本章,我们讨论有关RabbitMQ的容错性,消息一致性及高可用性。RabbitMQ可以作为集群节点来运行,因此RabbitMQ通常被归为分布式消息系统,对于分布式消息系统,我们的关注点通常是一致性与可用性。
我们为什么要讨论分布式系统的一致性与可用性,本质在于两者描述的是系统在失败的情况下表现如何。在实际应用中,网络连接失败、服务器宕机,硬盘损坏,服务器由于GC暂时不可用,网络连接丢失或速度慢,所有这些异常都会导致数据中断、丢失或冲突等问题。事实证明,在所有的这些故障模式下,我们是无法同时兼顾最终一致性(无数据丢失,无数据差异)和可用性。系统一致性与可用性就像光的两端,你必须选择其中一种作为首要关注点。
本章,我们将深入讨论什么样的配置会导致确认写场景下的数据丢失。之前篇幅中我们有讨论,在生产者、代理节点和消费者之间存在一个消息传递的责任链关系,一旦消息被传递到代理节点,那么代理节点就要负责消息的安全性。当代理节点发送确认消息给生产者之后,我们期待的是消息不再丢失,但事实上,即便生产者收到了消息确认,消息依然存在丢失的可能性,这依赖于代理与生产者的实际配置如何。
单节点持久化原语
持久化消息队列/交换器
RabbitMQ支持两种类型的消息队列:持久化队列和非持久化队列,所有的队列都是将消息保存到Mnesia数据库中,区别在于在RabbitMQ服务节点启动时,持久化队列会重新声明,因此当节点重启、系统宕机或者系统异常失败时,只要数据仍在,那么队列仍然存在。相反的,非持久化队列和交换器在节点启动时会被删除。
持久化消息
声明了持久化队列并不意味着当节点重启时消息仍旧可以正常保存除非生产者将消息声明为持久化的。尽管持久化消息会加重消息代理负担,但如果实际业务场景无法接受消息丢失,那么,持久化消息也是不二之选。
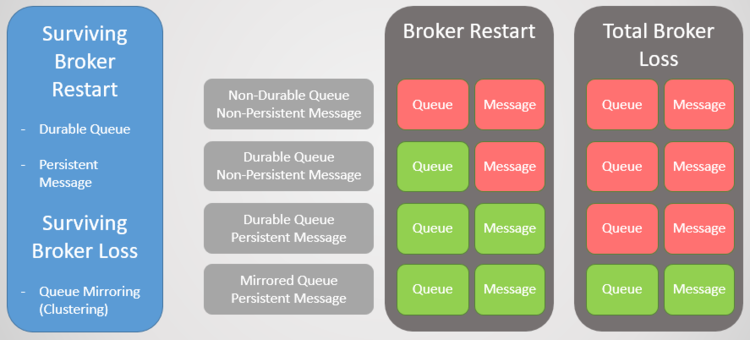
服务集群与队列镜像
为了避免单个消息代理异常出现的消息丢失,我们可以冗余处理。我们可以在一个服务集群中添加多个RabbitMQ节点,并通过跨多个服务节点复制队列实现消息冗余。在这种架构下,即便出现单个节点失败的情况也不会导致数据丢失的问题发生。
一个镜像队列包含以下内容:
-
一个主队列负责接收所有读和写
-
