Kafka是一个分布式的、可分区的、可复制的消息系统,下面是Kafka的几个基本术语:
Kafka将消息以topic为单位进行归纳;
将向Kafka topic发布消息的程序成为producers;
将预订topics并消费消息的程序成为consumer;
Kafka以集群的方式运行,可以由一个或多个服务组成,每个服务叫做一个broker。
producers通过网络将消息发送到Kafka集群,集群向消费者提供消息,如下图所示:

创建一个topic时,可以指定partitions(分区)数目,partitions数越多,其吞吐量也越大,但是需要的资源也越多,同时也会导致更高的不可用性,kafka在接收到producers发送的消息之后,会根据均衡策略将消息存储到不同的partitions中:
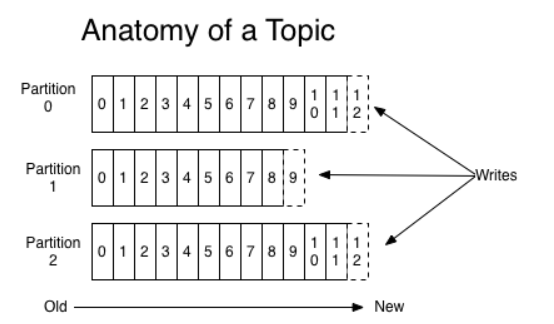
在每个partitions中,消息以顺序存储,最晚接收的的消息会最后被消费。
producers在向kafka集群发送消息的时候,可以通过指定partitions来发送到指定的partitions中。也可以通过指定均衡策略来将消息发送到不同的partitions中。如果不指定,就会采用默认的随机均衡策略,将消息随机的存储到不同的partitions中。
在consumer消费消息时,kafka使用offset来记录当前消费的位置:
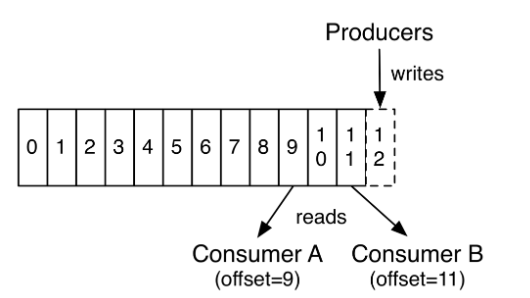
在kafka的设计中,可以有多个不同的group来同时消费同一个topic下的消息,如图,我们有两个不同的group同时消费,他们的的消费的记录位置offset各不项目,不互相干扰。
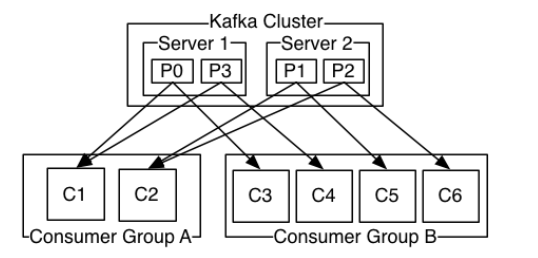
对于一个group而言,consumer的数量不应该多于partitions的数量,因为在一个group中,每个partitions至多只能绑定到一个consumer上,即一个consumer可以消费多个partitions,一个partitions只能给一个consumer消费。因此,若一个group中的consumer数量大于partitions数量的话,多余的consumer将不会收到任何消息。
Kafka安装使用
这里演示在Windows下Kafka安装与使用。Kafka下载地址:http://kafka.apache.org/downloads,选择二进制文件下载(Binary downloads),然后解压即可。
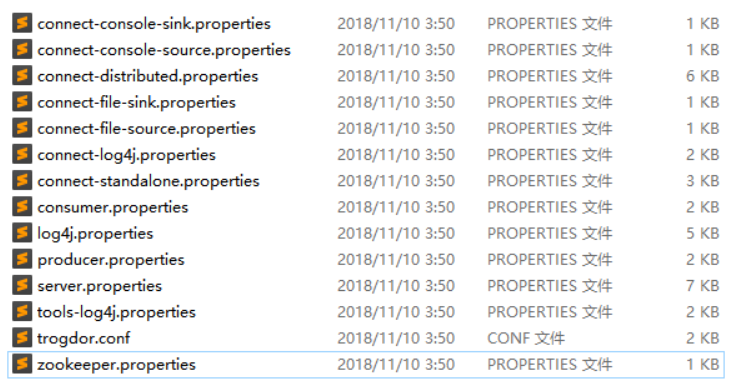
Kafka的配置文件位于config目录下,因为Kafka集成了Zookeeper(Kafka存储消息的地方),所以config目录下除了有Kafka的配置文件server.properties外,还可以看到一个Zookeeper配置文件zookeeper.properties:
打开server.properties,将broker.id的值修改为1,每个broker的id都必须设置为Integer类型,且不能重复。Zookeeper的配置保持默认即可。
接下来开始使用Kafka。
启动Zookeeper
在Windows下执行下面这些命令可能会出现找不到或无法加载主类的问题,解决方案可参考:https://www.daimajiaoliu.com/daima/47a362d1d900408 。
在Kafka根目录下使用cmd执行下面这条命令,启动ZK:
2
2
在Linux下,可以使用后台进程的方式启动ZK:
2
2
启动Kafka
执行下面这条命令启动Kafka:
2
3
2
3
Linux对应命令:
2
3
2
3
当看到命令行打印如下信息,说明启动完毕:

创建Topic
执行下面这条命令创建一个Topic
2
3
2
3
这条命令的意思是,创建一个Topic到ZK(指定ZK的地址),副本个数为1,分区数为1,Topic的名称为test。
Linux对应的命令为:
2
3
2
3
创建好后我们可以查看Kafka里的Topic列表:
2
2

可看到目前只包含一个我们刚创建的test Topic。
Linux对应的命令为:
2
3
2
3
查看test Topic的具体信息:
2
2

Linux对应的命令为:
2
3
2
3
生产消息和消费消息
启动Producers
2
3
2
3
9092为生产者的默认端口号。这里启动了生产者,准备往test Topic里发送数据。
Linux下对应的命令为:
2
3
2
3
启动Consumers
接着启动一个消费者用于消费生产者生产的数据,新建一个cmd窗口,输入下面这条命令:
2
3
2
3
from-beginning表示从头开始读取数据。
Linux下对应的命令为:
2
3
2
3
启动好生产者和消费者后我们在生产者里生产几条数据:

消费者成功接收到数据:

Spring Boot整合Kafka
上面简单介绍了Kafka的使用,下面我们开始在Spring Boot里使用Kafka。
新建一个Spring Boot项目,版本为2.1.3.RELEASE,并引入如下依赖:
2
3
4
5
6
7
8
9
2 <groupId>org.springframework.boot</groupId>
3 <artifactId>spring-boot-starter-web</artifactId>
4</dependency>
5<dependency>
6 <groupId>org.springframework.kafka</groupId>
7 <artifactId>spring-kafka</artifactId>
8</dependency>
9
生产者配置
新建一个Java配置类KafkaProducerConfig,用于配置生产者:
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
2public class KafkaProducerConfig {
