1.概述
在编写 Flink,Spark,Hive 等相关作业时,要是能快速的将我们所编写的作业能可视化在我们面前,是件让人兴奋的时,如果能带上趋势功能就更好了。今天,给大家介绍这么一款工具。它就能满足上述要求,在使用了一段时间之后,这里给大家分享以下使用心得。
2.How to do
首先,我们来了解一下这款工具的背景及用途。Zeppelin 目前已托管于 Apache 基金会,但并未列为顶级项目,可以在其公布的 官网访问。它提供了一个非常友好的 WebUI 界面,操作相关指令。它可以用于做数据分析和可视化。其后面可以接入不同的数据处理引擎。包括 Flink,Spark,Hive 等。支持原生的 Scala,Shell,Markdown 等。
2.1 Install
对于 Zeppelin 而言,并不依赖 Hadoop 集群环境,我们可以部署到单独的节点上进行使用。首先我们使用以下地址获取安装包:
2
2
这里,有2种选择,其一,可以下载原文件,自行编译安装。其二,直接下载二进制文件进行安装。这里,为了方便,笔者直接使用二进制文件进行安装使用。这里有些参数需要进行配置,为了保证系统正常启动,确保的 zeppelin.server.port 属性的端口不被占用,默认是8080,其他属性大家可按需配置即可。[配置链接]
2.2 Start/Stop
在完成上述步骤后,启动对应的进程。定位到 Zeppelin 安装目录的bin文件夹下,使用以下命令启动进程:
2
2
若需要停止,可以使用以下命令停止进程:
2
2
另外,通过阅读 zeppelin-daemon.sh 脚本的内容,可以发现,我们还可以使用相关重启,查看状态等命令。内容如下:
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
2 start)
3 start
4 ;;
5 stop)
6 stop
7 ;;
8 reload)
9 stop
10 start
11 ;;
12 restart)
13 stop
14 start
15 ;;
16 status)
17 find_zeppelin_process
18 ;;
19 *)
20 echo ${USAGE}
21
3.How to use
在启动相关进程后,可以使用以下地址在浏览器中访问:
2
2
启动之后的界面如下所示:
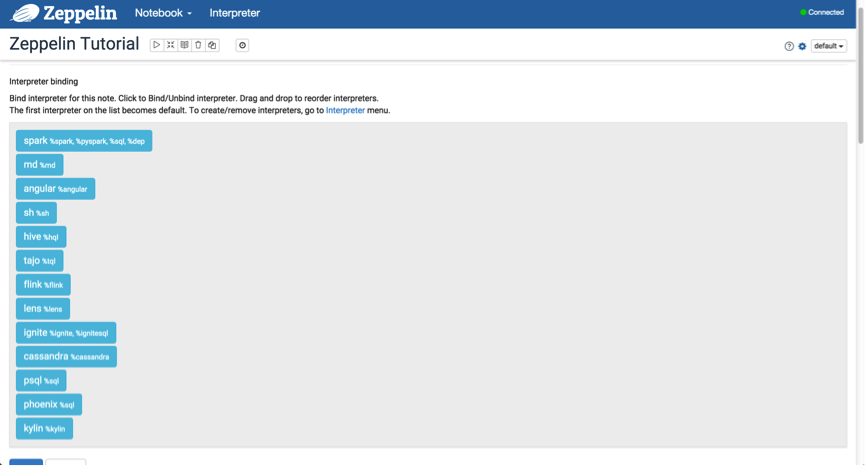
该界面罗列出插件绑定项。如图中的 spark,md,sh 等。那我如何使用这些来完成一些工作。在使用一些数据引擎时,如 Flink,Spark,Hive 等,是需要配置对应的连接信息的。在 Interpreter 栏处进行配置。这里给大家列举一些配置示例:
3.1 Flink
可以找到 Flink 的配置项,如下图所示:

然后指定对应的 IP 和地址即可。
3.2 Hive
这里 Hive 配置需要指向其 Thrift 服务地址,如下图所示:

另外,其他的插件,如 Spark,Kylin,phoenix等配置类似,配置完成后,记得点击 “restart” 按钮。
3.3 Use md and sh
下面,我们可以创建一个 Notebook 来使用,我们拿最简单的 Shell 和 Markdown 来演示,如下图所示:
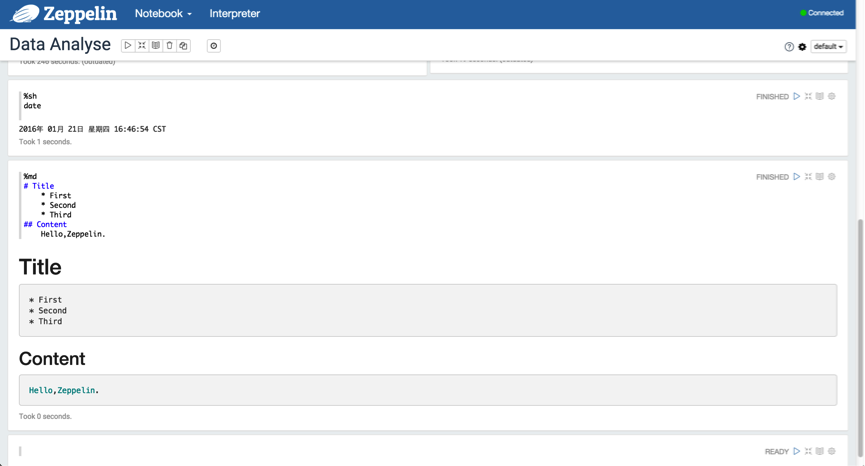
3.4 SQL
当然,我们的目的并不是仅仅使用 Shell 和 Markdown,我们需要能够使用 SQL 来获取我们想要的结果。
3.4.1 Spark SQL
下面,我们使用 Spark SQL 去获取想要的结果。如下图所示:
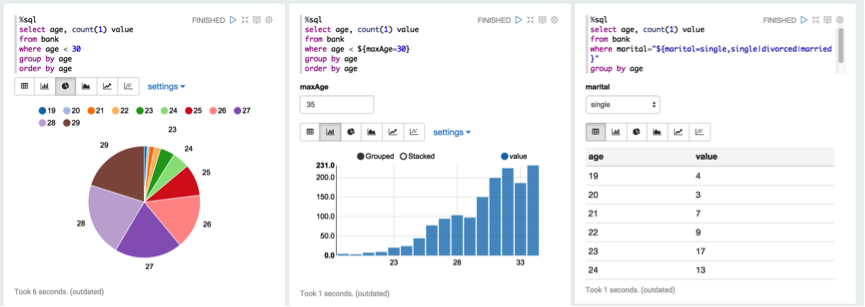
这里,可以将结果以不同的形式来可视化,量化,趋势,一目了然。
3.4.2 Hive SQL
另外,可以使用动态格式来查询分区数据,以"${partition_col=20160101,20160102|20160103|20160104|20160105|20160106}"的格式进行表示。如下图所示:
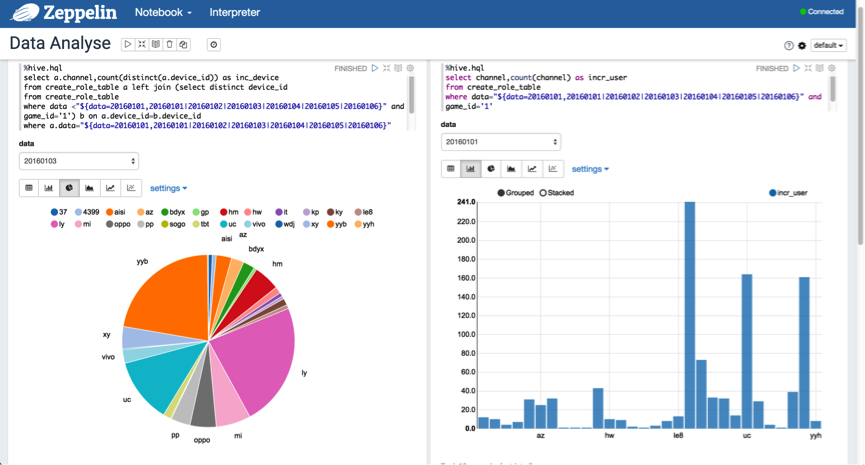
3.5 Video Guide
另外,官方也给出了一个快速指导的入门视频,观看地址:[入口]
4.总结
在使用的过程当中,有些地方需要注意,必须在编写 Hive SQL 时,%hql 需要替换为 %hive.sql 的格式;另外,在运行 Scala 代码时,如果出现以下异常,如下图所示:

解决方案,在 zeppelin-env.sh 文件中添加以下内容:
2
2
该 BUG 在 0.5.6 版本得到修复,参考码:[ZEPPELIN-305]
5.结束语
这篇博客就和大家分享到这里,如果大家在研究学习的过程当中有什么问题,可以加群进行讨论或发送邮件给我,我会尽我所能为您解答,与君共勉!