一个或多个队列镜像,镜像负责从主队列中接收所有的消息和元数据,镜像并不是为了扩展消息队列的读取性能,只是单纯的数据冗余而存在。
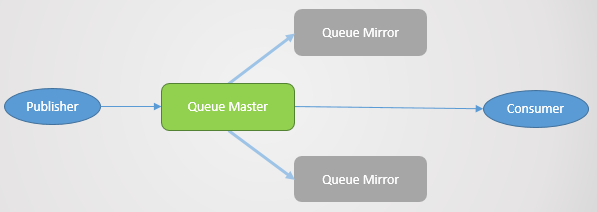
我们可以简单的通过设置策略即可实现队列镜像。比如,可以选择复制要素,甚至指定镜像队列所在节点:
-
ha-mode: all
-
ha-mode: exactly, ha-params: 2(one master and one mirror)
-
ha-mode: nodes, ha-params:rabbit@node1, rabbit@node2
生产者确认
为了达到一致性写的目的,我们需要生产者确认,否则可能会导致消息丢失。一旦消息被写到磁盘中,消息确认就会发送给生产者。注意,RabbitMQ并不是收到消息就执行消息写操作,而是基于定时(每几百毫秒之内)的消息写逻辑。对于镜像队列来说,只有所有的镜像都完成了消息写入时,才会发送确认消息,这也就是说,使用生产者确认机制会导致消息延迟,但如果业务场景关注的是消息的安全性,那么使用生产者确认也是非常必须的。
消息队列故障转移
当某个消息代理关闭或者宕机,位于当前节点上的所有主队列都会随之消失。接下来,集群会从剩下的镜像中选取新的队列,并将其提升为主队列。
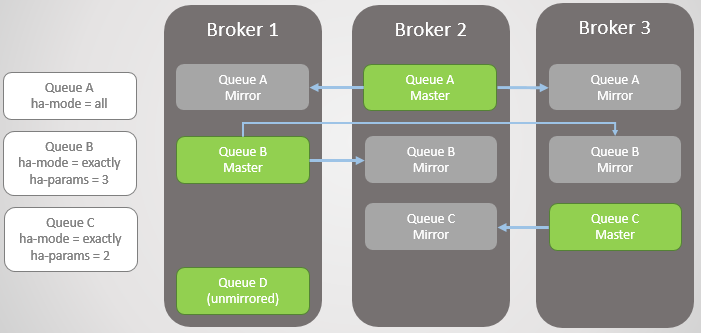
消息代理Broker 3宕机之后,Queue C在代理Broker 2上的镜像被提升为了主队列,同时在代理Broker 1创建了新的消息镜像,RabbitMQ会负责维护这种复制要素。
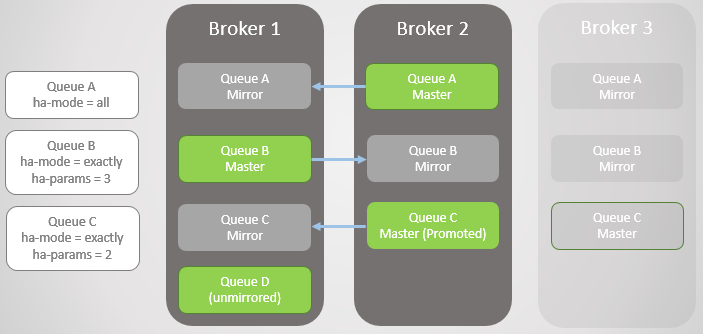
接下来,Broker 1宕机,我们只剩下Broker 2,Queue B镜像被提升为主队列。
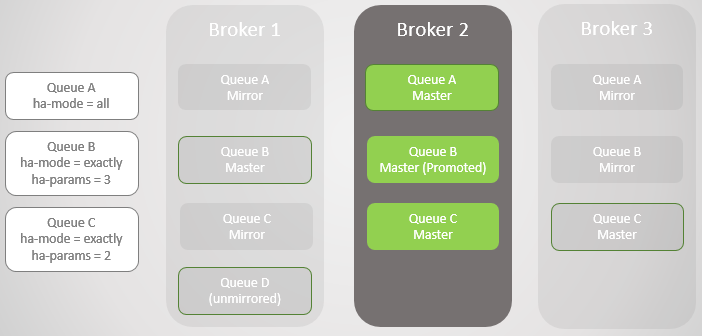
我们重启Broker 1,此时,无论当前节点上的数据是否得以恢复保留,所有的镜像队列消息都将在节点启动时丢弃。Broker 1作为集群节点成员重新加入集群,集群本身也会根据之前设定的复制策略重新在Broker 1上创建对应的队列镜像。本例中,Broker 1上的消息彻底丢失,因为队列Queue D没有镜像队列,因此,Queue D彻底丢失。
