1. hive group by distinct区别以及性能比较
https://blog.csdn.net/xiaoshunzi111/article/details/68484426
-
用insert into替换union all
-
order by & sort by
执行计划是什么
执行计划代表
HiveSQL
会转化成怎么样的
MapReduce
作业。也是优化
HiveSQL
根本
依据。
HiveSQL
的优化本质是对
MapReduce
作业的
优化。不管使用的引擎是mr
、
tez
还是
spark
都是一样的。
执行计划初步解析
抽象
语法树
AST
(
A
bstract
S
yntax
T
ree
)
是源代码的抽象语法结构的树状表现
形式
。
Hive
使用
Antlr
实现
SQL
的词法和语法
解析生成
AST
。
QueryBlock
QueryBlock
是一条
SQL
最基本的组成单元,包括三个部分:输入源,计算过程,输出。简单来讲一个
QueryBlock
就是一个子查询
。
Operator
Hive
最终生成的
MapReduce
任务,
Map
阶段和
Reduce
阶段均由
OperatorTree
组成。逻辑操作符,就是在
Map
阶段或者
Reduce
阶段完成单一特定的操作。
基本的操作符包括
TableScanOperator
,
FilterOperator
,
JoinOperator
,
GroupByOperator
,
ReduceOutputOperator
,
FileOutputOperator
。
Operator
在
Map Reduce
阶段之间的数据传递都是一个流式的过程。每一个
Operator
对一行数据完成操作后之后将数据传递给
childOperator
计算
。
逻辑层优化
器、物理层优化器
SimpleFetchOptimizer
、
MapJoinProcessor
、
GroupByOptimizer
、
PredicatePushDown
等等
MapReduce
任务生成步骤
AST>>QueryBlock
Operator Tree>>
MapReduce
Job
查看执行计划:
EXPLAIN [EXTENDED|DEPENDENCY|AUTHORIZATION]
query
2
3
4
5
6
7
8
9
10
2 b.pid,
3 count(distinct a.wid)
4from default.saas_uc_user_info b
5join d_extra.dim_shp_saas_pid_info_ext a
6on a.id=b.pid
7join default.t_march_merchant_info c
8on b.wid=c.wid
9group by b.pid
10
数据倾斜
map/reduce
程序执行时,
reduce
节点大部分执行完毕,但是有一个或者几个
reduce
节点运行很慢,导致整个程序的处理时间很长,这是因为某一个
key
的条数比其他
key
多很多(有时是百倍或者千倍之多),这条
key
所在的
reduce
节点所处理的数据量比其他节点就大很多,从而导致某几个节点迟迟运行不完,此称之为数据倾斜
。
特殊情况:
map
端“数据倾斜”
num_map_tasks
= max[${
mapred.min.split.size
},min(${
dfs.block.size
},${
mapred.max.split.size
})]
通过调整
max
可以起到调整
map
数的作用,减小
max
可以增加
map
数,增大
max
可以减少
map
数。需要提醒的是,直接调整
mapred.map.tasks
这个参数是没有效果的。
数据
量大不是问题,数据倾斜是个问题
。
倾斜
的原因
:
使
map
的输出数据更均匀的分布到
reduce
中去,是我们的最终目标。由于
Hash
算法的局限性,按
key Hash
会或多或少的造成数据倾斜。大量经验表明数据倾斜的原因是人为的建表疏忽或业务逻辑可以规避的
。
解决
思路
:
Hive
的执行是分阶段的,
map
处理数据量的差异取决于上一个