3
4 @Value("${spring.kafka.bootstrap-servers}")
5 private String bootstrapServers;
6
7 @Bean
8 public ProducerFactory<String, String> producerFactory() {
9 Map<String, Object> configProps = new HashMap<>();
10 configProps.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, bootstrapServers);
11 configProps.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, StringSerializer.class);
12 configProps.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, StringSerializer.class);
13 return new DefaultKafkaProducerFactory<>(configProps);
14 }
15
16 @Bean
17 public KafkaTemplate<String, String> kafkaTemplate() {
18 return new KafkaTemplate<>(producerFactory());
19 }
20}
21
首先我们配置了一个producerFactory,方法里配置了Kafka Producer实例的策略。bootstrapServers为Kafka生产者的地址,我们在配置文件application.yml里配置它:
2
3
4
5
2 kafka:
3 bootstrap-servers: localhost:9092
4
5
ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG和 ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG指定了key,value序列化策略,这里指定为Kafka提供的StringSerializer,因为我们暂时只发送简单的String类型的消息。
接着我们使用producerFactory配置了kafkaTemplate,其包含了发送消息的便捷方法,后面我们就用这个对象来发送消息。
发布消息
配置好生产者,我们就可以开始发布消息了。
新建一个SendMessageController:
2
3
4
5
6
7
8
9
10
11
12
2public class SendMessageController {
3
4 @Autowired
5 private KafkaTemplate<String, String> kafkaTemplate;
6
7 @GetMapping("send/{message}")
8 public void send(@PathVariable String message) {
9 this.kafkaTemplate.send("test", message);
10 }
11}
12
我们注入了kafkaTemplate对象,key-value都为String类型,并通过它的send方法来发送消息。其中test为Topic的名称,上面我们已经使用命令创建过这个Topic了。
send方法是一个异步方法,我们可以通过回调的方式来确定消息是否发送成功,我们改造SendMessageController:
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
2public class SendMessageController {
3
4 private Logger logger = LoggerFactory.getLogger(this.getClass());
5
6 @Autowired
7 private KafkaTemplate<String, String> kafkaTemplate;
8
9 @GetMapping("send/{message}")
10 public void send(@PathVariable String message) {
11 ListenableFuture<SendResult<String, String>> future = this.kafkaTemplate.send("test", message);
12 future.addCallback(new ListenableFutureCallback<SendResult<String, String>>() {
13 @Override
14 public void onSuccess(SendResult<String, String> result) {
15 logger.info("成功发送消息:{},offset=[{}]", message, result.getRecordMetadata().offset());
16 }
17
18 @Override
19 public void onFailure(Throwable ex) {
20 logger.error("消息:{} 发送失败,原因:{}", message, ex.getMessage());
21 }
22 });
23 }
24}
25
消息发送成功后,会回调onSuccess方法,发送失败后回调onFailure方法。
消费者配置
接着我们来配置消费者,新建一个Java配置类KafkaConsumerConfig:
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
2@Configuration
3public class KafkaConsumerConfig {