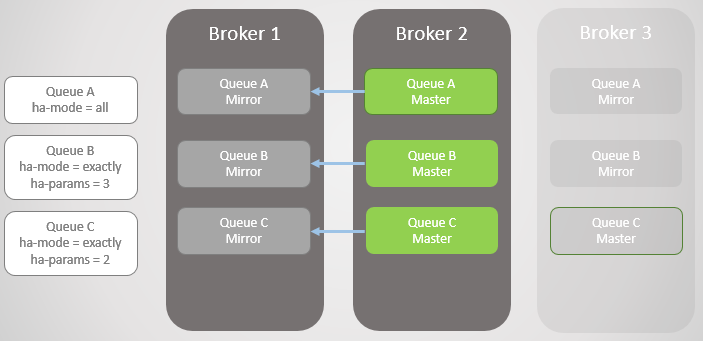
接下来,重启Broker3,对应的Queue A 和Queue B的镜像也会被创建,但,注意,此刻所有的主队列都是在一个服务节点上的,这当然不是理想状态,我们期待的是能将所有的主队列平均分布到所有节点上,但不幸的是,我们并没有很好的方法来实现重新分布主节点。关于这一点,我们在讨论队列同步时在讨论这个问题。
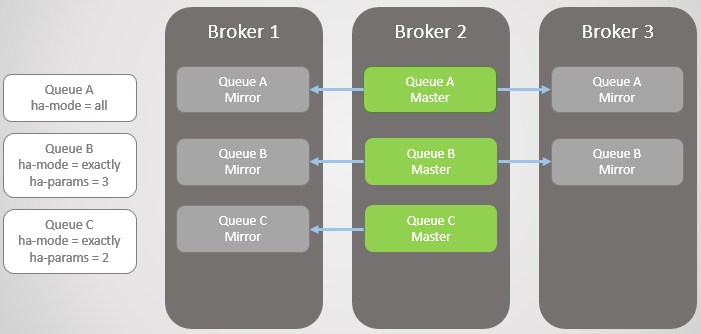
同步
当新的队列镜像创建后,所有的新消息都会被复制到镜像中来。至于主队列中的已有数据,我们可以选择复制,这样,新建镜像就是主队列的一个完全拷贝。也可以选择不复制,这样主队列和新建镜像随着时间的流转自动一致,因为新的消息会不断的加入到队尾,而队首已有的消息则会被不断处理移除。
队列与镜像间的消息同步既可以是自动同步的,也可以通过主动触发的,主要通过队列策略来控制实现。
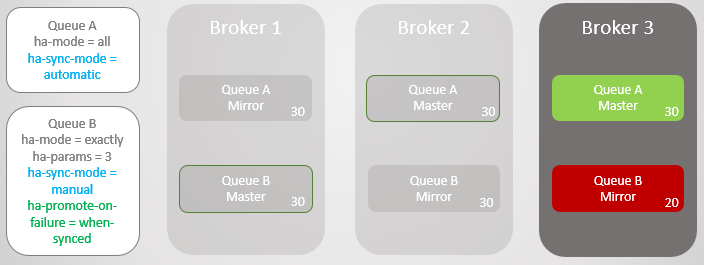
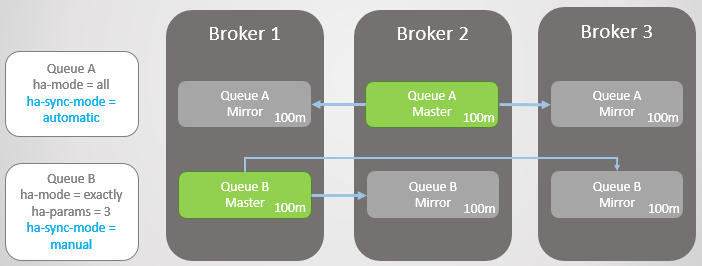
我们有两个镜像队列,Queue A设置了消息自动同步策略, Queue B设置的是主动触发同步策略,两个队列均有10条消息。
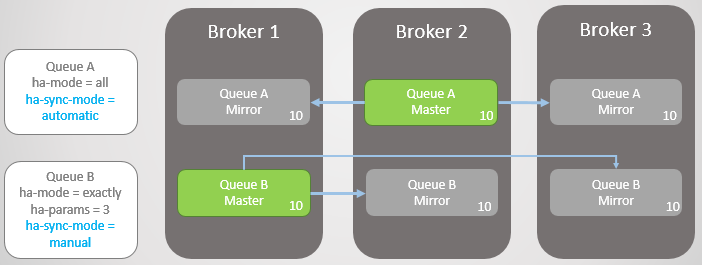
首先,我们让Broker 3下线。
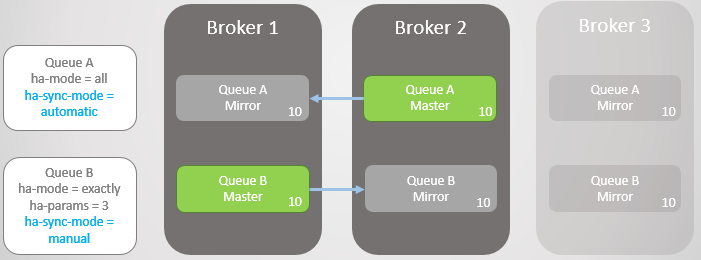
Broker 3重新上线,集群会在新的节点上为每一个队列重新创建一个消息镜像,对于Queue A镜像来说,消息自动同步。但Queue B镜像就是空队列。对于Queue A来说,自动同步带来的是消息全冗余,而对于Queue B来说,我们仅有一个镜像冗余。
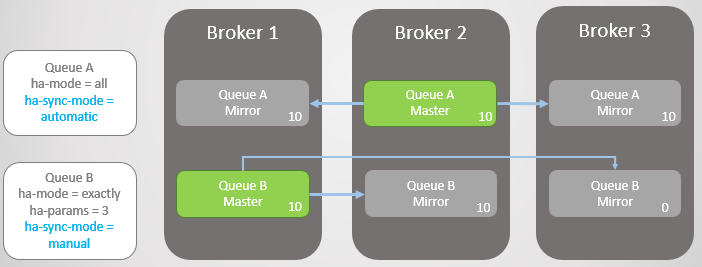
接下来,两个消息队列都收到了另外10条消息,此时,Broker 2下线,Queue A故障转移到Broker 1上,消息没有出现丢失,而对于Queue B来说,主队列有20条消息,而镜像却只有10条消息,并且永远无法从主队列复制到最初的10条消息。
