索引是特殊的数据结构,它以易于遍历的形式存储部分集合数据集。索引存储特定字段或字段集的值,按字段值排序。
MongoDB的索引几乎与传统的关系型数据库索引一模一样,它的主键_id也是一个索引,MongoDB的数据按照_id的顺序存储在内存页与磁盘块上。但是,_id与业务毫无关联,在业务相关的条件查询时,还是需要进行全表扫描才能找到对应页,效率并不高。
- 为了避免性能瓶颈,可以根据常用的查询建立索引
- 索引的值是按照一定的顺序排列的,使用索引键对文档进行排序效率非常高,只需要按照索引读取数据即可。
不过,使用索引也是有代价的,不仅会增加磁盘与内存的消耗,对于添加的每一个索引,每次写操作(插入、更新、删除)都会耗费更多时间,这是因为,数据发生变动时,还需要额外的开销更新索引。
文章目录
-
聚簇索引与非聚簇索引
-
MongoDB索引分类
-
主键索引
- 单字段索引
- 复合索引
-
复合索引与排序共用
- 唯一索引
-
复合唯一索引
* 去除重复- 稀疏索引
- TTL索引
- 全文索引
- 地理空间索引
-
索引优化
-
查询优化
- 写操作优化
-
索引命令JavaScript
聚簇索引与非聚簇索引
磁盘上的数据某一时刻只能有一种排序方式,而聚簇索引的特点是:索引顺序与数据存储顺序一致,所以聚簇索引只能有一个。
《数据库原理》中对聚簇索引的定义:聚簇索引的叶子节点是数据节点,非聚簇索引的叶子节点仍然是索引节点,只不过有指向对应数据块的指针。
所以Mysql的InnoDB引擎的主键索引是聚簇索引、MyIsam引擎使用的是非聚簇索引。
MongoDB不会将_id索引与文档内容放在一起,所以MongoDB的_id索引不是聚簇索引,mogoDB将数据与索引分开存放,通过RecordId间接引用。假设为字段”name“创建了索引,主键id为主键索引,那么该集合就通过索引查找RecordId,再查找数据。
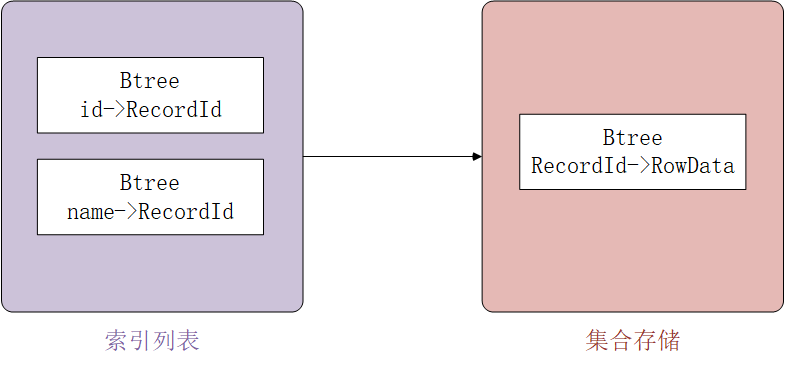
MongoDB索引分类
主键索引
_id索引是默认的主键索引,与业务相关联的项不适合用作主键(难以保障全局唯一、非null),建议使用_id作为主键。
单字段索引
对单个filed建立索引,也是常说的“普通索引”;建立索引时可以指定索引数据的order:正序还是倒序。MongoDB 3.0后的版本,使用createIndex、ensureIndex是一样的,均是创建索引的命令。
2
3
4
2db.mycollection.createIndex({"name":1}) // MongoDB 3.0后的版本,可以使用createIndex
3
4
复合索引
两个或两个以上的键建立索引,可以减小检索的范围。复合索引与Mysql一样,也是按照左侧匹配规则。例如:对于集合col中的字段age和name建立复合索引:
2
3
2
3
1表示按照正序排列,-1表示按照倒序排列,若插入4条数据,
2
3
4
5
6
22 db.col.insert({age:21,name:'a2'})
33 db.col.insert({age:19,name:'a3'})
44 db.col.insert({age:21,name:'a4'})
5
6
MongoDB在复合索引中存储这些数据的顺序是:(19,a3)、(20,a1)、(21,a2)、(21,a4)。编写查询语句时应该先匹配age,再匹配name。
复合索引与排序共用
复合索引与排序共用的场景很常见,使用不当会导致内存排序,默认的快速排序的时间复杂度是NlogN,在集合文档数超过一定量级后,耗时就会很大。所以要选择最佳的索引创建方式,尽量避免内存排序。
内存排序的产生:
创建两个复合索引,唯一区别就是键顺序不同,排序规则都是正序。
2
3
4
2db.col.ensureIndex({"name":1,"age":1}); // 索引2
3
4
由于存在了多个索引,使用hint命令指明使用哪个索引。下面两个查询的条件是一致的,排序规则也是一致的,不同的是一个使用索引1,一个使用索引2。
2
3
4
5
6
7
2db.col.find({"age":{"$gte":21, "$lte":30}}).sort({"name":1}).hint({"age":1,"name":1});
