网站为了支撑更大的用户访问量,往往需要对用户访问的数据做cache,服务机群和负载均衡来专门处理缓存,负载均衡的算法很多,轮循算法、哈希算法、最少连接算法、响应速度算法等,hash算法是比较常用的一种,它的常用思想是先计算出一个hash值,然后使用 CRC余数算法将hash值和机器数mod后取余数,机器的编号可以是0到N-1(N是机器数),计算出的结果一一对应即可。
缓存最关键的就是命中率这个因素,如果命中率非常低,那么缓存也就失去了它的意义。如采用一般的CRC取余的hash算法虽然能达到负载均衡的目的,但是它存在一个严重的问题,那就是如果其中一台服务器down掉,那么就需要在计算缓存过程中将这台服务器去掉,即N台服务器,目前就只有N-1台提供缓存服务,此时需要一个rehash过程,而reash得到的结果将导致正常的用户请求不能找到原来缓存数据的正确机器,其他N-1台服务器上的缓存数据将大量失效,此时所有的用户请求全部会集中到数据库上,严重可能导致整个生产环境挂掉.
举个例子,有5台服务器,编号分别是0(A),1(B),2(C),3(D),4(E) ,正常情况下,假设用户数据hash值为12,那么对应的数据应该缓存在12%5=2号服务器上,假设编号为3的服务器此时挂掉,那么将其移除后就得到一个新的0(A),1(B),2(C),3(E)(注:这里的编号3其实就是原来的4号服务器)服务器列表,此时用户来取数据,同样hash值为12,rehash后的得到的机器编号12%4=0号服务器,可见,此时用户到0号服务器去找数据明显就找不到,出现了cache不命中现象,如果不命中此时应用会从后台数据库重新读取数据再cache到0号服务器上,如果大量用户出现这种情况,那么后果不堪设想。同样,增加一台缓存服务器,也会导致同样的后果。
可以有一种设想,要提高命中率就得减少增加或者移除服务器rehash带来的影响,那么有这样一种算法么?Consistent hashing算法就是这样一种hash算法,简单的说,在移除/添加一个 cache 时,它能够尽可能小的改变已存在 key 映射关系,尽可能的满足单调性的要求。
1.环形Hash空间
按照常用的hash算法来将对应的key哈希到一个具有2^32个桶的空间中,即0~(2^32)-1的数字空间中。可以将这些数字头尾相连,想象成一个闭合的环形。如下图:
2.把数据通过一定的hash算法处理后映射到环上
现在将object1、object2、object3、object4四个对象通过特定的Hash函数计算出对应的key值,然后散列到Hash环上。如下图:
Hash(object1) = key1;
Hash(object2) = key2;
Hash(object3) = key3;
Hash(object4) = key4;
3.将机器通过hash算法映射到环上
在采用一致性哈希算法的分布式集群中将新的机器加入,其原理是通过使用与对象存储一样的Hash算法将机器也映射到环中(一般情况下对机器的hash计算是采用机器的IP或者机器唯一的别名作为输入值),然后以顺时针的方向计算,将所有对象存储到离自己最近的机器中。
假设现在有NODE1,NODE2,NODE3三台机器,通过Hash算法得到对应的KEY值,映射到环中,其示意图如下:
Hash(NODE1) = KEY1;
Hash(NODE2) = KEY2;
Hash(NODE3) = KEY3;
通过上图可以看出对象与机器处于同一哈希空间中,这样按顺时针转动object1存储到了NODE1中,object3存储到了NODE2中,object2、object4存储到了NODE3中。在这样的部署环境中,hash环是不会变更的,因此,通过算出对象的hash值就能快速的定位到对应的机器中,这样就能找到对象真正的存储位置了。
4.机器的删除与添加
普通hash求余算法最为不妥的地方就是在有机器的添加或者删除之后会照成大量的对象存储位置失效,这样就大大的不满足单调性了。下面来分析一下一致性哈希算法是如何处理的。
1. 节点(机器)的删除
以上面的分布为例,如果NODE2出现故障被删除了,那么按照顺时针迁移的方法,object3将会被迁移到NODE3中,这样仅仅是object3的映射位置发生了变化,其它的对象没有任何的改动。如下图:
2. 节点(机器)的添加
如果往集群中添加一个新的节点NODE4,通过对应的哈希算法得到KEY4,并映射到环中,如下图:
通过按顺时针迁移的规则,那么object2被迁移到了NODE4中,其它对象还保持这原有的存储位置。通过对节点的添加和删除的分析,一致性哈希算法在保持了单调性的同时,还是数据的迁移达到了最小,这样的算法对分布式集群来说是非常合适的,避免了大量数据迁移,减小了服务器的的压力。
5.平衡性
根据上面的图解分析,一致性哈希算法满足了单调性和负载均衡的特性以及一般hash算法的分散性,但这还并不能当做其被广泛应用的原由,因为还缺少了平衡性。下面将分析一致性哈希算法是如何满足平衡性的。
hash算法是不保证平衡的,如上面只部署了NODE1和NODE3的情况(NODE2被删除的图),object1存储到了NODE1中,而object2、object3、object4都存储到了NODE3中,这样NODE3节点由于承担了NODE2节点的数据,所以NODE3节点的负载会变高,NODE3节点很容易也宕机,这样依次下去可能造成整个集群都挂了。
