虚拟文件系统的思想是把能表示很多不同种类文件系统的共同信息放入内核;
其中有一个字段或函数来支持 Linux 所支持的所有实际文件系统所提供的操作。
虚拟文件系统(VFS)的作用
虚拟文件系统也可称为虚拟文件转换,是一个内核软件层,用来处理与 Unix 标准文件系统相关的所有系统调用。
VFS 能为各种文件系统提供一个通用的接口。
VFS 支持三种主要类型的文件系统:
- 磁盘文件系统。如 Ext2、Ext3、System V 等。这些文件系统管理本地磁盘分区中可用的存储空间或者其他可起到磁盘作用的设备(USB 闪存)。
- 网络文件系统。如 NFS、Coda 等。这些文件系统允许轻易地访问属于其他计算机的文件系统所包含的文件。
- 特殊文件系统。如 /proc 文件系统等。这些文件系统不管理本地或者远程磁盘空间。
Unix 的目录建立了一棵目录为“/”的树。
根目录包含在根文件系统中,Linux 通常为 Ext2 或 Ext3。
其他文件系统可以被“安装”在根文件系统的子目录中。
基于磁盘的文件系统通常存放在硬件块设备中,如磁盘、软盘或 CD-ROM。
Linux VFS 能处理如 /dev/loop0 这样的虚拟块设备,这种设备可用来安装普通文件所在的文件系统。
通用文件模型
VFS 所隐含的主要思想在于引入了一个通用的文件模型,该模型能表示所有支持的文件系统。
要实现每个具体的文件系统,必须将其物理组织结构转换为虚拟文件系统的通用文件模型。
本质上,Linux 内核不能对一个特定的函数进行硬编码来执行如 read() 或 ioctl() 这样的操作,而是对每个操作都必须使用一个指针,指向要访问的具体文件系统的函数。
可将通用文件模型看作是面向对象的,出于效率考虑,采用普通的 C 数据结构实现。
普通文件模型由下列对象类型组成:
- 超级块对象,存放已安装文件系统的有关信息。对基于磁盘的文件系统,该对象通常对应于存放在磁盘上的文件系统控制块。
- 索引节点对象,存放关于具体文件的一般信息。对基于磁盘的文件系统,通常对应于存放在磁盘上的文件控制块。
每个索引节点对象都有一个索引节点号,该节点号唯一标识文件系统中的文件。
- 文件对象,存放打开文件与进程之间进行交互的有关信息。这些信息仅当进程访问文件期间存放在内核中。
- 目录项对象,存放目录项与对应文件进行链接的有关信息。每个磁盘文件系统都有自己特有的方式将该类信息存放在磁盘上。
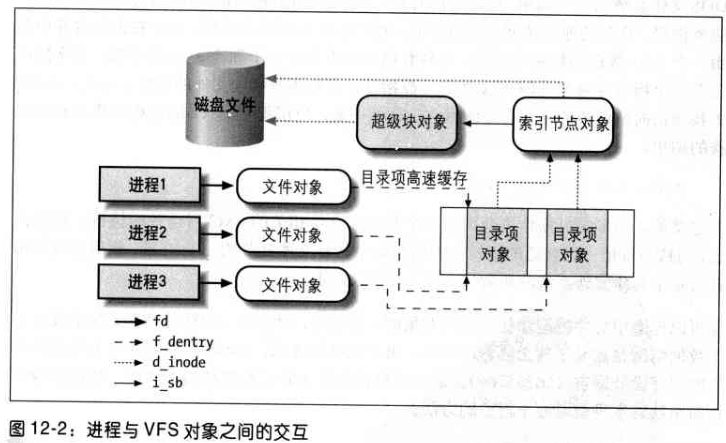
图中,三个进程打开同一个文件,其中两个进程使用同一个硬链接。
每个进程都使用自己的文件对象,但只需要两个目录项对象,每个硬链接对应一个目录对象。
这两个目录对象指向同一个索引节点对象,该索引节点对象标识超级块对象,以及随后的普通磁盘文件。
最近最常使用的目录项对象被放在称为目录高速缓存的磁盘高速缓存中,以加速从文件路径名到最后一个路径分量的索引节点的转换过程。
一般,磁盘高速缓存属于软件机制,它允许内核将原本存在磁盘上的某些信息保存在 RAM 中。
磁盘高速缓存不同于硬件高速缓存或内存高速缓存,后两者都与磁盘或其他设备无关。
硬件高速缓存是一个快速 RAM,加快了直接对慢速动态 RAM 的请求。
内存高速缓存是一种软件机制,引入它是为了绕过内核内存分配器。
除了目录项高速缓存和索引节点高速缓存,还有其他磁盘高速缓存,如页高速缓存。
VFS 处理的系统调用
某些情况下,一个文件操作可能由 VFS 本身去执行,无需调用底层函数。
如,当某个进程关闭一个打开的文件时,不需要涉及磁盘上的相应文件,VFS 只需释放对应的文件对象即可。
VFS 的数据结构
超级块对象
超级块对象由 super_block 结构组成。
所有超级块对象都存放在双向循环链表中。
super_block 的某些字段:
- s_list,链表相邻元素的指针。
- s_lock,自旋锁,保护链表免受多处理器系统的同时访问。
- s_fs_info,指向属于具体文件系统的超级块信息。假如超级块对象指的是 Ext2 文件系统,该字段就指向 ext2_sb_info 数据结构,该结构包括磁盘分配位掩码和其他与 VFS 的通用文件模型无关的数据。
- s_dirt,标识该超级块是否为脏。通常,为效率起见,s_fs_info 字段指向的数据被复制到内存,可能导致 VFS 超级块不再与磁盘上相应的超级块同步。
- s_op,超级块操作,由数据结构 super_operations 描述。
索引节点对象
存放文件系统处理文件所需要的所有信息。
文件名可随时更改,但索引节点对文件是唯一的,并且随文件的存在而存在。
内存中的索引节对象由一个 inode 数据结构组成。
每个索引节点对象都会复制磁盘索引节点包含的一些数据,比如分配给文件的磁盘块数。
inode 的某些字段:
- i_state,如果等于 I_DIRTY_SYNC、I_DIRTY_DATASYNC 或 I_DIRTY_PAGES,该索引节点就是“脏“的,对应的磁盘索引节点必须被更新。
I_DIRTY 宏可检测这三个标志的值。
i_state 字段的其他值:
-
- I_LOCK(涉及的索引节对象处于 I/O 传送中)
-
- I_FREEING(索引节点对象正在被释放)
-
- I_CLEAR(索引节对象的内容不再有意义)
-
- I__NEW(索引节对象已经分配但还灭有从磁盘索引节点读取来的数据填充)。
- i_list,每个索引节对象总是出现在双向循环链表的某个链表中,i_list 字段指向相邻元素。
- i_sb_list,每个索引节点对象也包含在每文件系统的双向循环链表中,链表的头存放在超级块对象的 s_indoes 字段;索引节点对象的 i_sb_list 字段指向相邻元素。
- i_hash,索引节点对象也存放在一个称为 inode_hashtable 的散列表中。散列表加快了对索引节对象的搜索,前提是系统内核知道索引节点号及文件所在文件系统对应的超级块对象的地址。
索引节点对象的 i_hash 用来解决散列冲突,它包括指向前、后的指针。
- i_op,索引节点操作,inode_operation 结构类型。
索引节点双向循环链表的种类:
- 有效未使用的索引节的链表。这些索引节点不为脏,且它们的 i_count 字段为 0。
链表中的首元素和尾元素由变量 inode_ununsed 的 next 字段和 prev 字段分别指向。
该链表用作磁盘高速缓存。
- 正在使用的索引节点链表。这些索引节的不为脏,但它们的 i_count 字段为正数。
链表中的首元素和尾元素由变量 inode_in_use 引用。
- 脏索引节的链表。链表中的首元素和尾元素分别由相应超级块对象的 s_dirty 字段引用。
文件对象
文件对象描述进程怎样与一个打开的文件进行交互。
文件对象是在文件被打开时创建的,由一个 file 结构组成。
文件对象在磁盘上没有对应的映像,因此 file 结构中没有设置”脏“字段来表示文件对象是否已经被修改。
存放在文件对象中的主要信息是文件指针,即文件中当前的位置,下一个操作将在该位置发生。
由于几个进程可能同时访问同一文件,因此文件指针必须存放在文件对象而不是索引节点对象。
文件对象通过一个名为 filp 的 slab 高速缓存分配,filp 描述符地址存放在 filp_cachep 变量中。
files_stat 变量在其 max_files 字段中指定了可分配文件对象的最大数目,即系统可同时访问的最大文件数。
file 的某些字段:
- f_list,“在使用”文件对象包含于被具体文件系统的超级块确立的几个链表中。
每个超级块对象把文件对象链表的头存放在 s_files 字段。
链表中分别指向前一个和后一个元素的指针存放在文件对象的 字段。
files_lock 自旋锁保护超级块的 s_files 链表免受多处理器系统上的同时访问。
- f_count,是一个引用计数器,记录使用文件对象的进程数(CLONE_FILES 标志创建的轻量级级进程共享打开文件表,因此可使用相同的文件对象)。
内核本身使用该文件对象时也要增加计数器的值,如,把对象插入链表中或发出 dup() 系统调用。
- f_op,文件操作集合。当内核将一个索引节点从磁盘装入内存时,就会把指向这些文件操作的指针存放在在索引节点对象的 i_fop 字段。
进程打开该文件时,VFS 用索引节的 i_fop 字段初始化文件对象的 f_op 字段。
