写到这里,我记得我前面提出的两个需求,参数化构建和报告和日志显示就差一个日志文件显示了。本篇就先来介绍如何在jenkins上提供日志文件下载,第二个介绍一下rebuild插件。如果一个jenkins job有十个以上的参数化构建,那么下一次构建,选择rebuild菜单是最方便,rebuild菜单会记住上一次构建的输入值,支持修改后再提交构建。
1.日志文件归档
早期jenkins中,文件归档使用的命令是archive,然后这个方法就弃用了,改成了archiveArtifacts,这里我两个方法都测试了下。这里我先贴出关键代码,完整代码我后面给出,大部分代码都是和前面一篇相同。
2
3
4
5
6
7
8
9
10
11
12
13
14
2 always{
3 script{
4 node(win_node){
5 //delete report file
6 println "Start to delete old html report file."
7 bat("del /s /q C:\\JenkinsNode\\workspace\\selenium-pipeline-demo\\test-output\\*.html")
8 //list the log files on jenkins ui
9 archive 'log/*.log'
10 }
11 }
12 }
13 }
14
看最后一行代码,archive是方法名称,后面表示在根目录下的log文件夹下所有以.log结尾的文件进行归档操作,在jenkns当前构建页面可以看到这些归档文件。
我测试了下,发现有下面这个提示错误,构建失败。
2
3
2
3
然后,只能尝试archiveArtifacts了。
2
3
4
5
6
7
8
9
10
11
12
13
14
15
2 always{
3 script{
4 node(win_node){
5 //delete report file
6 println "Start to delete old html report file."
7 bat("del /s /q C:\\JenkinsNode\\workspace\\selenium-pipeline-demo\\test-output\\*.html")
8 //list the log files on jenkins ui
9 //archive 'log/*.log'
10 archiveArtifacts artifacts: 'log/*.log'
11 }
12 }
13 }
14 }
15
测试效果如下。
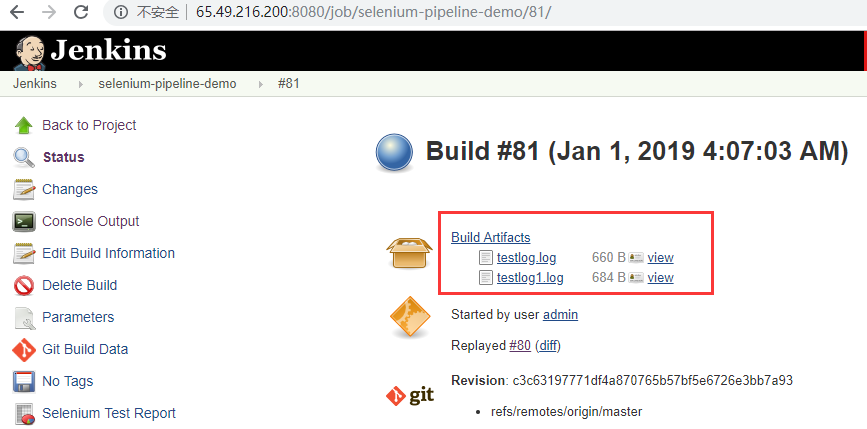
如果你想看日志内容,直接点击红框内的文件就可以。当然,我们框架内log文件夹下有三个日志文件,这里还缺一个html文件。
你可以归档的时候写成以下这样。
2
3
4
5
6
7
8
9
10
11
12
13
14
2 always{
3 script{
4 node(win_node){
5 //delete report file
6 println "Start to delete old html report file."
