段描述符,描述符与GDT
-
描述符(Descriptor)和全局描述符表(GDT)
-
实模式寻址方式
- 保护模式寻址方式
- 全局描述符表
-
段描述符
-
保护模式段描述符
-
代码段描述符
* 数据段描述符
* 系统段描述符
* 计算
* 保护模式地址转换- IA-32e段描述符
-
代码段描述符
* 数据段描述符
* 系统段描述符 -
特权级
-
基本概念
- CPL,DPL,RPL
-
CPL
* DPL -
数据段
* 非一致代码段(不使用调用门)
* 调用门
* 一致代码段和通过调用门访问的非一致代码段
* TSS1
21 * RPL
2 -
开始干活
-
选择子
- 描述符
- GDT
-
下一步做什么?
在本节中我们开始编写IA-32e模式描述符部分,在此之前我们还是需要了解关于IA-32e的内容,我们从开始的实模式寻址开始讲解(本文理论内容有些偏多)
描述符(Descriptor)和全局描述符表(GDT)
实模式寻址方式
在16位模式中我们的寻址方式以段基址*16+偏移地址形式寻址,其中段基址*16+偏移地址得到的地址是线性地址,在16位实模式中线性地址可以跟物理地址做映射,因此我们可以把线性地址看成物理地址,段基址*16+偏移地址得到的就是16位物理地址,在8086CPU中,一个寄存器的最大能够存储16位数据(2^16=65536(byte),65536(byte)>>10=64(kb)) ,但是8086CPU有20根地址线,因此最大寻址范围是 2^20 = 1048576(byte) 我们转换一下,结果就是 1048576(byte) >> 20 = 1(MB)
这里我们通过位移运算计算出来的,我们知道KB转MB的转换需要除以1024,1024转为二进制为100 0000 0000刚好10位,因此我们可以通过右移10位完成了KB转MB的操作,Byte转MB时需要除以2次1024,因此我们需要右移20位刚好得到
单个寄存器的最大只有64KB,因此一个段最大只支持64KB(65535byte,转为十六进制为0x10000),单个寄存器不能表示1MB内存地址空间因此需要2个寄存器共同表示20位地址。
假设我们在ES(附加段寄存器)中存入0x1000,DI(变址寄存器)中存入0xFFFF,那么ES:DI=0x1000*0x10+0xFFFF=0x1FFFF(0x10转为十进制刚好是16)。
保护模式寻址方式
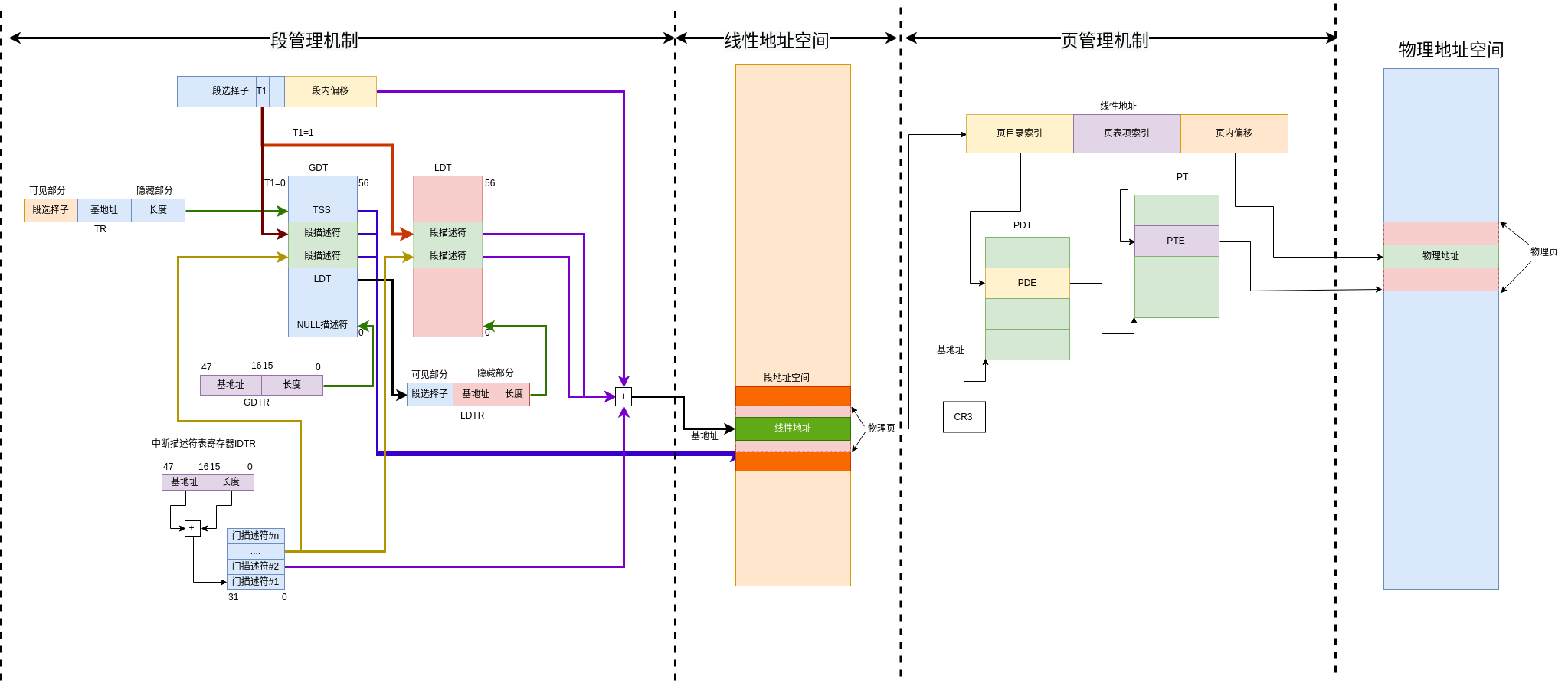
保护模式采用了全新的分段管理基址和分页管理机制来代替实模式基于段的寻址方式,保护模式支持分段和分页两种管理基址,处理器必须经过分段机制将逻辑地址转为线性地址后才能使用分页基址把线性地址转为物理地址(分页机制是可选项,但是分段机制是必选项)
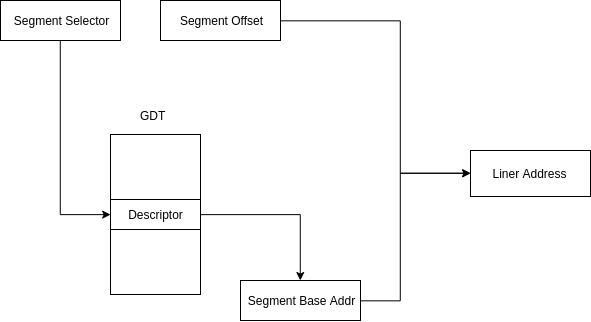
虽然保护模式下依旧可以使用分段的形式进行寻址但是寻址的方式发生很大的变化了,段寄存器保存的不再是段的基地址而是一个16位索引值(称为段选择子Segment Selector),在保护模式中引入了一个新的结构称为描述符表(Descriptor Table),描述符表有2个,一个是全局描述符表(Global Descriptor Table,GDT)另一个是局部描述符表(Local Descriptor Table,LDT),在寻址的时候,处理首先将选择子从全局描述符表中索引出对应的段描述符并加载到段寄存器内,段寄存器再从刚加载的段描述符中取得段基地址
段寻址模式如下
段选择子结构如下
2
3
4
5
6
7
2| | | |
3+------------+-----+-----+
4| Index | TI | RPL |
5+------------+-----+-----+
6
7
段选择子位功能说明
Index
用于索引目标段描述符
TI
目标段描述符所在的描述符表类型
RPL
请求特权级
在保护模式中段寄存器也发生了变化,CS,SS,DS,ES,FS,GS寄存器中加入了缓存区域,这些缓存区域是不可见的(不能手动设置)记录着段描述符的基地址,段限长属性等信息,系统可以定义8192个段描述符,但是同一时刻只能使用6个段
程序要想访问某个段,必须将段加载到段寄存器中,例如执行程序需要用到数据段,代码段和堆栈段,那么必须将有效的段选择子加载到CS,DS,SS寄存器中(结构如下)

