因为业务逻辑的修改,投放数据存入大数据集群中,因此,需要修改之前的业务逻辑,需要实时知道rtb投放的花费情况。
环境版本:
spark: 2.11-2.4.0-cdh6.2.0
kafka: 2.1.0-cdh6.2.0
fluem: 1.9.0-cdh6.2.0
-
-
Flume配置
-
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
2
3a1.sinks = k1
4
5a1.channels = c1
6
7#sources
8
9a1.sources.r1.type = spooldir # 监控目录方式读取新增的日志文件
10
11a1.sources.r1.recursiveDirectorySearch = true # flume在1.9版本中已实现递归监视子文件夹里的有新文件产生的功能
12
13a1.sources.r1.spoolDir = /mnt/data1/flume_data/bid_bsw # flume监控的目录
14
15a1.sources.r1.fileHeader = false
16
17a1.sources.r1.ignorePattern = ^(.)*\\.[0|1]{1}$
18
19a1.sources.r1.includePattern = ^bid.log.[0-9]{12}$
20
21#channels
22
23a1.channels.c1.type = memory
24
25a1.channels.c1.capacity = 1000
26
27a1.channels.c1.transactionCapacity = 100
28
29#sinks
30
31a1.sinks.k1.type = org.apache.flume.sink.kafka.KafkaSink
32