如果需要,VFS 也可通过在 f_op 字段存放一个新值而修改文件操作的集合。
VFS 代表进程打开一个文件时,调用 get_emtpy_filp() 分配一个新的文件对象。
该函数调用 kmem_cache_alloc() 从 filp 高速缓存中获得一个空闲的文件对象,然后初始化该对象的字段:
2
3
4
5
6
7
8
9
10
11
2INIT_LIST_HEAD(&f->f_ep_links);
3spin_lock_init(&f->f_ep_lock);
4atomic_set(&f->f_count, 1);
5f->f_uid = current->fsuid;
6f->f_gid = current->fsgid;
7f->f_owner.lock = RW_LOCK_UNLOCKED;
8INIT_LIST_HEAD(&f->f_list);
9f->f_maxcount = INT_MAX;
10
11
目录项对象
VFS 把每个目录看作由若干子目录和文件组成的一个普通文件。
当目录项被读入内存,VFS 就把他转换成基于 dentry 结构的一个目录项对象。
对于进程查找的路径名的中的每个分量,内核都为其创建一个目录项对象;目录项对象将每个分量与其对应的索引节点相联系。
目录项对象在磁盘上没有对应的映像,因此在 dentry 结构中不包含“dirty”字段。
目录项对象存放在名为 dentry_cache 的 slab 分配器高速缓存中。
因此,目录项对象的创建和删除是通过调用 kmem_cache_alloc() 和 kmem_cache_free() 实现的。
每个目录项对象可以处于以下四种状态之一:
- 空闲状态,不包括有效信息,且没有被 VFS 使用。对应的内存区由 slab 分配器进行处理。
- 未使用状态,当前还没有被内核使用。该对象的引用计数器 d_count 为 0,但其 d_inode 字段指向关联的索引节点。
该目录项对象包含有效的信息,但为了在必要时回收内存,它的内容可能被丢弃。
- 正在使用状态,当前正在被内核使用。该对象的引用计数器 d_count 为正数,其 d_inode 字段指向关联的索引节点对象。该目录项对象包含有效的信息,且不能被丢弃。
- 负状态,与目录项关联的索引节点不存在,或因为相应的磁盘索引节点已被删除,或因为目录项对象是通过解析一个不存在的路径名创建的。
目录项对象的 d_inode 字段为 NULL,但该对象仍被保存在目录项高速缓存中,以便迅速完成后续对同一文件目录名的查找操作。
与目录项对象关联的方法称为目录项操作,由 dentry_operatinos 结构描述,存放于 d_op 字段。
目录项高速缓存
为了最大限度地提高处理目录对象的效率,Linux 使用目录项高速缓存,它由两种类型的数据结构组成:
- 一个处于正在使用、未使用或负状态的目录项对象的集合。
- 一个散列表,从中能快速获取与给定的文件名和目录名对应的目录项对象。不在目录项高速缓存中时,返回空值。
目录项高速缓存还相当于索引节点高速缓存的控制器。
在内核中,并不丢弃与目录项相关的索引节点,因为目录项高速缓存仍在使用它们。
因此,这些索引节点对象保存在 RAM 中,并能够借助相应的目录项快速索引。
所有“未使用”目录项对象都存放在一个“最近最少使用”的双向链表中,该链表按照插入的时间排序。
即最后释放的目录对象放在链表的首部,所以最近最少使用的目录项对象总是靠近链表的尾部。
一旦目录项高速缓存的空间开始变小,内核就从链表的尾部删除元素,使得最近最常使用的对象得以保留。
LRU 链表的首元素和尾元素的地址存放在 list_head 类型的 dentry_unsed 变量的 next 字段和 prev 字段中。
目录项对象的 d_lru 字段指向相邻元素。
每个“正在使用”的目录项对象都被插入一个双向链表中,该链表由一个索引节点对象的 i_dentry 字段指向。
目录项对象的 d_alias 字段指向相邻元素。
这两个字段的类型都是 struct list_head。
当指向文件的最后一个硬链接被删除,一个“正在使用”的 目录项对象可能变成“负状态”。
这种情况下,该目录项对象被移到“未使用”目录项对象组成的 LRU 链表中。
每当内核缩减目录项高速缓存时,“负状态”目录项对象就朝着 LRU 链表的尾部移动,导致对象被逐渐释放。
散列表是由 dentry_hashtable 数组实现的。
数组中的每个元素是一个指向链表的指针,这种链表就是把具有相同散列表值的目录项进行散列而形成的。
该数组的长度取决于系统已安装 RAM 的数量;缺省值是每兆字节 RAM 包含 256 个元素。
目录项对象的 d_hash 字段指向具有相同散列值的链表中的相邻元素。
散列函数产生的值是由目录的目录项对象及文件名计算出来的。
dcache_lock 自旋锁保护目录项高速缓存数据结构免受多处理器系统的同时访问。
d_loolup() 在散列表中查找给定的父目录项对象和文件名;为避免发生竞争,使用顺序锁。
__d_lookup() 与之类似,但它假定不会发生竞争,因此不使用顺序锁。
与进程相关的文件
进程描述符的字段:
- fs,为 fs_struct 结构类型,指向进程当前的工作目录和根目录。
- files,为 files_struct 结构类型,表示进程当前打开的文件。
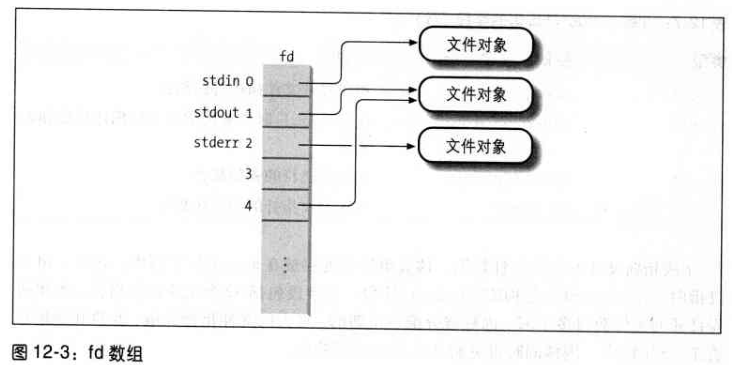
- fd,为文件对象的指针数组。通常,fd 字段指向 files_struct 结构的 fd_array 字段,该字段包括 32 个文件对象指针。
- max_fds,文件对象的指针数组的长度。如果进程打开的文件数多于 32, 内核就分配一个新的、更大的文件指针数组,并将其地址存放在 fd 字段,内核同时更新 max_fds 字段的值。
对于在 fd 数组中由元素的每个文件来说,数组的索引就是文件描述符。
通常,数组的第一个元素(索引为 0)是进程的标准输入文件,
数组的第二个元素(索引为 1)是进程的标准输出文件,
数组的第三个元素(索引为 2)是进程的标准错误文件。
Unix 进程将文件描述符作为主文件标识符。
借助于 dup()、dup2() 和 fcntl(),两个文件描述符可以指向同一个打开的文件,
即数组的两个元素可能指向同一个文件对象,比如重定向。
进程不能使用多于 NR_OPEN 个文件描述符。
内核也在进程描述符的 signal->rlim[RLIMIT_NOFILE] 结构上强制动态限制文件描述符的最大数;
该值通常为 1024,但是如果进程具有超级用户特权,就可以增大该值。
- open_fds 最初包含 open_fds_init 字段的地址,open_fds_init 字段表示当前已打文件的文件描述符的位图。
- max_fdset 字段存放位图中的位数。
由于 fd_set 数据结构有 1024 位,所以通常不需要扩大位图的大小。
不过,必要时,内核仍能动态增加位图的大小。
当内核通过 fget() 开始使用一个文件对象。
该函数参数为文件描述符 fd,返回在 current->files->fd[fd] 中的地址,即对那个文件对象的地址,并将文件对象引用计数器 f_count 的值增 1。
如果没有任何文件与 fd 对应,返回 NULL 。
内核控制路径通过 fput() 完成对文件对象的使用 。
该函数的参数为将文件对象的地址,减少文件对象应用计数器 f_count 的值。
另外,如果 f_count 变为 0,就调用文件操作的 release 方法,减少索引节点对象的 i_write_count 字段的值,将文件对象从超级块链表移走,释放文件对象到 slab 分配器,最后减少相关的文件描述符的目录项对象的引用计数器的值。
fget_light() 和 fput_light() 是 fget() 和 fput() 的快速版本:
内核要使用它们,前提是能安全地假设当前进程已经拥有文件对象,即进程先前已经增加了文对象引用计数器的值。
文件系统类型
文件系统注册–通常在系统初始化器间并且使用文件系统类型前必须执行的基本操作。
一旦文件系统被注册,其特定的函数对内核就是可用的,因此文件系统类型可安装在系统的目录树上。
特殊文件系统
当网络和磁盘文件系统能够使用用户处理存放在内核之外的信息时,特殊文件系可以为系统程序员和管理员提供一种容易的方式来操作内核的数据结构并实现操作系统的特殊特征。