每个段寄存器都被划分为2个部分,隐藏部分(Hidden Part)和可见部分(Visible Part)隐藏部分称为影子寄存器(Shadow Register),当段选择子加载到段寄存器的可见部分时,处理器还会同时加载段基址,段限长,段属性到影子寄存器中,处理会根据这些缓存的信息,直接进行地址转换,避免了重复读取内存的开销
全局描述符表
在加载段选择子的过程中,处理器会将选择子作为索引,从GDTR寄存器指向的描述符表中索引(找出)段描述符,GDTR寄存器是一个48位伪描述符(Pseudo-Descriptor)保存着全局描述符表的首地址和长度,GDT不是段描述符,而是在线性地址中的一个数据结构,GDT需要将自己的基地址(线性地址)和长度使用lgdt指令加载到GDTR寄存器中,GDT的长度为8N-1(N为描述符的个数)
全局描述符表的第0项被作为空选择子(NULL Segment Selector),处理器的CS和SS段寄存器不能加载空段,否则会发生#GP异常,其他寄存器可以使用空段选择子初始化
段描述符
保护模式段描述符
2
3
4
5
6
7
2| | | | | || | || | || || || || |
3+-----------+--+---+--+---+--------+--+-----+--+----+-----------+-----------+--------+
4|BaseAddr(H)|G |D/B|L |AVL|Limit(H)|P | DPL |S |Type|BaseAddr(M)|BaseAddr(L)|Limit(L)|
5+-----------+--+---+--+---+--------+--+-----+--+----+-----------+-----------+--------+
6
7
- 段限长字段(Limit):段限长字段用于指定段的长度,处理器会把段描述符中两个长字段组合成一个20位的值,根据颗粒度标识指定段限长的实际含义,如果G=0则段长度的范围可从1字节到1MB字节,如果G=1则段长度可从4KB-4GB
- 基地址字段(BaseAddr):该字段在4GB线性地址空间中一个字节长度0所处的位置,处理器会把3个分立的基地址字段组合形成32位值,段地址应该对齐16字节边界
- 段类型字段(Type):指定段或门的类型,说明段的访问种类以及段的扩展方向,该段的解释依赖于描述符类型标识符S指明是一个应用描述符还是一个系统描述符
- 描述符类型标志(S):指明一个段描述符时系统段描述符还是代码或数据段描述符
- 段特权级(DPL):指明段描述符的特权级,特权级从0到3,0级最高,3级最低,DPL用于控制对段的访问
- 段存在标志(P):指出一个段时在内存中(p=1)还是不在内存中(p=0)
- 默认操作大小/默认栈指针大小标志(D/B):根据段描述是一个可执行代码段,下扩数据段,还是一个堆栈段(对于32位代码和数据这个标志总是设置为1,对于16位代码段,这个标志被设置为0)
- 颗粒度标识符(G):该字段用于确定限长字段的Limit值的单位,如果颗粒度标志为0则段限长值单位时字节,如果设置了颗粒度标志,则段限长使用4KB单位
- 可用和保留比特位(AVL):段描述符第二个双字的位20可供系统软件使用,位21时保留并总是设置为0
代码段描述符
代码段描述符Type结构如下
2
3
4
5
6
2+---+---+---+---+
3| - | C | R | A |
4+---+---+---+---+
5
6
- A标志位(Accessed,已访问):记录代码是否被访问过,当A=1表示被访问过否则表示未访问,处理器只负责置位不负责复位
- R标志位(Readable,可读): 如果想读取程序段中的数据必须将该位置位
- C标志位(Conforming,一致性): 代码段分为一致性代码段和非一致性代码段,处理器通过此标志位可以进行标识
一致性代码段和非一致性代码段,我在刚看到这个的时候也是一头雾水,这里的一致性我的理解是在低特权级程序可以执行或跳转到高特权级(相同特权级)的代码段,并在执行过程中底特权级程序的CPL不变(执行前和执行后特CPL都是一致的,不会因为跳转到高特权级代码段的时候发生改变),所有的数据段都是非一致性的,意味着不能被底特权级程序访问
这样就好比你是一个普通职员,有一天领导让你去收拾一份保密文件,在收拾保密文件的过程中你的身份还是普通职员,并不会因为你收拾了保密文件而变成高级职员
数据段的非一致性就好比你工作时使用的数据可以被你上级查看,但是上级使用的数据你不能随意查看