33a1.sinks.k1.kafka.topic = statistic_bid_topic # 读取的topic
34
35a1.sinks.k1.kafka.bootstrap.servers = 192.168.1.65:9092,192.168.1.66:9092,192.168.1.67:9092
36
37a1.sinks.k1.kafka.producer.acks=1
38
39a1.sinks.k1.kafka.flumeBatchSize =20
40
41a1.sinks.k1.channel = c1
42
43a1.sources.r1.channels = c1
44
说明:
a1.sources.r1.spoolDir配置监控bid日志的目录;
a1.sources.r1.recursiveDirectorySearch配置此监控目录可以递归监控是否有新的文件产生;
a1.sinks.k1.kafka.bootstrap.servers配置kafka的Destination Broker List值
-
- kafka安装和配置
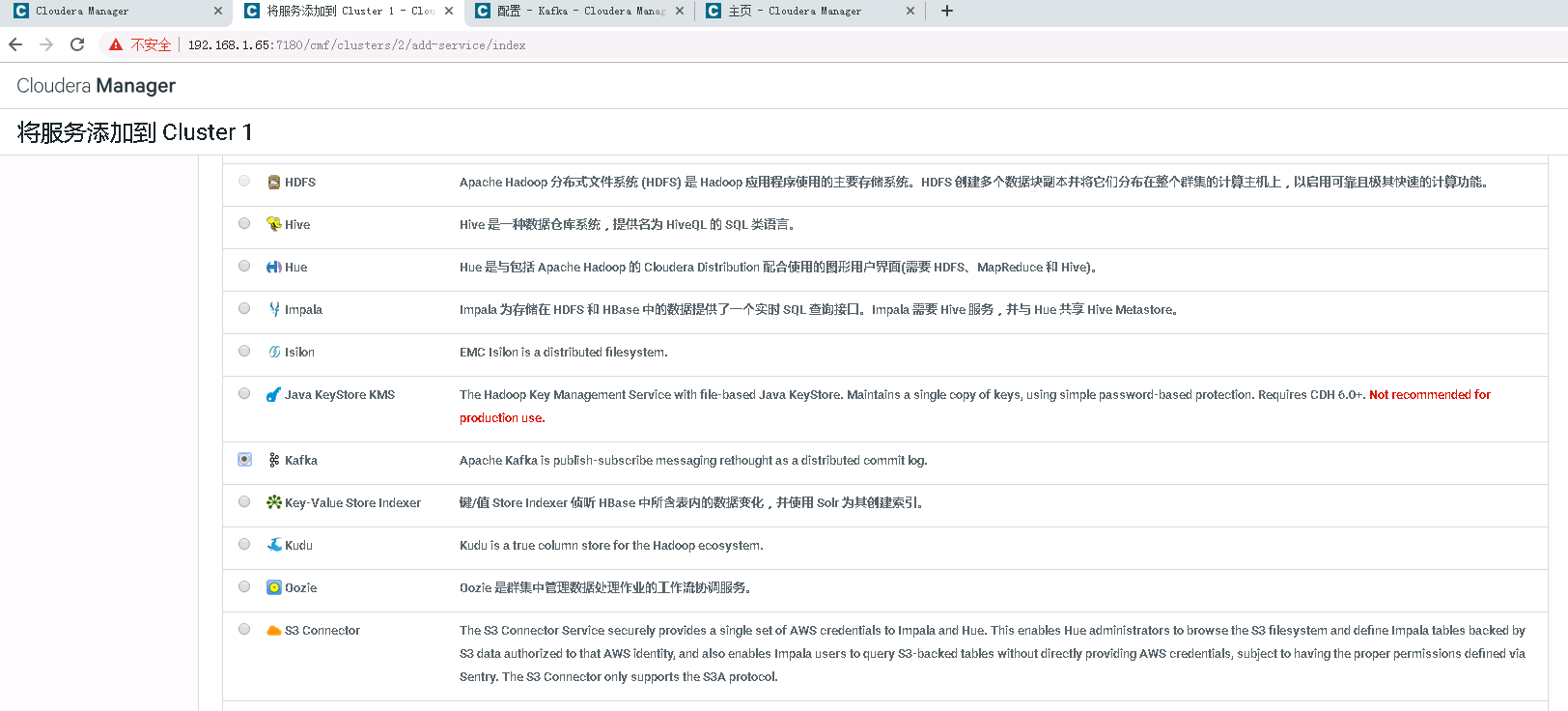
在cdh集群:操作->添加服务->Kafka进行相应添加
安装cdh-master,cdh-slaver1,cdh-slaver2作为kafka broker;
cdh-master作为Kafka MirrorMaker
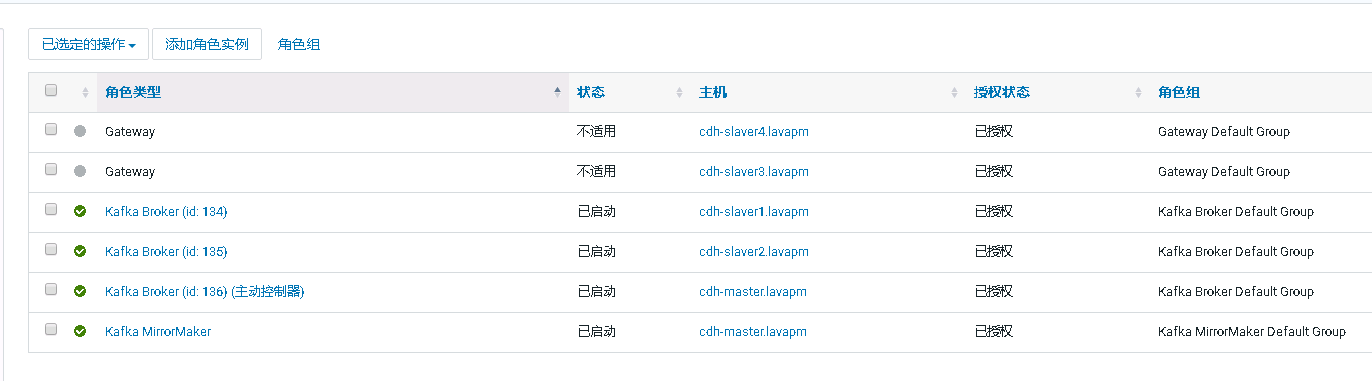
Kafka配置:
zookeeper.chroot
:
设置为
/kafka
auto.create.topics.enable
:勾选
delete.topic.enable
:勾选
broker.id

log.dirs
:
/XXX/kafka/data
注意:如果此路径的磁盘空间不足,kafka
会报错关闭!