特殊文件系统不限于物理块设备。
然而,内核给每个安装的特殊文件系统分配一个虚拟的块设备,让其主设备号为 0 而次设备号具有任意值。
set_anon_super() 初始化特殊文件系统的超级块;
该函数本质上获得一个未使用的次设备号 dev,然后用主设备号 0 和次设备号 dev 设置超级块的 s_dev 字段。
kill_anon_super() 移走特殊系统的超级块。
文件系统注册类型
VFS 必须对代码目前已在内核中的所有文件系统的类型进行跟踪。
这通过文件系统类型注册实现。
每个注册的文件系统都用一个类型为 file_system_type 的对象表示。
所有文件系统类型的对象都插入一个单向链表,变量 file_systems 指向链表的第一个元素。
file_systems_lock 读/写自旋锁保护整个链表免受同时访问。
file_system_type 的一些字段:
- fs_supers,表示给定类型的已安装文件系统所对应的超级块链表的头。
链表元素的向后和向前链接存放在超级块对象的 s_instances 字段。
- get_sb,指向依赖于文件系统类型的函数,该函数分配一个新的超级块对象并初始化它。
- kill_sb,指向删除超级块的函数。
- fs_flags,存放几个标志。
在系统初始化器间,register_filesystem() 注册编译时指定的每个文件系统:
该函数把相应的 file_system_type 对象插入到文件系统类型的链表。
当文件系统的模块被装入时,也要调用 register_filesystem()。
当该模块被卸载时,对应的文件系统也可以被注销。
get_fs_type() 扫描已注册的文件系统链表以查找文件系统类型的 name 字段,并返回指向相应的 file_system_type 对象的指针。
文件系统处理
Linux 使用系统的根文件系统:它由内核在引导阶段直接安装,并拥有系统初始化脚本以及最基本的系统程序。
其他文件系统要么由初始化脚本安装,要么由用户直接安装在已安装文件系统的目录上。
作为一个目录树,每个文件系统都拥有自己的根目录。
安装文件系统的目录称为安装点。
已安装文件系统属于安装点目录的一个子文件系统。
命名空间
每个进程可拥有自己的安装文件系统树—叫做进程的命名空间。
通常大多数进程共享一个命名空间,即位于系统的根文件系统且被 init 进程使用的已安装文件系统树。
不过,clone() 以 CLONE_NEWS 标志创建一个新进程,那么进程将获取一个新的命名空间。
该新的命名空间随后由子进程继承。
当进程安装或卸载一个文件系统时,仅修改它的命名空间。
因此,所作的修改对共享同一命名空间的所有进程都是可见的,且只对它们可见。
进程甚至可用通过 Linux 特有的 pivot_root() 系统调用来改变它的命名空间的根文件系统。
进程的命名空间由进程描述符的 namespace 字段指向的 namespace 结构描述。
namespace 的一些字段:
- list,是双向循环链表的头,该表聚集了属于命名空间的所有已安装文件系统。
- root,命名空间中的已安装文件系统树的根。已安装文件系统由 vfsmount 结构描述。
文件系统安装
在 Linux 中,同一个文件系统可被多次安装。
如果一个文件系统被安装了 n 次,那么它的根目录就可通过 n 个安装点访问。
但文件系统的确是唯一的,因此,不管一个文件系统被安装了多少次,都仅有一个超级块对象。
安装的文件系统形成一个层次:一个文件系统的安装点可能成为第二个文件系统的目录。
而第三个文件系统又安装在第二个文件系统之上,等等。
把多个安装堆叠在一个单独的安装点上也是可能的。
当最顶层的安装被删除时,下一层的安装再一次变为可见。
跟踪已安装的文件系统:
对于每个安装操作,内核必须在内存中保存安装点和安装标志,以及要安装文件系统与其他已安装文件系统之间的关系。
这样的信息保存在已安装文件系统描述符中:每个描述符是一个具有 vfsmout 类型的数据结构。
vfsmount 数据结构保存在几个双向循环链表中:
- 一个散列表,根据父文件系统的 vfsmount 描述符的地址和安装点目录的目录项对象的地址进行索引。
散列表存放在 mount_hashtable 数组中,其大小取决于系统中 RAM 的容量。
表中每一项是具有同一散列值的所有描述符形成的双向循环链表的头。
描述符的 mnt_hash 字段指向链表中的相邻元素。
- 对于每个命名空间,所有属于此命名空间的已安装的文件系统描述符形成了一个双向循环链表。
namespace 的 list 字段为链表头,vfsmount 描述符的 mnt_list 字段指向链表中的相邻元素。
- 对于每个已安装的文件系统,所有已安装的子文件系统形成了一个双向循环链表。
每个链表的头存放已安装的文件描述符的 mnt_mounts 字段;描述符的 mnt_child 字段指向链表中的相邻元素。
vfsmount 的几个字段:
- vfsmount_lock,自旋锁,保护已安装文件系统对象的链表免受同时访问。
- mnt_flags,存放几个标志的值,用以指定如何处理已安装文件系统中的某些种类的文件。这些标志可通过 mount 命令的选项进行设置。
安装普通文件系统
mount() 被用来安装一个普通文件系统,它的服务例程 sys_mount 作用于以下参数:
- 文件系统所在设备文件的路径名,可为 NULL
- 安装点
- 文件系统的类型,必须是已注册文件系统的名字
- 安装标志
- 指向一个与文件系统相关的数据结构的指针(可为 NULL)
sys_mount() 把参数的值拷贝到临时内核缓冲区,获得大内核锁,并调用 do_mount()。
一旦 do_mount() 返回,该服务例程就释放大内核锁并释放临时内核缓冲区。
do_mount() 的安装操作:
- 如果安装标志 MS_NOSUID、MS_NODEV 或 MS_NOEXEC 中任一个被设置,则清除它们,并在已安装文件系统对象中设置相应的标志(MNT_NOSUID、MNT_NODEV、MNT_NOEXEC)。
- 调用 path_lookup() 查找安装点的路径名,把结果存放在 nameidata 类型的局部变量 nd 中。
- 检查安装标志以决定做什么。尤其是:
a. 如果 MS_REMOUNT 标志被指定,do_remount() 改变超级块对象 s_flags 字段的安装标志,以及安装文件系统对象 mnt_flags 字段的安装文件系统标志。
b. 否则,检查 MS_BIND 标志。如果它被指定,则用户要求在系统目录树的另一个安装点上的文件或目录能够可见。
c. 否则,检查 MS_MOVE 标志。如果它被指定,do_move_mount() 原子地完成改变已安装文件系统的安装点。
d. 否则,调用 do_new_mount()。这是最普通的情况,用户要求安装一个特殊系统或存放在磁盘分区中的普通文件系统。
它调用 do_kern_mount(),给它传递的参数为文件系统类型、安装标志以及块设备名。
do_kern_mount() 处理实际的安装操作并返回一个新安装文件系统描述符的地址。
然后,do_new_mont() 调用 do_add_mount(),后者本质上执行下列操作:
(1)获得当前进程的写信号号量 namesapce->sem,以修改 namespace 结构。
(2)验证在该安装点上最近安装的文件系统是否仍指向当前的 namespace;
如果不是,则释放读/写信号量并返回一个错误码。
因为 do_kern_mount() 可能让当前进程睡眠;同时,另一个进程可能在完全相同的安装点上安装文件系统甚至更改根文件系统(current->namesapce->root)。
(3)如果要安装的文件系统已经被安装在由系统调用的参数所指定的安装点上,或该安装点是一个符号链接,则释放读/写信号量并返回一个错误码。
(4)初始化由 do_kern_mount() 分配的新安装文件系统对象的 mnt_flags 字段。
(5)调用 graft_tree() 把新安装的文件系统对象插入到 namespace 链表、散列表及父文件系统的子链表中。
(6)释放 namespace->sem 读/写信号量并返回。
- 调用 path_release() 终止安装点的路名查找,并返回 0.
