1 分布式缓存理论
1.1 大型网站架构
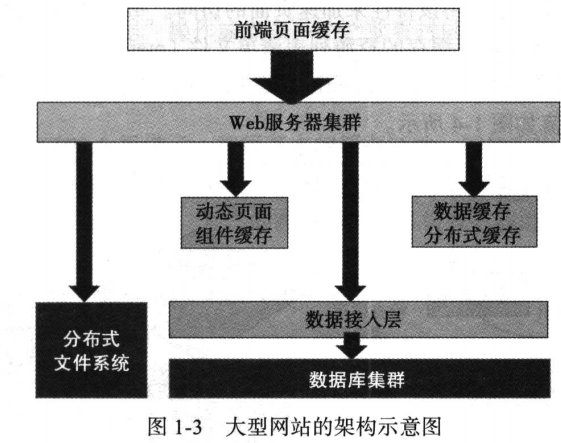
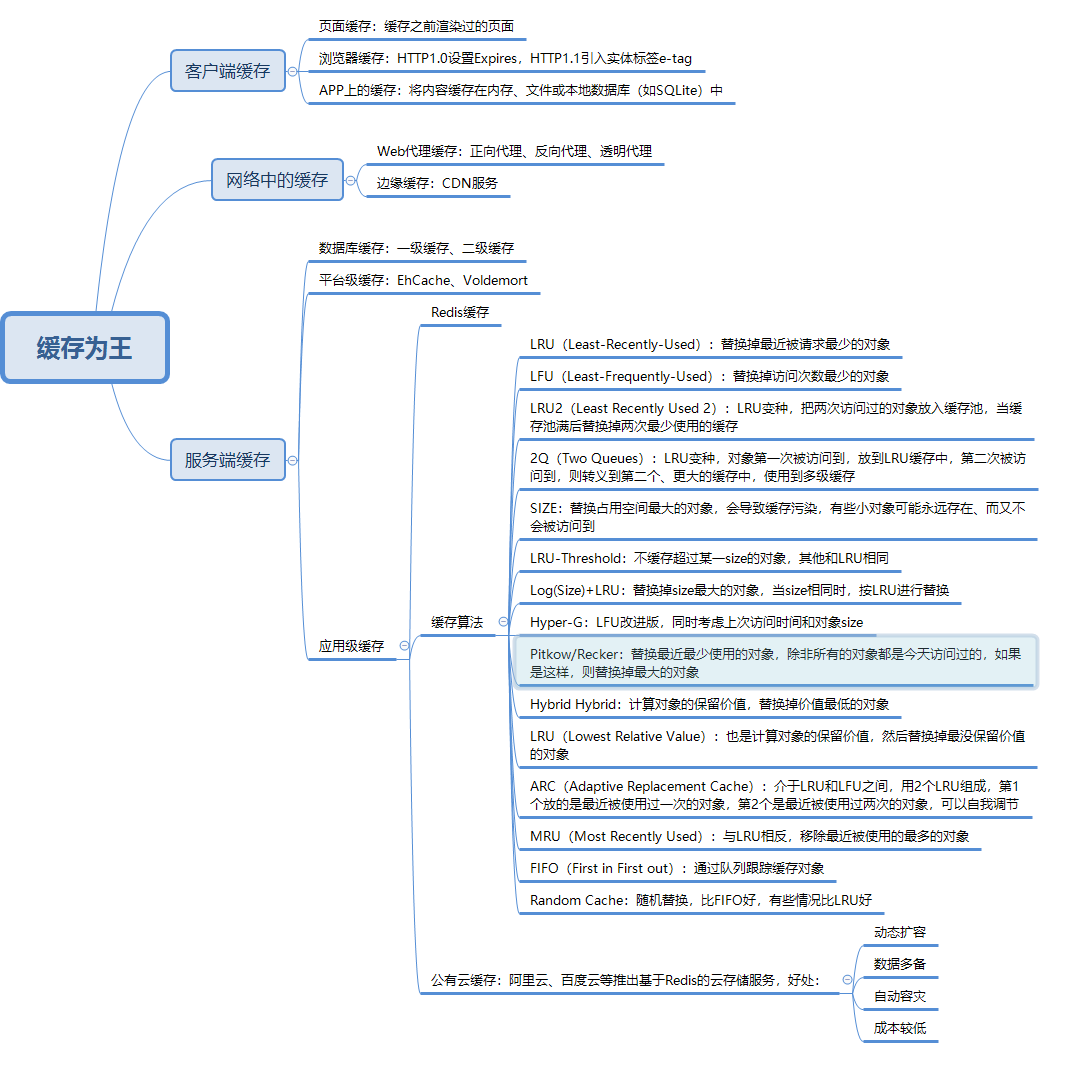
1.2 缓存概况
缓存分为:客户端缓存、网络中的缓存、服务端缓存。
1.3 幂等性
概念:1次调用和N次调用返回一样的结果。
保证措施:通常在调用时加上唯一标识,例如订单号。
1.4 分布式系统理论
1.4.1 CAP理论
一致性(C):分布式系统中所有数据备份在同一时刻拥有相同的值;
可用性(A):集群中一部分节点故障后,集群整体还能响应客户端的读写请求;
分区容忍性(P):如果系统不能在一定时限内达成数据一致性,就意味着发生了分区,必须就当前操作在C和A之间做出选择。
1.4.2 分布式一致性协议
(1)Paxos
多个节点之间就某个值(提案)达成一致(决议)的而通信协议。
分为两个阶段:Prepare阶段和Accept阶段。
参与者角色:Proposer——提一提案的服务器,Acceptor——批准提案的服务器,二者在物理上可以是同一台机器。
- Prepare阶段:Proposer发送Prepare、Acceptor应答Prepare;
- Accept阶段:Proposal发送Accept、Acceptor应答Accept。
(2)2PC
- 阶段1:提交请求阶段(投票阶段)
- 阶段2:提交阶段
不足:提交协议是阻塞型协议,如果协调器宕机则参与者无法解决事务。
(3)3PC
- 阶段1:canCommit,投票,事务协调器询问参与者是否能提交;
- 阶段2:preCommit,预提交;
- 阶段3:doCommit,提交,一般通过重试补偿策略保证doCommit提交成功。
(4)Raft
任何时候一台服务器可以扮演以下角色之一:
领导者、选民、候选人
也分为2个阶段,第一阶段选举,第二阶段正常操作
1.4.3 解决“脑裂”问题
心跳机制 + Monitor
1.4.4 负载均衡
(1)轮询:Round Robin,根据Nginx配置文件中的顺序,依次把客户端的Web请求分发到不同的后端服务器;
(2)最少连接:谁的连接最少就分发给谁
(3)IP地址哈希:来自相同IP的请求转发给后端同一台服务器处理,方便session保持
(4)基于权重的负载均衡:把请求更多的分发给配置高的服务器上。
2 手写LRU缓存
双向链表实现,不带超时策略。链表首部表示最近的数据,尾部表示最远使用的数据。head仅仅作为哨兵,不保存任何数据;tail则保存了实际数据。
(1)put(E e):插入一个元素。如果超过缓存容量,则先从链表尾部删除一个元素再插入首部,否则直接插入首部;
(2)get(E e):没有就返回null;有就返回值,并且把该元素提到链表首部。
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
2
3import java.util.ArrayList;
4import java.util.List;
5import java.util.concurrent.atomic.AtomicInteger;
6
7/**
8 * @Description LRU淘汰算法(链表实现,线程安全)
9 */
10public class LRUCache<E> {
11
12 // 双向链表,用于缓存数据
13 static class Node<E> {
14 E item;
15
16 Node<E> pre;
17 Node<E> next;
18
19 Node(E x) {
20 item = x;
21 }
22 }
23
24 // 缓存容量
25 private final int capacity;
26 private final AtomicInteger count = new AtomicInteger();
27
28 private Node<E> head; //头结点
29 private Node<E> tail; //尾节点
30
31 public LRUCache() {
32 this(Integer.MAX_VALUE);
33 }
34
35 public LRUCache(int capacity) {
