Kafka集群搭建
一、概念
- 说明
它是一个分布式消息系统,由linkedin使用scala编写,用作LinkedIn的活动流(Activity Stream)和运营数据处理管道(Pipeline)的基础。具有高水平扩展和高吞吐量。
- 比较
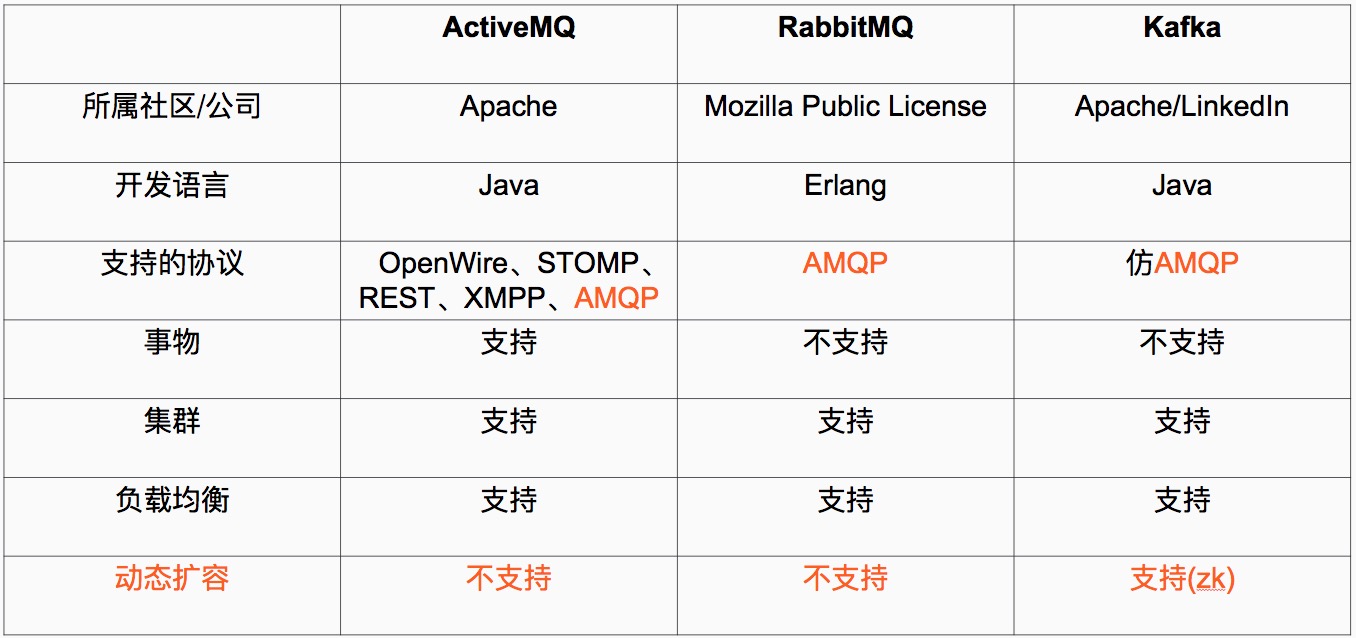
定义解释:
1
、Java 和 scala都是运行在JVM上的语言。
2
、erlang和最近比较火的和go语言一样是从代码级别就支持高并发的一种语言,所以RabbitMQ天生就有很高的并发性能,但是 有RabbitMQ严格按照AMQP进行实现,受到了很多限制。kafka的设计目标是高吞吐量,所以kafka自己设计了一套高性能但是不通用的协议,他也是仿照AMQP( Advanced Message Queuing Protocol 高级消息队列协议)设计的。
3
、事物的概念:在数据库中,多个操作一起提交,要么操作全部成功,要么全部失败。举个例子, 在转账的时候付款和收款,就是一个事物的例子,你给一个人转账,你转成功,并且对方正常行收到款项后,这个操作才算成功,有一方失败,那么这个操作就是失败的。
对应消在息队列中,就是多条消息一起发送,要么全部成功,要么全部失败。3个中只有ActiveMQ支持,这个是因为,RabbitMQ和Kafka为了更高的性能,而放弃了对事物的支持 。
4
、集群:多台服务器组成的整体叫做集群,这个整体对生产者和消费者来说,是透明的。其实对消费系统组成的集群添加一台服务器减少一台服务器对生产者和消费者都是无感之的。
5
、负载均衡,对消息系统来说负载均衡是大量的生产者和消费者向消息系统发出请求消息,系统必须均衡这些请求使得每一台服务器的请求达到平衡,而不是大量的请求,落到某一台或几台,使得这几台服务器高负荷或超负荷工作,严重情况下会停止服务或宕机。
6
、动态扩容是很多公司要求的技术之一,不支持动态扩容就意味着停止服务,这对很多公司来说是不可以接受的。
注:
阿里巴巴的Metal,RocketMQ都有Kafka的影子,他们要么改造了Kafka或者借鉴了Kafka,最后Kafka的动态扩容是通过Zookeeper来实现的。
Zookeeper
是一种在分布式系统中被广泛用来作为:分布式状态管理、分布式协调管理、分布式配置管理、和分布式锁服务的集群。
kafka
增加和减少服务器都会在Zookeeper节点上触发相应的事件kafka系统会捕获这些事件,进行新一轮的负载均衡
,客户端也会捕获这些事件来进行新一轮的处理。
- 工作原理
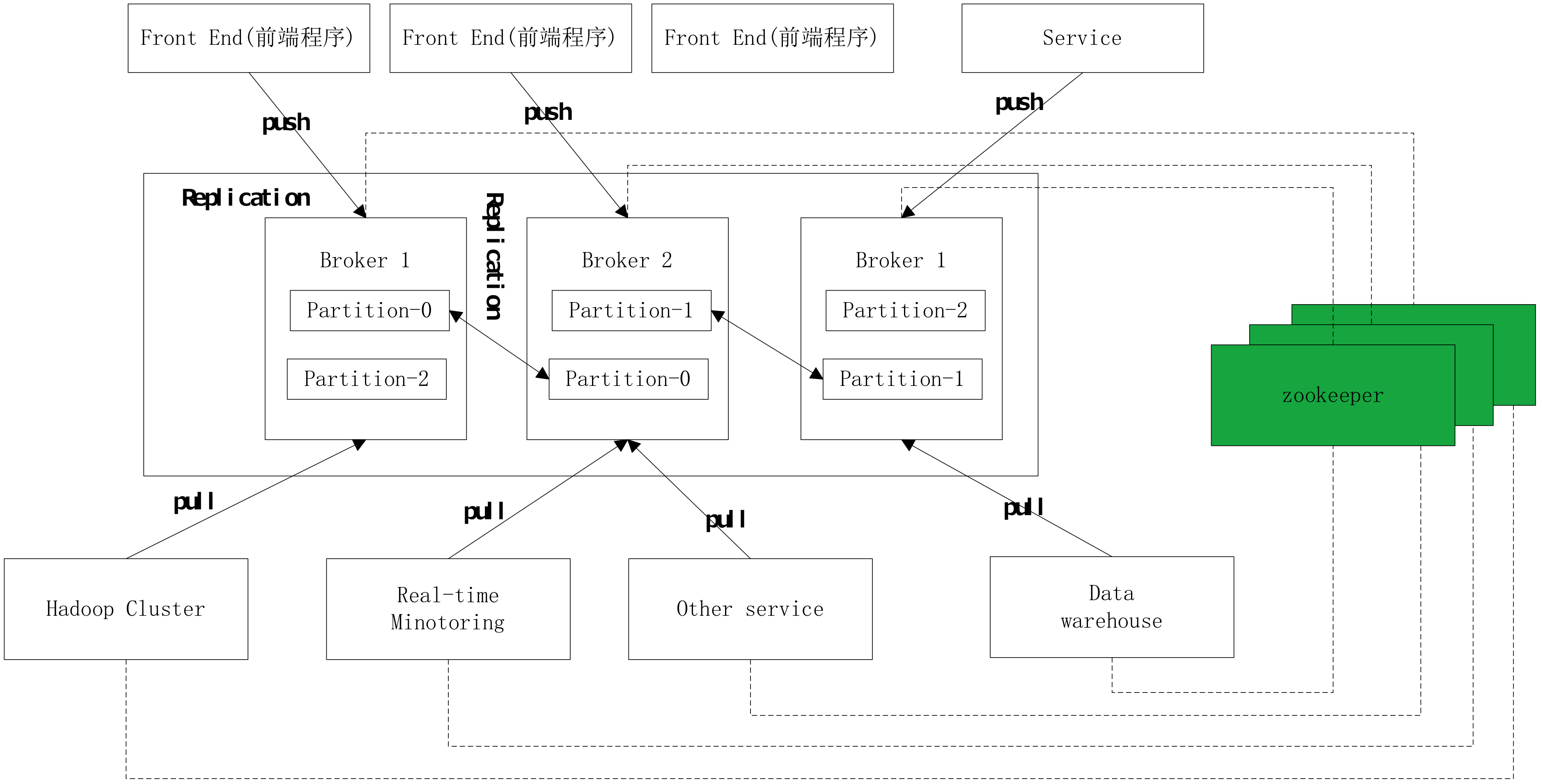
二、搭建kafak
搭建kafka集群首先要搭建zookeeper集群
- 软件环境
| Ip | 系统类型 | |
| 192.168.1.221 | centos7 | Server1 |
| 192.168.1.138 | centos7 | Server2 |
| 192.168.1.89 | centos7 | Server3 |
1 | 1 |
-
Kafka需要在zookeeper上运行,所以先搭建zookeeper (每一台服务器都需要操作)
-
安装jdk
2
3
4
2
3yum -y install java-1.7.0-openjdk*
4
-
. 下载zookeeper
2
3
4
5
6
7
8
9
10
11
12
13
14
2
3cd /use/local/zookeeper
4
5#快照日志
6
7mkdir data
8
9#事务日志
10
11mkdir logs
12
13#命令下载
14
-
修改配置文件
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
2cd /usr/local/zookeeper/apache-zookeeper-3.5.6-bin/conf/
3
4
5
6tickTime=2000
7initLimit=10
8syncLimit=5
9dataDir=/usr/local/zookeeper/data
10dataLogDir=/usr/local/zookeeper/logs
11clientPort=2181
12server.1=192.168.1.221:2888:3888
13server.2=192.168.1.138:2888:3888
14server.3=192.168.1.89:2888:3888
15#server.1 这个1是服务器的标识也可以是其他的数字, 表示这个是第几号服务器,用来标识服务器,这个标识要写到快照目录下面myid文件里
16#192.168.7.107为集群里的IP地址,第一个端口是master和slave之间的通信端口,默认是2888,第二个端口是leader选举的端口,集群刚启动的时候选举或者leader挂掉之后进行新的选举的端口默认是3888
17
2
3
4
2
3
4
-
创建myid文件(分别在每一个机器上)
2
3
4
5
6
7
2echo "1" > /usr/local/zookeeper/data/myid
3#server2
4echo "2" > /usr/local/zookeeper/data/myid
5#server3
6echo "3" > /usr/local/zookeeper/data/myid
7
2
3
4
2
3
4
-
启动(三台机子都要操作)
2
3
4
5
6
7
8
9
10
11
2cd /opt/zookeeper/zookeeper-3.4.6/bin