stage
的
reduce
输出,所以如何将数据均匀的分配到各个
reduce
中,就是解决数据倾斜的
根本
。
典型的业务场景
NULL
值产生
的数据
倾斜
(
或其他默认业务值。比如
常见
的空值
,0,1
,-1,-99
等业务默认
值。
)
例:如
日志中,常会有信息丢失的问题,
比如电商日志
中
的
store_id
,
如果取其中的
store_id
和 门店
表
中
的
store_id
关联,会碰到数据倾斜的问题
。
解决办法:
写
成两段
union all
在一起
给空值做转换
join
条件写成
2
3
4
5
6
7
2On
3case when A.store_id= null then concat('hive',rand()) else A.store_id end
4=
5B.store_id
6
7
园园的例子:
drop table temp.qyy_test_1 ;
create table temp.qyy_test_1 as
select
logdate
,
cuid
, max(
wid
)
wid
from
datacleanup.mdpath
where
logdate
= '2017-05-01' and logdate
<= '2017-05-20'
group by
logdate
,
cuid
;
drop table temp.qyy_test_2 ;
create table temp.qyy_test_2 as
select
t1.logdate,
t1.cuid,
t2.wid
from temp.qyy_test_1 t1
left join
d_extra.dm_user_wid_msg
t2 on ( t1.wid = t2.wid );

drop table temp.qyy_test_3 ;
create table temp.qyy_test_3 as
select
t1.logdate,
t1.cuid,
t2.wid
from temp.qyy_test_1 t1
left join d_extra.dm_user_wid_msg t2
on ( if (t1.wid > 0,t1.wid, cast(ceiling(rand() * -65535) as bigint)) = t2.wid ) ;

结论:
如果关联不上的
KEY
数据太多,可使用
rand()
将这种数据均匀分布到各个
reducer
中。
count distinct
set
hive.map.aggr
=true;
sum,count,max,min
等
UDAF
,不怕数据倾斜问题
,
hadoop
在
map
端的汇总合并优化,使数据倾斜不成问题。
此语句非常容易产生数据
倾斜,因为其执行的
MapReduce
是以
GroupBy
分组
,
再对
distinct
列排序
,
然后输出交给
Reduce.
问题
就在这里,
相比其它
GroupBy
聚合统计,
count(distinct)
少一个关键步骤
(Map
的预计算,
在
Map
端提前做一次聚合再将聚合结果交给
Reduce)
当
Map
直接将全部数据交给
Reduce
后,
如果数据的分组本身不平衡
(
存在大量值为
NULL
或空的记录,比如及格
,80%
以上及格数据
),
会造成某一些
Reduce
处理太过多的数据。
解决方式:
如果是仅计算
count distinct
,可以不用处理,直接过滤,在最后结果中加
1
;或者拆成
count(1) from (select distinct)
。
如果
还有其他
计算需要
进行
group by
,可以先将值为空的记录单独处理,再和其他计算结果进行
union all
。
set
hive.groupby.skewindata
=true
只能支持一个
distinct
。
生成的查询计划有两个
MapReduce
任务
。
eg: 园园的例子
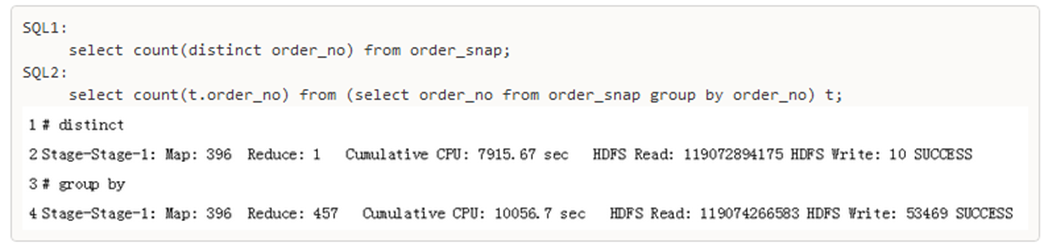
使用
Distinct
会将所有
order_no
都
shuffle
到一个
reducer
中,这就导致了数据倾斜。
而