do_kern_mount()
安装操作的核心是 do_kern_mount(),它检查文件系统类型标志以决定安装操作是如何完成的。
参数:
- fstype,要安装的文件系统的类型名。
- flags,安装标志。
- name,存放文件系统的块设备的路径名(或特殊文件系统的类型名)。
- data,指向传递给文件系统的 read_super 方法的附加数据的指针。
本质上,该函数执行下列实际的安装操作:
- 调用 get_fs_type() 在文件系统类型链表中搜索并确定存放在 fstype 参数中的名字的位置;返回局部变量 type 中对应 file_system_type 描述符的地址。
- 调用 alloc_vfsmnt() 分配一新的已安装文件系统的描述符,并将它的地址存放在 mnt 局部变量中。
- 调用依赖于于文件系统的 type->get_sb() 分配并初始化一个新的超级块。
- mnt->mnt_sb = 新超级块对象的地址。
- mnt->mnt_root = 与文件系统根目录对应的目录项对象的地址,并增加该目录项对象的引用计数器值。
- mnt->mnt_parent = mnt。
- mnt->mnt_namespace = current->namespace。
- 释放超级块对象的读/写信号量 s_umount。
- 返回已安装文件系统对象的地址 mnt。
分配超级块对象
文件系统对象的 get_sb 方法通常由单行函数实现,如 Ext 2 中的实现:
2
3
4
5
6
2{
3 return get_sb_bdev(type, flags, dev_name, data, ext2_file_super);
4}
5
6
get_sb_bdev() VFS 函数分配并初始化一个新的适合于磁盘文件系的超级块;
它接收 ext2_fill_super() 函数的地址,该函数从 Ext2 磁盘分区读取磁盘超级块。
get_sb_bdev() 执行如下操作:
- open_bdev_excl() 打开设备文件名为 dev_name 的块设备(字符设备)。
- sget() 搜索文件系统的超级块对象链表。
如果找第一个与块设备相关的超级块,则返回它的地址。
否则,分配并初始化一个新的超级块对象,把它插入到文件系统链表和超级块全局链表中,并返回其地址。
- 超级块的 s_flags = 参数 flags,并将 s_id、s_old_blocksize 及 s_blocksize 字段设置为块设备的合适值。
- 调用依赖于文件系统的函数访问磁盘上的超级块信息,并填充新超级块对象的其他字段。
- 返回新超级块对象的地址。
安装根文件系统
安装根文件系统是系统初始化的关键部分。
安装根文件系统分两个阶段:
- 内核安装特殊 rootfs 文件系统,该文件系统仅提供一个作为初始安装点的空目录。
- 内核在空目录上安装实际根文件系统。
rootfs 文件系统使得内核较容易地改变实际根文件系统。
阶段1:安装 rootfs 文件系统
第一阶段由 init_rootfs() 和 init_mount_tree() 完成,它们在系统初始化过程中执行。
init_rootfs() 注册特殊文件系统类型 rootfs:
2
3
4
5
6
7
8
9
2{
3 .name = "rootfs";
4 .get_sb = rootfs_get_sb;
5 .kill_sb = kill_litter_super;
6};
7register_filesystem(&rootfs_fs_type);
8
9
init_mount_tree() 执行如下操作:
- do_kern_mount() ,参数为文件系统类型参数–字符串 “rootfs” ,该函数把返回的新安装文件系统描述符的地址保存在 mnt 局部变量中。
do_kern_mount() 调用 rootfs 文件系统的 get_sb 方法,即 rootfs_get_sb():
2
3
4
5
6
2{
3 return get_sb_nodev(fs_type, flags|MS_NOUSESR, data, ramfs_file_super);
4}
5
6
- get_sb_nodev() 执行下述步骤:
a. sget() 分配新对超级块,传递 set_anon_super() 的地址作为参数。
用合适的方式设置超级块的 s_dev 字段:主设备号为 0,次设备号不同于其他已安装的特殊文件系统的次设备号。
b. 超级块的 s_flags = flags 参数的值。
c. ramfs_fill_super() 分配索引节点对象和对应的目录项对象,并填充超级块字段。
由于 rootfs 是一种特殊文件系统,没有磁盘超级块,因此只需执行两个超级块操作。
d. 返回新超级块的地址。
-
为进程 0 的命名空间分配一个 namespace 对象,并将它插入到由 do_kern_mount() 返回的已安装文件系统描述符中:
2
3
4
5
6
7
2list_add(&mnt->mnt_list, &namespace->list);
3
4namespace->root = mnt;
5mnt->mnt_namespace = init_task.namesapce = namespace;
6
7
- 系统中其他每个进程的 namespace = namespace 对象的地址;同时初始化引用计数器 namespace->count。
- 将进程 0 的根目录和当前工作目录设置为根文件系统。
阶段2:安装实际根文件系统
为简单起见,只考虑磁盘文件系统的情况,它的设备文件名已通过“root”启动参数传递给内核。
同时假定除了 rootfs 文件系统外,没有使用其他初始特殊文件系统。
prepare_namespace() 执行如下操作:
- root_device_name = 从启动参数“root”中获取的设备文件名。
ROOT_DEV = 同一设备文件的主设备号和次设备号。
- mount_root() 执行下述操作:
a. sys_mknod() 在 rootfs 初始根文件系统中创建设备文件 /dev/root,其主、次设备号与存放在 ROOT_DEV 中的一样。
b. 分配一个缓冲区并用文件系统类型名链表填充。
该链表要么通过启动参数“rootstype”传递给内核,要么通过扫描文件系统类型单向链表建立。
c. 扫描上一步建立的文件系统类型名链表。
对每个名字,调用 sys_mount() 在根设备上安装给定的文件系统类型。
由于每个特定于文件系统的方法使用不同的魔数,因此,对 get_sb() 的调用大都会失败,但有一个例外,那就是用根设备上实际使用过的文件系统的函数来填充超级块的那个调用,该文件系统被安装在 rootfs 文件系统的 /root 目录上。
d. sys_chdir(”/root“)改变进程的当前目录。
-
移动 rootfs 文件系统根目录上的已安装文件系统的安装点。
2
3
4
2sys_chroot(".");
3
4
注意,rootfs 特殊文件系统没有被卸载,只是隐藏在基于磁盘的根文件系统下了。
卸载文件系统
umount() 系统调用卸载一个文件系统。
sys_umount() 服务例程作用于两个参数:
- 文件名(多是安装点目录或块设备文件名)
- 一组标志
sys_umount() 执行下列步骤:
- path_lookup() 查找安装点路径名;把返回的查找结果存放在 nameidata 类型的局部变量 nd 中。
- 如果查找的最终目录不是文件系统的安装点,则设置 retval 返回码为 -EINVAL 并跳到第 6 步。
该检查通过验证 nd->mnt->mnt_root 进行。
- 如果要卸载的文件系统还没有安装在命名空间中,则设置 retval 返回码为 -EINVAL 并跳到第 6 步。
这种检查通过在 nd->mnt 上调用 check_mnt() 进行。
- 如果用户不具有卸载文件系统的特权,则设置 retval 返回码为 -EPERM 并跳到第 6 步。
- do_umount(),参数为 nd.mnt(已安装文件系统对象)和 flags(一组标志)。执行下述步骤:
a. 从已安装文件系统对象的 mnt_sb 字段检索超级块对象 sb 的地址。
b. 如果用户要求强制卸载操作,则调用 umount_begin 超级块操作中断任何正在进行的安装操作。
c. 如果要卸载的文件系统是根文件系统,且用户并不要求真正卸载,则调用 do_remount_sb() 重新安装根文件系统为只读并终止。
d. 为进行写操作获取当前进程的 namespace->sem 读/写信号量和 vfsmount_lock 自旋锁。
e. 如果已安装文件系统不包含任何子安装文件系统的安装点,或者用户要求强制卸载文件系统,则调用 umount_tree() 卸载文件系统。
f. 释放 vfsmount_lock 自旋锁和当前进程的 namespace->sem 读/写信号量。
- 减少相应文件系统根目录的目录项对象和已安装文件系统描述符的应用计数器值;
这些计数器值由 path_lookup() 增加。
- 返回 retval 值。
路径名查找
VFS 需要解决路径名查找问题,即如何从文件名导出相应的索引节点。
执行这一任务的标准过程就是分析路径名并把它拆分成一个文件名序列。
除了最后一个文件名外,所有的文件名都必定是目录。
路径查找由 path_lookup() 执行,接收三个参数:
- name,指向要解析的文件路径名的指针。
- flags,标志的值,表示将会怎样访问查找的文件。
- nd,nameidata 数据结构的地址,存放查找结果。
path_lookup() 执行下列操作:
- 初始化 nd 参数的某些字段:
a. last_type = LAST_ROOT(如果路径名是一个“/”或“/”序列,那么这是必须的)
b. flags = 参数 flags
c. depth = 0
- 为进程读操作而获取当前进程的 current->fs->lock 读/写信号量。
- 如果路径名的第一个字符是“/“,查找操作必须从当根目录开始:
nd->mnt = 已安装文件系统对象(current->fs->rootmnt)的地址
nd->dentry = 目录项对象(current->fs->root)的地址
增加引用计数器。
- 否则,如果路径名的第一个字符不是”/“,查找操作必须从当前工作目录开始:
nd->mnt = 已安装文件系统对象(current->fs->pwdmnt)的地址
nd->dentry = 目录项对象(current->fs->pwd)的地址
增加引用计数器。
-
释放放进程的 current->fs->lock 读/写信号量。
-
current->total_link_count = 0。
-
link_path_walk() 执行查找操作:
2
3
4
5