3#启动服务(3台都需要操作)
4./zkServer.sh start
5#检查服务器状态
6./zkServer.sh status
7#执行命令jps
8Jps
9QuorumPeerMain
10
11
-
搭建kafka集群
2
3
4
5
6
2创建消息目录 mkdir logs,主要存放 kafka消息
3在线下载 wget https://mirrors.tuna.tsinghua.edu.cn/apache/kafka/2.4.0/ kafka_2.13-2.4.0.tgz
4解压 tar -zxvf kafka_2.13-2.4.0.tgz
5
6
-
修改配置文件
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
2
3cd /usr/local/kafka/kafka_2.13-2.4.0/config/
4
5编辑server.poperties
6
7vim server.poperties
8
9
10broker.id=0 #当前机器在集群中的唯一标识,和zookeeper的myid性质一样
11port=9092 #当前kafka对外提供服务的端口默认是9092
12host.name=192.168.1.221 #这个参数默认是关闭的,在0.8.1有个bug,DNS解析问题,失败率的问题。
13num.network.threads=3 #这个是borker进行网络处理的线程数
14num.io.threads=8 #这个是borker进行I/O处理的线程数
15log.dirs=/opt/kafka/kafkalogs/ #消息存放的目录,这个目录可以配置为“,”逗号分割的表达式,上面的num.io.threads要大于这个目录的个数这个目录,如果配置多个目录,新创建的topic他把消息持久化的地方是,当前以逗号分割的目录中,那个分区数最少就放那一个
16socket.send.buffer.bytes=102400 #发送缓冲区buffer大小,数据不是一下子就发送的,先回存储到缓冲区了到达一定的大小后在发送,能提高性能
17socket.receive.buffer.bytes=102400 #kafka接收缓冲区大小,当数据到达一定大小后在序列化到磁盘
18socket.request.max.bytes=104857600 #这个参数是向kafka请求消息或者向kafka发送消息的请请求的最大数,这个值不能超过java的堆栈大小
19num.partitions=1 #默认的分区数,一个topic默认1个分区数
20log.retention.hours=168 #默认消息的最大持久化时间,168小时,7天
21message.max.byte=5242880 #消息保存的最大值5M
22default.replication.factor=2 #kafka保存消息的副本数,如果一个副本失效了,另一个还可以继续提供服务
23replica.fetch.max.bytes=5242880 #取消息的最大直接数
24log.segment.bytes=1073741824 #这个参数是:因为kafka的消息是以追加的形式落地到文件,当超过这个值的时候,kafka会新起一个文件
25log.retention.check.interval.ms=300000 #每隔300000毫秒去检查上面配置的log失效时间(log.retention.hours=168 ),到目录查看是否有过期的消息如果有,删除
26log.cleaner.enable=false #是否启用log压缩,一般不用启用,启用的话可以提高性能
27zookeeper.connect=192.168.1.221: 2181,192.168.1.138:2181,192.168.1.89:218 #设置zookeeper的连接端口
28
-
启动服务
2
3
4
5
6
7
8
9
10
11
2cd /usr/local/kafka/kafka_2.13-2.4.0/bin #进入到kafka的bin目录
3#前台启动看看报错不
4./kafka-server-start.sh ../config/server.properties
5#后台启动
6./kafka-server-start.sh -daemon ../config/server.properties
7#是否启动
8Jps
9QuorumPeerMain
10Kafka
11
2
3
4
2
3
4
三、Springboot测试kafka
2
3
4
21.jar包依赖
3
4
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
2 <dependency>
3 <groupId>org.springframework.kafka</groupId>
4 <artifactId>spring-kafka</artifactId>
5 </dependency>
6
7 <!-- swagger -->
8 <dependency>
9 <groupId>io.springfox</groupId>
10 <artifactId>springfox-swagger2</artifactId>
11 <version>2.8.0</version>
12 </dependency>
13
14 <!--swagger2-ui依赖-->
15 <dependency>
16 <groupId>io.springfox</groupId>
17 <artifactId>springfox-swagger-ui</artifactId>
