print("z = ",a.z) # 报错:AttributeError: 'A' object has no attribute 'z'
18
19del A.aa
20# a.aa() # 报错:AttributeError: 'A' object has no attribute 'aa'
21
**19.eval(expression[, globals[, locals]]):**可参考 https://mp.csdn.net/postedit/90639536
**20.exec(object[, globals[, locals]]):**可参考 https://blog.csdn.net/grace666/article/details/101294711
**21.filter(function, iterable):**用来过滤序列中不符合条件的元素,返回的是迭代器对象,用的话需要进行转换,比如要转换为列表,可以使用 list() 来转换;接收两个参数,第一个function为函数,第二个iterable为序列,iterable的每个元素作为参数传递给function进行判,然后返回 True 或 False,最后将返回 True 的元素放到新的迭代器中;
注, filter(function, iterable) 相当于一个生成器表达式,当 function 不是 None 的时候为 (item for item in iterable if function(item));function 是 None 的时候为 (item for item in iterable if item)
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
2 return n%2==1
3
4alist=[1,2,3,4,5,6]
5temp=filter(is_odd, alist)
6print(temp) # <filter object at 0x000001DCE49A0AC8>
7newlist=list(temp)
8print(newlist) # [1, 3, 5]
9
10newtuple=tuple(temp)
11print(newtuple) # ()
12
13temp=filter(is_odd, alist)
14newtuple=tuple(temp)
15print(newtuple) # (1, 3, 5)
16
17
18alist=[1,2,3,4,5,6]
19temp=filter(None, alist)
20print(temp) # <filter object at 0x0000019DF5D10A90>
21newlist=list(temp)
22print(newlist) # [1, 2, 3, 4, 5, 6]
23
24alist=[1,2,3,0,5,6,0,False,"a","","ee"," ","b",(),"c",[],"d",{},"f",set(),"g",range(0)]
25temp=filter(None, alist)
26print(temp) # <filter object at 0x0000018BD3060AC8>
27newlist=list(temp)
28print(newlist) # [1, 2, 3, 5, 6, 'a', 'ee', ' ', 'b', 'c', 'd', 'f', 'g']
29
ps:python2中该函数返回的是list,而Python3中改成迭代器,这样的好处为了节省内存,因为map和filter等函数返回一个迭代器,这个迭代器具有类生成器的特性,是懒加载的,它只有在下次调用的时候才会去计算本次生成的值,而不是像列表那样预先生成所有的值然后每次调用返回列表中的下一个值。这种方式需要将所有的值预先保存在列表中,当列表很大的时候这是非常消耗内存的
**22.float([x]):**返回从数字或字符串 x 生成的浮点数,可参考 https://blog.csdn.net/grace666/article/details/90639536
**23.format(value[, format_spec]):**将 value 转换为 format_spec 控制的“格式化”表示
(1)
format_spec的格式: [[fill]align][sign][#][0][width][grouping_option][.precision][type]
(2)
format_spec默认为空字符串,等同于 str(value)
(3)
fill:可为任意字符,fill是可选的,但是如果设置了fill,就必须和align搭配使用
align:对齐方式
| 选项 | 含义 |
| '<' | 强制字段在可用空间内左对齐(这是大多数对象的默认值) |
| '>' | 强制字段在可用空间内右对齐(这是数字的默认值) |
| '=' | 强制将填充放置在符号(如果有)之后但在数字之前,此对齐选项仅对数字类型有效,否则报错 |
| '^' | 强制字段在可用空间内居中 |
1 | 1 |
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
2print(format(0x500, 'X'))
3print(format(3.14, '0=10'))
4print(format(3.14159, '05.3'))
5print(format(3.14159, 'E'))
6print(format('test', '<20'))
7print(format('test', '>20'))
8print(format('test', '^20'))
9
10#打印值:
11# 2918
12# 500
13# 0000003.14
14# 03.14
15# 3.141590E+00
16# test
17# test
18# test
19
左对齐:
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
2print(format('test', '<')) # test
3print(format('test', '@<')) # test
4
5#字符“test”左对齐,宽度为5,不足以“@”补齐
6print(format('test', '@<5')) # test@
7
8#字符“test”左对齐,宽度为4,不足以“@”补齐
9print(format('test', '@<4')) # test
10
11#字符“test”左对齐,宽度为3,不足以“@”补齐
12print(format('test', '@<3')) # test
13
14#给出fill,就必须要和align搭配使用,否则报错
15# print(format('test', '@')) # 报错:ValueError: Unknown format code '@' for object of type 'str'
16
17#字符“test”左对齐,宽度为10,不足以“@”补齐
18print(format('test', '@<10')) # test@@@@@@
19
右对齐:
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
2print(format('test', '>')) # test
3print(format('test', '$>')) # test
4
5#字符“test”右对齐,宽度为5
6print(format('test', '$>5')) # $test
7
8#字符“test”右对齐,宽度为4,不足以“$”补齐
9print(format('test', '$>4')) # test
10
11#字符“test”右对齐,宽度为3,不足以“$”补齐
12print(format('test', '$>3')) # test
13
14
15#字符“test”右对齐,宽度为10,不足以“$”补齐
16print(format('test', '$>10')) # $$$$$$test
17
居中:
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
2# print(format('test', '*')) # 报错:ValueError: Unknown format code '*' for object of type 'str'
3print(format('test', '*^')) # test
4
5#字符“test”空间内居中,宽度为5
6print(format('test', '*^5')) # test*
7
8#字符“test”空间内居中,宽度为4,不足以“$”补齐
9print(format('test', '*^4')) # test
10
11#字符“test”空间内居中,宽度为3,不足以“$”补齐
12print(format('test', '*^3')) # test
13
14
15#字符“test”空间内居中,宽度为10,不足以“$”补齐
16print(format('test', '*^10')) # ***test***
17
填充数字宽度
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
2# print(format('test', '@=10')) # 报错:ValueError: '=' alignment not allowed in string format specifier
3
4print(format(123, '=')) # 123
5
6#数字“123”宽度为5,不足以“@”补足
7print(format(123, '@=5')) # @@123
8
9#数字“123”宽度为4,不足以“@”补齐
10print(format(123, '@=4')) # @123
11
12#数字“123”宽度为3,不足以“@”补齐
13print(format(123, '@=3')) # 123
14
15#数字“123”宽度为10,不足以“@”补齐
16print(format(123, '@=10')) # @@@@@@@123
17
2
3
4
5
6
7
8
9
10
11
12
13
14
2
3# #数字“12.13”宽度为6,不足以“@”补足
4# print(format(12.13, '@=6')) # @12.13
5
6# #数字“12.13”宽度为5,不足以“@”补齐
7# print(format(12.13, '@=5')) # 12.13
8
9# #数字“12.13”宽度为4,不足以“@”补齐
10# print(format(12.13, '@=4')) # 12.13
11
12# #数字“12.13”宽度为10,不足以“@”补齐
13# print(format(12.13, '@=10')) # @@@@@12.13
14
(4)
sign:符号,仅对数字有效
| 选项 | 含义 |
| '+' | 表示标志应该用于正数和负数 |
| '-' | 表示标志应仅用于负数(这是默认行为) |
| space | 表示应在正数上使用前导空格,在负数上使用减号 |
1 | 1 |
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
2print(format(123, '-')) #123
3
4print(format(-123, '+')) #-123
5print(format(-123, '-')) #-123
6
7print(format(123, '>5')) # 123
8print(format(123, ' >5')) # 123
9
10print(format(123, '>+5')) # +123
11print(format(123, '>-5')) # 123
12
13print(format(-123, '>+5')) # -123
14print(format(-123, '>-5')) # -123
15
16print(format(123, ' ')) # 123
17print(format(-123, ' ')) #-123
18
19# print(format(123, ' ')) #2个空格报错:ValueError: Unknown format code '\x20' for object of type 'int'
20
21print(format(1.23, ' ')) # 1.23
22print(format(-1.23, ' ')) #-1.23
23
(5)
#:数字的格式,
仅对整数、浮点、复数和 Decimal 类型有效;对于整数类型,当使用二进制、八进制或十六进制输出时,此选项会为输出值添加相应的 '0b', '0o' 或 '0x' 前缀; 对于浮点数、复数和 Decimal 类型,替代形式会使得转换结果总是包含小数点符号,即使其不带小数;通常只有在带有小数的情况下,此类转换的结果中才会出现小数点符号; 此外,对于 'g' 和 'G' 转换,末尾的零不会从结果中被移除
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
2print(format(-123, '#')) #-123
3print(format(0x500, '#')) #1280
4print(hex(1280)) #0x500
5
6#二进制/八进制/十六进制数
7print(format(123, '#b')) #0b1111011
8print(format(123, '#o')) #0o173
9print(format(123, '#x')) #0x7b
10print(format(123, 'b')) #1111011
11print(format(123, 'o')) #173
12print(format(123, 'x')) #7b
13
14#带g或G的数
15print(format(123, '#g')) #123.000
16print(format(123, '#G')) #123.000
17print(format(123.000, '#')) #123.0
18print(format(123, 'g')) #123
19print(format(123, 'G')) #123
20print(format(123.000, '')) #123.0
21
22#小数
23print(format(1.235, '#')) #1.235
24print(format(11.0, '#')) #11.0
25print(format(12., '#')) #12.0
26print(format(1.235, '')) #1.235
27print(format(11.0, '')) #11.0
28print(format(12., '')) #12.0
29print(format(float(12), '#')) #12.0
30print(format(float(12), '')) #12.0
31
32#复数
33print(format(2+3j, '#')) #(2.+3.j)
34print(format(2+3j, '')) #(2.+3j)
35
(6)
0:针对数字的对齐,当没有明确给出对齐方式时,则在width选项前面加'0'字符可以为数字类型是字符0进行填充。这相当于填充字符'0',对齐类型为'='
2
3
4
5
2print(format(0x500, '0=10')) #0000001280
3print(format(1.23, '0=')) #1.23
4print(format(1.23, '0=10')) #0000001.23
5
(7)