如果段描述符的S位与第43位同时被置1,表示这个段描述符的类型位代码段描述符,代码段的Type标志区域(第40-42位)可组合的区域如下
8
0x8
1
0
0
0
代码
仅执行
9
0x9
1
0
0
1
代码
仅执行,已访问
10
0xA
1
0
1
0
代码
执行/可读
11
0xB
1
0
1
1
代码
执行/可读,已访问
12
0xC
1
1
0
0
代码
一致性段,仅执行
13
0xD
1
1
0
1
代码
一致性段,仅执行,已访问
14
0xE
1
1
1
0
代码
一致性段,执行/可读
15
0xF
1
1
1
1
代码
一致性段,执行/可读,已访问
数据段描述符
代码段描述符Type结构如下
2
3
4
5
6
2+---+---+---+---+
3| - | E | W | A |
4+---+---+---+---+
5
6
如果段描述符的S标志被置1,第43位处于复位状态,那么这个段描述符的类型就是数据段描述符
0
0x0
0
0
0
0
数据
只读
1
0x1
0
0
0
1
数据
只读,已访问
2
0x2
0
0
1
0
数据
执行/可读
3
0x3
0
0
1
1
数据
执行/可读,已访问
4
0x4
0
1
0
0
数据
向下扩展,只读
5
0x5
0
1
0
1
数据
向下扩展,只读,已访问
6
0x6
0
1
1
0
数据
向下扩展,可读/写
7
0x7
0
1
1
1
数据
向下扩展,可读/写,已访问
- A标志位(Accessed,已访问):记录代码是否被访问过,当A=1表示被访问过否则表示未访问,处理器只负责置位不负责复位
- W标志位(Write-enable,可读写): 表示数据段的读写权限,当W=1时表示可以读写,W=0时表示只读
- E标志位(Expansion-direction,方向位): 该标志位指示数据段的扩展方向,当E=1时表示向下扩展,当E=0时表示向上扩展
系统段描述符
如果段描述符的S标志位处于复位状态,那么段描述符的类型为系统段描述符
0
0x0
0
0
0
0
Reserved
保留
1
0x1
0
0
0
1
16-Bits TSS(Available)
16位TSS(可用)
2
0x2
0
0
1
0
LDT
LDT
3
0x3
0
0
1
1
16-Bits TSS(Busy)
16位TSS(忙)
4
0x4
0
1
0
0
16-Bits Call Gate
16位调用门
5
0x5
0
1
0
1
Task Gate
任务门
6
0x6
0
1
1
0
16-Bits Interrupt Gate
16位中断门
7
0x7
0
1
1
1
16-Bits Call Gate
16位陷阱门
8
0x8
1
0
0
0
Reserved
保留
9
0x9
1
0
0
1
32-Bits TSS(Available)
32位TSS(可用)
10
0xA
1
0
1
0
Reserved
保留
11
0xB
1
0
1
1
32-Bits TSS(Busy)
32位TSS(忙)
12
0xC
1
1
0
0
32-Bits Call Gate
32位调用门
13
0xD
1
1
0
1
Reserved
保留
14
0xE
1
1
1
0
32-Bits Interrupt Gate
32位中断门
15
0xF
1
1
1
1
32-Bits Call Gate
32位陷阱门
LDT段描述符,TSS段描述符,调用门描述符以后介绍
段描述符关系如下
1
1
代码段描述符
1
0
数据段描述符
0
系统段描述符
计算
我们可以使用如下方式取计算段描述符
2
3
4
5
6
7
2段界限 & 0xFFFF ; 段界限 1 (2 字节)
3(段基址 >> 16) & 0xFF ; 段基址 2 (1 字节)
4((段界限 >> 8) & 0xF00) | (属性 & 0xF0FF) ; 属性 1 + 段界限 2 + 属性 2 (2 字节)
5(段基址 >> 24) & 0xFF ; 段基址 3 (1 字节)
6
7
例如我们的代码段描述符属性为存在的可执行可读代码段二进制结果为1001 1010 十六进制位0x9A,代码段界限为0xFFFF计算方式如下
S标志位和43位同时置1,非一致性代码,可执行可读的段属性位1010最终结果为1001 1010
2
3
4
5
6
7
8
9
20xfffff & 0xFFFF =0xFFFF
3(0 >> 16) & 0xFF =0x00
4((0xfffff >> 8) & 0xF00) | (0x9A & 0xF0FF) = 009A