3
4// 查询2使用索引2
5db.col.find({"age":{"$gte":21, "$lte":30}}).sort({"name":1}).hint({"name":1,"age":1});
6
7
- 对于查询1,先根据索引age查找复合条件的结果集,然后在内存中排序(age索引是有序的,但是排序规则用不到)
- 对于查询2,遍历整个索引树,找出所有匹配的文档,不需要排序(name索引本身就是有序的),按正序遍历即可。
结果集的大小可以使用limit关键字人为限制,这样便限制了待排序的基数N,如果limit比较小,也是可以接受内存排序的。
2
3
2
3
此外,MongoDB也提供了一个explain工具用来进行查询分析。使用它可以比较两种排序的效率。
2
3
4
5
2
3db.col.find({"age":{"$gte":21, "$lte":30}}).sort({"name":1}).hint({"age":1,"name":1}).explain()[`millis`]; \\获取查询2耗时
4
5
唯一索引
唯一索引用来确保集合的每一个文档的指定键都有唯一值,允许null值。例如:在集合mycollection中,给”name“键建立唯一索引,试图插入重复name的值时,会抛出异常,也会影响效率。
2
3
2
3
使用场景:应对偶尔可能会出现重复的键重复问题,而不是在运行时对重复键进行过滤。比如:为避免消息重复消费,可以为”消息id“键创建唯一索引。
复合唯一索引
复合的唯一索引,单个键的值可以相同,但所有键的组合值必须是唯一的。
例如,如果有一个{”username":1, “age”:100}上的唯一索引,下面的插入是合法的,不会报错。
2
3
4
5
2db.mycollection.insert({"username":"bob", "age":23});
3db.mycollection.insert({"username":"fred", "age":23});
4
5
去除重复
在已有的集合上创建唯一索引时,可能会失败,因为集合中可能已经存在重复的值了。此时,有三种办法:
-
找出重复数据,想办法去除
-
直接删除重复的值,创建索引时使用”dropDups“选项,如果遇到重复的值,只会保留第一个值。正是由于这种不确定性(不确定哪条记录被删除),MongoDB 3.0版本以后移除了该选项。
-
新建一个集合,建立索引,然后把旧集合的数据拷贝至新集合
2
3
2
3
稀疏索引
唯一索引会把null看做值,假如集合中有以下两个文档,假设对键”age“建立唯一索引,则文档2中的"age"就是null
2
3
4
2{"name":"bob"} // 文档2
3
4
现在想新增文档3,是无法添加的,因为文档3中”age“也是null,与文档2冲突了,违反了唯一性。
2
3
2
3
此时,应该使用稀疏索引(sparse index),就可以插入文档3,同时也能保证文档4无法插入,满足唯一性。
2
3
4
5
6
2db.ensureIndex({"age":1}, {"unique": true, "sparse": true});
3
4{"name":"dod", "age":23} // 文档4
5
6
稀疏索引定义如下:如果集合中的文档存在索引键,则必须是唯一的,如果文档不存在索引键,则不要求该文档的唯一性。
注意事项:
根据是否使用稀疏索引,查询结果可能有所不同。例如:对于下面的查询,查询1和查询2是完全相同的语句,不同的是,查询1对应未创建稀疏索引的情况,查询2对应创建稀疏索引的情况。
2
3
4
2db.mycollection.find({"age":{"$ne":23}}) // 查询2
3
4
查询结果如下,查询2没有查询到文档,这是因为**建立了稀疏索引后,查询只根据索引查询,不再全表扫描,因此,会遗漏那些没有索引键的文档。**如果一定要获取与查询1相同的结果,通过hint命令指明不使用索引,执行全表扫描。
2
3
4
5
6
7
8
2{"name":"bob"}
3{"name":"bob", "addresss":"sz"}
4
5// 查询2的查询结果
6// nothing...