width:最小字段宽度的十进制整数, 如果未指定,则字段宽度将由内容确定
2
3
4
5
6
2print(format("abc", '10')) #abc
3# print(format("abc", '010')) #报错:ValueError: '=' alignment not allowed in string format specifier
4print(format("abcdefg", '10')) #abcdefg
5# print(format([1,2,3], '10')) #报错:TypeError: unsupported format string passed to
6
当未显式给出对齐方式时,
在 width 字段前加一个零 ('0') 字段将为数字类型启用感知正负号的零填充, 这相当于设置 fill 字符为 '0' 且 alignment 类型为 '='
2
3
2print(format(123, '010')) #0000000123
3
(8)
grouping_option:千位分隔符
| 选项 | 含义 |
| ',' | 选项表示使用逗号(,)作为千位分隔符。 对于感应区域设置的分隔符,请改用 'n' 整数表示类型 |
| '_' | 表示对浮点表示类型和整数表示类型 'd' 使用下划线(_)作为千位分隔符。 对于整数表示类型 'b', 'o', 'x' 和 'X',将为每 4 个数位插入一个下划线。 对于其他表示类型指定此选项则将导致错误 |
1 | 1 |
2
3
4
5
6
7
8
9
10
2print(format(12.3, ',')) #12.3
3print(format(123456789, ',')) #123,456,789
4print(format(1.23456789, ',')) #1.23456789
5
6print(format(123, '_')) #123
7print(format(12.3, '_')) #12.3
8print(format(123456789, '_')) #123_456_789
9print(format(1.23456789, '_')) #1.23456789
10
(9)
**.**precision:
对于
数字类型,如以 'f' and 'F' 格式化的浮点数值要在
小数点后显示多少位,或者对于以 'g' 或 'G' 格式化的浮点数值要在小数点前后共显示多少个数位, 对于整数值则不允许使用 precision
2
3
4
2print(format(12.3, ".5")) # 12.3
3print(format(1.23456789, '.5')) #1.2346
4
对于
非数字类型,该字段表示
最大字段大小 —— 换句话说就是要使用多少个来自字段内容的字符
2
2
(10)
type:数据类型
针对字符串:
| 类型 | 含义 |
| 's' | 字符串格式。这是字符串的默认类型,可以省略 |
| None(不设置) | 和 's' 一样 |
1 | 1 |
2
3
4
5
6
7
2print(format("abc", )) #abc
3print(format("abc","" )) #abc
4
5# print(format(12.3, "s")) #报错:ValueError: Unknown format code 's' for object of type 'float'
6# print(format(123, 's')) #报错:ValueError: Unknown format code 's' for object of type 'int'
7
针对整数:
| 类型 | 含义 |
| 'b' | 二进制格式, 输出以 2 为基数的数字 |
| 'c' | 字符,在打印之前将整数转换为相应的unicode字符 |
| 'd' | 十进制整数, 输出以 10 为基数的数字 |
| 'o' | 八进制格式, 输出以 8 为基数的数字 |
| 'x' | 十六进制格式, 输出以 16 为基数的数字,使用小写字母表示 9 以上的数码 |
| 'X' | 十六进制格式, 输出以 16 为基数的数字,使用大写字母表示 9 以上的数码 |
| 'n' | 数字, 这与 'd' 相似,不同之处在于它会使用当前区域设置来插入适当的数字分隔字符,在中文语言环境是没有分隔符的。可以使用locale模块进行切换 |
| None | 和 'd' 相同 |
1 | 1 |
2
3
4
5
6
7
8
9
10
2print(format(123, "c")) #{
3print(format(123, "d")) #123
4print(format(123, "o")) #173
5print(format(123, "x")) #7b
6print(format(123, "X")) #7B
7print(format(123, "n")) #123
8print(format(123, "")) #123
9print(format(123, )) #123
10
针对浮点和小数:
| 类型 | 含义 |
| 'e' | 指数表示, 以使用字母 'e' 来标示指数的科学计数法打印数字, 默认的精度为 6 |
| 'E' | 指数表示, 与 'e' 相似,不同之处在于它使用大写字母 'E' 作为分隔字符。、 |
| 'f' | 定点表示, 将数字显示为一个定点数, 默认的精确度为 6;如果原数字小数点后位数超过6位且第7位大于5,则第6位+1,但第7位等于5时,则要看是否存在第8位且大于0,如大于0,第6位也+1,如果原数字小数点后不足6位的,则以0补充。如果指定了精度则按上述规则推算即可 |
| 'F' | 定点表示。 与 'f' 相似,但会将 nan 转为 NAN 并将 inf 转为 INF。 |
| 'g' | 常规格式。 对于给定的精度 p >= 1,这会将数值舍入到 p 位有效数字,再将结果以定点格式或科学计数法进行格式化,具体取决于其值的大小。 一般格式,在未设置精度的情况下,它保留6位数(整数+小数),根据实际情况选择以固定位数或者科学计数法格式化结果,结果后面如果存在多余的0将会被舍去。有以及几种规则:如果整数位已经等于精度,则舍掉所有小数,并且以小数的第一位四舍五入进整数;如果整数位大于精度,则以exp指数的形式格式化,以精度位的下一位作为判断依据四舍五入;如果整数位不足精度位数,则使用小数位补充,不存在小数位或者整数位+小数位不足精度,则显示完整数字;如果整数位不足精度位数,且小数位大于剩余精度,则截取小数位剩余精度,以后一位小数为判断是否舍去还是进一,如后一位小数大于5,则进一,如后一小数小于5,则舍去,如后一位小数等于5且后二位小数大于0,则进一。 正负无穷,正负零和 nan 会分别被格式化为 inf, -inf, 0, -0 和 nan,无论精度如何设定。 精度 0 会被视为等同于精度 1。 默认精度为 6。 |
| 'G' | 常规格式。 类似于 'g',不同之处在于当数值非常大时会切换为 'E'。 无穷与 NaN 也会表示为大写形式。 |
| 'n' | 数字, 这与 'g' 相似,不同之处在于它会使用当前区域设置来插入适当的数字分隔字符,在中文语言环境是没有分隔符的。可以使用locale模块进行切换。 |
| '%' | 百分比。 将数字乘以 100 并显示为定点 ('f') 格式,后面带一个% |
| None | 类似于 'g',不同之处在于当使用定点表示法时,小数点后将至少显示一位, 默认精度与表示给定值所需的精度一样, 整体效果为与其他格式修饰符所调整的 str() 输出保持一致 |
1 | 1 |
“e”和“E”
2
3
4
5
6
7
8
9
2print(format(12.3, "E")) #1.230000E+01
3print(format(12.3456789, "e")) #1.234568e+01
4print(format(12.3456789, "E")) #1.234568E+01
5print(format(12.3456785, "e")) #1.234568e+01
6print(format(12.3456785, "E")) #1.234568E+01
7print(format(12.34567851, "e")) #1.234568e+01
8print(format(12.34567851, "E")) #1.234568E+01
9
“f"和”F“
2
3
4
5
6
7
8
9
10
11
2print(format(123, "F")) #123.000000
3print(format(12.3, "f")) #12.300000
4print(format(12.3, "F")) #12.300000
5print(format(12.3456789, "f")) #12.345679
6print(format(12.3456789, "F")) #12.345679
7print(format(12.3456785, "f")) #12.345678
8print(format(12.3456785, "F")) #12.345678
9print(format(12.34567851, "f")) #12.345679
10print(format(12.34567851, "F")) #12.345679
11
”g“和”G“
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
2print(format(123456, "G")) #123456
3
4print(format(123456.3, "g")) #123456
5print(format(123456.3, "G")) #123456
6print(format(123456.5, "g")) #123456
7print(format(123456.5, "G")) #123456
8print(format(123456.6, "g")) #123457
9print(format(123456.6, "G")) #123457
10
11print(format(1234567.6, "g")) #1.23457e+06
12print(format(1234567.6, "G")) #1.23457E+06
13print(format(1234562.6, "g")) #1.23456e+06
14print(format(1234562.6, "G")) #1.23456E+06
15
16print(format(123, "g")) #123
17print(format(123, "G")) #123
18print(format(123.45, "g")) #123.45
19print(format(123.45, "G")) #123.45
20print(format(12.3456189, "g")) #12.3456
21print(format(12.3456189, "G")) #12.3456
22print(format(12.34567851, "g")) #12.3457
23print(format(12.34567851, "G")) #12.3457
24print(format(12.34565, "g")) #12.3456
25print(format(12.34565, "G")) #12.3456
26print(format(12.345650, "g")) #12.3456
27print(format(12.345650, "G")) #12.3456
28print(format(12.345651, "g")) #12.3457
29print(format(12.345651, "G")) #12.3457
30print(format(12.3456501, "g")) #12.3457
31print(format(12.3456501, "G")) #12.3457
32
”n"
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
2print(format(123456.3, "n")) #123456
3print(format(123456.5, "n")) #123456
4print(format(123456.6, "n")) #123457
5print(format(1234567.6, "n")) #1.23457e+06
6print(format(1234562.6, "n")) #1.23456e+06
7
8print(format(123, "n")) #123
9print(format(123.45, "n")) #123.45
10print(format(12.3456189, "n")) #12.3456
11print(format(12.34567851, "n")) #12.3457
12print(format(12.34565, "n")) #12.3456
13print(format(12.345650, "n")) #12.3456
14print(format(12.345651, "n")) #12.3457
15print(format(12.3456501, "n")) #12.3457
16
None:
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
2print(format(123456.3, "")) #123456.3
3print(format(123456.5, "")) #123456.5
4print(format(123456.6, "")) #123456.6
5print(format(1234567.6, "")) #1234567.6
6print(format(1234562.6, "")) #1234562.6
7
8print(format(123, "")) #123
9print(format(123.45, "")) #123.45
10print(format(12.3456189, "")) #12.3456189
11print(format(12.34567851, "")) #12.34567851
12print(format(12.34565, "")) #12.34565
13print(format(12.345650, "")) #12.34565
14print(format(12.345651, "")) #12.345651
15print(format(12.3456501, "")) #12.3456501
16
**24.frozenset([iterable]):**不可变集合,具体可参考:https://blog.csdn.net/grace666/article/details/98752091
**25.getattr(object, name[, default]):**返回对象命名属性的值;
object是对象,name 必须是字符串,如果
name是对象的属性之一,则返回该属性的值;如果指定的属性不存在,但是提供了 default 值,则返回它;否则触发 AttributeError;如果
给定的属性name是对象的方法,则返回的是函数对象,需要调用函数对象来获得函数的返回值,调用的话就是函数对象后面加括号,如func之于func()
2
3
4
5
6
7
8
9
10
11
12
13
14
2 bar=1
3
4print(getattr(A, "bar")) #1
5print(getattr(A, "bar","new")) #1
6print(getattr(A, "bar1","默认")) #默认
7# print(getattr(A, "bar1")) #报错:AttributeError: 'A' object has no attribute 'bar1'
