- Web应用:部署在云服务器上,为个人电脑或者移动用户提供的访问体验。
- SQL数据库:为Web应用提供数据持久化以及数据查询。
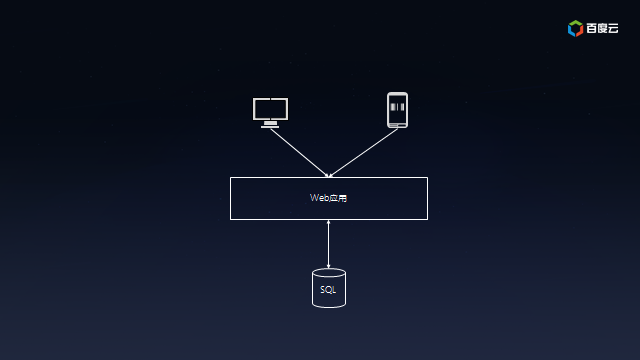
这套架构简洁而高效,很快便能够部署到百度云等云计算平台,以便快速推向市场。互联网不就是讲究小步快跑嘛!
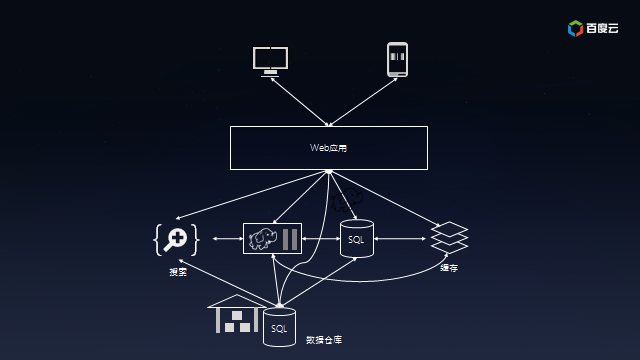
好景不长。随着用户的迅速增长,所有的访问都直接通过SQL数据库使得它不堪重负,不得不加上缓存服务以降低SQL数据库的荷载;为了理解用户行为,开始收集日志并保存到Hadoop上离线处理,同时把日志放在全文检索系统中以便快速定位问题;由于需要给投资方看业务状况,也需要把数据汇总到数据仓库中以便提供交互式报表。此时的系统的架构已经盘根错节了,考虑将来还会加入实时模块以及外部数据交互,真是痛并快乐着……
这时候,应该跑慢一些,让灵魂跟上来。
本质上,这是一个数据集成问题。没有任何一个系统能够解决所有的事情,所以业务数据根据不同用途存而放在不同的系统,比如归档、分析、搜索、缓存等。数据冗余本身没有任何问题,但是不同系统之间像意大利面条一样复杂的数据同步却是挑战。
这时候就轮到Kafka出场了。
Kafka可以让合适的数据以合适的形式出现在合适的地方。Kafka的做法是提供消息队列,让生产者单往队列的末尾添加数据,让多个消费者从队列里面依次读取数据然后自行处理。之前连接的复杂度是O(N^2),而现在降低到O(N),扩展起来方便多了:
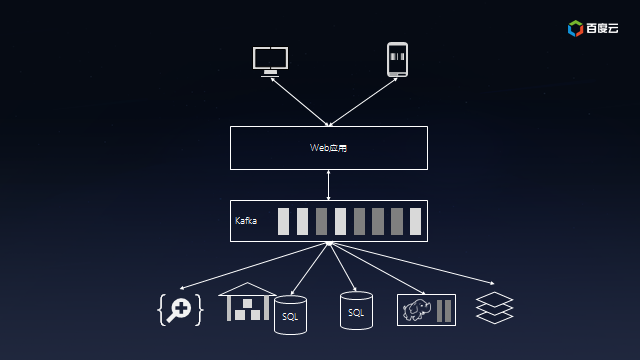
在Kafka的帮助下,你的互联网应用终于能够支撑飞速增长的业务,成为下一个BAT指日可待。
以上故事说明了Kafka主要用途是数据集成,或者说是流数据集成,以Pub/Sub形式的消息总线形式提供。但是,Kafka不仅仅是一套传统的消息总线,本质上Kafka是分布式的流数据平台,因为以下特性而著名:
-
提供Pub/Sub方式的海量消息处理。
-
以高容错的方式存储海量数据流。
-
保证数据流的顺序。
个人认为, Kafka与Redis PUB/SUB之间最大的区别在于Kafka是一个完整的系统,而Redis PUB/SUB只是一个套件(utility)——没有冒犯Redis的意思,毕竟它的主要功能并不是PUB/SUB。
先说Redis吧,它首先是一个内存数据库,其提供的PUB/SUB功能把消息保存在内存中(基于channel),因此如果你的消息的持久性需求并不高且后端应用的消费能力超强的话,使用Redis PUB/SUB是比较合适的使用场景。比如官网说提供的一个网络聊天室的例子:模拟IRC,因为channel就是IRC中的服务器。用户发起连接,发布消息到channel,接收其他用户的消息。这些对于持久性的要求并不高,使用Redis PUB/SUB来做足矣。
而Kafka是一个完整的系统,它提供了一个高吞吐量、分布式的提交日志(由于提供了Kafka Connect和Kafka Streams,目前Kafka官网已经将自己修正为一个分布式的流式处理平台,这里也可以看出Kafka的野心:-)。除了p2p的消息队列,它当然提供PUB/SUB方式的消息模型。而且,Kafka默认提供了消息的持久化,确保消息的不丢失性(至少是大部分情况下)。另外,由于消费元数据是保存在consumer端的,所以对于消费而言consumer被赋予极大的自由度。consumer可以顺序地消费消息,也可以重新消费之前处理过的消息。这些都是Redis PUB/SUB无法做到的。
最后总结一下,
Redis PUB/SUB使用场景:
- 消息持久性需求不高
- 吞吐量要求不高
- 可以忍受数据丢失
- 数据量不大
Kafka使用场景:
上面以外的其他场景:)
- 高可靠性
- 高吞吐量
- 持久性高
- 多样化的消费处理模型
Apache kafka是消息中间件的一种,我发现很多人不知道消息中间件是什么,在开始学习之前,我这边就先简单的解释一下什么是消息中间件,只是粗略的讲解,目前kafka已经可以做更多的事情。
举个例子,生产者消费者,生产者生产鸡蛋,消费者消费鸡蛋,生产者生产一个鸡蛋,消费者就消费一个鸡蛋,假设消费者消费鸡蛋的时候噎住了(系统宕机了),生产者还在生产鸡蛋,那新生产的鸡蛋就丢失了。再比如生产者很强劲(大交易量的情况),生产者1秒钟生产100个鸡蛋,消费者1秒钟只能吃50个鸡蛋,那要不了一会,消费者就吃不消了(消息堵塞,最终导致系统超时),消费者拒绝再吃了,”鸡蛋“又丢失了,这个时候我们放个篮子在它们中间,生产出来的鸡蛋都放到篮子里,消费者去篮子里拿鸡蛋,这样鸡蛋就不会丢失了,都在篮子里,而这个篮子就是”kafka“。
鸡蛋其实就是“数据流”,系统之间的交互都是通过“数据流”来传输的(就是tcp、http什么的),也称为报文,也叫“消息”。
消息队列满了,其实就是篮子满了,”鸡蛋“ 放不下了,那赶紧多放几个篮子,其实就是kafka的扩容。
各位现在知道kafka是干什么的了吧,它就是那个"篮子"