bootstrap.servers
:
192.168.1.65:9092,192.168.1.66:9092,192.168.1.67:9092 (安装kafka的服务器,如上图所示)
source.bootstrap.servers
:
192.168.1.65:9092,192.168.1.66:9092,192.168.1.67:9092
whitelist
:
192.168.1.65:9092,192.168.1.66:9092,192.168.1.67:9092
oom_heap_dump_dir
:
/tmp
kafka设置topic命令:
到kafka的安装bin目录下,执行:
./kafka-topics.sh –create –topic statistic_bid_topic –zookeeper cdh-master.lavapm:2181,cdh-slaver1.lavapm:2181,cdh-slaver2.lavapm:2181/kafka –partitions 3 –replication-factor 2
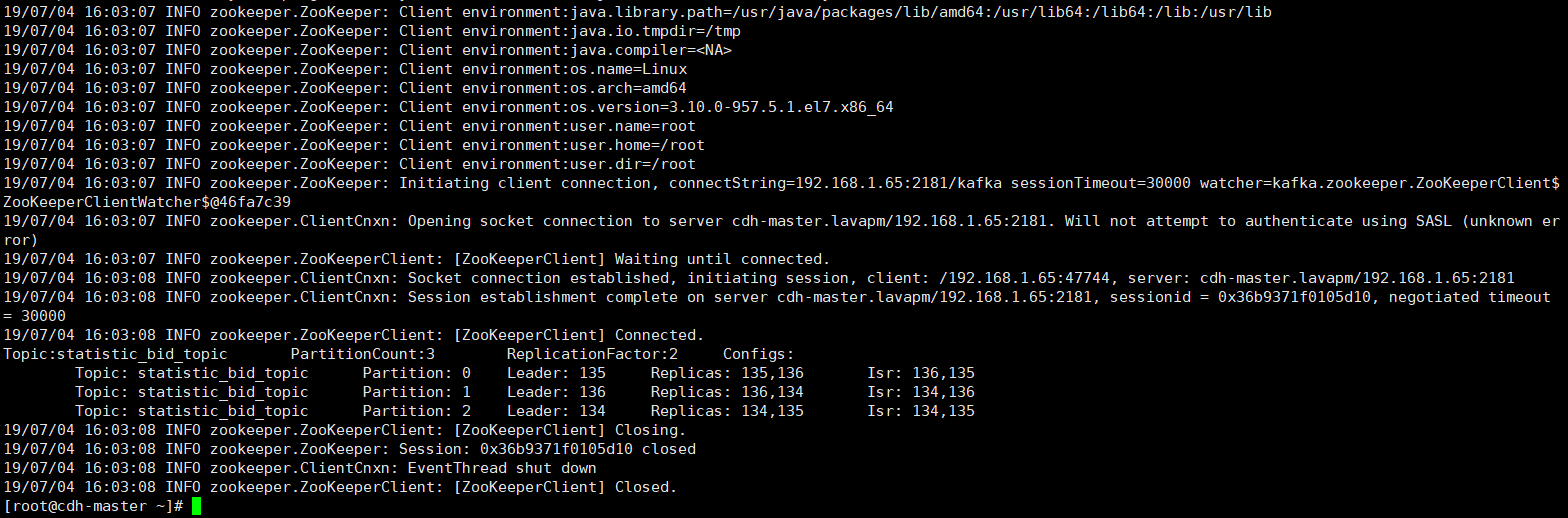
设置了topic名字为statistic_bid_topic,设置了3个分区,2个副本;
查看所有的topic命令:
./kafka-topics.sh –zookeeper 192.168.1.65:2181/kafka –list
查看某个topic详细信息:
列出了statistic_bid_topic的parition数量、replica因子以及每个partition的leader、replica信息,命令为:
./kafka-topics.sh –zookeeper 192.168.1.65:2181/kafka –topic statistic_bid_topic –describe
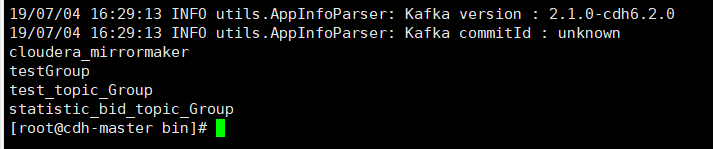
查看consumer group列表
使用–list参数,命令为:
./kafka-consumer-groups.sh –bootstrap-server 192.168.1.65:9092 –list
**查看特定****consumer group **详情
使用
–group
与
–describe
参数
,运行命令:
./kafka-consumer-groups.sh –bootstrap-server 192.168.1.65:9092 –group statistic_bid_topic_Group –describe

接收消息,从头开始接收全部数据命令:
./kafka-console-consumer.sh –bootstrap-server 192.168.1.65:9092 –topic statistic_bid_topic –from-beginning
生产消息命令:
./kafka-console-producer.sh –broker-list cdh-master.lavapm:9092 –topic statistic_bid_topic
- 3.spark streaming开发
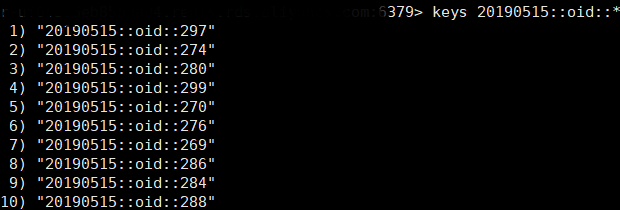
实时读取kafka对应topic中的bid数据,一行一行解析json字符串,获取对应的imp,bid,click数据,然后做统计和合并,最后以增量方式存入redis中,因为是用于每天的投放统计,因此,存储的key的格式为:年月日::oid::推广单元id,如下图所示:
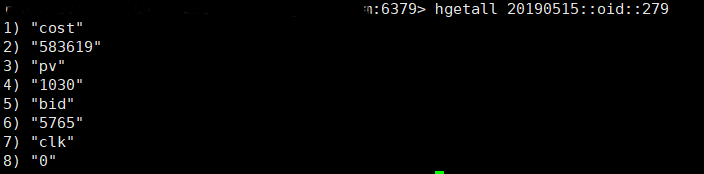
具体某个推广单元的详细数据如下图所示:
代码实现使用scala:
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
164
165
166
167
168
169
170
171
172
173
174
175
176
177
178
179
180
181
182
183
184
185
186
187
188
189
190
191
192
193
194
195
196
197
198
199
200
201
202
203
204
205
206
207
208
209
210
211
212
213
214
215
216
217
218
219
220
221
222
223
224
225
2import java.util.Date
3import org.apache.kafka.common.serialization.StringDeserializer
4import org.apache.log4j.{Level, Logger}