8
9a=A()
10print(getattr(a, "bar")) #1
11print(getattr(a, "bar","new")) #1
12print(getattr(a, "bar1","默认")) #默认
13# print(getattr(a, "bar1")) #报错:AttributeError: 'A' object has no attribute 'bar1'
14
注意,
如果给定的方法func()是实例函数,则不能写getattr(A, 'func')(),因为fun()是实例函数的话,是不能用A类对象来调用的,应该写成getattr(A(), 'func')();实例函数和类函数的区别可以简单的理解一下,实例函数定义时,直接def func(self):,这样定义的函数只能是将类实例化后,用类的实例化对象来调用;而
类函数定义时,需要用@classmethod来装饰,函数默认的参数一般是cls,类函数可以通过类对象来直接调用,而不需要对类进行实例化;
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
2 def p(self):
3 print("hello")
4
5 @classmethod
6 def q(cls):
7 print("world")
8
9c=getattr(A, "p")
10print(type(c)) #<class 'function'>
11print(c) #<function A.p at 0x00000174D6AE9950>
12# c() #报错:TypeError: p() missing 1 required positional argument: 'self'
13
14a=A()
15c=getattr(a, "p")
16print(type(c)) #<class 'method'>
17print(c) #<bound method A.p of <__main__.A object at 0x000002064A110A90>>
18c() #hello
19
20
21c=getattr(A, "q")
22print(type(c)) #<class 'method'>
23print(c) #<bound method A.q of <class '__main__.A'>>
24c() #world
25
26a=A()
27c=getattr(a, "q")
28print(type(c)) #<class 'method'>
29print(c) #<bound method A.q of <class '__main__.A'>>
30c() #world
31
**26.globals():**获取当前模块的全局变量,
不受位置的影响,无论在是否在类或者方法中,都将返回调用它时当前模块的全局变量
在模块中直接使用:
2
2
定义在变量内:
2
3
2print(globals()) #{'__name__': '__main__', '__doc__': None, '__package__': None, '__loader__': <_frozen_importlib_external.SourceFileLoader object at 0x0000029A0FAE3080>, '__spec__': None, '__annotations__': {}, '__builtins__': <module 'builtins' (built-in)>, '__file__': 'test.py', '__cached__': None, 'pymongo': <module 'pymongo' from 'D:\\lib\\site-packages\\pymongo\\__init__.py'>, 'datetime': <module 'datetime' from 'D:\\\\V3.7.0\\lib\\datetime.py'>, 'reduce': <built-in function reduce>, 'ctime': <built-in function ctime>, 'a': 'hello'}
3
定义在方法内:
2
3
4
5
6
7
2 a=1
3 b=2
4 print(globals())
5
6f() #{'__name__': '__main__', '__doc__': None, '__package__': None, '__loader__': <_frozen_importlib_external.SourceFileLoader object at 0x000001F9DFEC3080>, '__spec__': None, '__annotations__': {}, '__builtins__': <module 'builtins' (built-in)>, '__file__': 'test.py', '__cached__': None, 'pymongo': <module 'pymongo' from 'D:\\V3.7.0\\lib\\site-packages\\pymongo\\__init__.py'>, 'datetime': <module 'datetime' from 'D:\\lib\\datetime.py'>, 'reduce': <built-in function reduce>, 'ctime': <built-in function ctime>, 'f': <function f at 0x000001F9DFB5D1E0>}
7
**27.hasattr(object, name):**object是对象,name 必须是字符串,如果name是对象的属性之一,则返回True;否则返回False
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
2 bar=1
3
4print(hasattr(A, "bar")) #True
5print(hasattr(A, "bar1")) #False
6
7a=A()
8print(hasattr(a, "bar")) #True
9print(hasattr(a, "bar1")) #False
10
11
12class A():
13 def p(self):
14 print("hello")
15
16 @classmethod
17 def q(cls):
18 print("world")
19
20c=hasattr(A, "p")
21print(type(c)) #<class 'bool'>
22print(c) #True
23# c() #报错:TypeError: 'bool' object is not callable
24
25a=A()
26c=hasattr(a, "p")
27print(type(c)) #<class 'bool'>
28print(c) #True
29
30
31c=hasattr(A, "q")
32print(type(c)) #<class 'bool'>
33print(c) #True
34
35a=A()
36c=hasattr(a, "q")
37print(type(c)) #<class 'bool'>
38print(c) #True
39
**28.hash(object):**如果object有哈希值的话,并返回,它们在字典查找元素时用来快速比较字典的键,相同大小的数字变量有相同的哈希值(即使它们类型不同,如 1 和 1.0)
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
2a="a"
3print(hash(a)) #1662299966867198853
4
5print(hash(1)) #1
6print(hash(1.0)) #1
7print(hash(1.00)) #1
8
9class A():
10 pass
11
12a=A()
13print(hash(a)) #-9223371894822596443
14print(hash(A)) #-9223371894822325386
15
16
17# list1=[1,2]
18# print(hash(list1)) #报错:TypeError: unhashable type: 'list'
19
20# set1=set([1,2])
21# print(hash(set1)) #报错:TypeError: unhashable type: 'set'
22
23# dict1={"a":1}
24# print(hash(dict1)) #报错:TypeError: unhashable type: 'dict'
25
26class Test:
27 def __init__(self, i):
28 self.i = i
29for i in range(10):
30 t = Test(1)
31 print(hash(t), id(t))
32
注:可应用于number、string和对象,不能直接应用于 list、set、dictionary;在 hash() 对对象使用时,所得的结果不仅和对象的内容有关,还和对象的 id(),也就是内存地址有关;可以让攻击者难以预测内置的set或者dict的一些行为,但远不足以承担真正的密码安全级别的hash的作用
**29.id(object):**返回对象的“标识值”(内存地址)。该值是一个整数,在此对象的生命周期中保证是
唯一且恒定的。两个生命期不重叠的对象可能具有相同的 id() 值
2
3
4
5
6
7
2b="a"
3c=[1,2]
4print(id(a)) #140708809987104
5print(id(b)) #2006140491904
6print(id(c)) #2006179152584
7
**30.input([prompt]):**如果存在 prompt 实参,则将其标准输出,末尾不带换行符。接下来,该函数从输入中读取一行,将其转换为字符串(除了末尾的换行符)并返回。当读取到 EOF 时,则触发 EOFError
2
3
4
5
6
7
8
9
10
11
12
13
2print(s)
3# --> hello nihao
4# hello nihao
5
6
7s=input()
8print(s)
9print(type(s))
10# 绝对舒服就多少
11# 绝对舒服就多少
12# <class 'str'>
13
注:如果加载了 readline 模块,input() 将使用它来提供复杂的行编辑和历史记录功能
**31.int(x, base=10):**返回一个使用数字或字符串 x 生成的整数对象
2
2
(1)若没有实参的时候返回 0
2
2
(2)对于浮点数,它向零舍入
2
3
4
2print(int(3.5)) #3
3print(int(3.9)) #3
4
(3)如果 x 定义了 int(),int(x) 返回 x.int() ;如果 x 定义了 trunc(),它返回 x.trunc() ;若x既定义了 int(),也定义了__trunc__(),貌似返回的是 x.int()
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
2 def __int__(self):
3 print("true aaa")
4 return 100 #若没定义,会报错:TypeError: __int__ returned non-int (type NoneType)
5
6a=A()
7int(a) #true aaa
8print(int(a)) #true aaa
9 #100
10
11class B():
12 def __trunc__(self):
13 print("true bbb")
14 return 500 #若没定义,会报错:TypeError: __int__ returned non-int (type NoneType)
15
16b=B()
17int(b) #true bbb
18print(int(b)) #true bbb
19 #500
20
21class C():
22 def __trunc__(self):
23 print("true kkk")
24 return 333 #若没定义,会报错:TypeError: __int__ returned non-int (type NoneType)
25
26 def __int__(self):
27 print("true aaa")
28 return 100 #若没定义,会报错:TypeError: __int__ returned non-int (type NoneType)
29
30c=C()
31int(c) #true aaa
32print(int(c)) #true aaa
33 #100
34
(4)如果 x 不是数字,或者有 base 参数,x 必须是字符串、bytes、表示进制为 base 的 整数字面值 的 bytearray 实例。
2
3
4
5
2print(int("12",16)) #18
3print(int("0xa",16)) #10
4print(int("11", 10)) #11
5
(5)该文字前可以有 + 或 – (中间不能有空格),前后可以有空格;一个进制为 n 的数字包含 0 到 n-1 的数,其中 a 到 z (或 A 到 Z )表示 10 到 35;默认的 base 为 10 ,允许的进制有 0、2-36;2、8、16 进制的数字可以在代码中用 0b/0B 、 0o/0O 、 0x/0X 前缀来表示;进制为 0 将安照代码的字面量来精确解释,最后的结果会是 2、8、10、16 进制中的一个,所以 int('010', 0) 是非法的,但 int('010') 和 int('010', 8) 是合法的
2
3
4
5
6
7
8
9
10
11
12
13
14
2print(int("-12",16)) #-18
3print(int(" +12 ",16)) #18
4
5print(int("+0xa",16)) #10
6print(int("-0xa",16)) #-10
7print(int(" -0xa ",16)) #-10
8
9print(int("+11", 10)) #11
10print(int("-11", 10)) #-11
11print(int(" -11 ", 10)) #-11
12
13# print(int("010",0)) #报错:ValueError: invalid literal for int() with base 0: '010'
14
注:x 现在只能作为位置参数。
**32.isinstance(object, classinfo):**如果 object 实参是 classinfo 实参的实例,或者是(直接、间接或 虚拟)子类的实例,则返回 true。如果
classinfo 是对象类型(或多个递归元组)的元组,如果 object 是其中的任何一个的实例则返回 true。 如果 classinfo 既不是类型,也不是类型元组或类型的递归元组,那么会触发 TypeError 异常
**33.issubclass(class, classinfo):**如果 class 是 classinfo 的子类(直接、间接或虚拟的),则返回 true。
classinfo 可以是类对象的元组,此时 classinfo 中的每个元素都会被检查。其他情况,会触发 TypeError 异常。
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
2print("[Hello]是否是str类的实例:",isinstance(hello, str)) #True