Group By
会启动
457
个
reducer
,将数据均匀的分布到多个
CPU
上执行。 这样速度就会快很多。
group by
Select
wid
, count(*)
From
datacleanup.mdpath
Where
logdate
= ‘2017-05-01
’
Group by
wid
;
以上脚本也会产生数据倾斜, 因为
wid
为
null or -1
的记录很多。
解决办法:
set
hive.groupby.skewindata
=true;
set
hive.groupby.mapaggr.checkinterval
=100000 ;
当某个
KEY
的数据量超过这个值时,
hive
就会产生一个新的
reducer
去处理。
不同数据类型关联产生数据倾斜
场景:用户表中
user_id
字段为
int
,
log
表中
user_id
字段既有
string
数据也有
int数据
。当按照
user_id
进行两个表的
Join
操作时,默认的
Hash
操作会按
int
型的
id
来进行分配,这样会导致所有
string
类型
id
的记录都分配到一个
Reducer
中
。
解决方法:把数字类型转换成字符串
类型
。
Join
操作产生数据
倾斜
大表和小表
Join
产生
原因:
Hive
在进行
join
时,按照
join
的
key
进行分发,而在
join
左边的表的数据会首先读入内存,如果左边表的
key
相对分散,读入内存的数据会比较小,
join
任务执行会比较快;而如果左边的表
key
比较集中,而这张表的数据量很大(也容易
发生
OOM
错误
),那么数据倾斜就会比较严重,而如果这张表是小表,则还是应该把这张表放在
join
左边
。
解决
方式:使用
mapjoin
。
此
Join
操作在
Map
阶段完成,不再需要
Reduce
,也就不需要经过
Shuffle
过程,从而能在一定程度上节省资源提高
JOIN
效率。
可以变相支持不等
连接
。
在
0.7.0
版本之前:需要在
sql
中使用
/*+ MAPJOIN(
smallTable
) */
;
例:
SELECT
/*+ MAPJOIN(b) */
a.key
,
a.value
FROM a JOIN b
ON
a.key
b.key
;
在
0.7.0
版本之后:
可以
set
hive.auto.convert.join
=true
;
其他相关参数:
set
hive.mapjoin.smalltable.filesize
=100000000
;
小表最大大小
set
hive.auto.convert.join.noconditionaltask
=true
;
合并多个
MJ
为一个
set
hive.auto.convert.join.noconditionaltask.size
=894435328
;
多
个
MJ
的小表总大小,如总大小小于此值则合并。
小技巧
只
取需要的字段
表
先过滤
总结:
数据量大不是问题,数据倾斜是个问题
。
jobs
数比较多的作业运行效率相对比较低,比如即使有几百行的表,如果多次关联多次汇总,产生十几个
jobs
,耗时很长。原因是
map reduce
作业初始化的时间是比较长的
。(
tez
做的事情)
sum,count,max,min
等
UDAF
,不怕数据倾斜问题
,
hadoop
在
map
端的汇总合并优化,使数据倾斜不成问题
。
数据倾斜是导致效率大幅降低的主要原因,可以采用多一次
Map/Reduce
的方法, 避免倾斜
。
—-Credit to Peiqing
优化意识及思路
MR流程图

WordCount
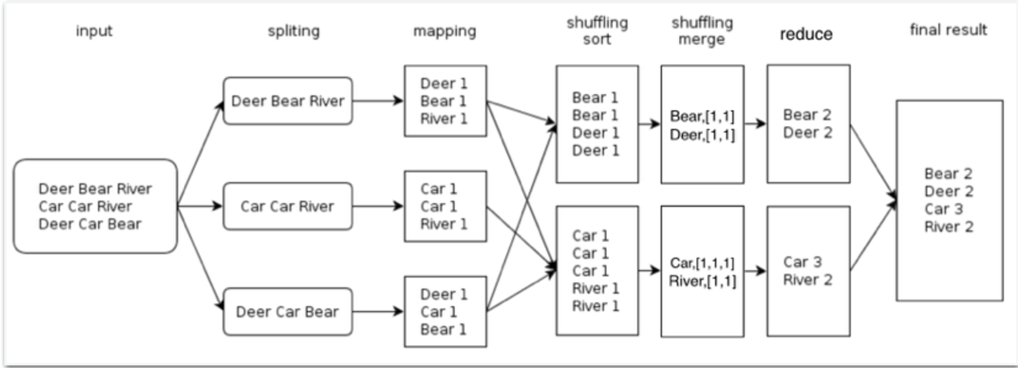
方法论:
收集数据
:
explain
查看执行计划
定位瓶颈
:
1
)查看执行日志,定位哪个
Stage
(
Job
)时间长
2
)查看
Job
日志,定位
Map
阶段慢还是
Reduce
阶段慢
诊断问题
:
1
)资源不足
pending
2
)数据倾斜
3
)
reduce
数太少
4
)
…
解决瓶颈
:对症下药,
蛇打七寸
如何优化?