36 if (capacity <= 0) {
37 throw new IllegalArgumentException();
38 }
39 this.capacity = capacity;
40 tail = head = new Node<E>(null);
41 }
42
43 public synchronized void put(E e) {
44 // 缓存已满,淘汰尾节点
45 if (count.get() == capacity) {
46 removeLast();
47 }
48
49 // 然后将新节点插入到头部
50 insertHead(e);
51 }
52
53 /**
54 * 删除链表最后一个元素
55 */
56 private void removeLast() {
57 if (count.get() == 0) {
58 return;
59 }
60
61 // 只有一个节点的删除
62 if (count.get() == 1) {
63 tail = head = new Node<>(null);
64 } else {
65 // 将末尾节点的前一个节点作为新的尾节点
66 tail = tail.pre;
67 tail.next = null;
68 }
69 count.getAndDecrement();
70 }
71
72 /**
73 * 将新元素插入链表头部
74 * @param e
75 */
76 private void insertHead(E e) {
77 Node<E> newNode = new Node<>(e);
78 insertHead(newNode);
79 }
80
81 private void insertHead(Node<E> newNode) {
82 if (count.get() == 0) {
83 head.next = newNode;
84 newNode.pre = head;
85
86 tail = newNode;
87 } else {
88 Node<E> tmp = head.next;
89 head.next = newNode;
90 newNode.pre = head;
91
92 tmp.pre = newNode;
93 newNode.next = tmp;
94 }
95
96 count.getAndIncrement();
97 }
98
99 public synchronized E get(E e) {
100 if (count.get() == 0) {
101 return null;
102 }
103
104 Node<E> tmp = head;
105 while (tmp != null && tmp.next != null) {
106 tmp = tmp.next;
107 if (e.equals(tmp.item)) {
108 E e1 = tmp.item;
109 // 将该元素提到开头处
110 moveToHead(tmp);
111 return e1;
112 }
113 }
114 return null;
115 }
116
117 /**
118 * 将元素移到首位
119 * @param node
120 */
121 private void moveToHead(Node<E> node) {
122 if (node.pre == head) {
123 return;
124 }
125
126 // 先删除该元素
127 if (node == tail) {
128 removeLast();
129 } else {
130 node.pre.next = node.next;
131 node.next.pre = node.pre;
132 }
133
134 //然后插入首部
135 insertHead(node);
136 }
137
138 // 打印缓存中的所有元素
139 @Override
140 public String toString() {
141 List<E> list = new ArrayList<>();
142
143 if (count.get() == 0) {