5import org.apache.spark.rdd.RDD
6import org.apache.spark.streaming.{Seconds, StreamingContext}
7import org.apache.spark.{SparkConf, SparkContext}
8import org.apache.spark.streaming.kafka010._
9import org.apache.spark.streaming.kafka010.LocationStrategies.PreferConsistent
10import org.apache.spark.streaming.kafka010.ConsumerStrategies.Subscribe
11import org.apache.spark.sql.SparkSession
12import org.apache.spark.streaming.dstream.DStream
13import org.apache.spark.HashPartitioner
14import scala.util.parsing.json._
15import redis.clients.jedis.{Jedis, JedisPool, JedisPoolConfig}
16
17object KafkaBidStatistic extends Serializable {
18
19 def regJson(json: Option[Any]) = json match {
20 // 转换类型
21 case Some(map: collection.immutable.Map[String, Any]) => map
22 }
23
24 /**
25 * 解析多层json
26 *
27 * @param string_json
28 * @return
29 */
30 def str_json(string_json: String): collection.immutable.Map[String, Any] = {
31 var first: collection.immutable.Map[String, Any] = collection.immutable.Map()
32 val jsonS = JSON.parseFull(string_json)
33 //不确定数据的类型时,此处加异常判断
34 if (jsonS.isInstanceOf[Option[Any]]) {
35 first = regJson(jsonS);
36 }
37 first
38 }
39
40 def get_str_json(line: String): String = {
41 var ret = "";
42 try{
43 var first: collection.immutable.Map[String, Any] = str_json(line);
44 // 根据imp日志数据的特征,提取一种imp日志数据作为统计值
45 // imp日志数据列子:{"cip":"223.24.172.199","mid":"687","pid":"","oid":"284","et":{"bid":1557196078,"imp":1557196080},"wd":{},"ip":"35.200.110.13","ov":1,"ex":20191211,"url":"","usc":["IAB18"],"uri":"\/imp?ext_data=b2lkPTI4NCxjaWQ9LHV1aWQ9VURhSlVmQXEybW1acmVpSTZzWVJCZSxtZT1iaWRzd2l0Y2gsZXg9Ymlkc3dpdGNoLHBjPTAsbGlkPSxuYXQ9MCx2cj0wLHV0PTE1NTcxOTYwNzgsZG9tPSxwaWQ9LG9jYz1jaW0sY2NwPTU2MDAwMCxhaWQ9Njg3LHk9MCxhdj0w&ver=1&reqid=bidswitch&price=0.55992","occ":"cim","me":"bidswitch","mobile":{"id":"","os":2},"ua":"BidSwitch\/1.0","id":"UDaJUfAq2mmZreiI6sYRBe","op":"","ccp":1,"ins":{},"sz":"320x50","reuse":1,"wp":0.55992,"is_mobile":1,"nwp":1,"ev":"imp","rg":1840000000,"did":"CDz2mRv7s7fffMuVY3eeuy"}
46 // && first.contains("uri") 国内投放没有此值!