7 bat("del /s /q C:\\JenkinsNode\\workspace\\selenium-pipeline-demo\\test-output\\*.html")
8 //list the log files on jenkins ui
9 archiveArtifacts artifacts: 'log/*.*'
10 }
11 }
12 }
13 }
14
我们知道,按照上面这么写,就是把log文件夹下所有文件都归档,效果如下
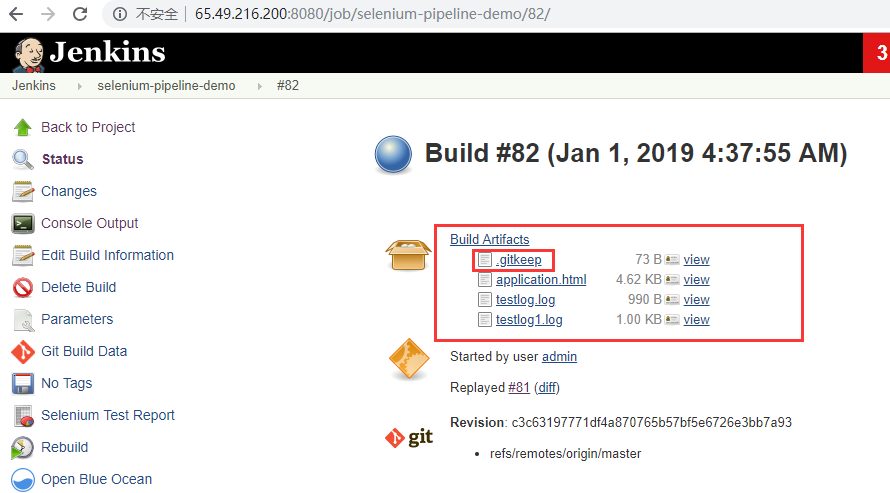
这里三个文件都出来,但是不要担心.gitkeep这个文件,这个我原来代码仓库中,需要保留一个空的log文件夹,在git中为了能push一个空的文件夹,需要在这个文件夹下写一个.gitkeep文件,并且在这个文件写几行内容,内容如下。
2
3
4
2*
3# Except this file !.gitkeep
4
同理,在我github这个代码仓库中,有log,screenshots,test-output三个文件夹都使用了这个文件。以上两种方法,一个是精确到log文件类型,一个是模糊的一个文件夹下所有文件都归档。结合你自己项目实际情况,自己选择取舍。
2.这里介绍一个rebuild插件
在pipeline的开发和测试过程中,有一个rebuild插件,这里介绍下。rebuild安装完会变成一个菜单,点击之后,会自动记录前面的构建时填写的参数。这样其实是很方便,特别是一个项目有十多个参数是需要每次构建都选择或者填写的,而且默认值不一定是你要的,这样如果没有rebuild功能,你每次点击参数化构建,都需要填写多次参数变量的值,这样就很麻烦。
所以,你得去安装一个rebuild的插件,插件名称就叫rebuild,搜索并安装,很简单,下面是一个效果图。
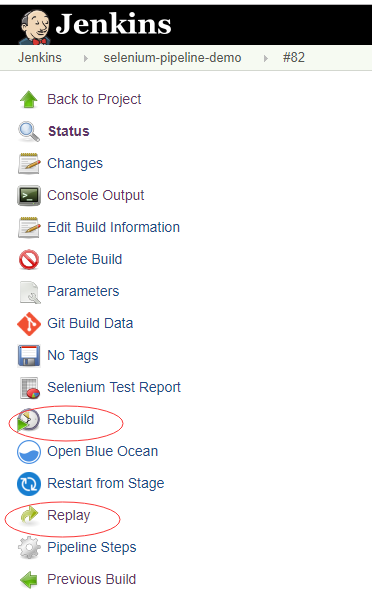
这里注意下rebuild和replay的区别,在实际工作中,两者往往是经常使用,前一个构建使用了replay是为了debug,改代码,下一个构建为了再次验证,点击rebuild就可以。
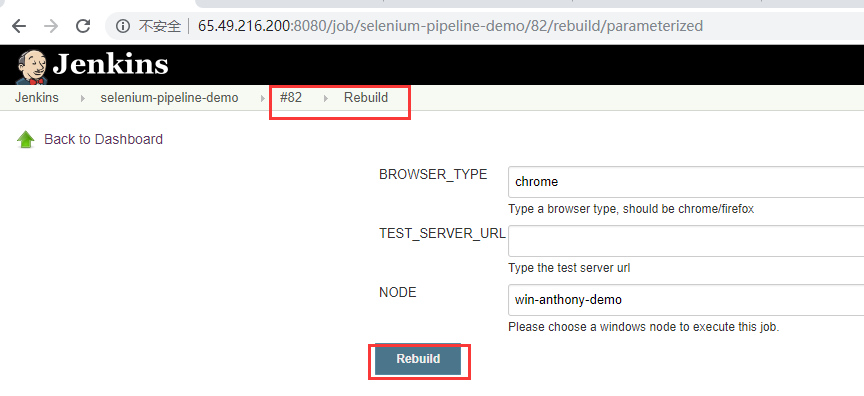
上面的图表示,下一次构建,也就是第83次构建是在82的记录下触发的,这个时候按钮是Rebuild,而不是参数化构建页面的build的按钮。
3.添加事后删除日志功能
和前面报告一样,每次构建,都会产生日志文件和报告文件,那么我们这里也添加事后清空日志文件夹的功能。当然,也会把.gitkeep文件一块删除,但是由于删除的是本地拉取完之后的文件,不会影响到github上的文件,所以这个就不要担心。
这里,我把两个groovy文件的代码都贴出来。
文件:selenium-jenkins.groovy
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
2
3pipeline{
4
5 agent any
6 parameters {
7 string(name: 'BROWSER_TYPE', defaultValue: 'chrome', description: 'Type a browser type, should be chrome/firefox')
8 string(name: 'TEST_SERVER_URL', defaultValue: '', description: 'Type the test server url')
9 string(name: 'NODE', defaultValue: 'win-anthony-demo', description: 'Please choose a windows node to execute this job.')