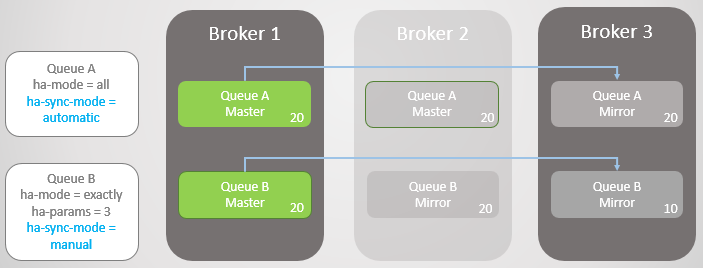
又有10条消息到来,Broker 1下线,对于Queue A来说故障转移并不会导致消息丢失,但对于Queue B来说,就出现了消息丢失的问题,因此,在这一点上,我们需要选择可用性或者是一致性。
如果我们侧重于可用性,那么我们需要设置ha-promote-on-failure为always,事实上,我们根本需要设置策略,因为默认情况下,RabbitMQ集群采取的就是这种策略。这种策略允许故障转移的情况下未同步镜像存在,可能存在消息丢失的情况但保留了队列的读写可用性。
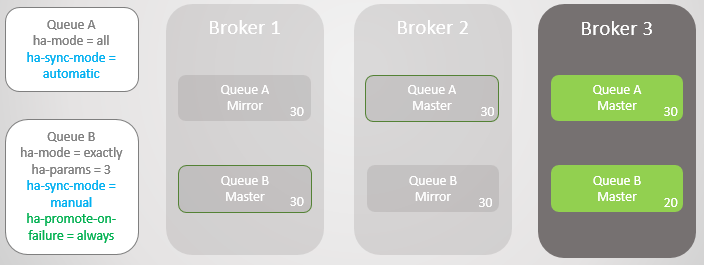
也可以设置ha-promote-on-failure为when-synced,这种策略将阻止主队列在Borker 1节点的队列进行故障转移,一直等待Broker 1重新数据无损上线,在此期间,队列将不可用。策略考虑了数据的安全性但牺牲了可用性。
这里有一个问题:为什么不采用自动同步策略?原因在于同步操作是阻塞操作,同步期间主队列无法执行任何读写操作。
我们看一个简单的例子,假设我们有一个非常大的队列。至于队列为什么这么大,可能有多个原因:
-
消费者未能有效处理
-
队列容量本身较大,且消费者处理效率不高
-
队列容量本身较大,期间发生中断,消费者正加紧处理中
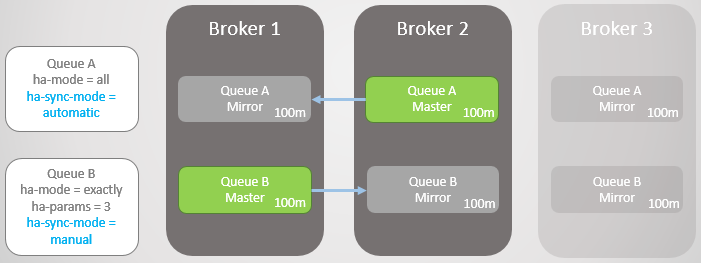
假设,Broker 3下线
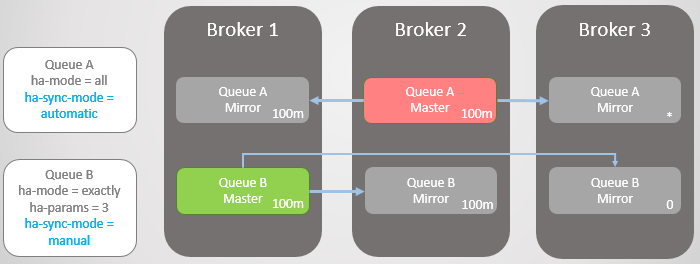
Broker 3重新上线,新的镜像被创建,Queue A主队列开始复制同步消息到新建镜像,在此期间,队列将不可用,假设同步耗时需要两个小时,那么就会导致两个小时的队列下线。但对于Queue B来说,其通过牺牲了部分冗余实现了可用性。
滚动升级
同步期间的阻塞行为使得具有大容量队列的集群的滚动升级成为问题。比如,主队列的宿主服务器需要重启,要么集群故障转移到镜像队列上,要么在升级期间队列不可用。如果我们选择故障转移,可能我们会丢失消息(镜像未同步),默认情况,在Broker下线期间,集群不会故障转移到未同步镜像(只剩一个镜像的除外),这也意味着当代理节点重新上线后,我们并不会丢失任何消息,唯一影响是队列的下线时间,我们可以通过一定的策略ha-promote-on-shutdown来控制下线行为:
-
always: 允许故障转移到未同步镜像
-
when-synced: 只有同步镜像存在才会执行故障转移,否则队列不可用,当代理重新上线之后,队列重新可用。
策略ha-promote-on-failure=when-synced的问题
ha-promote-on-failure = when-synced 策略通过避免故障转移至未同步镜像而避免了数据丢失,但,如果主队列宿主Broker丢失数据,那么就会有大问题,消息队列就会丢失所有的数据,即便有镜像已经基本和主队列同步,那些镜像也会被丢弃。所以,总结来讲,使用这种策略非常危险,其存在的意义在于数据安全性但本质上是一把双刃剑
主队列的再平衡操作
之前我们有谈到,当所有的主队列都分布在某个单一代理节点或者一组节点上会可能有问题。理想状态是主队列平均分布在各个节点上。
但,对主队列进行再平衡操作非常困难:
-
无有效的适合工具
-
队列同步
有第三方插件支持主队列的再平衡操作,但插件本身不受RabbitMQ官方支持,使用风险由自己承担。这里还有一个通过HA策略实现的移动主队列的技巧,具体可参考:https://github.com/rabbitmq/support-tools/blob/master/scripts/rebalance-queue-masters
网络分区(网络中断问题)
在分布式系统中,各个节点通过网络进行连接,说到网络,那么必然免不了断线,这依赖于实际内部架构或者所选云的可靠性,对于分布式系统来说,必须要能处理网络断线或者中断问题,当然这里又涉及到两个问题的选择:可用性与一致性。
对于RabbitMQ来说,我们主要有两个选择:
-
允许split-brain:这种模式下,可用性有保证但可能会带来数据丢失。
-
不允许split-brain:可能带来短暂的队列不可用。
这里解释下split-brain的含义:因为网络连接的原因,集群被一份为二,在每个分区中,都有镜像被提升为主队列,这也就意味着对于每一个队列我们可能有多个主队列存在。如果生产者将消息成功写入两个主队列中,那么我们就会有两个不同的队列拷贝。
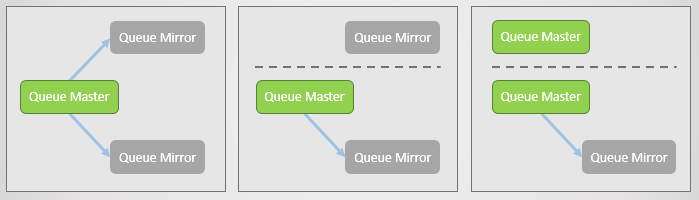