47 if (first("ev").toString == "imp" && first.contains("me")) { // first.getOrElse("me" , 1) && first("me").toString=="bidswitch"
48 val wp = first("wp");
49 val mid = first("mid").toString;
50 val oid = first("oid").toString;
51 val ev = first("ev").toString;
52 val id = first("id").toString;
53 ret = oid + "," + mid + "," + wp + ",\"" + ev + "\",\"" + id + "\""; // oid,mid,wp,"imp","id"
54 }
55 else if (first("ev").toString == "bid") {
56 val mid = first("mid").toString;
57 val oid = first("oid").toString;
58 val id = first("id").toString;
59 val ev = first("ev").toString;
60 ret = oid + "," + mid + ",\"" + ev + "\",\"" + id + "\""; // oid,mid,"bid","id"
61 }
62 else if (first("ev").toString == "clk") {
63 val mid = first("mid").toString;
64 val oid = first("oid").toString;
65 val id = first("id").toString;
66 val ev = first("ev").toString;
67 ret = oid + "," + mid + ",\"" + ev + "\",\"" + id + "\""; // oid,mid,"clk","id"
68 }
69 }
70 catch{
71 case ex: Exception => {
72 ex.printStackTrace() // 打印到标准err
73 System.err.println("get_str_json()解析字符串异常! line = "+line) // 打印到标准err
74 }
75 }
76 ret;
77 }
78
79
80 def main(args: Array[String]): Unit = {
81 // Logger.getLogger("org.apache.spark").setLevel(Level.WARN);
82
83 Logger.getLogger("org.apache.spark").setLevel(Level.ERROR)
84 Logger.getLogger("org.eclipse.jetty.server").setLevel(Level.ERROR)
85 Logger.getLogger("org.apache.kafka.clients.consumer").setLevel(Level.ERROR)
86
87 val conf = new SparkConf();
88 conf.setMaster("yarn").setAppName("statisticBid2Redis")
89 //每隔2秒监测一次是否有数据
90 val ssc = new StreamingContext(conf, Seconds.apply(2))
91 val ssce = SparkSession.builder().config(conf).getOrCreate
92
93 // 提高Job并发数
94 // spark.conf.set("spark.streaming.concurrentJobs", 10)
95 // 获取topic分区leaders及其最新offsets时,调大重试次数。 Receiver模式下使用
96 //spark.conf.set("spark.streaming.kafka.maxRetries", 50)
97 //开启反压
98 ssce.conf.set("spark.streaming.backpressure.enabled",true)
99 //确保在kill任务时,能够处理完最后一批数据,再关闭程序,不会发生强制kill导致数据处理中断,没处理完的数据丢失
100 ssce.conf.set("spark.streaming.stopGracefullyOnShutdown",true)
101 //反压机制时初始化的摄入量,该参数只对receiver模式起作用,并不适用于direct模式
102 ssce.conf.set("spark.streaming.backpressure.initialRate",5000)
103 // 设置每秒每个分区最大获取日志数,控制处理数据量,保证数据均匀处理。
104 // 每次作业中每个,Kafka分区最多读取的记录条数。可以防止第一个批次流量出现过载情况,也可以防止批次处理出现数据流量过载情况
105 ssce.conf.set("spark.streaming.kafka.maxRatePerPartition",3000)
106
107 val sc = ssce.sparkContext;
108 println("********* spark.default.parallelism *********"+sc.defaultParallelism)
109
110 val kafkaParams = Map[String, Object](
111 "bootstrap.servers" -> "192.168.1.65:9092,192.168.1.66:9092,192.168.1.67:9092", // kafka 集群
112 "key.deserializer" -> classOf[StringDeserializer],
113 "value.deserializer" -> classOf[StringDeserializer],
114 "group.id" -> "statistic_bid_topic_Group", // statistic_bid_topic_Group
115 "auto.offset.reset" -> "latest", // 1.earliest 每次都是从头开始消费(from-beginning)2.latest 消费最新消息 3.smallest 从最早的消息开始读取
116 "enable.auto.commit" -> (true: java.lang.Boolean) //true , false=手动提交offset
117 )
118
119 val topics = Array("statistic_bid_topic") //主题,可配置多个
120
121 //Direct方式