3print("[Hello]是否是object类的实例:",isinstance(hello, object)) #True
4print("[Hello]是否是tuple类的实例:",isinstance(hello, tuple)) #False
5print("[Hello]是否是(str,tuple,list)类的实例:",isinstance(hello, (str,tuple,list))) #True
6# print("[Hello]是否是object类的实例:",isinstance(hello, [str,tuple,list])) #报错:TypeError: isinstance() arg 2 must be a type or tuple of types
7
8# print("[Hello]是否是str类的子类:",issubclass(hello, str)) #报错:TypeError: issubclass() arg 1 must be a class
9# print("[Hello]是否是str类的子类:",issubclass(hello, object)) #报错:TypeError: issubclass() arg 1 must be a class
10
11print("[str]是否是str类的子类:",issubclass(str, str)) #True
12print("[str]是否是str类的子类:",issubclass(str, object)) #True
13print("[str]是否是str类的子类:",issubclass(str, tuple)) #False
14print("[str]是否是str类的子类:",issubclass(str, (str,tuple,list))) #True
15
16
17class A():
18 pass
19
20a=A()
21print("class[A]是否是A类的实例:",isinstance(A, A)) #False
22print("class[A]是否是object类的实例:",isinstance(A, object)) #True
23print("类实例[a]是否是A类的实例:",isinstance(a, A)) #True
24print("类实例[a]是否是object类的实例:",isinstance(a, object)) #True
25
26print("class[A]是否是A类的子类:",issubclass(A, A)) #True
27print("class[A]是否是object类的子类:",issubclass(A, object)) #True
28# print("类实例[a]是否是A类的子类:",issubclass(a, A)) #报错:TypeError: issubclass() arg 1 must be a class
29# print("类实例[a()]是否是A类的子类:",issubclass(a(),A)) #报错:TypeError: 'A' object is not callable
30# print("类实例[a()]是否是object类的子类:",issubclass(a(),object)) #报错:TypeError: 'A' object is not callable
31
32class B():
33 pass
34
35class C(A,B):
36 pass
37
38c=C()
39
40print("类实例[c]是否是A类的实例:",isinstance(c, A)) #True
41print("类实例[c]是否是B类的实例:",isinstance(c, B)) #True
42print("类实例[c]是否是object类的实例:类的实例:",isinstance(c, C)) #True
43print("类实例[c]是否是object类的实例:",isinstance(c, object)) #True
44print("class[C]是否是A类的实例:",isinstance(C, A)) #False
45print("class[C]是否是B类的实例:",isinstance(C, B)) #False
46print("class[C]是否是C类的实例:",isinstance(C, C)) #False
47print("class[C]是否是object类的实例:",isinstance(C, object)) #True
48
49print("class[C]是否是A类的子类:",issubclass(C, A)) #True
50print("class[C]是否是B类的子类:",issubclass(C, B)) #True
51print("class[C]是否是C类的实例:类的子类:",issubclass(C, C)) #True
52print("class[C]是否是object类的子类:",issubclass(C, object)) #True
53
通过上面程序可以看出,
issubclass() 和 isinstance() 两个函数的用法差不多,区别是:(1) issubclass() 的第一个参数是类名,isinstance() 的第一个参数是变量,因此:issubclass 用于判断是否为子类,而 isinstance() 用于判断是否为该类或子类的实例;(2)issubclass() 和 isinstance() 两个函数的第二个参数都可使用元组。
**34.iter(object[, sentinel]):**返回一个iterator对象;该方法的第一个参数object的参数类型,是根据有无第二个参数sentinel决定–>
若没有sentinel,object 必须是支持迭代协议(有 iter() 方法)的集合对象,或必须支持序列协议(有 getitem() 方法,且数字参数从 0 开始),如果它不支持这些协议,会触发 TypeError;
如果有sentinel,那么 object 必须是可调用的对象(如,函数)。这种情况下生成的迭代器,每次迭代调用它的 next() 方法时都会不带实参地调用 object;如果返回的结果等于sentinel,则触发 StopIteration,否则返回调用结果
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
2for i in iter(lst):
3 print(i) #1
4 #2
5 #3
6 #4
7 #5
8
9
10
11
12# for i in iter(lst,3): #报错:TypeError: iter(v, w): v must be callable
13# print(i)
14
15from random import randint
16cnt=1
17
18# guess(3)
19
20def guess():
21 return(randint(0,10))
22
23
24print(type(iter(guess,5))) #<class 'callable_iterator'>
25print(type(iter("sdfdf"))) #<class 'str_iterator'>
26
27for i in iter(guess,5):
28 print("Yes,第%s次猜测的数字是 : %s"%(cnt,i))
29 cnt+=1
30
**35.len(s):**返回对象s的长度(元素个数)。s可以是序列(如 string、bytes、tuple、list 或 range 等)或集合(如 dictionary、set 或 frozen set 等)
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
2print(len(str1)) #5
3
4byte1=b"123"
5print(len(byte1)) #3
6
7tuple1=(1,2,3,4,5)
8print(len(tuple1)) #5
9
10list1=[1,2,3,"a",(1,2)]
11print(len(list1)) #5
12
13range1=range(1,8)
14print(len(range1)) #7
15
16dict1={"a":1,"b":2}
17print(len(dict1)) #2
18
19set1={1,2,1,3}
20print(len(set1)) #3
21
**36.locals():**返回当前环境的局部变量
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
2print(locals()) #{'__name__': '__main__', '__doc__': None, '__package__': None, '__loader__': <_frozen_importlib_external.SourceFileLoader object at 0x0000017C7FEF3080>, '__spec__': None, '__annotations__': {}, '__builtins__': <module 'builtins' (built-in)>, '__file__': 'test.py', '__cached__': None, 'pymongo': <module 'pymongo' from 'D:\\Program Files (x86)\\Python\\V3.7.0\\lib\\site-packages\\pymongo\\__init__.py'>, 'datetime': <module 'datetime' from 'D:\\Program Files (x86)\\Python\\V3.7.0\\lib\\datetime.py'>, 'reduce': <built-in function reduce>, 'ctime': <built-in function ctime>}
3
4# 2.方法中
5out=1
6def run1(inside):
7 print(locals())
8
9# 结果中只有inside一个参数,它无法在方法体内获取到外面的全局变量out
10run1(3) #{'inside': 3}
11
12
13def run(inside1,inside2):
14 print(locals())
15
16run(8,7) #{'inside1': 8, 'inside2': 7}
17
18# 3.类方法中
19class A():
20 a=1
21 b=2
22 print(locals()) #{'__module__': '__main__', '__qualname__': 'A', 'a': 1, 'b': 2}
23
24 def run(self):
25 print(locals())
26
27a=A()
28
29#结果只有self,甚至连类声明的属性a和b都是无法获取到的
30a.run() #{'self': <__main__.A object at 0x000001D0621B0A58>}
31
**37.map(function, iterable, …):**返回一个将 function 应用于 iterable(iterable开始,其后的都是可迭代对象,列表,元祖,迭代器等,换句话说:能执行 for x in param:语句的都可以)中每一项并输出其结果的
迭代器。 如果传入了额外的 iterable 参数,function 必须接受相同个数的实参并被应用于从所有可迭代对象中并行获取的项,即,map参数个数为x个,function个数为x-1个,否则会报错
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
2 return x*x
3
4list1=[1,2,3,4,5]
5list2=[6,7,8,9,10,11,12]
6list3=[20,21,22,23]
7list4=[1,2,3]
8list5=[6,7]
9list6=[20]
10
11square=list(map(lambda x:x**2,list1))
12print(square) #[1, 4, 9, 16, 25]
13
14tuple1=(1,2,3,4,5)
15square=list(map(lambda x:x**2,tuple1))
16print(square) #[1, 4, 9, 16, 25]
17
18print(map(f1,list1)) #<map object at 0x000001F0E5670A58>
19print(list(map(f1,list1))) #[1, 4, 9, 16, 25]
20print(tuple(map(f1,list1))) #(1, 4, 9, 16, 25)
21
当有多个可迭代对象时,最短的可迭代对象耗尽则整个迭代就将结束
2
3
4
5
6
2 return x+y+z
3# print(list(map(f2,list1))) #报错:TypeError: f2() missing 2 required positional arguments: 'y' and 'z'
4print(list(map(f2,list1,list2,list3))) #[27, 30, 33, 36]
5print(list(map(f2,list4,list5,list6))) #[27]
6
38.max(iterable, *[, key, default])
** max(arg1, arg2, *args[, key]):**返回可迭代对象中最大的元素;默认数值型参数,取值大者;字符型参数,取字母表排序靠后者;还可以传入命名参数key,其为一个函数,用来指定取最大值的方法;default命名参数用来指定最大值不存在时返回的默认值
(1)只传入一个参数,该参数必须为可迭代的对象,不能为空
2
3
4
5
6
2print(max({'x':1,'y':2,'z':10})) #z
3print(max(list1)) #5
4print(max(list2)) #12.1
5print(max(tuple1)) #4
6
(2)当传入参数数据类型不一致时,传入的参数会进行隐式数据类型转换,如果不能进行隐式转换就会报错
2
3
4
5
6
2print(max(list1,list2)) #[6, 7, 8, 9, 10, 11, 12, 12.1]
3print(max(list1,list7)) #[1, 2, 3, 4, 5, 5.0]
4print(max(list1,list8)) #[1, 2, 3, 4, 5, 5.0]
5print(max(list1,list9)) #[1, 2, 3, 4, 5, 5.0]
6
(3)当存在多个相同的最大值时,返回的是最先出现的那个最大值
2
3
4
5
6
7
8
9
10
11
12
13
2b=[1,1]
3c=[1,2]
4print(id(a)) #2191192589320
5print(id(b)) #2191194430024
6print(id(c)) #2191193972168
7
8d=max(a,b,c)
9print(d) #[1, 2]
10print(id(d)) #2191192589320
11print(id(a)==id(d)) #True
12print(id(c)==id(d)) #False
13
(4)可以传入命名参数 key,指定取最大值的方法
2
3
2print(max(-1,-5,key=abs)) #-5
3
key另一个作用是:原本数据类型不一致,不能进行比较的,传入适当的key就可以比较
2
2