在一致性哈希算法中,为了尽可能的满足平衡性,其引入了虚拟节点。“虚拟节点”( virtual node )是实际节点(机器)在 hash 空间的复制品(replica),一实际个节点(机器)对应了若干个“虚拟节点”,这个对应个数也成为“复制个数”,“虚拟节点”在 hash 空间中以hash值排列。即把想象在这个环上有很多“虚拟节点”,数据的存储是沿着环的顺时针方向找一个虚拟节点,每个虚拟节点都会关联到一个真实节点。
图中的A1、A2、B1、B2、C1、C2、D1、D2都是虚拟节点,机器A负载存储A1、A2的数据,机器B负载存储B1、B2的数据,机器C负载存储C1、C2的数据。由于这些虚拟节点数量很多,均匀分布,因此不会造成“雪崩”现象。
使用虚拟节点的思想,为每个物理节点(服务器)在圆上分配100~200个点。这样就能抑制分布不均匀,最大限度地减小服务器增减时的缓存重新分布。用户数据映射在虚拟节点上,就表示用户数据真正存储位置是在该虚拟节点代表的实际物理服务器上。
下面有一个图描述了需要为每台物理服务器增加的虚拟节点。
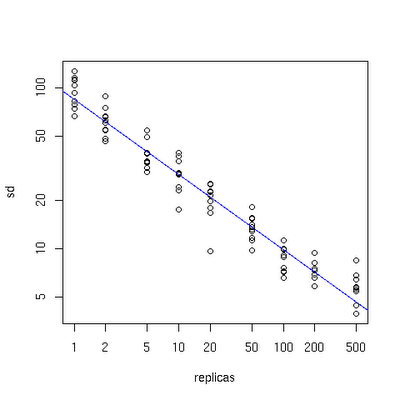
x轴表示的是需要为每台物理服务器扩展的虚拟节点倍数(scale),y轴是实际物理服务器数,可以看出,当物理服务器的数量很小时,需要更大的虚拟节点,反之则需要更少的节点,从图上可以看出,在物理服务器有10台时,差不多需要为每台服务器增加100~200个虚拟节点才能达到真正的负载均衡。
简单的java代码实现:
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
2
3 /**
4 * 哈希函数
5 */
6 private final HashFunction hashFunction;
7
8 /**
9 * 虚拟节点数 , 越大分布越均衡,但越大,在初始化和变更的时候效率差一点。 测试中,设置200基本就均衡了。
10 */
11 private final int numberOfReplicas;
12
13 /**
14 * 环形Hash空间
15 */
16 private final SortedMap<Integer, T> circle = new TreeMap<Integer, T>();
17
18 /**
19 * @param hashFunction
20 * ,哈希函数
21 * @param numberOfReplicas
22 * ,虚拟服务器系数
23 * @param nodes
24 * ,服务器节点
25 */
26 public ConsistentHash(HashFunction hashFunction, int numberOfReplicas,
27 Collection<T> nodes) {
28 this.hashFunction = hashFunction;
29 this.numberOfReplicas = numberOfReplicas;
30
31 for (T node : nodes) {
32 this.addNode(node);
33 }
34 }
35
36 /**
37 * 添加物理节点,每个node 会产生numberOfReplicas个虚拟节点,这些虚拟节点对应的实际节点是node
38 */
39 public void addNode(T node) {
40 for (int i = 0; i < numberOfReplicas; i++) {
41 int hashValue = hashFunction.hash(node.toString() + i);
42 circle.put(hashValue, node);
43 }
44 }
45
46 /**移除物理节点,将node产生的numberOfReplicas个虚拟节点全部移除
47 * @param node
48 */
49 public void removeNode(T node) {
50 for (int i = 0; i < numberOfReplicas; i++) {
51 int hashValue = hashFunction.hash(node.toString() + i);
52 circle.remove(hashValue);
53 }
54 }
55
56 /**
57 * 得到映射的物理节点
58 *
59 * @param key
60 * @return
61 */
62 public T getNode(Object key) {
63 if (circle.isEmpty()) {
64 return null;
65 }
66 int hashValue = hashFunction.hash(key);
67// System.out.println("key---" + key + " : hash---" + hash);
68 if (!circle.containsKey(hashValue)) {
69 // 返回键大于或等于hash的node,即沿环的顺时针找到一个虚拟节点
70 SortedMap<Integer, T> tailMap = circle.tailMap(hashValue);
71 // System.out.println(tailMap);