122 val stream = KafkaUtils.createDirectStream[String, String](
123 ssc,
124 PreferConsistent,
125 Subscribe[String, String](topics, kafkaParams)
126 )
127
128 stream.foreachRDD { kafkaRDD =>
129 if (!kafkaRDD.isEmpty()) {
130 val now: Date = new Date();
131 val dateFormat: SimpleDateFormat = new SimpleDateFormat("yyyyMMdd");
132 val date_str = dateFormat.format(now);
133 val df: SimpleDateFormat = new SimpleDateFormat("yyyy-MM-dd HH:mm:ss");//yyyyMMddHHmmss
134
135 // val offsetRanges = kafkaRDD.asInstanceOf[HasOffsetRanges].offsetRanges
136
137 val lines: RDD[String] = kafkaRDD.map(e => (e.value()))
138
139 //解析json字符串
140 val rdd = lines.flatMap {
141 line =>
142 val parse_str = get_str_json(line);
143 val arr = parse_str.split("\t");
144 arr;
145 }.filter(word => word.nonEmpty).distinct(); //去空行
146
147 rdd.cache();
148
149 // imp oid,mid,wp,"imp","id"
150 val rdd_imp = rdd.flatMap(_.split("\t")).filter(_.indexOf("\"imp\"") > 0).map(_.split(","));
151 val rdd_imp1 = rdd_imp.map(word => (word(0), word(1)) -> (word(2).toDouble / 1000).formatted("%.6f").toDouble); // oid,mid->wp 价格是cpm,因此要除以1000
152
153 // 统计 cost
154 //val result_imp_cost = rdd_imp1.reduceByKey(_ + _).sortBy(_._2, false).map({ case ((oid, mid), wp) => (oid, mid) -> (wp.toDouble.formatted("%.6f").toDouble*1000000).toInt }); bidswitch数据是真实价格,没有*1000
155 val result_imp_cost = rdd_imp1.reduceByKey(_ + _).sortBy(_._2, false).map({ case ((oid, mid), wp) => (oid, mid) -> (wp.toDouble.formatted("%.6f").toDouble*1000).toInt });
156
157 // 统计 pv
158 val rdd_imp3 = rdd_imp1.map({ case ((oid, mid), wp) => (oid, mid) -> 1 }); // oid,mid->1
159 val result_imp_count = rdd_imp3.reduceByKey(_ + _).sortBy(_._2, false);// 统计pv
160
161 //统计 bid num oid,mid,"bid","id"
162 val rdd_bid = rdd.flatMap(_.split("\t")).distinct.filter(_.indexOf("\"bid\"") > 0).map(_.split(","));
163 val rdd_bid1 = rdd_bid.map(word => (word(0), word(1)) -> 1);
164 val result_bid_count = rdd_bid1.reduceByKey(_ + _).sortBy(_._2, false);
165
166 //统计 clk num oid,mid,"clk","id"
167 val rdd_clk = rdd.flatMap(_.split("\t")).distinct.filter(_.indexOf("\"clk\"") > 0).map(_.split(","));
168 val rdd_clk1 = rdd_clk.map(word => (word(0), word(1)) -> 1);
169 val result_clk_count = rdd_clk1.reduceByKey(_ + _).sortBy(_._2, false);
170
171 // join imp+bid+clk
172 val rdd_join1 = result_imp_cost.join(result_imp_count).map({ case ((oid, mid), (wp, pv)) => (oid, mid) -> (wp, pv) }); // ((oid,mid),(wp,pv))
173 val rdd_join2 = result_bid_count.leftOuterJoin(rdd_join1);
174 // (oid,mid),(bid,(wp,pv)) (wp,pv)Option[(Double,Int)]
175 val rdd_join3 = rdd_join2.map { case ((oid, mid), (bid, x)) =>
176 val (wp, pv) = x.getOrElse((0, 0));
177 (oid, mid) -> (bid, wp, pv)
178 }
179 val rdd_join4 = rdd_join3.fullOuterJoin(result_clk_count);
180 // (oid,mid),((bid,wp,pv),clk)
181 val rdd_join5 = rdd_join4.map { case ((oid, mid), (x, y)) =>
182 val (bid, wp, pv) = x.getOrElse((0, 0, 0));
183 (oid, mid, bid, wp, pv, y.getOrElse(0))
184 }
185 //"{"+oid+","+mid+","+bid+","+pv+","+clk+","+wp+"}" oid,mid,bid,wp,pv,clk .sortBy(f => (f._4), false).