18 <version>2.8.0</version>
19 </dependency>
20
21
2
3
22.yml配置
3
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
2
3 port: 18888
4
5
6
7topinfo:
8
9 # kafka集群配置 ,bootstrap-servers 是必须的
10
11 kafka:
12
13 # 生产者的kafka集群地址
14
15 bootstrap-servers: 192.168.1.221:9092,192.168.1.138:9092,192.168.1.89:9092
16
17 producer:
18
19 topic-name: topinfo-01
20
21 consumer:
22
23 group-id: ci-data
24
25
26
3.yml变实体类
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
2
3import com.uximt.kaa.kafka.bean.Producer;
4
5import org.springframework.boot.context.properties.ConfigurationProperties;
6
7import org.springframework.stereotype.Component;
8
9
10
11@ConfigurationProperties(prefix = "topinfo.kafka")
12
13@Component
14
15public class KafKaConfiguration {
16
17
18
19 /**
20
21 * @Fields bootstrapServer : 集群的地址
22
23 */
24
25 private String bootstrapServers;
26
27
28
29 private Producer producer;
30
31
32
33 private Consumer consumer;
34
35
36
37 public String getBootstrapServers() {
38
39 return bootstrapServers;
40
41 }
42
43
44
45 public void setBootstrapServers(String bootstrapServers) {
46
47 this.bootstrapServers = bootstrapServers;
48
49 }
50
51
52
53 public Producer getProducer() {
54
55 return producer;
56
57 }
58
59
60
61 public void setProducer(Producer producer) {
62
63 this.producer = producer;
64
65 }
66
67
68
69 public Consumer getConsumer() {
70
71 return consumer;
72
73 }
74
75
76
77 public void setConsumer(Consumer consumer) {
78
79 this.consumer = consumer;
80
81 }
82
83}
84
4.topic配置
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
2import org.apache.kafka.clients.admin.AdminClientConfig;
3import org.apache.kafka.clients.admin.NewTopic;
4import org.springframework.beans.factory.annotation.Autowired;
5import org.springframework.context.annotation.Bean;
6import org.springframework.context.annotation.Configuration;
7import org.springframework.kafka.core.KafkaAdmin;
8import java.util.HashMap;
9import java.util.Map;
10
11
12/**
13
14* @date: 2019/12/31 14:36
15
16 * @Explanation:
17
18 */
19
20@Configuration
21
22public class KafKaTopicConfig {
23
24
25 @Autowired
26
27 private KafKaConfiguration configuration;
28
29
30 /**
31
32 *@Description: kafka管理员,委派给AdminClient以创建在应用程序上下文中定义的主题的管理员。
33
34 *@return
35
36 */
37
38 @Bean
39
40 public KafkaAdmin kafkaAdmin() {
41
42 Map<String, Object> props = new HashMap<>();
43
44 // 配置Kafka实例的连接地址
45