72 // System.out.println(circle.firstKey());
73 hashValue = tailMap.isEmpty() ? circle.firstKey() : tailMap.firstKey();
74 }
75// System.out.println("hash---: " + hash);
76 return circle.get(hashValue);
77 }
78
79 static class HashFunction {
80 /**
81 * MurMurHash算法,是非加密HASH算法,性能很高,
82 * 比传统的CRC32,MD5,SHA-1(这两个算法都是加密HASH算法,复杂度本身就很高,带来的性能上的损害也不可避免)
83 * 等HASH算法要快很多,而且据说这个算法的碰撞率很低. http://murmurhash.googlepages.com/
84 */
85 int hash(Object key) {
86 ByteBuffer buf = ByteBuffer.wrap(key.toString().getBytes());
87 int seed = 0x1234ABCD;
88
89 ByteOrder byteOrder = buf.order();
90 buf.order(ByteOrder.LITTLE_ENDIAN);
91
92 long m = 0xc6a4a7935bd1e995L;
93 int r = 47;
94
95 long h = seed ^ (buf.remaining() * m);
96
97 long k;
98 while (buf.remaining() >= 8) {
99 k = buf.getLong();
100
101 k *= m;
102 k ^= k >>> r;
103 k *= m;
104
105 h ^= k;
106 h *= m;
107 }
108
109 if (buf.remaining() > 0) {
110 ByteBuffer finish = ByteBuffer.allocate(8).order(
111 ByteOrder.LITTLE_ENDIAN);
112 finish.put(buf).rewind();
113 h ^= finish.getLong();
114 h *= m;
115 }
116
117 h ^= h >>> r;
118 h *= m;
119 h ^= h >>> r;
120 buf.order(byteOrder);
121 return (int) h;
122 }
123 }
124}
125
126
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
2
3 public static void main(String[] args) {
4 HashSet<String> serverNode = new HashSet<String>();
5 serverNode.add("127.1.1.1#A");
6 serverNode.add("127.2.2.2#B");
7 serverNode.add("127.3.3.3#C");
8 serverNode.add("127.4.4.4#D");
9
10 Map<String, Integer> serverNodeMap = new HashMap<String, Integer>();
11
12 ConsistentHash<String> consistentHash = new ConsistentHash<String>(
13 new HashFunction(), 200, serverNode);
14
15 int count = 50000;
16
17 for (int i = 0; i < count; i++) {
18 String serverNodeName = consistentHash.getNode(i);
19 // System.out.println(i + " 映射到物理节点---" + serverNodeName);
20 if (serverNodeMap.containsKey(serverNodeName)) {
21 serverNodeMap.put(serverNodeName,
22 serverNodeMap.get(serverNodeName) + 1);
23 } else {
24 serverNodeMap.put(serverNodeName, 1);
25 }
26 }
27 // System.out.println(serverNodeMap);
28
29 showServer(serverNodeMap);
30 serverNodeMap.clear();
31
32 consistentHash.removeNode("127.1.1.1#A");
33 System.out.println("-------------------- remove 127.1.1.1#A");
34
35 for (int i = 0; i < count; i++) {
