安装Scrapy
在安装Scrapy之前,需要先安装Twisted。Twisted可以使用pip安装,如果直接安装Scrapy,在安装过程中就会出现报错信息。
Windows下安装Scrapy:有很多种方法,本人直接使用pip安装。(这篇博客不想在安装上多费篇幅,网上都能查的到。)
cmd命令行:
2
2
创建Scrapy项目
在cmd上将路径切换到工作目录(也就是你想将工程放在的目录):
2
2
项目创建完毕。
Scrapy项目文件说明
创建项目后,在项目文件夹中看到目录结构如下(本人是使用IDE查看目录结构的,我的项目名称是nbaspider):
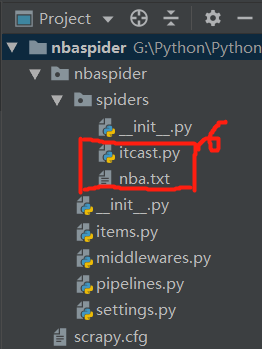
其中spiders文件夹下的itcast.py和nba.txt文件一开始是没有的,后面再娓娓道来。
- 第一层文件夹就是项目名nbaspider,没啥好说的。
- 第二层中是一个与项目名同名的文件夹nbaspider(模块/包,所有项目代码都在这个模块里添加)和一个文件scrapy.cfg(顾名思义是整个Scrapy项目的配置文件)。
我们可以看看这个scrapy.cfg文件里面有什么:
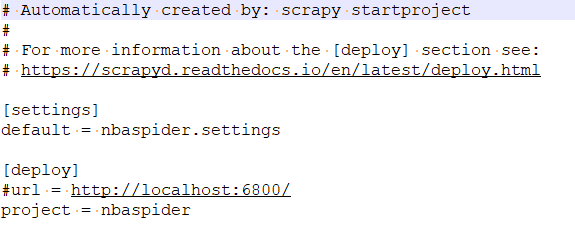
整个文件只声明了两件事:一是定义默认设置文件的位置为nbaspider模块下的settings文件,二是定义项目名称为nbaspider。
- 第三层中有如下文件:
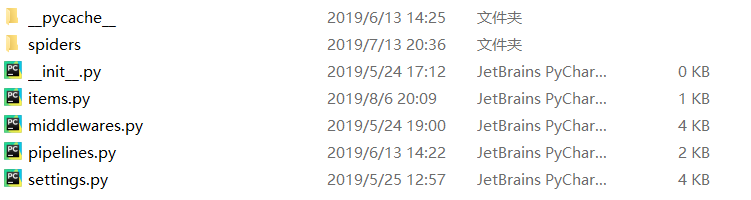
spiders文件夹其实也是一个模块。
第三层的文件看起来很多,其实有用的也就三个文件:
items.py:定义存储数据对象,主要衔接spiders(文件夹)和pipelines.py。
pipelines.py:数据存储,数据格式以字典形式表现,字典的键是items.py定义的变量。
settings.py:是上层目录中scrapy.cfg定义的设置文件,主要配置爬虫信息,如请求头、中间件和延时设置等。
_pycache_文件夹中的.pyc文件都是同名Python程序编译得到的字节码文件,settings.pyc是settings.py的字节码文件,据说可以加快程序的运行速度,从“cache”(高速缓存)一词就可窥探其作用。
middlewares.py文件是介于Scrapy的request/response处理的钩子框架,用于全局修改Scrapy request和response的一个轻量、底层的系统。
至于_init_.py文件,它是个空文件,在此处的唯一作用就是将它的上级目录变成了一个模块,也就是说第二层的nbaspider文件夹没有_init_.py文件,就只是一个单纯的文件夹,在任何一个目录下添加一个空的_init_.py文件,就会将该文件夹编程模块化,可以供Python导入使用。
Scrapy爬虫编写
在编写爬虫之前我们还需创建一个基础爬虫文件,也就是上文提到的itcast.py(当然文件名是自定义的),进入nbaspider模块,在cmd中输入:
2