4
5 @Value("${spring.kafka.bootstrap-servers}")
6 private String bootstrapServers;
7
8 @Value("${spring.kafka.consumer.group-id}")
9 private String consumerGroupId;
10
11 @Value("${spring.kafka.consumer.auto-offset-reset}")
12 private String autoOffsetReset;
13
14 @Bean
15 public ConsumerFactory<String, String> consumerFactory() {
16 Map<String, Object> props = new HashMap<>();
17 props.put(
18 ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG,
19 bootstrapServers);
20 props.put(
21 ConsumerConfig.GROUP_ID_CONFIG,
22 consumerGroupId);
23 props.put(
24 ConsumerConfig.AUTO_OFFSET_RESET_CONFIG,
25 autoOffsetReset);
26 props.put(
27 ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG,
28 StringDeserializer.class);
29 props.put(
30 ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG,
31 StringDeserializer.class);
32 return new DefaultKafkaConsumerFactory<>(props);
33 }
34
35 @Bean
36 public ConcurrentKafkaListenerContainerFactory<String, String> kafkaListenerContainerFactory() {
37 ConcurrentKafkaListenerContainerFactory<String, String> factory
38 = new ConcurrentKafkaListenerContainerFactory<>();
39 factory.setConsumerFactory(consumerFactory());
40 return factory;
41 }
42}
43
consumerGroupId和autoOffsetReset需要在application.yml里配置:
2
3
4
5
6
7
2 kafka:
3 consumer:
4 group-id: test-consumer
5 auto-offset-reset: latest
6
7
其中group-id将消费者进行分组(你也可以不进行分组),组名为test-consumer,并指定了消息读取策略,包含四个可选值:

-
earliest:当各分区下有已提交的offset时,从提交的offset开始消费;无提交的offset时,从头开始消费
-
latest:当各分区下有已提交的offset时,从提交的offset开始消费;无提交的offset时,消费新产生的该分区下的数据
-
none:topic各分区都存在已提交的offset时,从offset后开始消费;只要有一个分区不存在已提交的offset,则抛出异常
-
exception:直接抛出异常
在KafkaConsumerConfig中我们配置了ConsumerFactory和KafkaListenerContainerFactory。当这两个Bean成功注册到Spring IOC容器中后,我们便可以使用@KafkaListener注解来监听消息了。
配置类上需要@EnableKafka注释才能在Spring托管Bean上检测@KafkaListener注解。
消息消费
配置好消费者,我们就可以开始消费消息了,新建KafkaMessageListener:
2
3
4
5
6
7
8
9
10
11
2public class KafkaMessageListener {
3
4 private Logger logger = LoggerFactory.getLogger(this.getClass());
5
6 @KafkaListener(topics = "test", groupId = "test-consumer")
7 public void listen(String message) {
8 logger.info("接收消息: {}", message);
9 }
10}
11
我们通过@KafkaListener注解来监听名称为test的Topic,消费者分组的组名为test-consumer。
演示
启动Spring Boot项目,启动过程中,控制台会输出Kafka的配置,启动好后,访问http://localhost:8080/send/hello,mrbird,控制台输出如下:

@KafkaListener详解
@KafkaListener除了可以指定Topic名称和分组id外,我们还可以同时监听来自多个Topic的消息:
2
2
我们还可以通过@Header注解来获取当前消息来自哪个分区(partitions):
2
3
4
5
6
2public void listen(@Payload String message,
3 @Header(KafkaHeaders.RECEIVED_PARTITION_ID) int partition) {
4 logger.info("接收消息: {},partition:{}", message, partition);