5(0 >> 24) & 0xFF =0x00
6
7Final:0x0000 FFFF 00 009A 00 = 0x0000FFFF00009A00
8
9
保护模式地址转换
IA-32e段描述符
IA-32e相比于保护模式,标志位大大缩减,但是不支持分段,尽管如此,GDT仍然需要使用,例如在用户和内核模式之间切换或加载TSS。
代码段描述符
2
3
4
5
6
2+-----------+--+---+--+---+--------+--+-----+--+---+--+--+--+------------+----------+
3|BaseAddr(H)|G |D/B|L |AVL|limit(H)|P |DPL |S |C/D|C |R |A | BaseAddr(L)| limit(L) |
4+-----------+--+---+--+---+--------+--+-----+--+---+--+--+--+------------+----------+
5
6
其中BaseAddr(H),G,AVL,limit(H),BaseAddr(L),limit(L)不在使用
- L :如果置1表示启用64位模式,如果置0表示启用32位兼容模式
- D/B:表示代码段的默认地址位宽和操作数位宽,D=0默认位宽为16位D=1默认位宽为32位,在IA-32e模式下L=1,D=0表明默认操作数位宽为32为,地址宽为64位,在此时D=1则会触发#GP异常
- P:指出一个段时在内存中(p=1)还是不在内存中(p=0)
- DPL:指明段描述符的特权级,特权级从0到3,0级最高,3级最低,DPL用于控制对段的访问
- S:指明一个段描述符时系统段描述符还是代码或数据段描述符
- C/D: Code/Data指明是代码段描述符还是数据段描述符
数据段描述符
2
3
4
5
6
2+-----------+--+---+--+---+--------+--+------+--+---+--+--+--+------------+----------+
3|BaseAddr(H)|G |D/B|L |AVL|limit(H)|P |DPL |S |C/D|E |W |A | BaseAddr(L)| limit(L) |
4+-----------+--+---+--+---+--------+--+------+--+---+--+--+--+------------+----------+
5
6
IA-32e模式数据段不仅忽略了段基址和段长度而且L标志位,D/B标志位,G标志位也均不起作用因此可用的标志位为
P,DPL,S,C/D,E,W,A
系统段描述符
IA-32e模式的系统段描述符从保护模式的8B(32位)扩展到16B(64位),IA-32e还对Type区域进行了精简
0
0
0
0
16B描述符的高8B
0
0
0
1
保留
0
0
1
0
LDT段描述符
0
0
1
1
保留
0
1
0
0
保留
0
1
0
1
保留
0
1
1
0
保留
0
1
1
1
保留
1
0
0
0
保留
1
0
0
1
64位TSS段描述符
1
0
1
0
保留
1
0
1
1
64位TSS段描述符
1
1
0
0
64位调用门描述符
1
1
0
1
保留
1
1
1
0
64位中断门描述符
1
1
1
1
64位陷进门描述符
在IA-32e模式下,处理器允许加载一个空段选择子(第0个GDT项)至CS寄存器以外的段寄存器(3特权级的SS段寄存器不允许加载NULL段选择子),处理器加载NULL段选择子到段寄存器的过程,并非读取GDT的第0项到段寄存器,而是以无效的段描述符来初始化段寄存器
特权级
基本概念
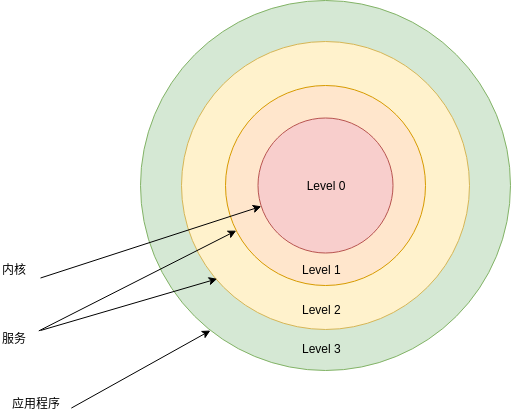
在保护模式的分段机制下,特权级总共有4个特权级别,从高到低位0,1,2,3数字越小表示特权级越大
较为核心的代码和数据,将被放在特权级较高的层级中,处理器用这样的机制来避免低特权级的任务在不被允许的情况加访问高特权级中的段,如果低特权级程序访问高特权级段将引发常规保护错误
Intel的CPU将特权级别分为4个级别:RING0,RING1,RING2,RING3
CPL,DPL,RPL
CPL
CPL(Current Privilege Level)为当前执行的程序或任务的特权级,存储在cs和ss的第0位和第1位上,通常情况下CPL等于代码所在段的特权级,当程序转移到不同特权级代码段时,处理器将改变CPL
