(1)HTTP请求过程
我们在浏览器中输入一个URL,回车之后便会在浏览器中观察到页面内容。实际上,这个过程是浏览器向网站所在的服务器发送了一个请求,网站服务器接收到这个请求后进行处理和解析,然后返回对应的响应,接着传回给浏览器。响应里包含了页面的源代码等内容,浏览器再对其进行解析,便将网页呈现了出来。
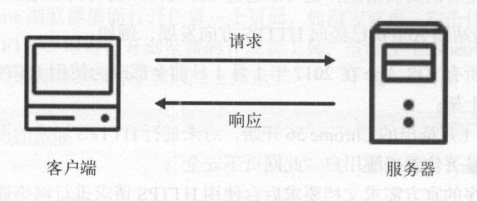
此处客户端即代表我们自己的PC或手机浏览器,服务器即要访问的网站所在的服务器。
chrome浏览器,右击并选择“检查”项,即可打开浏览器的开发者工具。其中各列含义如下:
- 第一列 Name:请求的名称,一般会将URL的最后一部分内容当作名称。
- 第二列 Status:相应的状态码,通过状态码可以判断发送了请求之后是否得到了正常的响应。
- 第三列 Type:请求的文件类型。
- 第四列 Initiator:请求源,用来标记请求是由哪个对象或进程发起的。
- 第五列 Size:从服务器下载的文件和请求的资源大小。如果是从缓存中取得的资源,则该列会显示from cache。
- 第六列 Time:发起请求到获取响应所用的总时间。
- 第七列 Waterfall:网络请求的可视化瀑布流。
(2)请求
请求,由客户端向服务器端发出,可以分为4部分内容:请求方法(Request Method)、请求的网址(request URL)、请求头(Request Headers)、请求体(Request Body)
1、请求方法:常见的请求方法两种:GET和POST,其区别如下
-
GET请求中的参数包含在URL里面,数据可以在URL中看到,而POST请求的URL不会包含这些数据,数据都是通过表单的形式传输的,会包含在请求体中。
-
GET请求提交的数据最多只有1024字节,而POST方式没有限制。
我们平常遇到的绝大部分请求都是GET和POST请求,另外还有一些请求方法,如HEAD、PUT、DELETE、OPTIONS、CONNECT、TRACE等。
2、请求地址:即统一资源定位符URL,它可以唯一确定我们想请求的资源。
3、请求头:用来说明服务器要使用的附加信息,比较重要的信息有cookies,referer,user_agent等。
-
Accept:请求报头域,用于指定客户端可以接受哪些类型的信息。
-
Accept-Language:指定客户端可以接受的语言类型。
-
Accept-Encoding:指定客户端可以接受的内容编码。
-
Host:用于指定请求资源的主机IP和端口号,其内容为请求URL的原始服务器或网关的位置。从HTTP1.1开始,请求必须包含此内容。
-
Cookie:常用复数形式Cookies,这是网站为了辨别用户进行会话跟踪而存储在用户本地的数据。他的主要功能是维持当前访问会话。
-
Referer:此内容用来表示这个请求是从哪个页面发送过来的,服务器可以拿到这一信息并作相应的处理,比如做来源统计、防盗链处理等。
-
User-Agent:简称UA,它是一个特殊的字符串头,可以使服务器识别客户使用的操作系统及版本,浏览器及版本等信息。在做爬虫时附加此信息,可以伪装浏览器。
-
Content-Type:也叫互联网媒体类型或者MIME类型,在HTTP协议消息头中,它用来表示具体请求中的媒体类型信息。
4、请求体:请求体一般承载的内容时POST请求中的表单数据,而对于GET请求,请求体则为空。
(3)响应
响应由服务器返回给客户端,可以分为三部分:响应状态码(Response Status Code)、响应头(Response Headers)、响应体(Response Body)。
1、响应状态码:表示服务器的响应状态,如200,404,500等。爬虫中根据响应状态码判断服务器的响应状态。
https://blog.csdn.net/ddhsea/article/details/79405996
2、响应头:包含了服务器对请求的应答信息,常用头信息如下
-
Date:标识响应产生的时间
-
Last-Modified:指定资源的最后修改时间
-
Content-Encoding:指定响应内容的编码
-
Server:包含服务器的信息,比如名称,版本号等
-
Content-Type:文档类型,指定返回的数据类型是什么,比如text/html代表返回HTML文档application/x-javascript则代表返回JavaScript文件,image/jpeg则代表返回图片。
-
Set-Cookie:设置Cookies。响应头中的Set-Cookies告诉浏览器需要将此内容放在Cookies中,下次请求携带Cookies请求。
-
Expires:指定相应的过期时间,可以使用代理服务器或浏览器将加载内容更新的缓存中。
3、响应体:
最重要的当属响应体的内容了。响应的正文数据都在响应体中,比如请求网页时,它的响应体就是网页的HTML代码;请求一张图片时,它的响应体就是图片的二进制数据。我们做爬虫请求网页后,要解析的内容就是响应体。在浏览器的开发者工具中点击Preview,就可以看到页面的源码,也就是响应体的内容,他就是解析的目标。在做爬虫时,我们主要通过响应体得到网页的源代码、JSON数据等,然后从中做相应内容的提取。