7
8
TTL索引
TTL(Time-to-live index)索引指具有生命周期的索引,这种索引会为文档设置一个超时时间,一旦文档存活时间超过该时间就会被删除。这种类型的索引可以用在:消息日志、服务器会话等具有时效性的场景。
在"createdTime"字段上创建TTL索引:
2
3
2
3
"createdTime"字段必需是日期类型,一般设置为当前时间,
记录被删除的时间点="createdTime"字段对应的时间点+"expireAfterSecs"对应的单位为秒的时间段
为了避免活跃的会话被删除,可以在会话上有活动发生时,更新"createdTime"为当前时间。
一个集合上可以创建多个TTL索引。
全文索引
与Mysql一样,MongoDB也支持全文检索。创建全文索引的开销较大,MongoDB本身就很耗内存,在一个操作频繁的集合上创建全文索引更容易导致内存不足,全文本索引的集合写入性能更差、分片时迁移速度更慢,一般的,如果不是特别强烈的业务需要,不建议使用全文索引。
在"mytext"字段上创建全文索引:
2
3
2
3
使用全文索引检索关键字"keyword":
2
3
2
3
地理空间索引
MongoDB支持几种类型的索引,最常见的是2dsphere索引(用于球面图)和2d索引(用于平面图)。这里只简单介绍下这两种索引的创建:
2
3
4
2db.mycollection.ensureIndex({"myloc":"2d"})
3
4
索引优化
如果数据库中已有大量数据,此时建立索引将会导致大量的IO操作(内存,磁盘读写),耗时较长。MongoDB提供了2种方式:foreground和background。
- foreground即前台操作,它会阻塞用户对数据的读写操作直到index构建完毕,即任何需要获取read、write锁的操作都会阻塞,默认情况下为foreground;
- background即后台模式,不阻塞数据读写操作,独立的后台线程异步构建索引,此时仍然允许对数据的读写操作;其中background比foreground更加耗时。
查询优化
-
对频繁访问的查询,尽量使用覆盖索引,如果一个索引包含(或者说覆盖)所有需要查询的数据,就称为“覆盖索引”,使用覆盖索引时,需要强制不显示objectId字段。
2
3
4
2db.mycollection.find({"name":bob, "_id":0}) // 0表示不显示该字段
3
4
-
选用差异性较强的字段作为索引,不要选用类似于性别、国家这种字段作为索引键。
-
需要哪些字段查询哪些字段,尽量不要查询整个文档
-
使用hint强制使用特定的索引
-
使用explain对比分析多种查询方式的性能
写操作优化
- 尽量不要创建过多的索引,索引会增加该集合写入、更新、删除的开销,因为要额外维护索引
- 合理设置journal相关参数,journal日志实现日志预写功能,开启journal保证了数据持久化,但也会存在一定的性能消耗,合理的设置commitIntercalMs控制journal写入磁盘的频率,该参数过大,影响MongoDB写操作的性能,该参数过小,MongoDB意外宕机期间预写日志未持久化的可能增大。
索引命令JavaScript
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
2docker exec -it mongodb bash
3# 弹出root@966de5e17b68:/#,输入mongo
4mongo
5use db1
6
7# 查看所有的索引
8db.col.getIndexes();
9
10# 查看所有索引的大小,单位是字节
11db.col.totalIndexSize()
12
13# 根据索引name,删除指定的索引,比如删除name为“testidx”的索引
14db.col.dropIndex("testidx");
15
16# 创建新的索引,在后台根据字段attr1、attr2、attr3创建组合索引,索引名称“idxcompose”
17db.col.ensureIndex({attr1:-1, attr2:-1, attr3:1},{name:"idxcompose", background:true})
18
19