5}
6
重启项目,再次访问http://localhost:8080/send/hello,mrbird,控制台输出如下:

因为我们没有进行分区,所以test Topic只有一个区,下标为0。
我们可以通过@KafkaListener来指定只接收来自特定分区的消息:
2
3
4
5
6
7
8
9
10
2 topicPartitions = @TopicPartition(topic = "test",
3 partitionOffsets = {
4 @PartitionOffset(partition = "0", initialOffset = "0")
5 }))
6public void listen(@Payload String message,
7 @Header(KafkaHeaders.RECEIVED_PARTITION_ID) int partition) {
8 logger.info("接收消息: {},partition:{}", message, partition);
9}
10
如果不需要指定initialOffset,上面代码可以简化为:
2
3
4
2 topicPartitions = @TopicPartition(topic = "test", partitions = { "0", "1" }))
3
4
消息过滤器
我们可以为消息监听添加过滤器来过滤一些特定的信息。我们在消费者配置类KafkaConsumerConfig的kafkaListenerContainerFactory方法里配置过滤规则:
2
3
4
5
6
7
8
9
10
11
12
2public ConcurrentKafkaListenerContainerFactory<String, String> kafkaListenerContainerFactory() {
3 ConcurrentKafkaListenerContainerFactory<String, String> factory
4 = new ConcurrentKafkaListenerContainerFactory<>();
5 factory.setConsumerFactory(consumerFactory());
6 // ------- 过滤配置 --------
7 factory.setRecordFilterStrategy(
8 r -> r.value().contains("fuck")
9 );
10 return factory;
11}
12
setRecordFilterStrategy接收RecordFilterStrategy<K, V>,他是一个函数式接口:
2
3
4
2 boolean filter(ConsumerRecord<K, V> var1);
3}
4
所以我们用lambda表达式指定了上面这条规则,即如果消息内容包含fuck这个粗鄙之语的时候,则不接受消息。
配置好后我们重启项目,分别发送下面这两条请求:
http://localhost:8080/send/fuck,mrbird
http://localhost:8080/send/love,mrbird
观察控制台:

可以看到,fuck,mrbird这条消息没有被接收。
发送复杂的消息
截至目前位置我们只发送了简单的字符串类型的消息,我们可以自定义消息转换器来发送复杂的消息。
定义消息实体
创建一个Message类:
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
2 private static final long serialVersionUID = 6678420965611108427L;
3
4 private String from;
5
6 private String message;
7
8 public Message() {
9
10 }
11
12 public Message(String from, String message) {
13 this.from = from;
14 this.message = message;
15 }
16
17 @Override
18 public String toString() {
19 return "Message{" +
20 "from='" + from + '\'' +
21 ", message='" + message + '\'' +
22 '}';
23 }
24
25 // get set 略
26}
27
改造消息生产者配置
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
2public class KafkaProducerConfig {
3
4 @Value("${spring.kafka.bootstrap-servers}")
5 private String bootstrapServers;
6
7 @Bean
8 public ProducerFactory<String, Message> producerFactory() {
9 Map<String, Object> configProps = new HashMap<>();
10 configProps.put(
11 ProducerConfig.BOOTSTRAP_SERVERS_CONFIG,
12 bootstrapServers);
13 configProps.put(
14 ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG,
15 StringSerializer.class);
16 configProps.put(
17 ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG,
18 JsonSerializer.class);