2// nd,nameidata 数据结构的地址,存放查找结果
3return link_path_walk(name, nd);
4
5
标准路径名查找
当 LOOKUP_PARENT 未被设置且路径名不包含符号链接时,link_path_walk() 进行标准路径名查找:
- 局部变量 look_flags = nd->flags。
- 跳过路径名第一个分量前的任何斜杠。
- 如果剩余路径名为空,返回 0。
nd->dentry 和 nd->mnt 指向原路径名最后一个解析分量对应的对象。
- 如果 nd 描述符中的 depth 字段的值为正,则把 lookup_flags 局部变量置为 LOOKUP_FOLLOW 标志。
- 执行一个循环,把 name 参数中传递的路径名分解为分量(中间的“/”被当作文件名分隔符);
对于每个分量:
a. 从 nd->dentry->d_inode 检索最近一个解析分量的索引节点对象的地址(第一次循环中,索引节点指向开始路径名查找的目录)。
b. 检查存放到索引节点中的最近解析分量的许可权是否允许执行(Unix 中,只有目录是可执行的,它才可被遍历)。
为此,如果索引节点有自定义的 permission 方法,则执行它;
否则,执行 exec_permission_lite(),该函数检查存放在索引节点 i_mode 字段的访问模式和运行进程的特权。
两种情况中,如果当前分量不允许执行,link_path_walk() 跳出循环并返回一个错误码。
c. 考虑要解析的下一个分量。根据它的名字,函数为目录项高速缓存散列表计算一个 32 位的散列值。
d. 如果“/”终止了要解析的分量名,则跳过“/”之后的任何尾部“/”。
e. 如果要解析的分量是原路径名的最后一个分量,则跳到第 6 步。
f. 如果分量名是“.”,则继续下一个分量(“.”指当前目录)。
g. 如果分量名是“..”,则尝试回到父目录:
(1)如果最近解析的目录是进程的根目录(nd->dentry == current->fs->root && nd->mnt == current->fs->rootmnt),
那么不能再向上追踪:在最近解析的分量上调用 follow_mount(),继续下一个分量。
(2)如果最近解析的目录是 nd->mnt 文件系统的根目录(nd->dentry == nd->mnt->mnt_root),且该文件系统没有被被安装在其他文件系统之上(nd->mnt == nd->mnt->mnt_parent),那么 nd->mnt 文件系统通常就是命名空间的根文件系统,不能再向上追踪:在最近解析的分量上调用 follow_mount(),继续下一个分量。
(3)如果最近解析的目录是 nd->mnt 文件系统的根目录,而这个文件系统被安装在其他文件系统之上,就需要文件系统交换。
因此,nd->dentry = nd->mnt->mnt_mountpoint,nd->mnt = nd->mnt->mnt_parent,然后重新开始第 5g 步。
(4)如果最近解析的目录不是已安装文件系统的根目录,那么必须回到父目录:nd->dentry = nd->dnetry->d_parent,在父目录上调用 follow_mount(),继续下一个分量。
follow_mount() 检查 nd->dentry 是否是某文件系统的安装点(nd->dentry->d_mounted > 0);
如果是,lookup_mnt() 搜索目录项高速缓存中已安装文件系统的根目录,把 nd->dentry 和 nd->mnt 更新为相应已安装文件系统的对象地址;然后重复整个操作。
本质上,由于进程可能从某个文件系统的目录开始路径名的查找,而该目录被另一个安装在其父目录上的文件系统隐藏,那么当需要回到父目录时,调用 follow_mount()。
h. 分量名既不是“.”也不是“..”,因此必须在目录高速缓存中查找它。
如果低级文件系统有一个自定义的 d_hash 目录项方法,可修改已在 5c 步计算出的散列值。
i. 把 nd->flags 中 LOOKUP_CONTINUE 标志对应的位置位,表示还有下一个分量要分析。
j. do_lookup() 得到与给定的父目录(nd->dentry)和文件名(要解析的路径名分量)相关的目录项对象。
本质上先调用 __d_lookup() 在目录高速缓存中搜索分量的目录项对象。
如果没有找到,则 real_lookup() 指向索引节点的 lookup 方法从磁盘读取目录,创建一个新的目录项对象并插入目录项高速缓存,然后创建一个新的索引节点对象并插入到索引节点高速缓存。
这一步结束时,next 局部变量中的 dentry 和 mnt 字段分别指向这次循环要解析的分量名的目录项对象和已安装文件系统对象。
k. follow_mount() 检查刚解析的分量是否指向某个文件系统安装的第一个目录(next.dentry->d_mounted > 0)。
follow_mount() 更新字段:next.dentry = 该路径分量名所表示的目录上安装的最上层文件系统的目录项对象,next.mnt = 已安装文件系统对象(第 5g 步)。
I. 检查刚解析的分量是否指向一个符号链接(next.dentry->d_inode 具有一个自定义的 follow_link 方法)。
m. 检查刚解析的分量是否指向一个目录(next.dentry->d_inode 具有一个自定义的 lookup 方法)。
如果没有,返回一个错误码 -ENOTDIR,因为该分量位于原路径名的中间。
n. nd->dentry = next.dentry,nd->mnt = next.mnt,然后继续路径名的下一个分量。
- 现在,除了最后一个分量,原路径名的所有分量都被解析。清除 nd->flags 中的 LOOKUP_CONTINUE 标志。
- 如果路径名尾部有一个”/“,则把 lookup_flags 局部变量在 LOOKUP_FLOOLW 和 LOOKUP_DIRECTORY 标志对应的位置位,以强制由后面的函数解释最后一个作为目录名的分量。
- 检查 look_flags 变量中 LOOKUP_PARENT 标志的值,下面假定该标志被置为 0。
- 如果最后一个分量名是“.”,则终止执行并返回值 0(无错误)。
nd->dnetry 和 nd->mnt 指向路径名中倒数第二个分量对应的对象。
- 如果最后一个分量名是“..”,则尝试回到父目录:
a. 如果最后解析的目录是进程的根目录(nd->dentry == currnet->fs->root && nd->mnt == current->fs->rootmnt),
则在倒数第二个分量上调用 follow_mount(),终止执行并返回值 0(无错误)。
nd->dnetry 和 nd->mnt 指向路径名的倒数第二个分量对应的对象,也就是进程的根目录。
b. 如果最后解析的目录是 nd->mnt 文件系统的根目录(nd->dentry == nd->mnt->mnt_root),且该文件系统没有被安装在另一个文件系统之上(nd->mnt == nd->mnt->mnt_parent),不能再向上搜索,因此在倒数第二个分量上调用 follow_mount(),终止指向并返回值 0(无错误)。
c. 如果最后解析的目录是 nd->mnt 文件系统的根目录,且该文件系统被安装在其他文件系统之上,那么 nd->dentry = nd->mnt->mnt_mountpoint,nd->mnt = nd->mnt->mnt_parent,然后重新执行第 10 步。
d. 如果最后解析的目录不是已安装文件系统的根目录,则 nd->dentry = nd->dentry->d_parent,在父目录上调用 follow_mount(),终止执行并返回 0(无错误)。
nd->dentry 和 nd->mnt 指向前一个分量。
- 路径名的最后分量既不是“.”也不是“..”,因此,必须在高速缓存中查找它。
如果低级文件系统有自定义的 d_hash 目录项方法,则该函数调用它来修改在第 5c 步计算出的散列值。
- do_lookup() 得到与父目录和文件名相关的目录项对象(5j 步)。
这一步结束时,next 局部变量存放的指向最后分量名对应的目录项和已安装文件系统描述符的指针。
- follow_mount() 检查最后一个分量名是否是某个文件系统的一个安装点,如果是,next 局部变量更新为最上层已安装文件系统根目录对应的目录项对象和已安装文件系统对象的地址。
- 检查 lookup_flags 中是否设置了 LOOKUP_FOLLOW 标志,且索引节点对象 next.dentry->d_inode 是否有一个自定义的 follow_link 方法。
如果是,分量就是一个必须进行解释的符号链接。
- 要解析的分量不是符号链接或符号链接不被解释。
nd->mnt = next.mnt,nt->dentry = next.dentry。
最后的目录项对象就是整个查找操作的结果。
- 检查 nd->dentry->d_inode 是否为 NULL ,这发生在没有索引节点与目录项对象关联时,通常是因为路径名指向一个不存在的文件,返回一个错误码 -ENOENT。
- 路径名的最后一个分量有一个关联的索引节点。
如果在 lookup_flags 中设置了 LOOKUP_DIRECTORY 标志,则检查索引节点是否有一个自定义的 lookup 方法,也就是说它是一个目录。
如果没有,返回一个错误码 -ENOTDIR。
- 返回 0(无错误)。nd->dentry 和 nd->mnt 指向路径名的最后分量。
父路径名查找
很多情况下,查找操作的真正目的是路径名的最后一个分量的前一个分量,需要使用 LOOKUP_PARENT 标志。
当 LOOKUP_PARENT 标志被设置,link_path_walk() 也在 nameidata 数据结构中建立 last 和 last_type 字段。
last 字段存放路径名的最后一个分量名。
last_type 字段标识最后一个分量的类型。
当路径名的查找操作开始时,LAST_ROOT 标志是由 path_lookup() 设置的缺省值。
如果路径名正好是“/”,则内核不改变 last_type 字段的初值。
last_type 字段的其他值在 LOOKUP_PARENT 标志置位时由 link_path_walk() 设置;
这种情况下,函数指向前一节描述的步骤,直到第 8 步。
第 8 步后,路径名中最后一个分量的查找操作是不同的:
- nd->last = 最后一个分量名。
- nd->last_type = LAST_NORM。
- 如果最后一个分量名为“.”,nd->last_type = LAST_DOT。
- 如果最后一个分量名为“..”,nd->last_type = LAST_DOTDOT.
