本文主要介绍了 flink sql redis 数据汇表的实现过程。
如果想在本地测试下:
- 在公众号后台回复
- flink sql 知其所以然(三)| sql 自定义 redis 数据汇表获取源码(源码基于 1.13.1 实现)
- flink sql 知其所以然(三)| sql 自定义 redis 数据汇表获取源码(源码基于 1.13.1 实现)
- flink sql 知其所以然(三)| sql 自定义 redis 数据汇表获取源码(源码基于 1.13.1 实现)
- 在你的本地安装并启动 redis-server。
- 执行源码包中的
1flink.examples.sql._03.source_sink.RedisSinkTest
测试类,然后使用 redis-cli 执行
1get a就可以看到结果了(目前只支持 kv,即 redis
1set key value)。
如果想直接在集群环境使用:
- 命令行执行
1mvn package -DskipTests=true
打包
- 将生成的包
1flink-examples-0.0.1-SNAPSHOT.jar
引入 flink lib 中即可,无需其它设置。
2.背景篇-为啥需要 redis 数据汇表
目前在实时计算的场景中,熟悉 datastream 的同学在很多场景下都会将结果数据写入到 redis 提供数据服务。
举个例子:
- 外存状态引擎:需要把历史所有的 id 存储下来,但是因为 id 会不断增多,仅仅使用 flink 内部状态引擎的话,状态会越来越大,很难去保障其稳定性。那么这时就会选择外部状态引擎,比如 redis。在我们使用 redis 存储所有设备 id 时,除了使用 redis 作为维表去访问 id 是否出现过,还需要将新增的 id 写入到 redis 中以供后续的去重。这时候就需要使用到 redis sink 表。
- 数据服务引擎:在某些大促(双十一)的场景下需要将 flink 计算好的结果直接写入到 redis 中以提供高速数据服务引擎,直接提供给大屏查询使用。
而官方是没有提供 flink sql api 的 redis sink connector 的。如下图,基于 1.13 版本。
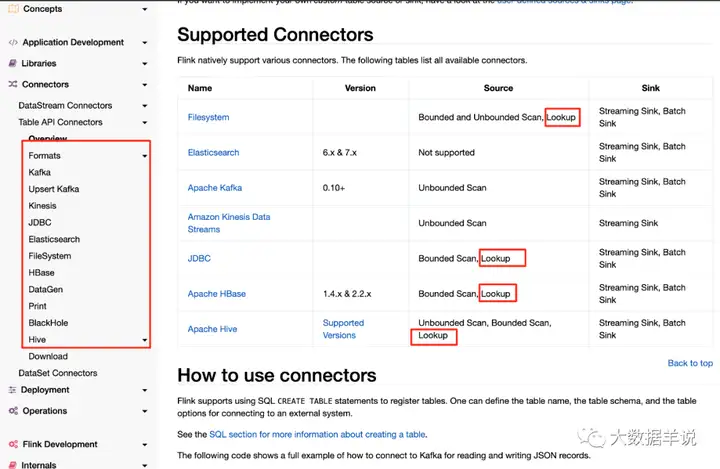
1
阿里云 flink 是提供了这个能力的。
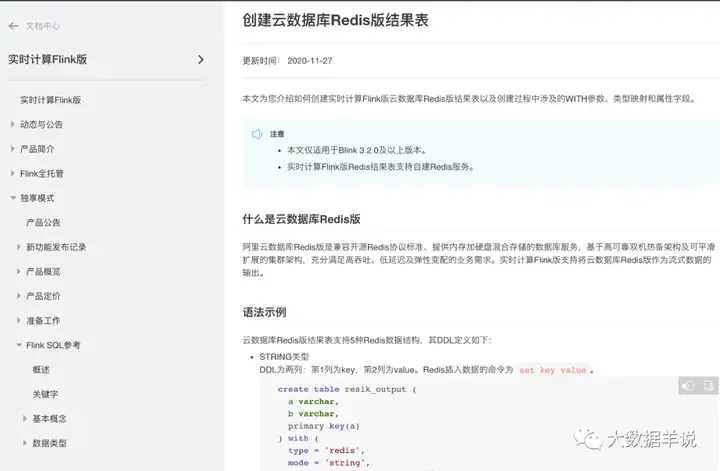
2
因此本文在介绍怎样自定义一个 sql 数据汇表的同时,实现一个 sql redis sink connector 来给大家使用。
3.目标篇-redis 数据汇表预期效果
redis 作为数据汇表在 datastream 中的最常用的数据结构有很多,基本上所有的数据结构都有可能使用到。本文实现主要实现 kv 结构,其他结构大家可以拿到源码之后进行自定义实现。也就多加几行代码就完事了。
预期效果就如阿里云的 flink redis,redis
1 | set key value |
的预期 flink sql:
2
3
4
5
6
7
8
9
10
11
12
13