2
就会在spiders文件夹下创建该文件,spiders文件夹用于编写爬虫规则,可以在已有的_init_.py文件中编写具体的爬虫规则,但实际开发中可能含有多个爬虫规则,所以建议一个爬虫规则用一个文件表示,这样便于维护和管理。
这样就可以开始在Scrapy框架下的几个文件里开始“填空”编写爬虫了:
- settings.py:其中有大量注释内容(配置代码、配置说明、相应的官方文档链接),根据需要去掉注释。
- items.py:Scrapy已生成相关的代码及文档说明,开发者只需在此基础上定义类属性即可。
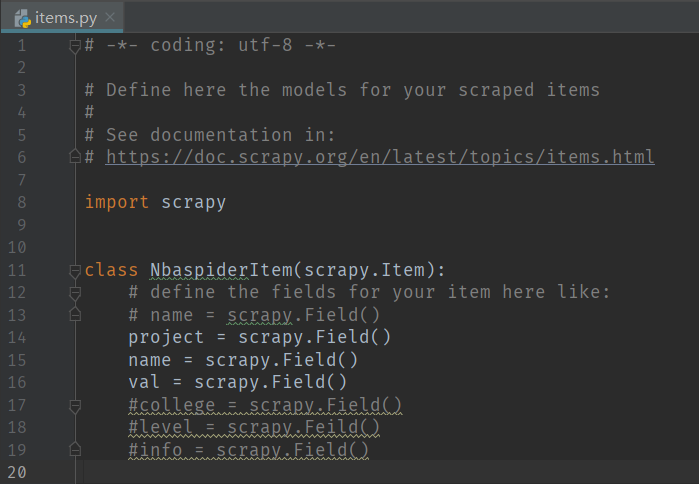
就我的项目来说,我需要爬取三项,所以定义三个类属性,scrapy.Field()是Scrapy的特有对象,其主要作用是处理并兼容不同的数据格式,开发者在定义类属性时无需考虑爬取数据的格式,Scrapy会对数据格式做相应处理。
- itcast.py:用于编写爬虫规则。
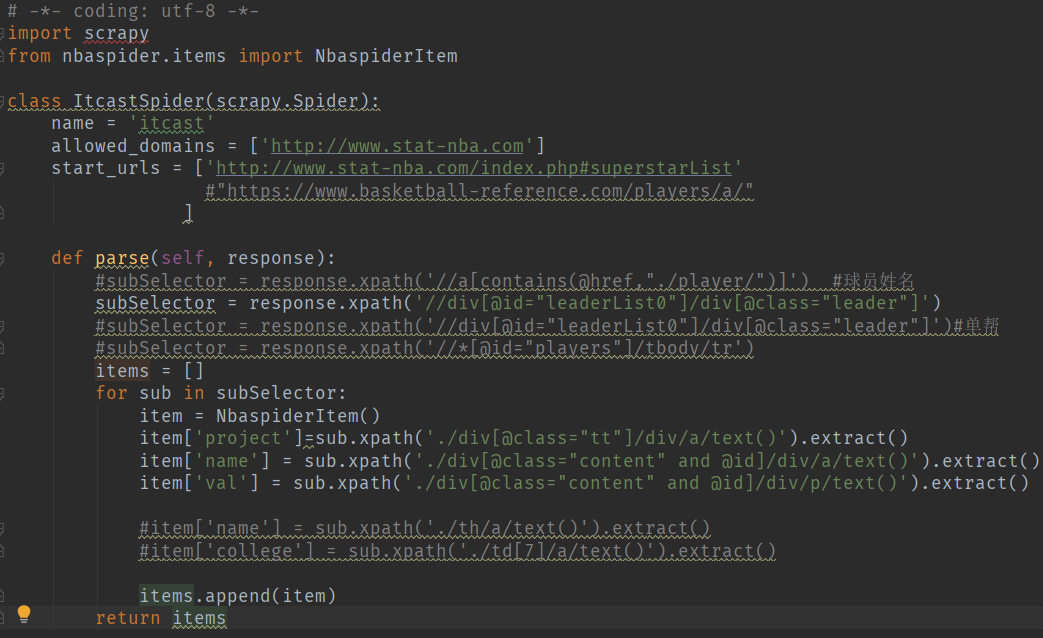
在该文件中,首先导入了scrapy模块,然后从模块nbaspider中的items文件中导入了NbaspiderItem类,也就是上述定义需要爬取内容的类。
name定义的是爬虫名。allowed_domains定义的是域范围,也就是爬虫只能在这个域内爬取。start_urls定义的是爬取的网页,最好使用列表类型,以便随时在后面添加要爬取的网页。
parse函数的参数response就是请求网页后返回的数据。然后利用选择器提取所需内容,选择器在下面讲解。items定义一个空列表用于返回多个item的列表。subSelector在上面用xpath选取了符合要求的内容组成列表,然后用for循环遍历这个列表,循环里,定义一个item初始化为一个NbaspiderItem类,然后下面就是用xpath选取内容给这个类的各个属性赋值。
其中有个比较迷惑新手的问题,即scrapy中xpath使用extract()的时候[0]位置问题,参考:
https://blog.csdn.net/LOG_IN_ME/article/details/99676481
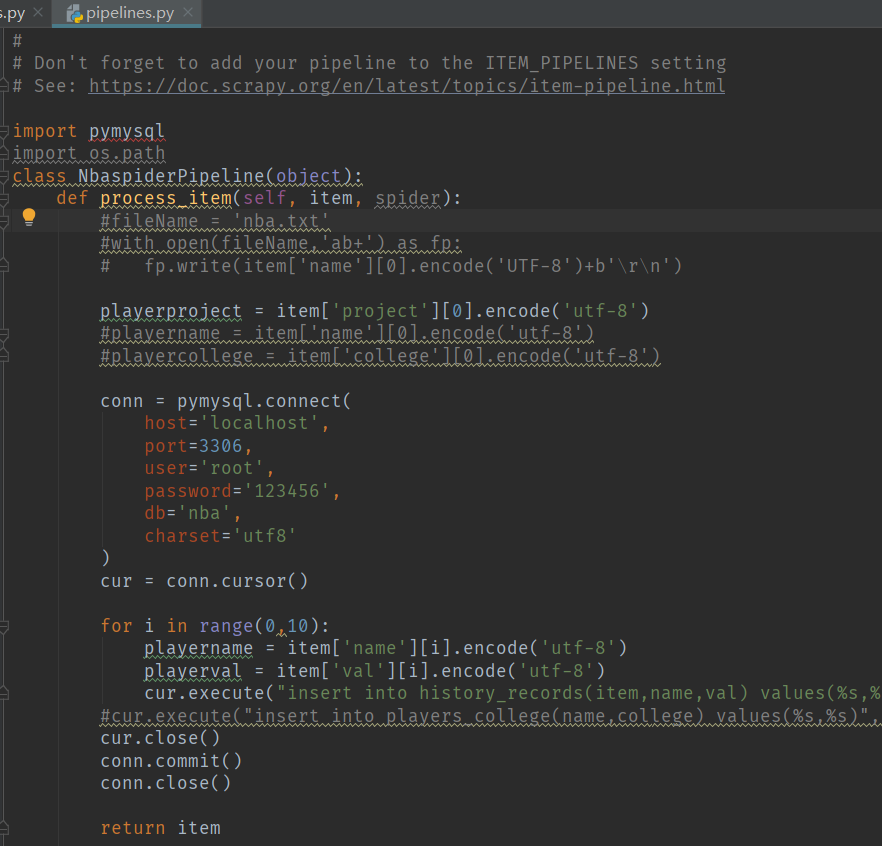
- pipelines.py:Scrapy已自动生成类NbaspiderPipeline,类NbaspiderPipeline就是setting.py配置ITEM_PIPLINES的内容。数据存储主要在类方法process_item()中执行。
数据存储到txt:
例pipeines.py:
2
3
4
5
6
7
8
9
2
3class WeatherPipeline(object):
4 def process_item(self, item, spider):
5
6 with codecs.open('1.txt','a','utf-8') as fp:
7 fp.write("%s \t %s \t\n" %(item['cityDate'],item['week']))