- 返回 0(无错误)。
可见,最后一个分量没有被解释,因此,函数终止时,nameidata 数据结构的 dentry 和 mnt 字段指向最后一个分量所在目录对应的对象。
符号链接的查找
符号链接是一个普通文件,其中存放另一个文件的路径名。
路径名可以包含符号链接,且必须由内核解析。
符号链接的路径名可能包含其他符号链接,为避免递归层数太多,用到当前进程的描述符的字段:
- link_count,递归层数。
- total_link_count,查找操作中的总符号链接数,包括非嵌套的。
一旦 link_path_walk() 检索到与路径名分量相关的目录项对象,就检查相应的索引节点对象是否有自定义的 follow_link 方法。
如果是,索引节点就是一个符号链接,在原路径名的查找操作进行前必须先解释该符号链接。
link_path_walk() 调用 do_follow_link(),前者传递给后者的参数:
- 符号链接目录项对象的地址 dentry
- nameidata 数据结构的地址 nd
do_follow_link() 执行下列步骤:
- if(current->link_count >= 5) return -ELOOP;
- if(current->total_link_count >= 40) return -ELOOP;
- 如果当前进程需要,调用 cond_resched() 进行进程交换(设置当前进程描述符 thread_info 中的 TIF_NEED_RESCHED 标志)。
- current->link_count++; current->total_link_count++; nd->depth++。
- 更新与要解析的符号链接关联的索引节点的访问时间。
- 调用与具体文件系统相关的调函数实现 follow_link 方法,给它传递的参数为 dentry 和 nd。
它读取存放在符号链接索引节点中的路径名,并把该路径名保存在 nd->saved_names 数组的合适项中。
- __vfs_follow_link(),参数为 地址 nd 和 nd->saved_names 数组中路径名的地址。
- 如果定义了索引节点对象的 put_link 方法,就执行它,释放由 follow_link 方法分配的临时数据结构。
- curent->link_count–; nd->depth–。
- 返回由 __vfs_follow_link() 返回的错误码(0 表示无错误)。
__vfs_follow_link() 本质上执行下列操作:
- 检查符号链接路径名的第一个字符是否是“/”:如果是,说明已经找到一个绝对路径名,因此没有必要在内存中保留前一个路径的任何信息。
对 nameidata 数据结构调用 path_release(),释放由前一个查找步骤产生的对象;
然后,设置 nameidata 数据结构的 dentry 和 mnt 字段,以使它们指向当前进程的根目录。
- link_path_walk() 解释符号链接的路径名,参数为路径名和 nd。
- 返回从 link_path_walk() 取回的值。
do_follow_link() 终止时,局部变量 next 的 dentry 字段设置为了目录项对象的地址,link_path_walk() 执行下一步。
VFS 系统调用的实现
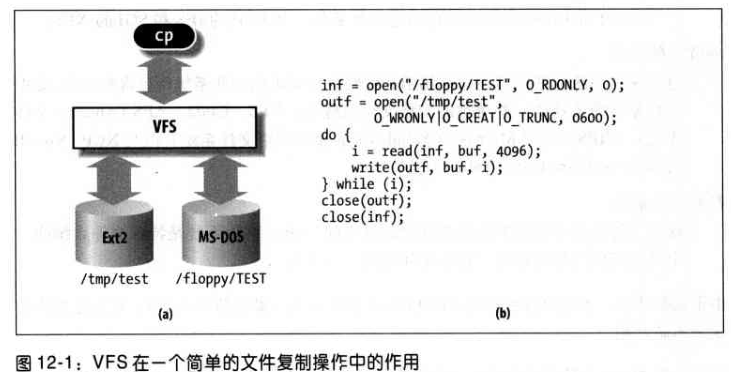
假设用户发出一条 shell 命令:把 /floppy/TEST 中的 MS-DOS 文件拷贝到 /tmp/test 的 Ext2 文件中。
命令 shell 调用一个外部程序(如 cp),假定 cp 执行下列代码片段:
2
3
4
5
6
7
8
9
10
11
2outf = open("/tmp/test", O_WRONLY | O_CREAT | O_TRUNC, 0600);
3do
4{
5 len = read(inf, buf, 4096);
6 write(outf, buf, len);
7}while(len);
8close(outf);
9close(inf);
10
11
以上代码忽略了检查每个系统调用返回的出错码。
open()
open() 系统调用的服务例程为 sys_open(),参数为:
- 要打开文件的路径名 filename
- 访问模式的一些标志 flags
- 如果该文件被创建,所需要的许可权位掩码 mode
sys_open() 返回:
如果成功,返回一个文件描述符,即指向文件对象的指针数组 current->files->fd 中分配给新文件的索引;
否则,返回 -1。
sys_open() 的操作:
- getname() 从进程地址空间读取该文件的路径名。
- get_unused_fd() 在 current->files->fd 中查找一个空的位置。
相应的索引(新文件描述符)存放在 fd 局部变量中。
- filp_open(),参数为路径名、访问模式标志及许可权位掩码,执行如下步骤:
a. 把访问模式标志拷贝到 namei_flags 标志中,但是,用特殊的格式对访问模式标志 O_RDONLY、O_WRONLY 和 O_RDWR 编码:
如果文件访问需要读特权,那么只设置 namei_flags 标志的下标为 0 的位(最低位);
类似地,如果文件访问需要写特权,就设置下标为 1 的位。
不能在调用 open() 时不指定文件访问的读或写特权,因为这在涉及符号链接的路径名查找中是有意义的。
b. open_namei(),参数为路径名、修改的访问模式标志及局部 nameidata 数据结构的地址。执行下列操作:
- 如果访问模式标志中没有设置 O_CREAT,则不设置 LOOKUP_PARENT 标志,而设置 LOOKUP_OPEN 标志,path_lookup() 开始查找操作。
此外,只有 O_NOFOLLOW 被清零,才设置 LOOKUP_FOLLOW 标志;
而只有设置了 O_DIRECTORY 标志,才设置 LOOKUP_DIRECTORY 标志。
- 如果在访问模式标志中设置了 O_CREAT,则设置 LOOKUP_PARENT、LOOKUP_OPEN 和 LOOKUP_CREATE 标志,path_lookup() 开始查找操作。
一旦 path_lookup() 成功返回,则检查请求的文件是否已存放在。
如果不存放在,则调用父索引节点的 create 方法分配一个新的磁盘索引节点。
- open_namei() 也在查找操作确定的文件上执行几个安全检查。
如,检查与已找到的目录项对象关联的索引节点是否存在、它是否是一个普通文件,以及是否允许当前进程根据访问模式标志访问它。
如果文件是为写打开的,则函数检查文件是否被其他进程加锁。
c. dentry_open(),参数为访问模式标志、目录项对象的地址及由查找操作确定的已安装文件系统对象。执行下列操作:
(1)分配一个新的文件对象。
(2)用传递给 open() 的访问模式标志初始化文件对象的 f_flags 和 f_mode 字段。
(3)用传入的目录项对象的地址和已安装文件系统对象的地址初始化文件对象的 f_fentry 和 f_vfsmnt 字段。
(4)f_op = 相应索引节点对象 i_fop,为进一步的文件操作建立起了所有的方法。
(5)把文件对象插入到文件系统超级块的 s_files 字段指向的打开文件的链表。
(6)如果文件操作的 open 方法被定义,则调用它。
(7)file_ra_state_init() 初始化预读的数据结构。
(8)如果 O_DIRECT 标志被设置,则检查直接 I/O 操作是否可以作用于文件。
(9)返回文件对象的地址。
d. 返回文件对象的地址。
- current->files->fd[fd] = dentry_open() 返回的文件对象的地址。
- 返回 fd。
read() 和 write()
read() 和 write() 相似,都需要三个参数:
- 文件描述符 fd
- 一个内存区的地址 buf(该缓冲区包含要传送的数据)
- 一个数 count(直到应该传送多少字节)