186 val rdd_join6 = rdd_join5.map({ case (oid, mid, bid, wp, pv, clk) => (oid, mid, bid, pv, clk, wp) }); // oid,mid,bid,pv,clk,wp
187 // println("!!! ### after join = " + rdd_join6.count() + " , detail info: ");
188
189 println(" ********* statistic finished ********* "+df.format(now)+" ********* rdd_join6 = "+rdd_join6.count())
190
191 // 存入redis
192 rdd_join6.foreachPartition(partitionOfRecords => {
193 partitionOfRecords.foreach(pair => { // oid,mid,bid,pv,clk,wp
194 val conn: Jedis = JedisConnectionPools.getConnection()// 获取jedis连接
195 val oid = pair._1 // oid, mid, bid, pv, clk, wp
196 val bid = pair._3
197 val pv = pair._4
198 val clk = pair._5
199 val cost = pair._6
200 val HashKey = date_str+"::oid::"+oid
201 conn.hincrBy(HashKey, "cost", cost.toInt)
202 conn.hincrBy(HashKey, "pv", pv.toInt)
203 conn.hincrBy(HashKey, "bid", bid.toInt)
204 conn.hincrBy(HashKey, "clk", clk.toInt)
205 conn.close()
206 })
207 })
208
209 // println("### save to redis over ! time = "+df.format(now))
210 // 确保结果都已经正确且幂等地输出了
211 // stream.asInstanceOf[CanCommitOffsets].commitAsync(offsetRanges)
212 // println("### 更新offset ! time = "+df.format(now))
213
214 rdd.unpersist()
215 println(" ********* save to redis finished ***** "+df.format(now))
216
217 }
218 }
219 ssc.start()
220 ssc.awaitTermination()
221 }
222
223}
224
225
redis实现:
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
2
3object JedisConnectionPools {
4 val redisHost = "your redis host"
5 val redisPort = 6379
6 val redisTimeout = 30000
7
8 val conf = new JedisPoolConfig()
9
10 //最大连接数
11 conf.setMaxTotal(20)
12
13 //最大空闲连接数
14 conf.setMaxIdle(10)
15
16 //调用borrow Object方法时,是否进行有效检查
17 //conf.setTestOnBorrow(true)
18
19 //ip地址, redis的端口号,连接超时时间
20 val pool = new JedisPool(conf,"your redis host",6379,10000,"password")
21
22 def getConnection():Jedis={
23 pool.getResource
24 }
25
26 def main(args: Array[String]): Unit = {
27 val conn = JedisConnectionPools.getConnection()
28 val r1 = conn.keys("oid::mid::*")
29 println(r1)
30 conn.close()
31 }
32
33}
34
intellij IDEA打jar包后,运行于cdh-master机器上,启动命令:
nohup spark-submit –master yarn –queue root.dev –deploy-mode client –jars /home/libs/jedis-2.9.0.jar,/home/libs/commons-pool2-2.0.jar –class com.XXX.KafkaBidStatistic /home/streaming/dspstreaming.jar > /home/logs/test.log 2>&1 &
说明:
-
第一次使用streaming开发,网上查找了很多资料,都说要自己使用代码提交offset,但是,我没有手动提交,因为业务需求方面对数据的丢失不是很严格。手动提交需要每次记录offset并存放到如redis,然后,每次读取offset时候手动更新。
-
采用Direct方式的streaming,如果程序坏了,重启会丢失之前程序坏了的时候的数据,需要使用checkpoint机制,但是本文暂时还没有实现。
基于direct的方式,使用kafka的简单api,Spark Streaming自己就负责追踪消费的offset,并保存在checkpoint中。Spark自己一定是同步的,因此可以保证数据是消费一次且仅消费一次。
- 运行streaming程序后,可以在cdh界面上查看streaming运行情况,地址如下所示:
http://cdh-slaver4.lavapm:8088/proxy/application_1562297838757_0853/streaming/
**scheduling delay:**用来统计在等待被处理所消费的时间;
如果scheduling delay值在程序运行一段时间后,一直在递增,这就表明此系统不能对产生的数据实时响应,就是出现了
处理时延,每个batch time 内的处理速度小于数据的产生速度。在这种情况下,需要想法减少数据的处理速度,即需要提升处理效率。可以增加kafka的topic的partition数量,因为其与streaming中的rdd的partition是一一对应的,就会并行读取数据,提高处理速度。