19 return new DefaultKafkaProducerFactory<>(configProps);
20 }
21
22 @Bean
23 public KafkaTemplate<String, Message> kafkaTemplate() {
24 return new KafkaTemplate<>(producerFactory());
25 }
26}
27
我们将value序列化策略指定为了Kafka提供的JsonSerializer,并且kafkaTemplate返回类型为KafkaTemplate<String, Message>。
发送新的消息
在SendMessageController里发送复杂的消息:
2
3
4
5
6
7
8
2private KafkaTemplate<String, Message> kafkaTemplate;
3
4@GetMapping("send/{message}")
5public void sendMessage(@PathVariable String message) {
6 this.kafkaTemplate.send("test", new Message("mrbird", message));
7}
8
修改消费者配置
修改消费者配置KafkaConsumerConfig:
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
2@Configuration
3public class KafkaConsumerConfig {
4
5 @Value("${spring.kafka.bootstrap-servers}")
6 private String bootstrapServers;
7
8 @Value("${spring.kafka.consumer.group-id}")
9 private String consumerGroupId;
10
11 @Value("${spring.kafka.consumer.auto-offset-reset}")
12 private String autoOffsetReset;
13
14 @Bean
15 public ConsumerFactory<String, Message> consumerFactory() {
16 Map<String, Object> props = new HashMap<>();
17 props.put(
18 ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG,
19 bootstrapServers);
20 props.put(
21 ConsumerConfig.GROUP_ID_CONFIG,
22 consumerGroupId);
23 props.put(
24 ConsumerConfig.AUTO_OFFSET_RESET_CONFIG,
25 autoOffsetReset);
26 return new DefaultKafkaConsumerFactory<>(
27 props,
28 new StringDeserializer(),
29 new JsonDeserializer<>(Message.class));
30 }
31
32 @Bean
33 public ConcurrentKafkaListenerContainerFactory<String, Message> kafkaListenerContainerFactory() {
34 ConcurrentKafkaListenerContainerFactory<String, Message> factory
35 = new ConcurrentKafkaListenerContainerFactory<>();
36 factory.setConsumerFactory(consumerFactory());
37 return factory;
38 }
39}
40
修改消息监听
修改KafkaMessageListener:
2
3
4
5
2public void listen(Message message) {
3 logger.info("接收消息: {}", message);
4}
5
重启项目,访问http://localhost:8080/send/hello,控制台输出如下:

更多配置
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
2spring.kafka.admin.fail-fast=false # Whether to fail fast if the broker is not available on startup.
3spring.kafka.admin.properties.*= # Additional admin-specific properties used to configure the client.
4spring.kafka.admin.ssl.key-password= # Password of the private key in the key store file.
5spring.kafka.admin.ssl.key-store-location= # Location of the key store file.
6spring.kafka.admin.ssl.key-store-password= # Store password for the key store file.
7spring.kafka.admin.ssl.key-store-type= # Type of the key store.
8spring.kafka.admin.ssl.protocol= # SSL protocol to use.