(5)空的可迭代对象不能进行比较,必须传入一个默认值,否则会触发ValueError
2
3
4
5
2# # # print(max([])) #报错:ValueError: max() arg is an empty sequence
3print(max((),default=1)) #1
4print(max((),default=0)) #0
5
默认值必须用命名参数进行传参,否会被认为是一个比较的元素
2
2
**39.memoryview(obj):**返回由obj创建的“内存视图”对象,memoryview对象允许 Python 代码访问一个对象的内部数据,只要该对象支持“缓冲区协议”,而无需进行拷贝;支持缓冲区协议的内置对象包括 bytes 和 bytearray
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
2a=bytearray(b"aaaaa")
3b=a[:2]
4print(b) #bytearray(b'aa')
5print(id(a[:2])) #2386588274224
6print(id(b)) #2386588273160
7b[:2]=b"bb"
8print(a) #bytearray(b'aaaaa')
9print(b) #bytearray(b'bb')
10
11# 2.使用memoryview
12a=bytearray(b"aaaaa")
13ma=memoryview(a)
14print(ma.readonly) #False
15mb=ma[:2]
16mb[:2]=b"bb"
17print(ma.tobytes()) #b'bbaaa'
18print(mb.tobytes()) #b'bb'
19
str和bytearray的切片操作会产生新的切片str和bytearry并拷贝数据,使用memoryview之后不会
**40.min(iterable, *[, key, default])
min(arg1, arg2, *args[, key]):**返回可迭代对象中最小的元素;默认数值型参数,取值小者;字符型参数,取字母表排序靠前者;还可以传入命名参数key,其为一个函数,用来指定取最小值的方法;default命名参数用来指定最小值不存在时返回的默认值
(1)只传入一个参数,该参数必须为可迭代的对象,不能为空
2
3
4
5
6
2print(min({'x':1,'y':2,'z':10})) #x
3print(min(list1)) #1
4print(min(list2)) #6
5print(min(tuple1)) #1
6
(2)当传入参数数据类型不一致时,传入的参数会进行隐式数据类型转换,如果不能进行隐式转换就会报错
2
3
4
5
6
2print(min(list1,list2)) #[1, 2, 3, 4, 5, 5.0]
3print(min(list1,list7)) #[1, 2, 3, 4, 5]
4print(min(list1,list8)) #[1, 2, 3, 4, 5, 5.0]
5print(min(list1,list9)) #[1, 2, 3, 4, 5, -1]
6
(3)当存在多个相同的最小值时,返回的是最先出现的那个最小值
2
3
4
5
6
7
8
9
10
11
12
13
2b=[1,2]
3c=[1,1]
4print(id(a)) #2264057461384
5print(id(b)) #2264057461896
6print(id(c)) #2264057416008
7
8d=min(a,b,c)
9print(d) #[1, 1]
10print(id(d)) #2264057461384
11print(id(a)==id(d)) #True
12print(id(c)==id(d)) #False
13
(4)可以传入命名参数 key,指定取最小值的方法
2
3
2print(min(-1,-5,key=abs)) #-1
3
key另一个作用是:原本数据类型不一致,不能进行比较的,传入适当的key就可以比较
2
2
(5)空的可迭代对象不能进行比较,必须传入一个默认值,否则会触发ValueError
2
3
4
5
2# print(min([])) #报错:ValueError: min() arg is an empty sequence
3print(min((),default=1)) #1
4print(min((),default=0)) #0
5
默认值必须用命名参数进行传参,否会被认为是一个比较的元素
2
2
**41.next(iterator[, default]):**通过调用iterator 的 next() 方法获取下一个元素;如果迭代器耗尽,则返回给定的 default,如果没有default,则触发 StopIteration
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
2a=iter(s1)
3print(next(a)) #a
4print(next(a)) #b
5print(next(a)) #c
6# print(next(a)) #报错:StopIteration
7
8s1="abc"
9a=iter(s1)
10print(next(a)) #a
11print(next(a)) #b
12print(next(a)) #c
13print(next(a,"默认值1")) #默认值1
14print(next(a,"默认值2")) #默认值2
15print(next(a,"默认值3")) #默认值3
16
**42.open(file, mode='r', buffering=-1, encoding=None, errors=None, newline=None, closefd=True, opener=None):**打开 file 并返回对应的 file object。如果该文件不能打开,则触发 OSError
(1)
file:表示将要打开的文件的路径(绝对路径或者当前工作目录的相对路径),也可以是要被封装的整数类型文件描述符;如果是文件描述符,它会随着返回的 I/O 对象关闭而关闭,除非 closefd 被设为 False ;
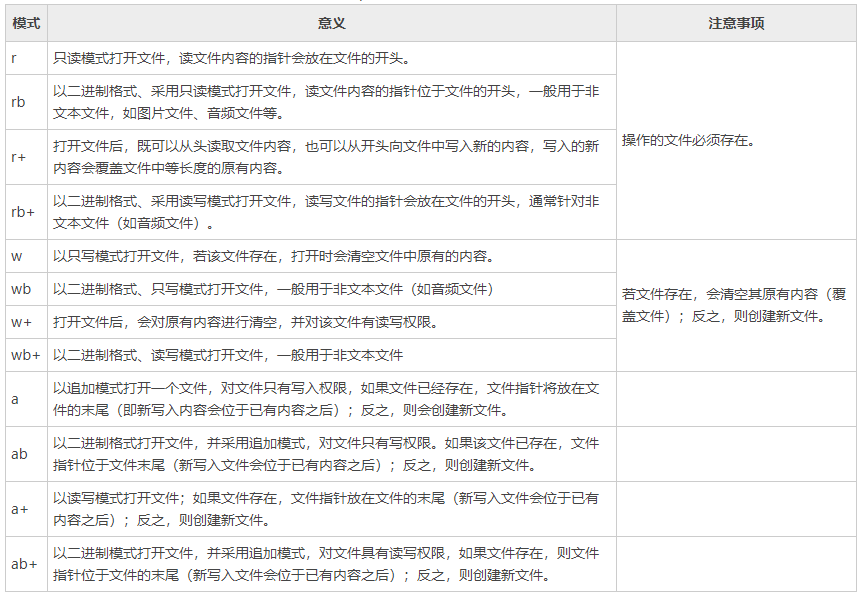
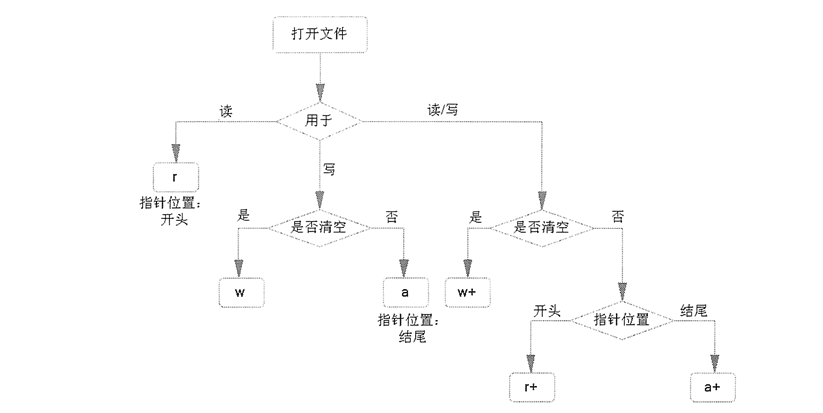
(2)
mode:指定打开文件的模式,默认值是 'r' ,如下图,具体不同mode值不同的意义
用流程图表示:
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
2with open(file_path,"r") as f:
3 data=f.readlines()
4 print(data) #['aaa\n', '的说法就是懒得加发烧\n', '沙发上地方\n', '地方开始发鸡蛋的\n', '\n', '打开方式\n', '独守空房\n', '收发点']
5 f.close()
6
7#"w",文件会先被清空
8with open(file_path,"w") as f:
9 # data=f.readlines() #报错:io.UnsupportedOperation: not readable
10 f.writelines(text1)
11 f.writelines(text2)
12with open(file_path) as f:
13 data=f.readlines()
14 print(data) #['abc\n', '但是\n']
15 f.close()
16
17# "x"
18with open(file_path,"x") as f: #报错:FileExistsError: [Errno 17] File exists: 'F:\\/test.txt'
19
20with open(file_path1,"x") as f:
21 f.writelines(text1)
22 f.writelines(text2)
23with open(file_path) as f:
24 data=f.readlines()
25 print(data) #['abc\n', '但是\n']
26 f.close()
27
28#"a"
29with open(file_path,"a",encoding="utf-8") as f:
30 f.writelines(text1)
31 f.writelines(text2)
32with open(file_path,encoding="utf-8") as f:
33 data=f.readlines()
34 print(data) #['锄禾日当午,汗滴禾下土。\n', 'abc\n', '但是\n']
35 f.close()
36
37#"a+"
38with open(file_path,"a+",encoding="utf-8",buffering=1) as f:
39 f.writelines(text1)
40 f.writelines(text2)
41with open(file_path,encoding="utf-8") as f:
42 data=f.readlines()
43 print(data) #['锄禾日当午,汗滴禾下土。\n', 'abc\n', '但是\n']
44 f.close()
45
46#"r+"
47with open(file_path,"r+",encoding="utf-8") as f:
48 f.writelines(text1)
49 f.writelines(text2)
50 data=f.readlines() #开始一直在这报错:UnicodeDecodeError: 'utf-8' codec can't decode byte 0xb9 in position 13: invalid start byte
51 #将文件另存为,把编码格式改为“utf-8”即可
52 print(data) #['\ufeff锄禾日当午,汗滴禾下土。\n']
53 f.close()
54
(3)
buffering:是一个可选的整数,用于设置缓冲策略。传递0以切换缓冲关闭(仅允许在二进制模式下),1选择行缓冲(仅在文本模式下可用),并且>1的整数以指示固定大小的块缓冲区的大小(以字节为单位)。如果没有给出 buffering 参数,则默认缓冲策略的工作方式如下:
1)二进制文件以固定大小的块进行缓冲;使用启发式方法选择缓冲区的大小,尝试确定底层设备的“块大小”或使用 io.DEFAULT_BUFFER_SIZE。在许多系统上,缓冲区的长度通常为4096或8192字节
2)“交互式”文本文件( isatty() 返回 True 的文件)使用行缓冲。其他文本文件使用上述策略用于二进制文件
(4)
encoding:是用于解码或编码文件的编码的名称,这应该只在文本模式下使用
(5)
errors:是一个可选的字符串参数,用于指定如何处理编码和解码错误 ,但不能在二进制模式下使用
(6)
newline:区分换行符,可以是 None,'','\n','\r' 和 '\r\n'
(7)
closefd :如果 closefd 是 False 并且给出了文件描述符而不是文件名,那么当文件关闭时,底层文件描述符将保持打开状态;如果给出文件名则 closefd 必须为 True (默认值),否则将引发错误
(8)
opener:可以通过传递可调用的 opener 来使用自定义开启器。然后通过使用参数( file,flags )调用 opener 获得文件对象的基础文件描述符。 opener 必须返回一个打开的文件描述符(使用 os.open as opener 时与传递 None 的效果相同)。
**43.pow(base, exp[, mod]):**返回的是base的 exp 次幂, pow(base, exp) 等价于base**exp
2
3
4
5
2print(pow(2,-3)) #0.125
3print(pow(2,1.3)) #2.4622888266898326
4print(pow(1.2,3)) #1.7279999999999998
5
(1)对于 int 操作数 base 和 exp,如果mod存在,则返回 base 的 exp 次幂对 mod 取余(比 pow(base, exp) % mod 更高效),但是mod必须为整数,不能为0,并且base和exp都必须为整数
2
3
4
5
6
7
8
9
2# print(pow(2,3,0)) #报错:ValueError: pow() 3rd argument cannot be 0
3print(pow(2,3,-4)) #0
4print(pow(2,3,1.1)) #报错:TypeError: pow() 3rd argument not allowed unless all arguments are integers
5
6print(pow(-2,3,-4)) #0
7# print(pow(2,3,1.1)) #报错:TypeError: pow() 3rd argument not allowed unless all arguments are integers
8# print(pow(2,1.3,4)) #报错:TypeError: pow() 3rd argument not allowed unless all arguments are integers
9
(2)在3.7版本中,如果给出 mod,则exp不能为负数,否则报错
2
3
4
5
6
7
8
2# print(pow(2,-3,-4)) #报错:ValueError: pow() 2nd argument cannot be negative when 3rd argument specified
3
4# print(pow(2,-3,-4)) #报错:ValueError: pow() 2nd argument cannot be negative when 3rd argument specified
5# print(pow(-2,-3,-4)) #报错:ValueError: pow() 2nd argument cannot be negative when 3rd argument specified
6# print(pow(2,-3,3)) #报错:ValueError: pow() 2nd argument cannot be negative when 3rd argument specified
7# print(pow(9,-3,3)) #报错:ValueError: pow() 2nd argument cannot be negative when 3rd argument specified
8
注:
(1)在 3.8 版更改:对于 int 操作数,三参数形式的 pow 现在允许第二个参数为负值,即可以计算倒数的余数;如果给出 mod 并且 exp 为负值,则 base 必须相对于 mod 不可整除。 在这种情况下,将会返回 pow(inv_base, -exp, mod),其中 inv_base 为 base 的倒数对 mod 取余
(2)在 3.9 版更改:允许关键字参数。 之前只支持位置参数
**44.print(*objects, sep=' ', end='\n', file=sys.stdout, flush=False):**file如果给出,将 objects 打印到 file 指定的文本流,以 sep 分隔并在末尾加上 end;否则就打印到屏幕上
2
3
4
5
6
7
8
2
3print("A","b","c", sep=' ** ') #A ** b ** c
4
5print("A","b","c", end=' !!\n') #A b c !!