DPL
DPL(Descriptor Privilege Level) 表示门或段的特权级,存储在段描述符和门描述符的DPL段中,当前代码段访问一个段或者门时 ,DPL将会和CPL以及段或门的选择子的RPL相比较,根据段或门的类型不同,DPL将会被区别对待
数据段
DPL规定了可以访问此段的最低权限,例如,一个程序段DPL为1,那么只有运行在CPL为0或者1的程序才有权访问
非一致代码段(不使用调用门)
DPL规定了可以访问此段的特权级,例如,一个非一致代码段的特权级为0,那么只有CPL为0的程序才能访问它
调用门
DPL规定了当前执行的程序或任务可以访问次调用门的最低特权级,与数据段规则一致
一致代码段和通过调用门访问的非一致代码段
DPl规定了访问此段的最高特权级,例如,一个一致代码的DPL为2,那么CPL为0和1的程序将无法访问此段
TSS
DPL规定了可以访问TSS的最低特权级,与数据段规则一致
RPL
RPL(Requested Privilege Level)
RPL是通过段选择子的第0位和第1位表现出来,处理器通过检查RPL和CPL来确认一个访问请求是否合法,如果RPL的数字比CPL大,那么RPL将会取决定性作用
操作系统过程中往往用RPL来避免低特权级程序访问高特权级段内数据
当被调用过程从一个调用过程接受到一个选择子时,将会把选择子的RPL设置为调用者的特权级
我们现在值说明了特权的一些定义,至于特权级转换我们后续文章中讲述,现在看不懂没关系,后面我们通过编程来感受一下
开始干活
我们需要定义特权级相关的结构,在src/ia_32e/mod.rs中添加以下内容
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
2 Ring0 = 0,
3 Ring1 = 1,
4 Ring2 = 2,
5 Ring3 = 3,
6}
7
8#[derive(Debug, Copy, Clone, PartialEq, Eq)]
9#[repr(u8)]
10impl PrivilegedLevel {
11 pub fn from_u16(level: u16) -> PrivilegedLevel {
12 match level {
13 0 => PrivilegedLevel::Ring0,
14 1 => PrivilegedLevel::Ring1,
15 2 => PrivilegedLevel::Ring2,
16 3 => PrivilegedLevel::Ring3,
17 other => panic!("invalid privileged level `{}`", other),
18 }
19 }
20}
21
22
该结构相对简单,就不在额外说明了
紧接着我们在src/ia_32e/目录下创建的包descriptor该目录我们将会放入GDT,IDT,TSS等数据结构,创建新的文件src/ia_32e/descriptor/gdt.rs
选择子
我们需要定义个SegmentSelector来表示段选择子,段选择子为16位无符号的因此我们在src/ia_32e/descriptor/mod.rs中定义如下的数据结构
2
3
4
5
2#[repr(transparent)]
3pub struct SegmentSelector(pub u16);
4
5
在创建段选择子的时候,我们需要考虑特权级相关的内容,因此,我们的new方法是这样的
2
3
4
5
2 SegmentSelector(index << 3 | (rpl as u16))
3}
4
5
只需要将index左移3位利用或运算将其合并即可
最后我们提供index方法(用于返回索引值)和rpl方法(用于返回当前选择子的特权级)
我们的mod.rs内容大概是这样的
2
3
4
5
6
7
8
9
10
11
12
13
14
15
2 pub fn new(index: u16, rpl: PrivilegedLevel) -> SegmentSelector {
3 SegmentSelector(index << 3 | (rpl as u16))
4 }
5
6 pub fn index(&self) -> u16 {
7 self.0 >> 3
8 }
9
10 pub fn rpl(&self) -> PrivilegedLevel {
11 PrivilegedLevel::from_u16(self.0.get_bits(0..2))