9spring.kafka.admin.ssl.trust-store-location= # Location of the trust store file.
10spring.kafka.admin.ssl.trust-store-password= # Store password for the trust store file.
11spring.kafka.admin.ssl.trust-store-type= # Type of the trust store.
12spring.kafka.bootstrap-servers= # Comma-delimited list of host:port pairs to use for establishing the initial connections to the Kafka cluster. Applies to all components unless overridden.
13spring.kafka.client-id= # ID to pass to the server when making requests. Used for server-side logging.
14spring.kafka.consumer.auto-commit-interval= # Frequency with which the consumer offsets are auto-committed to Kafka if 'enable.auto.commit' is set to true.
15spring.kafka.consumer.auto-offset-reset= # What to do when there is no initial offset in Kafka or if the current offset no longer exists on the server.
16spring.kafka.consumer.bootstrap-servers= # Comma-delimited list of host:port pairs to use for establishing the initial connections to the Kafka cluster. Overrides the global property, for consumers.
17spring.kafka.consumer.client-id= # ID to pass to the server when making requests. Used for server-side logging.
18spring.kafka.consumer.enable-auto-commit= # Whether the consumer's offset is periodically committed in the background.
19spring.kafka.consumer.fetch-max-wait= # Maximum amount of time the server blocks before answering the fetch request if there isn't sufficient data to immediately satisfy the requirement given by "fetch-min-size".
20spring.kafka.consumer.fetch-min-size= # Minimum amount of data the server should return for a fetch request.
21spring.kafka.consumer.group-id= # Unique string that identifies the consumer group to which this consumer belongs.
22spring.kafka.consumer.heartbeat-interval= # Expected time between heartbeats to the consumer coordinator.
23spring.kafka.consumer.key-deserializer= # Deserializer class for keys.
24spring.kafka.consumer.max-poll-records= # Maximum number of records returned in a single call to poll().
25spring.kafka.consumer.properties.*= # Additional consumer-specific properties used to configure the client.
26spring.kafka.consumer.ssl.key-password= # Password of the private key in the key store file.
27spring.kafka.consumer.ssl.key-store-location= # Location of the key store file.
28spring.kafka.consumer.ssl.key-store-password= # Store password for the key store file.
29spring.kafka.consumer.ssl.key-store-type= # Type of the key store.
30spring.kafka.consumer.ssl.protocol= # SSL protocol to use.
31spring.kafka.consumer.ssl.trust-store-location= # Location of the trust store file.
32spring.kafka.consumer.ssl.trust-store-password= # Store password for the trust store file.
33spring.kafka.consumer.ssl.trust-store-type= # Type of the trust store.
34spring.kafka.consumer.value-deserializer= # Deserializer class for values.
35spring.kafka.jaas.control-flag=required # Control flag for login configuration.
36spring.kafka.jaas.enabled=false # Whether to enable JAAS configuration.
37spring.kafka.jaas.login-module=com.sun.security.auth.module.Krb5LoginModule # Login module.
38spring.kafka.jaas.options= # Additional JAAS options.
39spring.kafka.listener.ack-count= # Number of records between offset commits when ackMode is "COUNT" or "COUNT_TIME".
40spring.kafka.listener.ack-mode= # Listener AckMode. See the spring-kafka documentation.
41spring.kafka.listener.ack-time= # Time between offset commits when ackMode is "TIME" or "COUNT_TIME".
42spring.kafka.listener.client-id= # Prefix for the listener's consumer client.id property.
43spring.kafka.listener.concurrency= # Number of threads to run in the listener containers.
44spring.kafka.listener.idle-event-interval= # Time between publishing idle consumer events (no data received).
45spring.kafka.listener.log-container-config= # Whether to log the container configuration during initialization (INFO level).
46spring.kafka.listener.monitor-interval= # Time between checks for non-responsive consumers. If a duration suffix is not specified, seconds will be used.
47spring.kafka.listener.no-poll-threshold= # Multiplier applied to "pollTimeout" to determine if a consumer is non-responsive.