6
7print("A","b","c", sep=' ** ', end=' !!\n') #A ** b ** c !!
8
(1)
sep, end, file 和 flush 如果存在,必须以关键字参数的形式给出
(2)所有非关键字参数(object)都会被转换为字符串,会被写入到流,以sep且在末尾加上 end,sep 和 end 都必须为字符串;它们也可以为 None,即,使用默认值
(3)如果没有给出 objects,则 print() 将只写入 end
2
3
4
5
6
2
3print(end=' !!\n') # !!
4
5print(sep=' ** ', end=' !!\n') # !!
6
(4)file 参数必须是一个具有 write(string) 方法的对象;如果参数不存在或为 None,则将使用 sys.stdout,
但如果使用了file,待打印文本就会输出到指定文件,而不是打印到屏幕上
2
3
2print(open('1.txt', 'r').read()) #A ** b ** c !
3
(5)由于要打印的参数会被转换为文本字符串,因此 print() 不能用于二进制模式的文件对象。 对于这些对象,应改用 file.write(…)
(6)输出是否被缓存通常决定于 file,但如果 flush 关键字参数为真值,流会被强制刷新。
在 3.3 版更改: 增加了 flush 关键字参数。
**45.class property(fget=None, fset=None, fdel=None, doc=None):**在新式类中返回属性值,其中,fget 是获取属性值的函数,fset 是用于设置属性值的函数,fdel 是用于删除属性值的函数,并且 doc 为属性对象创建文档字符串。
这么说明比较抽象,拿个例子来说:一般我们写类的时候,对于属性如果直接暴露出去,虽然写法简单,但是对于参数无法进行检查:
2
3
4
5
6
7
8
9
10
2class Goods:
3 def __init__(self):
4 self.p = 18
5
6obj=Goods()
7print(obj.p) #18
8obj.p="aa"
9print(obj.p) #aa
10
为了限制price的范围,可以通过一个set_price()方法来设置价格,再通过一个get_price()来获取价格,这样,在set_price()方法里,就可以检查参数:
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
2 def __init__(self):
3 self._p=100
4 # pass
5
6 def get_price(self):
7 return self._p
8
9 def set_price(self,value):
10 if not isinstance(value,int):
11 raise ValueError("价格必须为整数")
12 self._p=value
13
14 def del_price(self):
15 del self._p
16
17 # PRICE=property(get_price,set_price,del_price,"价格属性的描述。。。")
18
19obj=Goods()
20print(obj.get_price()) #100
21obj.set_price(200)
22print(obj.get_price()) #200
23obj.set_price("abc")
24# print(obj.get_price()) #报错:raise ValueError("价格必须为整数") ValueError: 价格必须为整数
25
但是,上面的调用方法又略显复杂,没有直接用属性这么直接简单,对于类的方法,装饰器一样起作用。Python内置的@property装饰器就是负责把一个方法变成属性调用的:
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
2 def __init__(self):
3 self._p = 18
4
5 @property
6 def price(self): # 读取
7 """属性属性属性"""
8 return self._p
9
10 # 方法名.setter
11 @price.setter # 设置,仅可接收除self外的一个参数,必须加上“price.”,否则报错:NameError: name 'setter' is not defined
12 def price(self, value):
13 if not isinstance(value,int):
14 raise ValueError("价格必须为整数")
15 self._p = value
16
17 # 方法名.deleter
18 @price.deleter # 删除
19 def price(self):
20 del self._p
21
22obj=Goods()
23print(obj.price) #18
24obj.price=22
25print(obj.price) #22
26# obj.price="a"
27# print(obj.price) #报错:raise ValueError("价格必须为整数") ValueError: 价格必须为整数
28del obj.price
29# print(obj.price) #报错:AttributeError: 'Goods' object has no attribute '_p'
30
把一个getter方法变成属性,只需要加上@property就可以了,此时,@property本身又创建了另一个装饰器@price.setter
**46.range(stop)
range(start, stop[, step]):**迭代器,为不可变的数字序列
(1)当只提供1个参数时,为stop,
start默认为0
2
2
(2)提供2个参数时,为start和stop,
step默认为1
2
3
4
5
2print(list(range(1,10))) #[1, 2, 3, 4, 5, 6, 7, 8, 9]
3print(list(range(10,1))) #[]
4print(list(range(10,2))) #[]
5
(3)提供3个参数时,如果step为0会触发异常
2
3
4
5
2print(list(range(0,10,2))) #[0, 2, 4, 6, 8]
3print(list(range(0,-10,-1))) #[0, -1, -2, -3, -4, -5, -6, -7, -8, -9]
4# print(list(range(0,10,0))) #报错 ValueError: range() arg 3 must not be zero
5
(4)提供如包含
检测、元素索引查找、切片等特性,并支持负索引
2
3
4
5
6
2print(11 in r) #False
3print(10 in r) #True
4print(r.index(6)) #3
5print(r[-1]) #18
6
(5)使用 == 和 != 检测 range 对象是否相等是将其作为序列来比较;如果两个 range 对象表示相同的值序列就认为它们是相等的(注:比较结果相等的两个 range 对象可能会具有不同的 start, stop 和 step 属性)
2
3
4
5
6
2print(list(range(2,1,3))) #[]
3print((range(0)==range(2,1,3))) #True
4print((range(0,3,2)==range(0,4,2))) #True
5print((range(0,3,2)!=range(0,4,2))) #False
6
(6)range 类型相比常规 list 或 tuple 的优势在于一个 range 对象总是
占用固定数量的(较小)内存,不论其所表示的范围有多大(因为它只保存了 start, stop 和 step 值,并会根据需要计算具体单项或子范围的值)
**47.repr(object):**返回包含一个对象的可打印表示形式的字符串, 对于许多类型来说,该函数会尝试返回的字符串将会与该对象被传递给 eval() 时所生成的对象具有相同的值
2
3
4
2# print(eval(s)) #报错NameError: name 'abc' is not defined
3print(eval(repr(s))) #abc
4
**48.reversed(seq):**返回一个反向的 iterator,原seq并不会改变
2
3
4
5
2print(list(reversed(s))) #['e', 'd', 'c', 'b', 'a']
3print(reversed(s)) #<reversed object at 0x000001B6080FCF28>
4print(s) #abcde
5
(1) 若序列反转赋值,第2次打印序列,会有空的现象
2
3
4
5
6
7
8
9
10
11
12
13
2print(list(reversed(s))) #['t', 'g', 'f', 'e', 'a']
3print(list(reversed(s))) #['t', 'g', 'f', 'e', 'a']
4
5
6s="aefgt"
7ss=reversed(s)
8print(s) #aefgt
9print(list(ss)) #['t', 'g', 'f', 'e', 'a']
10print(list(ss)) #[]
11
12#其原因就是ss不是反转列表本身,而是一个列表反向迭代器。所以当你第一次调用列表(ss),它会遍历ss并且创建一个新的列表从项目输出迭代器。当你再进行一次,ss仍然是原来的迭代器,已经经历了所有的项目,所以它不会再遍历什么,这就造成了空列表
13
即,
reversed()赋值后,只在第一次遍历时返回值
(2)seq 若无__reversed__() 方法的对象,则必须是支持该序列协议(具有从 0 开始的整数类型参数的 len() 方法和 getitem() (object.getitem(self, key)以实现 self[key] 的求值)方法)
2
3
4
5
6
7
8
9
10
11
2 def __len__(self):
3 return 6
4 def __getitem__(self, key):
5 return 'y{0}'.format(key)
6
7print(MySeq()[3]) #y3
8
9for item in reversed(MySeq()):
10 print(item, end=', ') #y5, y4, y3, y2, y1, y0,
11
(3)也可以自定义重写该方法
2
3
4
5
6
7
8
9
10
11
12
2 def __len__(self):
3 return 6
4 def __getitem__(self, index):
5 return 'y{0}'.format(index)
6class MyReversed(MySeq):
7 def __reversed__(self):
8 return reversed('hello, bright!')