36 String serverNodeName = consistentHash.getNode(i);
37 // System.out.println(i + " 映射到物理节点---" + serverNodeName);
38 if (serverNodeMap.containsKey(serverNodeName)) {
39 serverNodeMap.put(serverNodeName,
40 serverNodeMap.get(serverNodeName) + 1);
41 } else {
42 serverNodeMap.put(serverNodeName, 1);
43 }
44 }
45
46 showServer(serverNodeMap);
47 serverNodeMap.clear();
48
49 consistentHash.addNode("127.5.5.5#E");
50 System.out.println("-------------------- add 127.5.5.5#E");
51
52 for (int i = 0; i < count; i++) {
53 String serverNodeName = consistentHash.getNode(i);
54 // System.out.println(i + " 映射到物理节点---" + serverNodeName);
55 if (serverNodeMap.containsKey(serverNodeName)) {
56 serverNodeMap.put(serverNodeName,
57 serverNodeMap.get(serverNodeName) + 1);
58 } else {
59 serverNodeMap.put(serverNodeName, 1);
60 }
61 }
62
63 showServer(serverNodeMap);
64 serverNodeMap.clear();
65
66 consistentHash.addNode("127.6.6.6#F");
67 System.out.println("-------------------- add 127.6.6.6#F");
68 count *= 2;
69 System.out.println("-------------------- 业务量加倍");
70 for (int i = 0; i < count; i++) {
71 String serverNodeName = consistentHash.getNode(i);
72 // System.out.println(i + " 映射到物理节点---" + serverNodeName);
73 if (serverNodeMap.containsKey(serverNodeName)) {
74 serverNodeMap.put(serverNodeName,
75 serverNodeMap.get(serverNodeName) + 1);
76 } else {
77 serverNodeMap.put(serverNodeName, 1);
78 }
79 }
80 showServer(serverNodeMap);
81
82 }
83
84 /**
85 * 服务器运行状态
86 *
87 * @param map
88 */
89 public static void showServer(Map<String, Integer> map) {
90 for (Entry<String, Integer> m : map.entrySet()) {
91 System.out.println(m.getKey() + ", 存储数据量 " + m.getValue());
92 }
93 }
94}
95
96
2
2
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
2127.2.2.2#B, 存储数据量 11834
3127.3.3.3#C, 存储数据量 12827
4127.1.1.1#A, 存储数据量 12162
5-------------------- remove 127.1.1.1#A
6127.4.4.4#D, 存储数据量 17696
7127.2.2.2#B, 存储数据量 15114
8127.3.3.3#C, 存储数据量 17190
9-------------------- add 127.5.5.5#E
10127.4.4.4#D, 存储数据量 12154
11127.2.2.2#B, 存储数据量 11878
12127.3.3.3#C, 存储数据量 12908
13127.5.5.5#E, 存储数据量 13060
14-------------------- add 127.6.6.6#F
15-------------------- 业务量加倍
16127.4.4.4#D, 存储数据量 18420
17127.2.2.2#B, 存储数据量 20197
18127.6.6.6#F, 存储数据量 21015
19127.5.5.5#E, 存储数据量 19038
20127.3.3.3#C, 存储数据量 21330
21