8 return item
9
数据存储到JSON:
例pipeline2json.py:
2
3
4
5
6
7
8
9
10
11
2import json
3
4class WeatherPipeline(object):
5 def process_item(self, item, spider):
6
7 with codecs.open('1.json','a','utf-8') as fp:
8 jsonStr=json.dumps(dict(item))
9 fp.write("%s \r\n" %jsonStr)
10 return item
11
数据存储到MySQL:
Windows中安装PyMySQL3模块:
2
2
例pipelines2mysql.py:
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
2
3class WeatherPipeline(object):
4 def process_item(self, item, spider):
5
6 #爬取的项
7 cityDate=item['cityDate']
8 week=item['week']
9
10 conn=pymysql.connect(
11 host='localhost',
12 port=3306,
13 user='root',
14 passwd='123456',
15 db='数据库名'
16 charset='utf-8')
17 cur=conn.cursor()
18
19 #SQL语句
20 mysqlCmd="INSERT INTO weather(cityDate, week) VALUES('%s', '%s');" %(cityDate, week)
21
22 cur.execute(mysqlCmd)
23 cur.close()
24 conn.commit()
25 conn.close()
26
27 return item
28
最后,在settings.py中将pipelines储存数据的文件加入到数据处理列中去:
2
3
4
5
6
7
2 #weather是工程名
3 'weather.pipelines.WeatherPiplines':300,#数随意,越小越先处理
4 'weather.pipelines2json.WeatherPiplines':301,
5 'weather.pipelines2mysql.WeatherPiplines':302
6}
7
运行爬虫
回到scrapy.cfg文件的统计目录下(实际上只要是在nbaspider项目下的任意目录中执行都行),执行cmd:
2
2
Scrapy选择器XPath和CSS
Scrapy提取数据有自己的一套机制,他们被称作选择器(selectors),通过特定的XPath或者CSS表达式来选择HTML文件中的某个部分。XPath是一门用来在XML文件中选择节点的语言,也可以用在HTML上。CSS是一门将HTML文档样式化的语言,选择器由它定义,并与特定的HTML元素的样式相关联。