12 }
13}
14
15
描述符
我们在src/ia_32e/descriptor/mod.rs中添加如下内容
2
3
4
5
6
7
2pub enum Descriptor {
3 UserSegment(u64),
4 KernelSegment(u64, u64),
5}
6
7
IA-32e模式中不在支持分段机制,因此,代码段和数据段描述符标志位非常少我们可以通过定义函数的方式来获取即可,按照特权级我们可以分为系统使用的(内核)和用户使用的(用户),因此我们制定了UserSegment和KernelSegment,内核段中的特权级为Ring0,用户段的特权级为Ring3,内核段用于TSS描述符或LDT等,
标志位我们可以使用位运算的方式来完成
我们再来回顾一下描述符中的位段
代码段
2
3
4
5
6
2+------+--------+--+-----+--+---+--+--+--+
3|L |AVL|limit(H)|P |DPL |S |C/D|C |R |A |
4+------+--------+--+-----+--+---+--+--+--+
5
6
数据段
2
3
4
5
6
2+--+---+--------+--+-----+--+---+--+--+--+
3|L |AVL|limit(H)|P |DPL |S |C/D|E |W |A |
4+--+---+--------+--+-----+--+---+--+--+--+
5
6
我们需要定义一些常用的位例如
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
2writable = 1 << 41 // 第41位置1
3// 代码段分为一致性代码段和非一致性代码段
4read = 1 << 42 // 第42位置1
5// 代码段描述符
6code = 1 << 43 // 第43位置1
7// 系统/用户标识符
8user_segment = 1 << 44 // 第44位置1
9// 特权级(用户)
10user_privilegd = 3 << 45 // 第45位置1
11// 内存存在位
12present = 1 << 47 // 第47位置1
13// IA-32e模式
14long_mod = 1 << 53 // 第53位置1
15
16
如果我们需要定义64位用户代码段有读写权限我们可以使用或运算的方式连接起来
2
3
2
3
我们可以直接定义好要使用的值,或者采取这种运算的方式来定义,我们希望可以按照C风格的位运算,但是同时满足安全的需求,所以我们可以使用bitflags来完成,他的使用方式如下
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
2extern crate bitflags;
3
4bitflags! {
5 struct Flags: u32 {
6 const A = 0b00000001;
7 const B = 0b00000010;
8 const C = 0b00000100;
9 const ABC = Self::A.bits | Self::B.bits | Self::C.bits;
10 }
11}
12
13fn main() {
14 let e1 = Flags::A | Flags::C;
15 let e2 = Flags::B | Flags::C;
16 assert_eq!((e1 | e2), Flags::ABC); // union
17 assert_eq!((e1 & e2), Flags::C); // intersection
18 assert_eq!((e1 - e2), Flags::A); // set difference
19 assert_eq!(!e2, Flags::A); // set complement
20 assert_eq!(e1.bits(),0b00000101); // the raw value of the flags currently stored
21}
22
23
好了我们仿照上文的写法来定义DescriptorFlags
在Cargo.toml文件中添加以下内容
2
3
4
2version = "1.0.4"
3
4
这样我们就可以使用bitflags了,我们定义如下内容