144 return "Empty";
145 }
146
147 Node<E> tmp = head;
148 while (tmp != null && tmp.next != null) {
149 list.add(tmp.next.item);
150 tmp = tmp.next;
151 }
152 return list.toString();
153 }
154}
155
156
测试下:
新建一个容量为3的缓存:
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
2
3/**
4 * @Description 测试缓存
5 */
6public class Test {
7 public static void main(String[] args) {
8 LRUCache<Integer> cache = new LRUCache<>(3);
9
10 for (int i = 2 ; i < 9; i++) {
11 cache.put(i);
12 System.out.println(cache);
13 }
14 System.out.println("################");
15
16 for (int i = 0 ; i < 10; i++) {
17 printCacheEle(cache, i);
18 }
19 }
20
21 private static void printCacheEle(LRUCache<Integer> cache, int i) {
22 Integer a = cache.get(i);
23 System.out.println(a);
24 System.out.println(cache);
25 }
26}
27
28
打印出来:
[2]
[3, 2]
[4, 3, 2]
[5, 4, 3]
[6, 5, 4]
[7, 6, 5]
[8, 7, 6]
################
null
[8, 7, 6]
null
[8, 7, 6]
null
[8, 7, 6]
null
[8, 7, 6]
null
[8, 7, 6]
null
[8, 7, 6]
6
[6, 8, 7]
7
[7, 6, 8]
8
[8, 7, 6]
null
[8, 7, 6]
3 分布式缓存应用
3.1 Redis、Memcached对比
1)数据类型:Redis 5种——string、list、hash、set、zset(跳跃表);
Memcache——只支持键值对;
2)线程模型:Redis——单线程,可以在单台机器部署多个实例;
Memcached——所线程(俩都是非阻塞I/O模型)
3)持久机制:Redis——RDB(定时持久)、AOF(基于操作日志)
4)高可用:Redis——支持主从节点复制配置
5)事务:Redis——支持事务
6)数据淘汰策略:Redis——丰富的淘汰策略;
Memcached——只有LRU策略
3.2 Redis集群
异步复制,数据发到主节点,然后异步复制到从节点。
Redis集群分片机制:Hash槽,总共16384个Hash槽,每个节点分摊一段。
一致性哈希:
把集群中的机器分布在0-2^32的圆上,如果要缓存一个数据,先计算数据的Key的哈希值,然后顺时针找到第一台机器。
3.3 应用层访问缓存的模式
1)双读双写:读操作先读缓存、读不到再读数据库同时回写缓存;写操作先写数据库再写缓存;
2)异步更新:应用层只读缓存、只写DB,然后用定时任务或binlog把DB数据同步到缓存;
3)串联:应用层读、写缓存,缓存再读、写DB(不推荐)
3.4 分布式缓存扩容迁移步骤
1)上双写:同时写新老缓存,新的按新分片规则,老的按老分片规则;
2)迁移历史数据:把老的数据按新规则迁移到新的分片;
3)切读:读操作从老分片切到新分片;
4)下双写:旧分片下线。
3.5 缓存穿透、缓存并发、缓存雪崩
1)缓存穿透:大量访问一个不存在的key。解决办法:把空值也缓存起来,缓存一个较短的时间;
2)缓存并发:一个缓存key过期时,因为访问量巨大导致瞬间都去请求数据库。解决办法:分布式锁、软过期;
3)缓存雪崩:大量缓存集中失效。解决办法:对过期时间加一个随机值。
4 本地缓存