46 props.put(AdminClientConfig.BOOTSTRAP_SERVERS_CONFIG, configuration.getBootstrapServers());
47
48 KafkaAdmin admin = new KafkaAdmin(props);
49
50 return admin;
51
52 }
53
54
55
56 /**
57
58 *@Description: kafka的管理客户端,用于创建、修改、删除主题等
59
60 *@return
61
62 */
63
64 @Bean
65
66 public AdminClient adminClient() {
67
68 return AdminClient.create(kafkaAdmin().getConfig());
69
70 }
71
72
73 /**
74
75 * @Description: 创建一个新的 topinfo 的Topic,如果kafka中topinfo 的topic已经存在,则忽略。
76
77 * @return
78
79 */
80
81 @Bean
82
83 public NewTopic topinfo() {
84
85 // 主题名称
86
87 String topicName = configuration.getProducer().getTopicName();
88
89 // 第二个参数是分区数, 第三个参数是副本数量,确保集群中配置的数目大于等于副本数量
90
91 return new NewTopic(topicName, 2, (short) 2);
92
93 }
94
95
96}
97
5.配置kafka生产者消费者
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
164
165
166
167
168
169
170
171
172
173
174
175
176
177
178
179
180
181
182
183
184
185
186
187
188
189
190
191
192
193
194
195
196
197
198
199
200
201
202
203
204
205
206
207
208
209
210
211
212
213
214
215
216
217
218
219
220
221
222
223
224
225
226
227
228
229
230
231
232
233
234
235
236
237
238
239
240
241
242
243
244
2
3import org.apache.kafka.clients.producer.ProducerConfig;
4
5import org.springframework.beans.factory.annotation.Autowired;
6
7import org.springframework.context.annotation.Bean;
8
9import org.springframework.context.annotation.Configuration;
10
11import org.springframework.kafka.config.ConcurrentKafkaListenerContainerFactory;
12
13import org.springframework.kafka.config.KafkaListenerContainerFactory;
14
15import org.springframework.kafka.core.*;
16
17import org.springframework.kafka.listener.ConcurrentMessageListenerContainer;
18
19
20
21import java.util.HashMap;
22
23import java.util.Map;
24
25
26
27/**
28
29* @date: 2019/12/31 14:30
30
31 * @Explanation: kafka配置类
32
33 */
34
35@Configuration
36
37public class KafKaConfig {
38
39
40
41 @Autowired
42
43 private KafKaConfiguration configuration;
44
45
46
47
48
49
50
51 /**
52
53 * @Description: 生产者的配置
54
55 * @return
56
57 */
58
59 public Map<String, Object> producerConfigs() {
60
61
62
63 Map<String, Object> props = new HashMap<>();
64
65 // 集群的服务器地址
66
67 props.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, configuration.getBootstrapServers());
68
69 // 消息缓存
70
71 props.put(ProducerConfig.BUFFER_MEMORY_CONFIG, 40960);
72
73 // 生产者空间不足时,send()被阻塞的时间,默认60s
74
75 props.put(ProducerConfig.MAX_BLOCK_MS_CONFIG, 6000);