一个Hive查询生成多个Map Reduce Job,一个Map Reduce Job又有Map,Spill,Shuffle,Sort,Reduce等多个阶段,所以针对Hive查询的优化可以大致分为针对MR中单个步骤的优化(其中又会有细分),针对MR全局的优化,和针对整个查询(多MR Job)的优化。。。
Map
阶段的优化
Map
阶段的优化,主要是确定合适的
Map
数
num_Map_tasks
${input.size
} /max[${
Mapred.min.split.size
},min(${
dfs.block.size
},${
Mapred.max.split.size
})]
mapred.min.split.size
指的是
数据的最小分割单元
大小。
mapred.max.split.size
指的是
数据的最大分割单元
大小。
dfs.block.size
指的是
HDFS
设置的数据块
大小。
需要提醒的是,
**直接调整 **
mapred.map.tasks
这个参数是没有效果的
。
Reduce
阶段的优化
Reduce
阶段的优化,主要是确定合适的
Reduce
数
与
Map
优化不同的是,
Reduce
优化时,可以直接设置
mapred.reduce.tasks
参数从而直接指定
Reduce
的个数。当然直接指定
Reduce
个数虽然比较方便,
但是不利于自动扩展
。
num_Reduce_tasks = min[${
hive.exec.reducers.max
},(${
input.size
} / ${
hive.exec.reducers.bytes.per.reducer
})]
hive.exec.reducers.max
–reduce
数的上限值
Map
与
Reduce
之间的优化
**Spill **
**与 **
Sort
io.sort.mb
io.sort.factor
Copy
mapred.reduce.slowstart.completed.maps
tasktracker.http.threads
mapred.reduce.parallel.copies
文件格式的优化
文件格式
压缩比例
查询时间
Textfile
Rcfile
parquet
Orcfile
小文件合并
https://blog.csdn.net/yfkiss/article/details/8590486
Map
输入合并小文件
输出合并
执行模式
本地模式(数据量小时)
分布模式(数据量大时)
//
开启本地模式
set
hive.exec.mode.local.auto
= true
//job
的最大
map
数
hive.exec.mode.local.auto.tasks.max
?
//job
的最大输入数据量
,
**一般 **
**= **
dfs.block.size
hive.exec.mode.local.auto.inputbytes.max
JVM
重用
JVM
重用正常情况下,
MapReduce
启动的
JVM
在完成一个
task
之后就退出了,但是如果任务花费时间很短,又要多次启动
JVM
的情况下(比如对很大数据量进行计数操作),
JVM
的启动时间就会变成一个比较大的
overhead
。
在这种情况下,可以使用
jvm
重用的参数:
mapred.job.reuse.jvm.num.tasks
** = 5;**
他的作用是让一个
jvm
运行多次任务之后再退出。这样一来也能节约不少JVM
启动时间。
三大经典
join
算法
N
es
ted join
Hash join
Sort merge join
Join
算法
处理分布式join,一般有两种方法:
replication join:把其中一个表复制到所有节点,这样另一个表在每个节点上面的分片就可以跟这个完整的表join了;
repartition join:把两份数据按照join key进行hash重分布,让每个节点处理hash值相同的join key数据,也就是做局部的join。
这两种方式在
M/R Job
中分别对应了
Map side join
和
Reduce side join
Map-side join
(
小表复制的代价会好过大表
Shuffle
的代价
)
MapJoin
通常用于一个很小的表和一个大表进行
join
的场景,具体小表有多小,由参数
hive.mapjoin.smalltable.filesize
来决定,该参数表示小表的总大小,默认值为
25000000
字节,即
25M
。
Hive0.7
之前,需要使用
hint
提示
/*+
mapjoin
(table) */
才会执行
MapJoin
,
否则执行
Common Join
,但在
0.7
版本之后,默认自动会转换
Map Join
,由参数
hive.auto.convert.join
来控制,默认为
true.