key STRING, -- redis key,第 1 列为 key
`value` STRING -- redis value,第 2 列为 value
) WITH (
'connector' = 'redis', -- 指定 connector 是 redis 类型的
'hostname' = '127.0.0.1', -- redis server ip
'port' = '6379', -- redis server 端口
'write.mode' = 'string' -- 指定使用 redis `set key value`
)
INSERT INTO redis_sink_table
SELECT o.f0 as key, o.f1 as value
FROM leftTable AS o
下面是我在本地跑的结果:
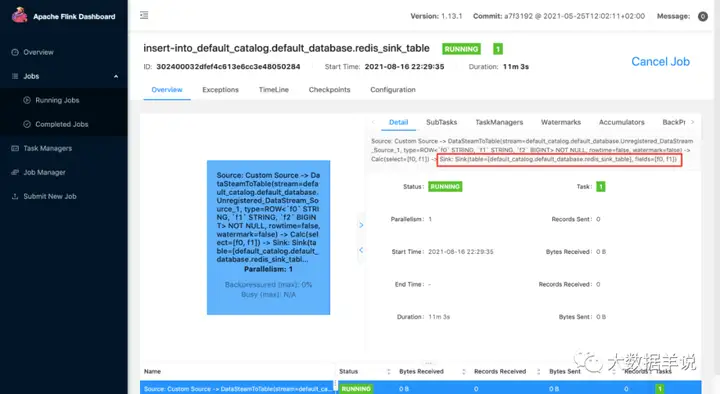
3
首先看下我们的测试输入,
1 | f0 |
恒定为
1 | a |
,
1 | f1 |
恒定为
1 | b |
,并且每 10ms 写入一次:
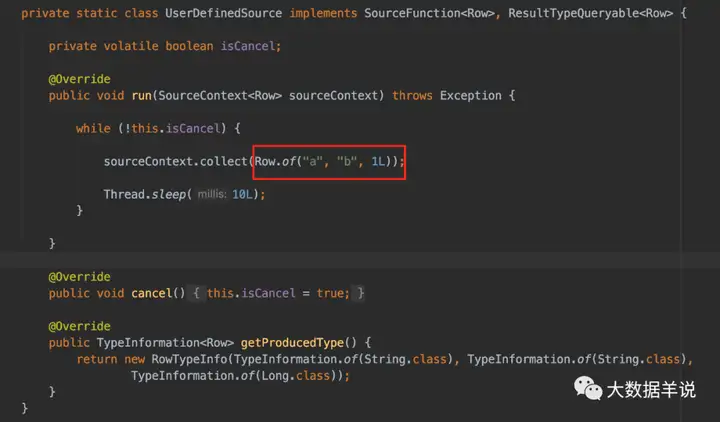
4
预期结果是 key 为
1 | a |
,value 会为
1 | b |
,实际结果也相同,使用 redis-cli 查询下,我删除掉也能在 10ms 后写入,所以查询时可以一直查得到:
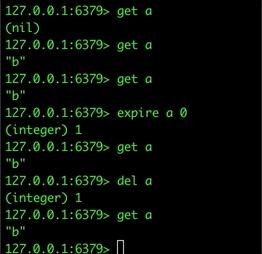
5
4.难点剖析篇-目前有哪些实现
目前可以从网上搜到的实现、以及可以参考的实现有以下两个:
- https://github.com/jeff-zou/flink-connector-redis。但使用起来有比较多的限制,包括需要在建表时就指定 key-column,value-column 等,其实博主觉得没必要指定这些字段,这些都可以动态调整。其实现是对 apache-bahir-flink https://github.com/apache/bahir-flink 的二次开发,但与 bahir 原生实现有割裂感,因为这个项目几乎参考 bahir redis connector 重新实现了一遍,接口与 bahir 不太相同。
- 阿里云实现 https://www.alibabacloud.com/help/zh/faq-detail/122722.htm?spm=a2c63.q38357.a3.7.a1227a53TBMuSY。阿里云的实现相对比较动态化,不需要在建表时就指定 hmap 等数据结构的 map key。
因此博主在实现时,定了一个基调。
- 参考阿里云的 DDL 实现
- 高度复用性:复用 bahir 提供的 redis connnector
- 简洁性:目前只实现 kv 结构,后续扩展可以给用户自己实现,扩展其实是非常简单的
5.实现篇-实现的过程
在实现 redis 数据汇表之前,不得不谈谈 flink 数据汇表加载和使用机制。
5.1.flink 数据汇表原理
其实上节已经详细描述了 flink sql 对于 source\sink 的加载机制。