76
77 // 生产者重试次数
78
79 props.put(ProducerConfig.RETRIES_CONFIG, 0);
80
81 // 指定ProducerBatch(消息累加器中BufferPool中的)可复用大小
82
83 props.put(ProducerConfig.BATCH_SIZE_CONFIG, 4096);
84
85 // 生产者会在ProducerBatch被填满或者等待超过LINGER_MS_CONFIG时发送
86
87 props.put(ProducerConfig.LINGER_MS_CONFIG, 1);
88
89 // key 和 value 的序列化
90
91 props.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, "org.apache.kafka.common.serialization.StringSerializer");
92
93 props.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG,
94
95 "org.apache.kafka.common.serialization.StringSerializer");
96
97 // 客户端id
98
99 props.put(ProducerConfig.CLIENT_ID_CONFIG, "producer.client.id.topinfo");
100
101
102
103 return props;
104
105 }
106
107
108
109 /**
110
111 * @Description: 生产者工厂
112
113 * @return
114
115 */
116
117 @Bean
118
119 public ProducerFactory<String, String> producerFactory() {
120
121 return new DefaultKafkaProducerFactory<>(producerConfigs());
122
123 }
124
125
126
127 /**
128
129 * @Description: KafkaTemplate
130
131 * @return
132
133 */
134
135 @Bean
136
137 public KafkaTemplate<String, String> kafkaTemplate() {
138
139 return new KafkaTemplate<String, String>(producerFactory());
140
141 }
142
143
144
145
146
147 // ------------------------------------------------------------------------------------------------------------
148
149
150
151 /**
152
153 * @Description: 消费者配置
154
155 * @return
156
157 */
158
159 public Map<String, Object> consumerConfigs() {
160
161 Map<String, Object> props = new HashMap<String, Object>();
162
163 props.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, configuration.getBootstrapServers());
164
165 // 消费者组
166
167 props.put(ConsumerConfig.GROUP_ID_CONFIG, configuration.getConsumer().getGroupId());
168
169 // 自动位移提交
170
171 props.put(ConsumerConfig.ENABLE_AUTO_COMMIT_CONFIG, true);
172
173 // 自动位移提交间隔时间
174
175 props.put(ConsumerConfig.AUTO_COMMIT_INTERVAL_MS_CONFIG, 100);
176
177 // 消费组失效超时时间
178
179 props.put(ConsumerConfig.SESSION_TIMEOUT_MS_CONFIG, 10000);
180
181 // 位移丢失和位移越界后的恢复起始位置
182
183 props.put(ConsumerConfig.AUTO_OFFSET_RESET_CONFIG, "latest");
184
185 // key 和 value 的反序列化
186
187 props.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG,
188
189 "org.apache.kafka.common.serialization.StringDeserializer");
190
191 props.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG,
192
193 "org.apache.kafka.common.serialization.StringDeserializer");
194
