OK!终于到了分布式爬虫了,说下,我整了几天才把分布式爬虫给搞定。(心里苦哇)为什么会这么久,请听我徐徐道来。
在使用分布式爬虫的时候通用的做法是一台电脑作为master端,另外的多台电脑作为slaver端,我采用的是主机与虚拟机来搭建的环境,说说我的主机,一台联想的y410笔记本,只有4G的内存,用到现在已经快5年了,还很坚挺 :-)就是内存小了点,我的虚拟机用的是xubuntu(轻量级的ubuntu),虚拟机作为的master端,master端的redis用来存储数据以及url去重,主机作为slaver端执行代码。这里面有一步很关键,那就是我的主机(slaver端)要能够访问我的虚拟机(master端)里面的redis数据库才行,很无奈我就是卡在了这里,我的主机无论如何都无法ping通虚拟机,也就是访问不了xubuntu的redis数据库,在网上找了各种解决方法,都行不通,最后没办法了直接卸载了vnware重装之后,又修改了下网络配置,才最终解决问题。实属心酸~
所以呀,如果有小伙伴遇见类似的问题,除了google之外,可以直接考虑重装下自己的vmware。

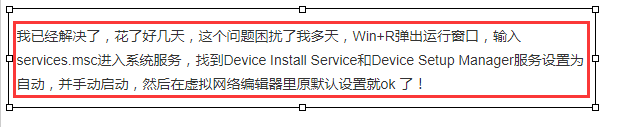
嗯~好,当主机与虚拟机ping通之后就可以来做分布式了,具体实现细节我就不再赘余了,百度一下出来一大堆结果。我之后会写一篇关于scrapy-redis的源码解读的博客。这里只是记录一下具体代码实现的过程。
目标网址:人民网
2
2
同样无反爬措施,可以安心使用。
items.py
2
3
4
5
6
7
8
9
10
11
2 2
3 3
4 4 class PeopleItem(scrapy.Item):
5 5 # define the fields for your item here like:
6 6 # name = scrapy.Field()
7 7 title = scrapy.Field()
8 8 pub_time = scrapy.Field()
9 9 url = scrapy.Field()
1010 content = scrapy.Field()
11
spiders.py
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
2 2 import scrapy
3 3
4 4 from scrapy_redis.spiders import RedisSpider
5 5 from ..items import PeopleItem
6 6
7 7
8 8 class RedisTestSpider(RedisSpider):
9 9 name = 'redis-test'
1010 # allowed_domains = ['people.com.cn'] 有坑需注意
1111 # start_urls = ['http://politics.people.com.cn/GB/1024/index1.html']
1212
1313 redis_key = "redistest:start_urls"
1414
1515 def __init__(self, *args, **kwargs):
1616 domain = kwargs.pop('domain', '')
1717 self.allowed_domains = filter(None, domain.split(','))
1818 super(RedisTestSpider, self).__init__(*args, **kwargs)
1919
2020 def parse(self, response):
2121 news_list = response.xpath("//div[@class='ej_list_box clear']/ul/li")
2222 for new in news_list:
2323 item = PeopleItem()
2424 title = new.xpath("./a/text()").extract_first()
2525 url = new.xpath("./a/@href").extract_first()
2626 url = "http://politics.people.com.cn" + url
2727 pub_time = new.xpath("./em/text()").extract_first()
2828
2929 item["title"] = title
3030 item["url"] = url
3131 item["pub_time"] = pub_time
3232 yield scrapy.Request(url=url, meta={"item": item}, callback=self.parse_detail,
3333 dont_filter=True) # 必须要加上 dont_filter 参数
3434
3535 # 下一页
3636 next_page_url = response.xpath("//div[@class='page_n clearfix']/a[last()]/@href").extract_first()
3737 next_page_url = "http://politics.people.com.cn/GB/1024/" + next_page_url
3838 is_active = response.xpath("//div[@class='page_n clearfix']/a[last()]/@href").extract_first()
3939
4040 if next_page_url and is_active != "common_current_page":
4141 yield scrapy.Request(url=next_page_url, callback=self.parse, dont_filter=True) # 必须要加上 dont_filter 参数
4242
4343 def parse_detail(self, response):
4444 item = response.meta["item"]
4545 article = ""
4646 content_list = response.xpath("//div[@class='fl text_con_left']//p/text()").extract()
4747 for content in content_list:
4848 content = content.strip()
4949 article += content
5050 print(article)
5151 item["content"] = article
5252 yield item
53
spiders.py 这里会有坑的,人民网他的url设计的时候跨度比较大 allowed_domains = ['people.com.cn'] 有时候无法匹配的上,这个时候会控制台会报如下错:
2
2

解决的办法就是将allowed_domains = ['people.com.cn'] 注释掉,如果还不能解决就加上 dont_filter ,表示本次请求不要要对url进行过滤。
settings.py
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
2 Safari/537.36 SE 2.X MetaSr 1.0'
3
4ROBOTSTXT_OBEY = False
5
6ITEM_PIPELINES = {
7 # 'people.pipelines.PeoplePipeline': 300,
8 'scrapy_redis.pipelines.RedisPipeline': 400,
9}
10
11# 使用scrapy-redis的去重规则
12DUPEFILTER_CLASS = "scrapy_redis.dupefilter.RFPDupeFilter"
13# 使用scrapy-redis的引擎
14SCHEDULER = "scrapy_redis.scheduler.Scheduler"
15# 暂停功能
16SCHEDULER_PERSIST = True
17# 默认的scrapy-redis请求队列形式(按优先级)
18SCHEDULER_QUEUE_CLASS = "scrapy_redis.queue.SpiderPriorityQueue"
19# 注释掉默认使用主机的redis
20# REDIS_HOST = '192.168.48.128'
21# REDIS_PORT = 6379
22
piplines.py
将redis里面的数据存储至mongodb / mysql 这里我在网上找到了一些文章我自己还没有取验证,目前主流的做法是单独的写脚本,从redis里面取数据,我是觉得这种做法特别的不好、特别的low,等我验证了网上的一些教程后在来贴出来。
结束语:
ok,scrapy真的是一个可拓展性很强的框架,短短的几行设置就能够实现分布式,日后我会更新一些反爬虫措施强一点的网站、模拟登录、以及scrapy的源码解读。老是爬一些无反爬措施的网站真的没什么意思。休息了休息了~