RabbitMQ提供了不同分区模式来处理split-brain场景,不同的模式侧重点不同
Ignore Model:默认模式
这种模式强调的是可用性,当网络分区产生时,随之带来split-brain,当分区消失后,管理者必须决定启用哪个分区,对应的另一个分区的节点则需要重启,对应的所有数据则将丢失。
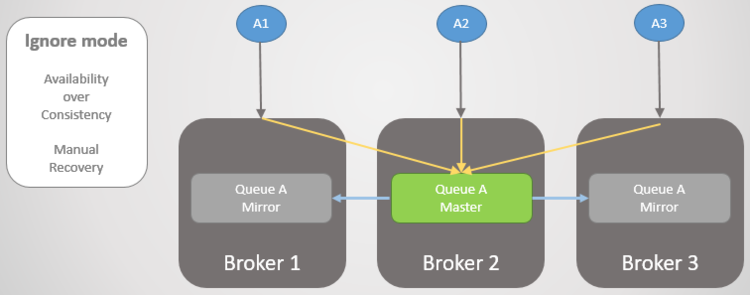
网络分区发生,Broker 3 从集群中剥离,Broker 3无法探测到其他节点,将自己的镜像队列提升为主队列
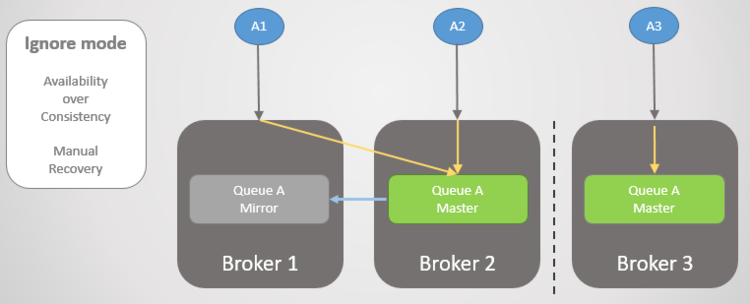
分区消除,但split-brain 仍旧存在,管理者必须通过选择丢弃某个分区来主动消除split-brain的发生,下图选择了放弃Broker 3,在这种情况下,任何在Broker 3上的尚未被处理的消息会随着Broker 3的重新加入集群而丢失。
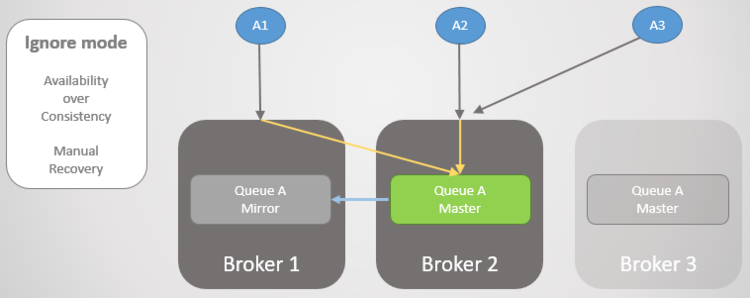

Autoheal Mode
与Ignore Model一致,除了集群会自动选择哪个分区,未选择分区会重新加入到集群中,所有仅发送到未选择分区且未处理的消息则被丢弃。
Pause Minority
如果我们不允许split-brain场景,我们可以在分区的少数侧拒绝读写操作,当代理判断出其位于分区的少数侧,则执行暂停操作,关闭当前连接,并拒绝新的连接请求。然后,代理会每隔一秒中执行一次检测,确认分区是否已经消除,一旦分区消除,那么代理会自行启动自己并重新加入到集群中来。

网络分区导致Broker 3与Broker 1,2 分开,Broker 3并没有将自己提升为主队列,而是中止自己为不可用

分区消除,Broker 3重新加入到集群中来
让我们看下另一个例子,主队列位于Broker 3上的场景。

同样的网络分区发生,Broker 3上的队列中止,主要侧节点Broker 1 ,2上最早的队列镜像被提升为主队列。

分区消除,Broker 3重新加入到集群中来

客户端连接保证