195 return props;
196
197 }
198
199
200
201 /**
202
203 * @Description: 消费者工厂
204
205 * @return
206
207 */
208
209 @Bean
210
211 public ConsumerFactory<String, String> consumerFactory() {
212
213 return new DefaultKafkaConsumerFactory<>(consumerConfigs());
214
215 }
216
217
218 /**
219
220 * @Description: kafka 监听容器工厂
221
222 * @return
223
224 */
225
226 @Bean
227
228 public KafkaListenerContainerFactory<ConcurrentMessageListenerContainer<String, String>> kafkaListenerContainerFactory() {
229
230
231 ConcurrentKafkaListenerContainerFactory<String, String> factory = new ConcurrentKafkaListenerContainerFactory<>();
232
233 // 设置消费者工厂
234 factory.setConsumerFactory(consumerFactory());
235 // 要创建的消费者数量(10 个线程并发处理)
236 factory.setConcurrency(10);
237 return factory;
238
239 }
240
241
242
243}
244
6.swagger配置
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
2
3
4
5import org.springframework.boot.autoconfigure.condition.ConditionalOnProperty;
6
7import org.springframework.context.annotation.Bean;
8
9import org.springframework.context.annotation.Configuration;
10
11import springfox.documentation.builders.ApiInfoBuilder;
12
13import springfox.documentation.builders.PathSelectors;
14
15import springfox.documentation.builders.RequestHandlerSelectors;
16
17import springfox.documentation.service.ApiInfo;
18
19import springfox.documentation.spi.DocumentationType;
20
21import springfox.documentation.spring.web.plugins.Docket;
22
23import springfox.documentation.swagger2.annotations.EnableSwagger2;
24
25
26
27/**
28
29 * Swagger配置
30
31 * @ClassName: Swagger2Config
32
33 */
34
35@Configuration
36
37@EnableSwagger2
38
39@ConditionalOnProperty(name = "enabled", prefix = "swagger", havingValue = "true", matchIfMissing = true)
40
41public class Swagger2Config {
42
43 @Bean
44
45 public Docket docket() {
46
47 return new Docket(DocumentationType.SWAGGER_2)
48
49 .apiInfo(apiInfo())
50
51 .select()
52
53 .apis(RequestHandlerSelectors.basePackage("com"))
54
55 .paths(PathSelectors.any())
56
57 .build();
58
59 }
60
61
62
63 private ApiInfo apiInfo() {
64
65 return new ApiInfoBuilder()
66
67 .title("Springboot Swagger项目文档")
68
69 .version("1.0")
70
71 .build();
72
73 }
74
75}
76
7.消费者和生产者实体建立
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
2
3 private String groupId;
4
5 public String getGroupId() {
6
7 return groupId;
8
9 }
10
11 public void setGroupId(String groupId) {
12
13 this.groupId = groupId;