法一:
hint
,语法是
/*+
MapJOIN
(
tbl
)*/
,其中
tbl
就是你想要做
replication
的表
法二:
hive.auto.convert.join
hive.mapjoin.smalltable.filesize
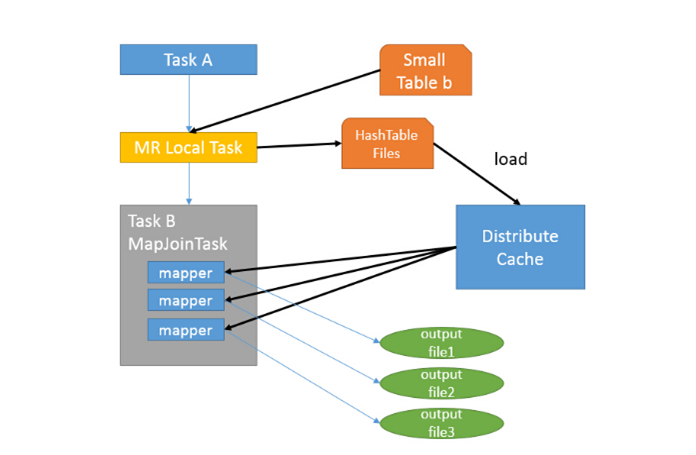
Broadcast hash Join
bucket Map join
(
当小表内存里放不下时
)
原理:
两个join表在join key上都做hash bucket,这样数据就会按照join key做hash bucket。
小表依然复制到所有节点,Map join的时候,
小表的每一组bucket加载成hashtable,与对应的一个大表bucket做局部join
,这样每次只需要加载部分hashtable就可以了。
要点:
和
map join
一起工作(
hive.optimize.bucketmapjoin
** = true;**
)
所有要
join
的表都必须做了分桶
(bucket) ,
大表的桶个数是小表桶个数的
整数倍
.
做了
bucket
的
列
必须
=
join
的
列
往
bucket
表里查数据时,必须
hive.enforce.bucketing
=true

Sort merge bucket Map join
当
两个表的
join key
都具有唯一性
的时候(也就是可做主键),还可以进一步做
Sort merge bucket Map join
。做法还是两边要做
hash bucket
,而且每个
bucket
内部要进行排序。这样一来当两边
bucket
要做局部
join
的时候,只需要用类似
merge Sort
算法中的
merge
操作一样把两个
bucket
顺序遍历一遍即可完成,这样甚至都不用把一个
bucket
完整的加载成
hashtable,这对性能的提升会有很大帮助。
在bucket Map join的基础上加上下面的设置即可:
hive.optimize.bucketmapjoin.sortedmerge
= true;
hive.input.format
= org.apache.Hadoop.Hive.ql.io.BucketizedHiveInputFormat;
Join
总结
一般
Map join
的优化效果已经很明显了。
如果小表不能完全放内存,但是小表相对大表的
size
量级差别也非常大的时候也可以试试
bucket Map join
,不过其
hash table
分发的过程会浪费不少时间,需要评估下是否能够比
Reduce join
更高效。
而
Sort merge bucket Map join
虽然性能不错,但是把数据做成
bucket
本身也需要时间,另外其发动条件比较特殊,就是两边
join key
必须都唯一
并行
场景:当需要执行
多个子查询
union all
或者
join
操作的时候
并行执行的确可以大的加快任务的执行速率,但不会减少其占用的资源。
//
打开任务并行执行
set
hive.exec.parallel
=true;
//
同一个
sql
允许最大并行度,默认为
8
。
set
hive.exec.parallel.thread.number
=16;
数据倾斜
group by
造成的倾斜
set
hive.map.aggr
=true
join
造成的倾斜
set
hive.optimize.skewjoin
= true;
set
hive.skewjoin.key
阀值;
原理:
特殊值单独
join
转化成
map join
union all ————————————————————
非特殊值转化成没有倾斜的普通
join
Left
semi
join
以下
2
个语句,结果是否一样
select a.id
from tmp.aaa a inner join tmp.bbb b
on a.id=b.id;
select a.id
from tmp.aaa a left semi join tmp.bbb b
on a.id=b.id;
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
2select '1'
3union all
4select '2'
5union all
6select '3’
7;
8insert overwrite table tmp.bbb
9select ‘2’
10;
11
12
13---------
14
15insert overwrite table tmp.bbb
16select '2'
17union all
18select '2'
19;
20
21
22
23CREATE TABLE tmp.aaa (
24 `id` string
25)
26ROW FORMAT SERDE
27 'org.apache.hadoop.hive.ql.io.orc.OrcSerde'
28STORED AS INPUTFORMAT
29 'org.apache.hadoop.hive.ql.io.orc.OrcInputFormat'
30OUTPUTFORMAT