read() 把数据从文件传送到缓存区,而 write() 执行相反的操作。
两者都返回成功传送的字节,或发送一个错误条件的信号并返回 -1。
以下情况允许返回值小于 count:
- 从管道或终端设备读取时,读到文件的末尾。
- 系统调用被信号中断。
读或写操作总是发生在当前文件指针所指定的文件偏移处(文件对象的 f_pos 字段)。
两者都通过把所传送的字节数加到文件指针上以更新文件指针。
sys_read() 与 sys_write() 几乎执行相同的步骤:
- fget_light() 从 fd 获取相应文件对象的地址 file。
- 如果 file->f_mode 中的标志不允许所请求的访问(读或写操作),则返回一个错误码 -EBADF。
- 如果文件对象没有 read() 或 aio_read() (write() 或 aio_write())文件操作,则返回一个错误码 -EINVAL。
- access_ok() 粗略检查 buf 和 count 参数。
- rw_verify_area() 对要访问的文件部分检查是否有冲突的强制锁。
如果有,返回一个错误码,如果该锁已被 F_SETLKW 命令请求,则挂起当前进程。
- 调用 file->f_op->read 或 file->f_op->write 方法(如果定义)传送数据;
否则,调用 file->f_op->aio_read 或 file->f_op->aio_write。
以上方法都返回实际传送的字节数。文件指针被适当更新。
- fput_light() 释放文件对象。
- 返回实际传送的字节数。
close()
close() 接收的参数为要关闭文件的文件描述符 fd。
sys_close() 服务例程执行下列操作:
- 获得存放在 current->files->fd[fd] 中的文件对象的地址;如果为 NULL,则返回一个出错码。
- 把 current->files->fd[fd] 置为 NULL。
释放文件描述符 fd,这通过清除 current->files 中的 open_fds 和 close_on_exec 字段的相应位来进行。
- filp_close() 执行下列操作:
a. 调用文件操作的 flush 方法。
b. 释放文件上的任何强制锁。
c. 调用 fput() 释放文件对象。
- 返回 0 或一个出错码。
出错码可由 flush 方法或文件中的前一个写操作错误产生。
文件加锁
POSIX 标志规定了基于 fcntl() 的文件加锁机制。
可对文件的任意一部分(甚至一个字节)加锁或对整个文件(包含以后要追加的数据)加锁。
这种锁被称为劝告锁,内核只提供加锁及检测文件是否已经加锁的手段,但不参与锁的控制和协调。
传统的 System V 变体提供了 lockf() 库函数,它仅仅是 fcntl() 的一个接口。
System V Release 3 引入了强制加锁:
如每次调用 open()、read() 和 write() 都不能违背所在访问文件上的强制锁。
不管进程是使用劝告锁还是强制锁,它们都可使用共享读锁和独占写锁。
在文件的某个区字段上,可以有任意多个进程进行读,但同一时刻只能有一个进程写。
此外,当其他进程对同一个文件都拥有自己的读锁时,就不可能获得一个写锁,反之亦然。
Linux 文件锁
Linux 支持所有的文件加锁方式:劝告锁和强制锁,以及 fcntl()、flock() 和 lockf()。
类 Unix 中,flock() 不管 MS_MANDLOCK 安装标志如何设置,只产生劝告锁。
Linux 中,增加了一种特殊的 flock() 强制锁,以支持专有的网络文件系统的实现。
这就是共享模式强制锁,该锁被设置时,其他任何进程都不能打开与锁访问模式冲突的文件。
Linux 还引入了另一种 fcntl() 的强制锁,称为租借锁。
一个进程试图打开由租借锁包含的文件时,会被阻塞。
但拥有锁的进程可接收信号,一旦得到通知,首先更新文件,以使文件的内容保持一致,然后释放锁。
如果拥有者不在预定的时间间隔(/proc/sys/fs/lease-break-time,通常为 45s)内这么做,租借锁被内核自动删除,阻塞进程恢复执行。
进程可采用以下两种方式获得或释放一个文件劝告锁:
- flock()。参数为文件描述符 fd 和指定锁操作的命令。该锁应用于整个文件。
- fcntl()。参数为文件描述符 fd、指定锁操作的命令和指向 flock 结构的指针。
flock 结构的几个字段允许进程指定要加锁的文件部分,因此进程可在同一文件的不同部分保持几个锁。
fcntl() 和 flock() 可在同一文件上同时使用,但两者加锁的文件看起来不一样,可避免死锁。
处理强制文件锁更复杂,步骤如下:
- 安装文件系统时强制锁是必须的,可使用 mount 命令的 -o mand 选项在 mount() 种设置 MS_MANDLOCK 标志。缺省操作不使用强制锁。
- 设置文件的 set-group 位(SGID)和清除 group-execute 许可权位,可将它们标记为强制锁的候选者。
因为 groupt-exectue 位为 0 时,set-group 位也没有意义,因此结果为强制锁而不是劝告锁 。
- fcntl() 获得或释放一个文件锁。
处理租借锁更容易:
调用具有 F_SETLEASE 或 F_GETLEASE 命令的 fcntl() 就可以了。
使用另一个带有 F_SETSIG 命令的 fcntl() 可以改变传送给租借锁进程拥有的信号类型。
在可修改文件内容的系统调用中,除了 read() 和 write() 中的检查外,内核还需考虑强制锁。
如,如果文件中存在强制锁,则带有 O_TRUNC 标志的 open() 会失效。
文件锁的数据结构
本节描述的数据结构用于处理由 flock()(FL_FLOCK 锁)和 fcntl()(FL_POSIX 锁)实现的文件锁。
Linux 中所有类型的锁都由相同的 file_lock 数据结构描述。
file_lock 的某些字段:
- fl_next:指向磁盘上同一文件的所有 lock_file 结构都在一个单向链表中,其第一个元素由索引节点对象的 i_flock 字段指向。
file_lock 的 fl_next 指向链表中的下一个元素。
- fl_wait:当发出阻塞系统调用的进程请求一个独占锁而该文件也存在共享锁时,该请求不能立即得到满足,且进程必须被挂起。
因此进程被插入到阻塞时由 file_lock 的 fl_wait 字段指向的等待队列中。
使用两个链表区分已满足的锁请求(活动锁)和那些不能立刻得到满足的锁请求(阻塞锁)。
- fl_link:所有的活动锁位于“全局文件锁链表”中,该表的首元素被存放在 file_lock_list 变量中。
所有的阻塞锁位于“阻塞链表”中,该表的首元素位于 blocked_list 变量中。
fl_link 字段可把 lock_file 插入到上述任何一个链表中。
- fl_block:因为内核必须跟踪所有与给定活动锁(“blocker”)关联的阻塞锁(“waiters”),所以链表根据给定的 blocker 把所有的 waiter 链接在一起。
blocker 的 fl_block 字段是链表的伪首部,而 waiter 的 fl_block 存放指向链表中相邻元素的指针。
FL_FLOCK 锁
FL_LOCK 锁总是与一个文件对象关联,因此由一个打开该文件的进程维护。
当一个锁被请求或允许时,内核就把进程在该文件对象上的其他锁都替换掉,如将一个读锁变为一个写锁,或将一个写锁变为一个读锁。
当 fput() 释放一个文件对象时,对该文件对象加的所有 FL_LOCK 锁都被撤销,但其他进程设置的 FL_LOCK 锁仍然有效。
flock() 允许进程在打开的文件上申请或删除劝告锁。参数:
- 要加锁的文件描述符 fd
- 指定锁操作的参数 cmd:
-
- LOCK_SH,则请求一个共享的读锁;
-
- LOCK_EX,则请求一个互斥的写锁;
-
- LOCK_UN,释放一个锁。
如果请求不能立即得到满足,系统调用通常阻塞当前进程。