9
10for item in reversed(MyReversed()):
11 print(item, end=' ') #! t h g i r b , o l l e h
12
(4)如果reversed()的参数不是一个序列对象,我们应该为该对象定义一个__reversed__方法,这个时候就可以使用reversed()函数
2
3
4
5
6
7
8
9
10
11
12
13
14
15
2 def __init__(self, name, *args):
3 self.name = name
4 self.scores = []
5 for value in args:
6 self.scores.append(value)
7
8 def __reversed__(self):
9 self.scores = reversed(self.scores)
10
11x = MyScore("Ann", 66, 77, 88, 99, 100)
12
13print('我的名字: {0}, 我的成绩: {1}'.format(x.name, x.scores)) #我的名字: Ann, 我的成绩: [66, 77, 88, 99, 100]
14print('我的成绩按倒序排列:{}'.format(list(reversed(x.scores)))) #我的成绩按倒序排列:[100, 99, 88, 77, 66]
15
**49.round( x [, n] ):**返回浮点数x的四舍五入值,其中
n默认为0,表示精度
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
2print(round(a)) #123
3a=123.4
4print(round(a)) #123
5a=123.5
6print(round(a)) #124
7a=123.6
8print(round(a)) #124
9a=123.9
10print(round(a)) #124
11a=123.11
12print(round(a)) #123
13a=123.15
14print(round(a)) #123
15a=123.51
16print(round(a)) #124
17a=123.55
18print(round(a)) #124
19
20a=123.11
21print(round(a,1)) #123.1
22a=123.15
23print(round(a,1)) #123.2
24a=123.51
25print(round(a,1)) #123.5
26a=123.55
27print(round(a,1)) #123.5
28a=123.56
29print(round(a,1)) #123.6
30a=123.541
31print(round(a,1)) #123.5
32a=123.545
33print(round(a,1)) #123.5
34a=123.549
35print(round(a,1)) #123.5
36a=123.551
37print(round(a,1)) #123.6
38a=123.555
39print(round(a,1)) #123.6
40a=123.559
41print(round(a,1)) #123.6
42
43a=123.541
44print(round(a,2)) #123.54
45a=123.545
46print(round(a,2)) #123.55
47a=123.549
48print(round(a,2)) #123.55
49a=123.551
50print(round(a,2)) #123.55
51a=123.555
52print(round(a,2)) #123.56
53a=123.559
54print(round(a,2)) #123.56
55
56
57a=123.5414
58print(round(a,3)) #123.541
59a=123.5415
60print(round(a,3)) #123.541
61a=123.5419
62print(round(a,3)) #123.542
63
64
65a=123.54145
66print(round(a,3)) #123.541
67a=123.54146
68print(round(a,3)) #123.541
69a=123.54149
70print(round(a,3)) #123.541
71
**50.setattr(object, name, value):**用于设置属性值,该属性不一定是存在的
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
2 bar=1
3
4print(getattr(A, "bar")) #1
5setattr(A, "bar","new")
6print(getattr(A, "bar")) #new
7setattr(A, "aa","hahaha")
8print(getattr(A, "aa")) #hahaha
9
10
11a=A()
12print(getattr(a, "bar")) #new
13setattr(a, "bar","newnew")
14print(getattr(a, "bar")) #newnew
15setattr(a, "aa","dododo")
16print(getattr(a, "aa")) #dododo
17
(1)针对类,如果
getattr方法是传参形式,setattr不起效
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
2 def p(self):
3 print("hello")
4
5 @classmethod
6 def q(cls):
7 print("world")
8
9a=A()
10
11c=getattr(a, "p")
12c() #hello
13setattr(A, "p","xinpp")
14print(getattr(a, "p")) #xinpp
15c() #hello
16
17c=getattr(A, "q")
18c() #world
19setattr(A, "q","xinq")
20c() #world
21print(getattr(A, "q")) #xinq
22
**51.class slice(stop)
class slice(start, stop[, step]):**实现切片对象,主要用在切片操作函数里的参数传递,其中,start — 起始位置,stop — 结束位置,step — 间距
2
3
4
5
6
7
8
9
10
11
2print(myslice) #slice(None, 3, None)
3
4L=[1,2,3,4,5,6,7,8,9,10]
5print(L[myslice]) #[1, 2, 3]
6print(L[0:3]) #[1, 2, 3]
7
8myslice=slice(1,7,2)
9print(L[myslice]) #[2, 4, 6]
10print(L[1:7:2]) #[2, 4, 6]
11
**52.sorted(iterable, *, key=None, reverse=False):**排序,返回新的排序列表,不会改变原对象,具体可见https://blog.csdn.net/grace666/article/details/103261144
**53.@staticmethod:**将方法转换为静态方法,静态方法不会接收隐式的第一个参数。要声明一个静态方法,具体可见https://blog.csdn.net/grace666/article/details/100990469
**54.class str(object='')
class str(object=b'', encoding='utf-8', errors='strict'):**返回 object 的 字符串 版本
(1)如果未提供 object 则返回空字符串
2
3
2print(s1)
3
(2)如果 encoding 或 errors 均未给出,str(object) 返回 object.str(),这是 object 的“非正式”或格式良好的字符串表示。 对于字符串对象,这是该字符串本身。 如果 object 没有 str() 方法,则 str() 将回退为返回 repr(object)–具体可参考https://blog.csdn.net/grace666/article/details/103334640
(3)如果 encoding 或 errors 至少给出其中之一,则 object 应该是一个 bytes-like object (例如 bytes 或 bytearray)。 在此情况下,如果 object 是一个 bytes (或 bytearray) 对象,则 str(bytes, encoding, errors) 等价于 bytes.decode(encoding, errors)。 否则的话,会在调用 bytes.decode() 之前获取缓冲区对象下层的 bytes 对象
2
3
4
5
6
7
8
9
2print(str(s1)) #b'Zoot!'
3
4s1="aaa"
5print(str(s1,encoding="utf-8")) #报错;TypeError: decoding str is not supported
6
7s1=b"aaa"
8print(str(s1,encoding="utf-8")) #aaa
9
**55.sum(iterable, /, start=0):**从 start 开始自左向右对 iterable 的项求和并返回总计值。 iterable 的项通常为数字,而start是指定相加的参数,默认为0
2
3
4
5
6
7
8
9
10
11
12
13
2print(sum(l1)) #15
3print(sum(l1,1)) #16
4
5t1=(1,2,3,4,5)
6print(sum(t1)) #15
7print(sum(t1,1)) #16
8
9
10d1={1,2,3,4,5}
11print(sum(d1)) #15
12print(sum(d1,1)) #16
13
**56.super([type[, object-or-type]]):**返回一个代理对象,它会将方法调用委托给 type 的父类或兄弟类
(1)单继承,主要用来调用父类的方法
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
2 def __init__(self):
3 self.n=2
4
5 def plus(self,m):
6 print("A类的plus方法")
7 self.n+=m
8
9class B(A):
10 def __init__(self):
11 self.n=3
12
13 def plus(self,m):
14 print("B类的plus方法")
15 super().plus(m)
16
17 self.n+=3
18
19b=B()
20b.plus(5) #B类的plus方法
21 #A类的plus方法
22print(b.n) #11
23
super() 只传递一个参数时,是一个不绑定的对象,不绑定的话它的方法是不会有用的
(2)多重继承
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
2 def __init__(self):
3 self.n=2
4
5 def plus(self,m):
6 print("A类的plus方法")
7 self.n+=m
8
9class B(A):
10 def __init__(self):
11 self.n=3
12
13 def plus(self,m):
14 print("B类的plus方法")
15 super().plus(m)
16 self.n+=4
17
18class C(B):
19 def __init__(self):
20 self.n=5
21
22 def plus(self,m):
23 print("C类的plus方法")
24 super().plus(m)
25 self.n+=6
26
27class D(C):
28 def __init__(self):
29 self.n=7
30
31 def plus(self,m):
32 print("D类的plus方法")
33 super().plus(m)
34 self.n+=8
35
36
37d=D()
38d.plus(5) #D类的plus方法
39 #C类的plus方法
40 #B类的plus方法
41 #A类的plus方法
42print(d.n) #30
43print(D.mro()) #[<class '__main__.D'>, <class '__main__.C'>, <class '__main__.B'>, <class '__main__.A'>, <class 'object'>]
44
(3)多继承
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
2 def __init__(self):
3 self.n=2
4
5 def plus(self,m):
6 print("A类的plus方法")
7 self.n+=m
8
9class B(A):
10 def __init__(self):
11 self.n=3
12
13 def plus(self,m):
14 print("B类的plus方法")
15 super().plus(m)
16 self.n+=4
17
18class C(A):
19 def __init__(self):
20 self.n=5
21
22 def plus(self,m):
23 print("C类的plus方法")
24 super().plus(m)
25 self.n+=6
26
27class D(B,C):
28 def __init__(self):
29 self.n=7
30
31 def plus(self,m):
32 print("D类的plus方法")
33 super().plus(m)
34 self.n+=8
35
36
37d=D()
38d.plus(5) #D类的plus方法
39 #B类的plus方法
40 #C类的plus方法
41 #A类的plus方法
42print(d.n) #30
43print(D.mro()) #[<class '__main__.D'>, <class '__main__.B'>, <class '__main__.C'>, <class '__main__.A'>, <class 'object'>]
44
以上可总结为:调用了父类的方法,出入的是子类的实例对象;新式类子类(A,B),A就在B之前进行搜索;super是一种类,类似于嵌套的一种设计,当代码执行到super实例化后,先去找同级父类,若没有其余父类,再执行自身父类,再往下走;所有类不重复调用,从左到右
(4)
super(type):只传递一个参数的时候,是一个不绑定的对象,其方法是不会有用的
如下例子,只是执行了D的init方法
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
2 def __init__(self):
3 print('Base.__init__')
4
5
6class A(Base):
7 def __init__(self):
8 super().__init__()
9 print('A.__init__')
10
11
12class B(Base):
13 def __init__(self):
14 super().__init__()
15 print('B.__init__')
16
17
18class C(Base):
19 def __init__(self):
20 super().__init__()
21 print('C.__init__')
22
23
24class D(A, B, C):
25 def __init__(self):