31 'org.apache.hadoop.hive.ql.io.orc.OrcOutputFormat'
32
33
实现
IN/EXISTS
子查询
SELECT A.*
FROM A WHERE A.KEY IN
(SELECT B.KEY FROM B WHERE B.VALUE > 100);
等同于
:
SELECT A.*
FROM A LEFT SEMI JOIN B
ON (A.KEY = B.KEY and B.VALUE > 100);
Left
semi
join
总结

1
,
select
和
where
语句不能引用到右表里的字段(横向不可扩展字段)
2
,不会增加主(左)表的行数(纵向无副作用)
3
,一旦匹配
,
立即退出
sort by
Order by 实现全局排序,一个reduce实现,效率低
Sort by 实现部分有序,单个reduce输出的结果是有序的,效率高,通常和DISTRIBUTE BY关键字一起使用(DISTRIBUTE BY关键字 可以指定map 到 reduce端的分发key)
CLUSTER BY col1 等价于DISTRIBUTE BY col1 SORT BY col1
分区消除(裁剪)
以下
2
句哪个效率高?
select a.id ,b.id
from tmp.aaa a inner join tmp.bbb b
on a.id=b.id and a.id
1
select a.id ,b.id
from tmp.aaa a inner join tmp.bbb b
on a.id=b.id
where a.id
=1
通常是
a.id
写在
on
里效率高,但是如果
a.id
是一个分区字段呢?
等价改写
需求:查询日志中同时访问过页面a
和页面
b
的用户数量
面向明细
select count(*)
from (select
wid
from logs where
pagename
= 'a' group by
wid
) a
join (select
wid
from logs where
pagename
= 'b' group by
wid
) b
on a.
wid
b.wid;
2
个求子查询的
job
,一个用于关联的
job
,还有一个计数的
job
,一共有
4
个
job
面向集合
select count(*) from (
select
wid
from logs group by
wid
having count(case when
pagename = 'a' then 1 end) *count(case when
pagename
= 'b' then 1 end) > 0
) t;
只需要用两个
job
就能跑完(1个子查询的group by, 1个count)
打个比方,你去一个会场里找对象,条件是1.7以上+30岁以下+肤白貌美,面向明细的做法就是先转一圈,挑出1.7以上的,再转一圈,挑出30岁以下的。。。面向集合的做法就是只转一圈,挑出同时满足的所有条件的。
job的启动是有成本的,我们尽可能在启动一个job时,让它多干活。
等价改写的陷阱
以下
2
句的结果是否一样?
select *
from
tmp.ccc
where id1=1 or id2=1
select
*
from
tmp.ccc
where id1=1
union all
select
*
from
tmp.ccc
where id2=1
准备数据:
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
2 `id1` string,
3 `id2` string
4)
5ROW FORMAT SERDE
6 'org.apache.hadoop.hive.ql.io.orc.OrcSerde'
7STORED AS INPUTFORMAT
8 'org.apache.hadoop.hive.ql.io.orc.OrcInputFormat'
9OUTPUTFORMAT
10 'org.apache.hadoop.hive.ql.io.orc.OrcOutputFormat'
11;
12
13
14insert overwrite table tmp.ccc
15select '1' ,'0'
16union all
17select '2' ,'1'
18union all
19select '3' ,'2';
20
21insert overwrite table tmp.ccc
22select '1' ,'1'
23union all
24select '2' ,'0'
25union all
26select '3' ,'2';
27
答案:union all 会产生重复的行
—–Credit to Xunbi
ref:
https://www.cnblogs.com/sandbank/p/6408762.html
https://blog.csdn.net/qq_26442553/article/details/80866723
https://www.cnblogs.com/smartloli/p/4356660.html
https://www.jianshu.com/p/6a9a52550f3e