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
2
3use bitflags::bitflags;
4
5bitflags! {
6 /// GDT 描述符标志位
7 pub struct DescriptorFlags: u64 {
8 const WRITABLE = 1 << 41;
9 const CONFORMING = 1 << 42;
10 const EXECUTABLE = 1 << 43;
11 const USER_SEGMENT = 1 << 44;
12 const PRESENT = 1 << 47;
13 const LONG_MODE = 1 << 53;
14 const DPL_RING_3 = 3 << 45;
15 }
16}
17
18
相信大家都知道每个的含义了
我们需要指定内核代码段描述符,内核数据段描述符,用户代码段描述符
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
2 pub fn kernel_code_segment() -> Descriptor {
3 use self::DescriptorFlags as Flags;
4 let flags = Flags::USER_SEGMENT | Flags::PRESENT | Flags::EXECUTABLE | Flags::LONG_MODE;
5 Descriptor::UserSegment(flags.bits())
6 }
7
8 pub fn user_data_segment() -> Descriptor {
9 use self::DescriptorFlags as Flags;
10 let flags = Flags::USER_SEGMENT | Flags::PRESENT | Flags::WRITABLE | Flags::DPL_RING_3;
11 Descriptor::UserSegment(flags.bits())
12 }
13
14 pub fn user_code_segment() -> Descriptor {
15 use self::DescriptorFlags as Flags;
16 let flags = Flags::USER_SEGMENT
17 | Flags::PRESENT
18 | Flags::EXECUTABLE
19 | Flags::LONG_MODE
20 | Flags::DPL_RING_3;
21 Descriptor::UserSegment(flags.bits())
22 }
23}
24
25
这样我们就定义完毕了,很简单不是么
GDT
我们实现完Descriptor后还要实现一个胖指针,这个胖指针是指向DescriptorTable的包含描述符表的大小和原始内存地址,结构如下
2
3
4
5
6
7
8
9
10
11
2#[derive(Debug,Copy, Clone)]
3#[repr(C,packed)]
4pub struct DescriptorTablePointer {
5 /// 描述符表大小
6 pub limit: u16,
7 /// 描述符表的内存地址
8 pub base: u64,
9}
10
11
我们为了添加了#[repr(C,packed)]属性,repr(C)表示DescriptorTablePointer数据的顺序、大小、对齐方式都和 C语言保持一致 ,repr(packed)强制 Rust 不填充空数据,各个类型的数据紧密排列
然后我们开始定义GDT
2
3
4
5
6
7
2pub struct GlobalDescriptorTable {
3 table: [u64; 8],
4 next_free: usize,
5}
6
7
table字段定义了用于存放描述符地址的64位无符号数组,next_free字段用于表示当前的GDT的长度,GDT表需要放入一个NULL描述符,因此next_free将从1开始,当next_free超过table最大长度将会panic
我们开始定义几个函数
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
2use crate::ia_32e::PrivilegedLevel;
3
4impl GlobalDescriptorTable {