10 }
11
12 stages{
13 stage("Initialization"){
14 steps{
15 script{
16 browser_type = BROWSER_TYPE?.trim()
17 test_url = TEST_SERVER_URL?.trim()
18 win_node = NODE?.trim()
19 }
20 }
21 }
22
23 stage("Git Checkout"){
24 steps{
25 script{
26 node(win_node) {
27 checkout([$class: 'GitSCM', branches: [[name: '*/master']],
28 userRemoteConfigs: [[credentialsId: '6f4fa66c-eb02-46dc-a4b3-3a232be5ef6e',
29 url: 'https://github.com/QAAutomationLearn/JavaAutomationFramework.git']]])
30 }
31 }
32 }
33 }
34
35 stage("Set key value"){
36 steps{
37 script{
38 node(win_node){
39 selenium_test = load env.WORKSPACE + "\\pipeline\\selenium.groovy"
40 config_file = env.WORKSPACE + "\\Configs\\config.properties"
41 try{
42 selenium_test.setKeyValue("browser", browser_type, config_file)
43 file_content = readFile config_file
44 println file_content
45 }catch (Exception e) {
46 error("Error met:" + e)
47 }
48 }
49 }
50 }
51 }
52
53 stage("Run Selenium Test"){
54 steps{
55 script{
56 node(win_node){
57 run_bat = env.WORKSPACE + "\\run.bat"
58 bat (run_bat)
59 }
60 }
61 }
62 }
63 stage("Publish Selenium HTML Report"){
64 steps{
65 script{
66 node(win_node){
67 html_file_name = selenium_test.get_html_report_filename("test-output")
68 publishHTML (target: [
69 allowMissing: false,
70 alwaysLinkToLastBuild: false,
71 keepAll: true,
72 reportDir: 'test-output',
73 reportFiles: html_file_name,
74 reportName: "Selenium Test Report"
75 ])
76 }
77 }
78 }
79 }
80 }
81
82 post{
83 always{
84 script{
85 node(win_node){
86 //delete report file
87 println "Start to delete old html report file."
88 bat("del /s /q C:\\JenkinsNode\\workspace\\selenium-pipeline-demo\\test-output\\*.html")
89 //archive the log files on jenkins ui
90 archive 'log/*.*'
91 println "Start to delete old log files."
92 bat("del /s /q C:\\JenkinsNode\\workspace\\selenium-pipeline-demo\\log\\*.*")
93 }
94 }
95 }
96 }
97
98}
99
100
文件:selenium.groovy
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
2import java.io.FileInputStream;
3import java.io.FileNotFoundException;
4import java.io.FileOutputStream;
5import java.io.IOException;
6import java.util.Properties;
7
8def setKeyValue(key, value, file_path) {
9 // read file, get string object
10 file_content_old = readFile file_path
11 println file_content_old
12 lines = file_content_old.tokenize("\n")
13 new_lines = []
14 lines.each { line ->
15 if(line.trim().startsWith(key)) {
16 line = key + "=" + value
17 new_lines.add(line)
18 }else {
19 new_lines.add(line)
20 }
21 }
22 // write into file
23 file_content_new = ""
24 new_lines.each{line ->
25 file_content_new += line + "\n"
26 }
27
28 writeFile file: file_path, text: file_content_new, encoding: "UTF-8"
29}
30
31def get_html_report_filename(report_store_path) {
32 get_html_file_command = "cd ${report_store_path}&dir /b /s *.html"
33 out = bat(script:get_html_file_command,returnStdout: true).trim()
34 out = out.tokenize("\n")[1] // get the second line string
35 println out
36 html_report_filename = out.split("test-output")[1].replace("\\", "")
37 println html_report_filename
38 return html_report_filename
39}
40
41return this;
42
完整代码在github上
https://github.com/QAAutomationLearn/JavaAutomationFramework.git
总结:
到了这里,我算把jenkins+pipeline+selenium持续集成的方案全部介绍完了,希望对于那些想学习pipeline的朋友有一些帮助。我不得不吐槽下,我的Jenkins环境太慢了,由于jenkins master机器在美国洛杉矶,我本地个人笔记本电脑作为一台windows slave机器连接,每次跑Jenkins job,拉取代码到windows上都很慢,而且连接很不稳定,写这个系列文章花了很多测试时间,总之,比我预想的要慢很多。从我现在的pipeline使用经验和技术水平来讲,我觉得我完成了pipeline从入门到实战运用,这篇系列教程,我个人感觉写得还不错,至少比java+selenium系列和python+selenium系列要写得好,只是,在国内,不管开发还是测试还是运维,使用pipeline的人还是很少数,希望这个队伍会越来越壮大。将来的软件都会在云端,所以云端软件的自动化和基础设施的自动化测试会越来越多,工作机会相信也会一样越多。学会pipeline去用代码的方式完成不同项目的CI和CD的开发测试工作,这个要求会在招聘需求里越来越突出。