但如果 cmd 包含 LOCK_NB 位,则系统调用不阻塞进程,而是返回一个错误码。
sys_flock() 执行下列步骤:
- 检查 fd 是否是一个有效的文件描述符;如果不是,就返回一个错误码。否则,获得相应文件对象 filp 的地址。
- 检查进程在打开文件上是否有读或写权限;如果没有,返回一个错误码。
- 获得一个新的 file_lock 对象锁并用适当的锁操作初始化它:
根据参数 cmd 的值设置 fl_type 字段,fl_file = filp 的地址,fl_flags = FL_FLOCK,fl_pid = current->tgid,fl_end = -1,表示对整个文件加锁。
- 如果参数 cmd 不包含 LOCK_NB 位,则把 FL_SLEEP 标志加入 fl_flags 字段。
- 如果文件具有一个 flock 文件操作,则调用它,传递给它的参数为文件对象指针 filp、一个标志(F_SETLKW 或 F_SETLK,取决于 LOCK_NB 位的值)以及新的 file_lock 对象锁的地址。
- 否则,没有定义 flock 文件操作(通常情况下),则调用 flock_lock_file_wait() 执行所请求的锁操作。
参数:文件对象指针 filp 和第 3 步创建的新的 file_lock 对象的地址 lock。
- 如果上一步还没有把 file_lock 描述符插入活动或阻塞链表,则释放它。
- 返回 0(成功)。
flock_lock_file_wait() 执行下列循环操作:
- flock_lock_file(),参数为文件对象指针 filp 和新 file_lock 对象锁的地址 lock。该函数执行下列操作:
a. 搜索 filp->f_dentry->d_inode->i_flock 指向的链表。
如果在同一文件对象中找到 FL_FLOCK 锁,则检查它的类型(LOCK_SH 或 LOCK_EX):
如果该锁类型与新锁相同,则返回 0。
否则,从索引节点链表和全局文件锁链表中删除该 file_lock 元素,唤醒 fl_block 链表在该锁等待队列上睡眠的所有进程,并释放 file_lock 结构。
b. 如果进程正在执行开锁(LOCK_UN),则返回 0。
c. 如果已经找同一文件对象的 FL_FLOCK 锁—表明进程想把一个已拥有的读锁改变为一个写锁(反之亦然),则调用 cond_resched() 给与其他更高优先级进程(特别时先前在
原文件锁上阻塞的任何进程)一个运行的机会。
d. 再次搜索索引节点链表以验证现有的 FL_FLOCK 锁并不与所请求的锁冲突。
该链表一定没有 FL_FLOCK 写锁,甚者,如果进程正在请求一个写锁,那么一定没有 FL_FLOCK 锁。
e. 如果不存在冲突锁,则把新的 file_lock 结构插入索引节点锁链表和全局文件锁链表中,然后返回 0(成功)。
f. 发现一个冲突锁:如果 fl_flags 字段中 FL_SLEEP 对应的标志置位,则把新锁(waiter 锁)插入到 blocker 锁循环链表和全局阻塞链表中。
g. 返回一个错误码 -EAGAIN。
- 检查 flock_lock_file() 的返回码:
a. 如果返回码为 0(没有冲突),则返回 0(成功)。
b. 有冲突。如果 fl_flags 字段中的 FL_SLEEP 标志被清除,释放 file_lock 锁描述符,并返回一个错误码 -EAGAIN。
c. 否则,冲突但进程能够睡眠的情况:wait_event_interruptible() 把当前进程插入到 lock_fl_wait 等队列中并挂起它。
当进程被唤醒时(正好在释放 blocker 锁后),跳转到第 1 步再次执行该操作。
FL_POSIX 锁
FL_POSIX 锁总是与一个进程和一个索引节点相关联。
当进程死亡或一个文件描述符被关闭时(即使进程对该文件打开了两次或复制了一个文件描述符),这种锁会被自动释放。
此外,FL_POSIX 锁不会被子进程通过 fork() 继承。
当使用 fcntl() 对文件加锁时,作用于三个参数:
- 要加锁的文件描述符 fd
- 指向锁操作的参数 cmd
- 指向存放在用户态进程地址空间的 flock 数据结构的指针 fl

sys_fcntl() 的操作取决于 cmd 参数的标志值:
- F_GETLK,确定由 flock 结构描述的锁是否与另一个进程已获得的某个 FL_POSIX 锁相互冲突。
冲突的情况下,用现有锁的有关信息重写 flock。
- F_SETLK,设置由 flock 结构描述的锁,如果不能获得该锁,则返回一个错误码。
- F_SETLKW,设置由 flock 结构描述的锁,如果不能获得该锁,阻塞,即调用进程进入睡眠状态直到锁可用为止。
- F_GETLK64,F_SETLK64,F_SETLKW64,与前面描述的几个标志相同,但使用的是 flock64 结构。
sys_fcntl() 首先获取与参数 fd 对应的文件对象,然后调用 fcntl_getlk() 或 fcntl_setlk(),取决于参数 cmd 的取值。
fcntl_setlk() 作用于三个参数:
- 指向文件对象的指针 filp
- cmd 命令(F_SETLK 或 F_SETLKW)
- 指向 flock 数据结构的指针 fl
fcntl_setlk() 执行下列操作:
- 读取参数 fl 指向的 flock 结构。
- 如果 fl 是一个强制锁,且文件有一个共享内存映射,拒绝创建锁并返回 -EAGAIN 出错码,说明文件正在被另一个进程访问。
- 根据 fl 和文件索引节点中的文件大小,初始化一个新的 file_lock 结构。
- 如果命令 cmd 为 F_SETLKW,则把 file_lock 结构的 fl_flags 字段设为 FL_SLEEP 标志对应的位置位。
- 如果 flock 结构的 l_type == F_RDLCK,则检查是否允许进程从文件读取;
类似地,l_type == F_WRLCK,则检查是否允许进程写入文件,如果都不是,返回一个出错码。
- 调用文件操作的 lock 方法。对于磁盘文件系统,通常不定义该方法。
- 调用 __posix_lock_file(),传递给它的参数为文件的索引节点对象地址以及 file_lock 对象的地址。该函数执行下列操作:
a. 对于索引节点的链表中的每个 FL_POSIX 锁,调用 posix_locks_conflict() 检查该锁是否与所请求的锁冲突。
本质上,索引节点的链表中,必定没有用于同一区的 FL_POSIX 写锁,并且,如果进程正在请求一个写锁,则同一个区字段也可能根本没有 FL_POSIX 锁。
但是,同一个进程所拥有的锁从不会冲突;这就允许进程改变它已经拥有的锁。
b. 如果找到一个冲突锁,则检查是否以 F_SETLKW 标志调用 fcntl()。
如果是,当前进程应当被挂起:调用 posix_locks_deadlock() 检查在等待 FL_POSIX 锁的进程之间没有产生死锁条件,然后把新锁(waiter 锁)插入到冲突锁(blocker 锁)blocker 链表和阻塞链表中,最后返回一个出错码。
否则,如果以 F_SETLK 标志调用 fcntl(),则返回一个出错码。
c. 只要索引节点的锁链表中不包含冲突的锁,就检查把文件区重叠起来的当前进程的所有 FL_POSIX 锁,并按需对文件中相邻的区进行锁定、组合及拆分。
d. 把新 的 file_lock 结构插入到全局锁链表和索引节点链表中。
e. 返回 0(成功)。
- 检查 __posix_lock_file() 的返回码:
a. 如果返回码为 0(没有冲突),则返回 0(成功)。
b. 冲突。如果 fl_flags 字段的 FL_SLEEP 标志被清除,就释放 file_lock 描述符,并返回一个错误码 -EAGAIN。
c. 如果不冲突但进程能睡眠,调用 wait_event_interruptible() 把当前进程插入到 lock->fl_wait 等队列并挂起它。
当进程被唤醒时(释放 blocker 后),跳到第 7 步再次执行该操作。