XPath和CSS选择器都可以嵌套使用,可以互相嵌套。
XPath选择器:
nodename
选取此节点的所有子节点。
/
从根节点选取。
//
从匹配选择的当前节点选择文档中的节点,而不考虑它们的位置。
.
选取当前节点。
..
选取当前节点的父节点。
@
选取属性。
匹配任何元素节点。
@*
匹配任何属性节点。
node()
匹配任何类型的节点。
/bookstore/book[1]
选取属于 bookstore 子元素的第一个 book 元素。
/bookstore/book[last()]
选取属于 bookstore 子元素的最后一个 book 元素。
/bookstore/book[last()-1]
选取属于 bookstore 子元素的倒数第二个 book 元素。
/bookstore/book[position()<3]
选取最前面的两个属于 bookstore 元素的子元素的 book 元素。
//title[@lang]
选取所有拥有名为 lang 的属性的 title 元素。
//title[@lang='eng']
选取所有 title 元素,且这些元素拥有值为 eng 的 lang 属性。
/bookstore/book[price>35.00]
选取 bookstore 元素的所有 book 元素,且其中的 price 元素的值须大于 35.00。
/bookstore/book[price>35.00]/title
选取 bookstore 元素中的 book 元素的所有 title 元素,且其中的 price 元素的值须大于 35.00。
//book/title | //book/price
选取 book 元素的所有 title 和 price 元素。
//title | //price
选取文档中的所有 title 和 price 元素。
/bookstore/book/title | //price
选取属于 bookstore 元素的 book 元素的所有 title 元素,以及文档中所有的 price 元素。
CSS选择器:
.class
.intro
选择class="intro"的所有元素
#id
#firstname
选择id="firstname"的所有元素
*
*
选择所有元素
element
p
选择所有<p>元素
element,element
div,p
选择所有<div>元素和所有<p>元素
element element
div p
选择<div>元素内部的所有p元素
[attribute]
[target]
选择带有target属性的所有元素
[attribute=value]
[target=_blank]
选择target="_blank"的所有元素
附:
使用scrapy shell命令查看链接网站返回的结果和数据,cmd进入工程的任意目录下:
2
2
可以查看response的返回状态码等等。
查看response的数据内容,cmd:
2
2