5 pub fn new() -> GlobalDescriptorTable {
6 GlobalDescriptorTable {
7 table: [0; 8],
8 next_free: 1,
9 }
10 }
11 fn push(&mut self, value: u64) -> usize {
12 if self.next_free < self.table.len() {
13 let index = self.next_free;
14 self.table[index] = value;
15 self.next_free += 1;
16 index
17 } else {
18 panic!("GDT full");
19 }
20 }
21}
22
23
new函数的实现比较简单,这里不做过多阐述,push函数是一个私有方每次添加完毕后会返回当前的描述符的索引值(选择子的索引值),然后我们需要增加一个添加段描述符的方法
2
3
4
5
6
7
8
9
10
11
12
13
2 let index = match descr {
3 Descriptor::UserSegment(value) => self.push(value),
4 Descriptor::KernelSegment(value_low, value_hight) => {
5 let index = self.push(value_low);
6 self.push(value_hight);
7 index
8 }
9 };
10 SegmentSelector::new(index as u16, PrivilegedLevel::Ring0)
11 }
12
13
add_descriptor方添加一个段描述符并且返回段其段选择子,注意我们的段的特权级是Ring0
添加完毕后
现在我们就剩下最后一件事情了,将加载好的GDT使用lgdt指令加载到GDTR寄存器中,Rust中我们可以使用内嵌汇编的形式来执行汇编代码,内嵌汇编的使用我们在下一篇文章中详细说明,在本章中我们使用定义好的即可
我们创建一个新的包src/ia_32e/instructions/该包将会放入asm!内嵌汇编指令相关的内容
我们在src/ia_32e/instructions/tables.rs文件中添加如下内容
2
3
4
5
6
7
8
9
10
11
12
2
3use crate::ia_32e::descriptor::SegmentSelector;
4use crate::ia_32e::descriptor::DescriptorTablePointer;
5
6
7#[inline]
8pub unsafe fn ldgt(gdt:&DescriptorTablePointer){
9 asm!("lgdt ($0)" :: "r" (gdt) : "memory");
10}
11
12
这样我们可以通过lgdt指令加载GDT了,主要编译的时候一定要使用rust nightly编译器,因为asm还不是很稳定
之后我们在src/ia_32e/descriptor/gdt.rs文件中添加以下内容
2
3
4
5
6
7
8
9
10
11
12
13
2 pub fn load(&'static self) {
3 use crate::instructions::tables::{lgdt, DescriptorTablePointer};
4 use core::mem::size_of;
5
6 let ptr = DescriptorTablePointer {
7 base: self.table.as_ptr() as u64,
8 limit: (self.table.len() * size_of::<u64>() - 1) as u16,
9 };
10 unsafe { lgdt(&ptr) };
11 }
12
13
我们使用了#[cfg(target_arch = "x86_64")]属性表示目标为x86_64架构,load方法中使用了'static生命周期,因为我们写的是系统,除非按下电源按钮,否则GDT将会一直存在,我们使用之前定义的胖指针来存放table的原始地址和gdt的大小,gdt大小应该为u64大小*描述符个数-1(因为我们有NULL描述符),这样我们就完成了对GDT的加载
下一步做什么?
在下一篇文章中,我们开始介绍rust内嵌汇编的使用,为我们的系统完成加载GDT的操作