对于客户端来说,我们可以有一些方式来设置客户端连接到分区的主要一侧,或者连接到那些存活的节点。注意,对于一个给定的队列来说,其肯定位于某个指定的代理节点上,但交换器和策略则是跨节点复制的。客户端可以链接到任意节点上,内部路由策略可以确保客户端连接到正确的服务节点上。但当一个节点中止,它就会拒绝连接,因此客户端也必须连接到其他节点上。当服务节点主动断开客户端连接,对于客户端来说也是无可奈何的。
因此,对于客户端来说,这里有一些操作实践:
-
通过负载均衡连接集群节点,当某个节点出现无法连接之后(网络中断或者节点宕机),负载均衡器会一直尝试可以正常连接的节点,直到获取到正确的服务连接,并且连接获取之后不会再去尝试其他服务节点,这种策略对于短期网络中断或者宕机节点迅速恢复的场景非常适用。
-
通过负载均衡连接集群节点,一旦检测到有中止节点或者宕机节点,则立即将该节点从节点列表中删除。如果我们可以迅速做出重试操作,那么就可以获取连贯的节点可用性。
-
由每一个客户端维护一个节点列表,客户端随机选择连接目标,直至可以正常获取连接。
-
使用DNS避免访问中止或者宕机节点,这需要一个小的TTL
结论
对于需要使用RabbitMQ集群来说,以下两个问题不容忽视:
-
重新加入集群的节点会丢弃之前的数据
-
消息同步是阻塞操作,从而引起一定时间内的队列不可用。
当有以下场景时,我们不建议使用RabbitMQ集群:
-
网络状态较差
-
存储不理想
-
消息队列过大
考虑到RabbitMQ集群的高可用性,我们可以考虑如下RabbitMQ设置:
-
ha-promote-on-failure=always
-
ha-sync-mode=manual
-
cluster_partition_handling=ignore or autoheal
-
持久化消息
-
当集群中某个节点宕机,确保客户端可以正确的连接到剩余存活节点
考虑到消息一致性、可靠性,我们可以考虑如下设置:
-
使用生产者确认或者消费者一侧的主动确认
-
ha-promote-on-failure=when-synced,前提是消息存储可靠,并且生产者具备稍后重试的能力,否则的话,使用always选项
-
ha-sync-mode=automatic ,但对于非活跃的大容量队列来说,建议考虑主动模式,且需要考虑不可用是否会导致消息丢失
-
Pause Minority mode
-
持久化消息