48spring.kafka.listener.poll-timeout= # Timeout to use when polling the consumer.
49spring.kafka.listener.type=single # Listener type.
50spring.kafka.producer.acks= # Number of acknowledgments the producer requires the leader to have received before considering a request complete.
51spring.kafka.producer.batch-size= # Default batch size.
52spring.kafka.producer.bootstrap-servers= # Comma-delimited list of host:port pairs to use for establishing the initial connections to the Kafka cluster. Overrides the global property, for producers.
53spring.kafka.producer.buffer-memory= # Total memory size the producer can use to buffer records waiting to be sent to the server.
54spring.kafka.producer.client-id= # ID to pass to the server when making requests. Used for server-side logging.
55spring.kafka.producer.compression-type= # Compression type for all data generated by the producer.
56spring.kafka.producer.key-serializer= # Serializer class for keys.
57spring.kafka.producer.properties.*= # Additional producer-specific properties used to configure the client.
58spring.kafka.producer.retries= # When greater than zero, enables retrying of failed sends.
59spring.kafka.producer.ssl.key-password= # Password of the private key in the key store file.
60spring.kafka.producer.ssl.key-store-location= # Location of the key store file.
61spring.kafka.producer.ssl.key-store-password= # Store password for the key store file.
62spring.kafka.producer.ssl.key-store-type= # Type of the key store.
63spring.kafka.producer.ssl.protocol= # SSL protocol to use.
64spring.kafka.producer.ssl.trust-store-location= # Location of the trust store file.
65spring.kafka.producer.ssl.trust-store-password= # Store password for the trust store file.
66spring.kafka.producer.ssl.trust-store-type= # Type of the trust store.
67spring.kafka.producer.transaction-id-prefix= # When non empty, enables transaction support for producer.
68spring.kafka.producer.value-serializer= # Serializer class for values.
69spring.kafka.properties.*= # Additional properties, common to producers and consumers, used to configure the client.
70spring.kafka.ssl.key-password= # Password of the private key in the key store file.
71spring.kafka.ssl.key-store-location= # Location of the key store file.
72spring.kafka.ssl.key-store-password= # Store password for the key store file.
73spring.kafka.ssl.key-store-type= # Type of the key store.
74spring.kafka.ssl.protocol= # SSL protocol to use.
75spring.kafka.ssl.trust-store-location= # Location of the trust store file.
76spring.kafka.ssl.trust-store-password= # Store password for the trust store file.
77spring.kafka.ssl.trust-store-type= # Type of the trust store.
78spring.kafka.streams.application-id= # Kafka streams application.id property; default spring.application.name.
79spring.kafka.streams.auto-startup=true # Whether or not to auto-start the streams factory bean.
80spring.kafka.streams.bootstrap-servers= # Comma-delimited list of host:port pairs to use for establishing the initial connections to the Kafka cluster. Overrides the global property, for streams.
81spring.kafka.streams.cache-max-size-buffering= # Maximum memory size to be used for buffering across all threads.
82spring.kafka.streams.client-id= # ID to pass to the server when making requests. Used for server-side logging.
83spring.kafka.streams.properties.*= # Additional Kafka properties used to configure the streams.
84spring.kafka.streams.replication-factor= # The replication factor for change log topics and repartition topics created by the stream processing application.
85spring.kafka.streams.ssl.key-password= # Password of the private key in the key store file.
86spring.kafka.streams.ssl.key-store-location= # Location of the key store file.
87spring.kafka.streams.ssl.key-store-password= # Store password for the key store file.
88spring.kafka.streams.ssl.key-store-type= # Type of the key store.
89spring.kafka.streams.ssl.protocol= # SSL protocol to use.
90spring.kafka.streams.ssl.trust-store-location= # Location of the trust store file.
91spring.kafka.streams.ssl.trust-store-password= # Store password for the trust store file.
92spring.kafka.streams.ssl.trust-store-type= # Type of the trust store.
93spring.kafka.streams.state-dir= # Directory location for the state store.
94spring.kafka.template.default-topic= # Default topic to which messages are sent.
95