14
15 }
16
17}
18
19
20
21public class Producer {
22
23
24 private String topicName;
25
26
27 public String getTopicName() {
28
29 return topicName;
30
31 }
32
33 public void setTopicName(String topicName) {
34
35 this.topicName = topicName;
36
37 }
38
39}
40
41
8.建立发送者controller
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
2
3import org.springframework.kafka.core.KafkaTemplate;
4
5import org.springframework.kafka.support.SendResult;
6
7import org.springframework.util.concurrent.ListenableFuture;
8
9import org.springframework.util.concurrent.ListenableFutureCallback;
10
11import org.springframework.web.bind.annotation.PostMapping;
12
13import org.springframework.web.bind.annotation.RequestMapping;
14
15import org.springframework.web.bind.annotation.RestController;
16
17/**
18
19 * @Author:hemingzhu
20
21 * @date: 2019/12/31 14:38
22
23 * @Explanation:
24
25 */
26
27@RestController
28
29@RequestMapping("kafka")
30
31public class TestKafKaProducerController {
32
33 @Autowired
34
35 private KafkaTemplate<String, String> kafkaTemplate;
36
37 @PostMapping("send")
38
39 public String send(String name) {
40
41 ListenableFuture<SendResult<String, String>> future = kafkaTemplate.send("topinfo", name);
42
43 future.addCallback(new ListenableFutureCallback<SendResult<String, String>>() {
44
45 @Override
46
47 public void onSuccess(SendResult<String, String> result) {
48
49 System.out.println("生产者-发送消息成功:" + result.toString());
50
51 }
52
53 @Override
54
55 public void onFailure(Throwable ex) {
56
57 System.out.println("生产者-发送消息失败:" + ex.getMessage());
58
59 }
60
61 });
62
63 return "test-ok";
64
65 }
66
9.消费者监听器
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
2
3import org.slf4j.Logger;
4
5import org.slf4j.LoggerFactory;
6
7import org.springframework.kafka.annotation.KafkaListener;
8
9import org.springframework.stereotype.Component;
10
11/**
12
13* @date: 2019/12/31 14:39
14
15 * @Explanation:
16
17 */
18
19@Component
20
21public class KafKaConsumer {
22
23
24 private final Logger logger = LoggerFactory.getLogger(KafKaConsumer.class);
25
26 /**
27
28 * @Description: 可以同时订阅多主题,只需按数组格式即可,也就是用“,”隔开
29
30 * @param record
31
32 */
33
34 @KafkaListener(topics = { "topinfo" })
35
36 public void receive(ConsumerRecord<?, ?> record) {
37
38
39 logger.info("消费得到的消息---key: " + record.key());
40
41 logger.info("消费得到的消息---value: " + record.value().toString());
42
43
44 }
45
46}
47