26 super(B).__init__() # 值传递一个参数,无论传A/B/C/D,都只执行了D的init方法
27 print('D.__init__')
28
29
30D() #D.__init__
31print(D.mro()) #[<class '__main__.D'>, <class '__main__.A'>, <class '__main__.B'>, <class '__main__.C'>, <class '__main__.Base'>, <class 'object'>]
32
(5)
super(type,obj):传递两个参数的时候,如果第二个参数为一个对象,则 isinstance(obj, type) 必须为真值,如果 object-or-type 的 mro 为 D -> B -> C -> A -> object 并且 type 的值为 B,则 super() 将会搜索 C -> A -> object
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
2 def __init__(self):
3 print('Base.__init__')
4
5
6class A(Base):
7 def __init__(self):
8 super().__init__()
9 print('A.__init__')
10
11
12class B(Base):
13 def __init__(self):
14 super().__init__()
15 print('B.__init__')
16
17
18class C(Base):
19 def __init__(self):
20 super().__init__()
21 print('C.__init__')
22
23
24class D(A, B, C):
25 def __init__(self):
26 super(B,self).__init__() # 值传递一个参数
27 print('D.__init__')
28
29
30D() #Base.__init__
31 #C.__init__
32 #D.__init__
33print(D.mro()) #[<class '__main__.D'>, <class '__main__.A'>, <class '__main__.B'>, <class '__main__.C'>, <class '__main__.Base'>, <class 'object'>]
34
(6)
super(type1,type2):传递两个参数的时候,如果第二个参数为一个类型,则 issubclass(type2, type) 必须为真值,如果 object-or-type 的 mro 为 D -> B -> C -> A -> object 并且 type 的值为 B,则 super() 将会搜索 C -> A -> object
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
2 def __init__(self):
3 print('Base.__init__')
4
5
6class A(Base):
7 def __init__(self):
8 super().__init__()
9 print('A.__init__')
10
11
12class B(Base):
13 def __init__(self):
14 super().__init__()
15 print('B.__init__')
16
17
18class C(Base):
19 def __init__(self):
20 super().__init__()
21 print('C.__init__')
22
23
24class D(A, B, C):
25 def __init__(self):
26 super(B,D).__init__(self) # D是B的子类,并且需要传递一个参数
27 print('D.__init__')
28
29
30D() #Base.__init__
31 #C.__init__
32 #D.__init__
33print(D.mro()) #[<class '__main__.D'>, <class '__main__.A'>, <class '__main__.B'>, <class '__main__.C'>, <class '__main__.Base'>, <class 'object'>]
34
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
2 def __init__(self):
3 print('Base.__init__')
4
5
6class A(Base):
7 def __init__(self):
8 super().__init__()
9 print('A.__init__')
10
11
12class B(Base):
13 def __init__(self):
14 super().__init__()
15 print('B.__init__')
16
17
18class C(Base):
19 def __init__(self):
20 super().__init__()
21 print('C.__init__')
22
23
24class D(A, B, C):
25 def __init__(self):
26 super(Base,B).__init__(self)
27 print('D.__init__')
28
29
30D() #D.__init__
31print(D.mro()) #[<class '__main__.D'>, <class '__main__.A'>, <class '__main__.B'>, <class '__main__.C'>, <class '__main__.Base'>, <class 'object'>]
32
**57.tuple([iterable]):**是一个不可变的序列类型,具体可参考https://blog.csdn.net/grace666/article/details/98079075
58.class type(object):
class type(name, bases, dict):
传入一个参数时,返回 object 的类型。 返回值是一个 type 对象,通常与 object.class 所返回的对象相同。
推荐使用 isinstance() 内置函数来检测对象的类型,因为它会考虑子类的情况。
传入三个参数时,返回一个新的 type 对象。 这在本质上是 class 语句的一种动态形式。 name 字符串即类名并且会成为 name 属性;bases 元组列出基类并且会成为 bases 属性;而 dict 字典为包含类主体定义的命名空间并且会被复制到一个标准字典成为 dict 属性。
具体可参考:https://blog.csdn.net/grace666/article/details/103446541
**59.vars([object]):**返回模块、类、实例或任何其它具有 dict 属性的对象的 dict 属性
(1)object为空,vars()==locals()
2
3
4
5
6
7
8
9
10
11
2 def __init__(self,name):
3 self.name=name
4 def test(self):
5 print(self.name)
6
7a=A("hello")
8
9print(vars()) #{'__name__': '__main__', '__doc__': None, '__package__': None, '__loader__': <_frozen_importlib_external.SourceFileLoader object at 0x037CE808>, '__spec__': None, '__annotations__': {}, '__builtins__': <module 'builtins' (built-in)>, '__file__': 'test.py', '__cached__': None, 'A': <class '__main__.A'>}
10print(locals()) #{'__name__': '__main__', '__doc__': None, '__package__': None, '__loader__': <_frozen_importlib_external.SourceFileLoader object at 0x037CE808>, '__spec__': None, '__annotations__': {}, '__builtins__': <module 'builtins' (built-in)>, '__file__': 'test.py', '__cached__': None, 'A': <class '__main__.A'>}
11
(2)当object不为空,参数可以是模块、类、类实例,或者定义了__dict__属性的对象
2
3
4
5
6
7
8
9
10
11
12
13
14
2 def __init__(self,name):
3 self.name=name
4 def test(self):
5 print(self.name)
6
7a=A("hello")
8
9print(vars(A)) #{'__module__': '__main__', '__init__': <function A.__init__ at 0x058901D8>, 'test': <function A.test at 0x05890190>, '__dict__': <attribute '__dict__' of 'A' objects>, '__weakref__': <attribute '__weakref__' of 'A' objects>, '__doc__': None}
10print(vars(a)) #{'name': 'hello'}
11
12print(A.__dict__) #{'__module__': '__main__', '__init__': <function A.__init__ at 0x00F201D8>, 'test': <function A.test at 0x00F20190>, '__dict__': <attribute '__dict__' of 'A' objects>, '__weakref__': <attribute '__weakref__' of 'A' objects>, '__doc__': None}
13print(a.__dict__) #{'name': 'hello'}
14
再看一个例子:
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
2 a=1
3 b=2
4 def __init__(self):
5 self.a=3
6 self.b=4
7 def test():
8 return "aaa"
9
10class B(A):
11 a=5
12 b=6
13 def __init__(self):
14 super().__init__()
15 # self.a=7
16 # self.b=8
17 def test():
18 return "aaa"
19
20a=A()
21b=B()
22print(vars(A)) #{'__module__': '__main__', 'a': 1, 'b': 2, '__init__': <function A.__init__ at 0x04FC02B0>, 'test': <function A.test at 0x04FC0268>, '__dict__': <attribute '__dict__' of 'A' objects>, '__weakref__': <attribute '__weakref__' of 'A' objects>, '__doc__': None}
23print(vars(B)) #{'__module__': '__main__', 'a': 5, 'b': 6, '__init__': <function B.__init__ at 0x00F50220>, 'test': <function B.test at 0x00F501D8>, '__doc__': None}
24print(vars(a)) #{'a': 3, 'b': 4}
25print(vars(b)) #{'a': 3, 'b': 4}
26
由上可见,
每个类的类变量、函数名都放在自己的__dict__中;而类实例对象,父类和子类对象的__dict__是公用的
**60.zip(*iterables):**用于将可迭代的对象作为参数,将对象中对应的元素打包成一个个元组,返回由这些元组组成的对象,其中的第 i 个元组包含来自每个参数序列或可迭代对象的第 i 个元素,这样做可节约了不少内存
(1)参数为空,则返回空迭代器
2
3
4
5
2print(z) #<zip object at 0x000002DCBC2D6048>
3print(type(z)) #<class 'zip'>
4print(list(z)) #[]
5
(2)只有1个参数,从iterable中依次取一个元组,组成一个元组
2
3
4
2z=zip(x)
3print(list(z)) #[(1,), (2,), (3,)]
4
注:在python 3.0中有个大坑,
zip中的数据只能操作一次,之后内存就会释放
2
3
4
5
6
7
8
9
10
11
12
2z=zip(x)
3print(list(z)) #[(1,), (2,), (3,)]
4print(list(z)) #[]
5
6
7
8
9l1=[[1,2,3],[4,5],[6,7,8]]
10z=zip(l1)
11print(list(z)) #[([1, 2, 3],), ([4, 5],), ([6, 7, 8],)]
12
(3)带有2个参数,zip(a,b)zip()函数分别从a和b依次各取出一个元素组成元组,再将依次组成的元组组合成一个新的迭代器
2
3
4
5
6
7
8
2y=[4,5,6]
3z=zip(x, y)
4print(z) #<zip object at 0x000002B157D96248>
5print(type(z)) #<class 'zip'>
6print(list(z)) #[(1, 4), (2, 5), (3, 6)]
7print(z) #<zip object at 0x000002B157D96248>
8
注:
当a与b的行数或列数不同时,取两者结构中最小的行数和列数,依照最小的行数和列数将对应位置的元素进行组合
2
3
4
5
2y=[4,5,6,7,8]
3z=zip(x, y)
4print(list(z)) #[(1, 4), (2, 5), (3, 6), (3, 7)]
5
(4)使用for循环+列表推导式
2
3
4
5
2n = [[2, 2, 2], [3, 3, 3], [4, 4, 4]]
3print('='*10 + "矩阵点乘" + '='*10) #==========矩阵点乘==========
4print([x*y for a, b in zip(m, n) for x, y in zip(a, b)]) #[2, 4, 6, 12, 15, 18, 28, 32, 36]
5
(5)*zip操作:*zip()函数是zip()函数的逆过程,将zip对象变成原先组合前的数据
2
3
4
5
6
7
8
9
10
2a2 = [4,5,6]
3a3 = [7,8,9]
4a4 = ['a','b','c','d']
5z=zip(a1,a2,a3,a4)
6print(list(z)) #[(1, 4, 7, 'a'), (2, 5, 8, 'b'), (3, 6, 9, 'c')]
7
8z1=zip(*zip(a1,a2,a3,a4))
9print(list(z1)) #[(1, 2, 3), (4, 5, 6), (7, 8, 9), ('a', 'b', 'c')]
10
