
美团点评技术沙龙由美团点评技术团队主办,每月一期。每期沙龙邀请美团点评及其它互联网公司的技术专家分享来自一线的实践经验,覆盖各主要技术领域。
目前沙龙会分别在北京、上海和厦门等地举行,要参加下一次最新沙龙活动?赶快关注微信公众号“美团点评技术团队”。
本次沙龙主要围绕数据库相关的主题,内容包括美团数据库自动化运维系统构建、点评侧MySQL自动化服务平台RDS、美团数据库中间件、和小米高级DBA带来的Redis Cluster的大规模运维实践。
讲师简介
宁龙,美团网高级DBA,现负责美团数据库自动化运维系统的架构和开发工作。
目录
今天我主要分这几个部分讲:

构建前的苦恼——一线运维DBA
首先说一下数据库运维自动化系统构建前,运维DBA都有哪些烦恼?
这是我们的一线运维DBA的小团,它每天需要对接很多的RD(Research&Development 研发)的需求。从我们现在的系统统计来看,使用我们平台系统的RD大概是一千五六百人,我们的人数是RD人数的十分之一不到。我们每个DBA对接的RD需求还是非常多的。新业务的上线,RD需要申请新的数据库集群。随着业务的发展,比如:数据库的流量大了,需要拆分了,都需要DBA手动去做。第三个是SQL的审核和上线,SQL会不会有什么问题,可能他测试环境OK,但是到了线上会有各种各样的问题。第四个是变更、升级。第五个是备份,不然的话,RD把数据写坏了,你就没地方找了,再就是帐号和安全,虚IP的维护,DNS、MySQL本身的维护,还有数据一致性,包括RD提的一些问题的排查,自身报警的处理。这就是我们一线运维的DBA,小团每天需要干很多的事情,这些事情都很重复,相信大家在座的有DBA的话,肯定是每天都会遇到我列的这些事情中的一个或多个。

构建前的苦恼——手动运维的烦恼
接下来,我们先看一下美团点评初期数据库系统的架构:一开始是两层的架构,在主从库的基础上配置读写DNS,后来引入LVS。这个两层或者三层的数据库架有什么问题呢?
比如底层的数据库做切换了,上层的DNS配置也要变更,生效到各个机房,几分钟过去了……
RD说:“这个不行,你不能这么搞,忍不了”。
所以说,这样的数据库架构在切换或者从库上下线流量的时候,都会导致业务的报错,业务接受不了。
第二个是多:重复没有成长,你让一个DBA一开始做搭建、扩容、拆分、切换,他们可能觉得很有新鲜感和成就感,但是你让他做了上百次甚至上千次之后他们觉得这个没有成长。
第三个是杂:经常被打断,有报警处理的时候需要立马处理,RD找到你说这个问题必须马上、立刻处理,所以经常在做一些事情的时候被打断,总感觉自己在做杂事。
最后一个烦:RD经常不按照规范做事,包括上线一些大SQL、慢查询。程序不加重试,在网络抖动的时候,发现数据库怎么连接断了?他就会找到你。还有一些误操作,前几天有一个RD半夜打电话跟我说,线上数据误删除了需要恢复,通过我们平台去Delete数据的话,是很好恢复的,但是他说不好意思,我通过帐号直连线上删了数据。有些明白的RD会不好意思,知道数据不好恢复;但是,有些RD会说:“你DBA就是干这个事儿的,你就是得帮我恢复数据。”
大家很郁闷,在没有自动化运维系统之前的DBA还是非常苦恼的。

构建中的坎坷和思考——1.0版系统设计之初的考虑
以上讲完了数据库运维自动化系统构建前DBA的苦恼,接下来说一说我们如果想去构建一套数据库自动化运维系统应该从哪里开始着手,我这里列的都是非常重要的。
第一个就是CMDB,如果你做的自动化系统中没有CMDB,那么,我觉得你做的自动化系统就不叫自动化系统。做自动化其实就是做标准化,这样的话,你在做自动化运维的时候,CMDB可以很方便的让你查询到信息,对业务进行合理的描述,这样的话有一个基本的地方,其实就是数据标准,我后面会说。
第二个就是你想一想在你做自动化运维系统之前,你整个公司或者RD的需求、DBA的需求,你需要做哪些自动化。美团初期只做了三个,在线DDL,数据库帐号申请和慢查询。有些RD或者DBA经常出去听一些会,比如腾讯讲蓝鲸,阿里讲鲁班,我们回去搞一套这么大的,其实没有必要,你们公司需要什么,你迫切需要的应该最先做,先把系统搭起来,再迭代。这里我给大家说个经验就是,可以先从DBA内部入手,再推广到RD。
第三个就是开发人员和成本,当时2015年初期的时候,美团App的DBA只有4个人,那时候既没有FE,也没有后台做开发的,这个时候就需要考虑到开发会有一些人员和成本的问题。会想,我是不是招一个人或者招两个人?其实没有必要,你可以放眼整个公司看一看,有没有共用的平台或者资源给你使用,这样更快,更便利的让你搭建平台。
最后就是开发形式,我们整个大的运维部是有开发人员相关资源的,我们找到他们去帮我们做一些页面,这样的话,你就会迅速的搭建你的1.0版本。
以上就是我要说的四点。

构建中的坎坷和思考——1.0版系统架构设计&使用情况
大家可以看一下我们1.0版系统的整体框图,用户就不说了,前端模块主要是Django+MVC的方式,前端开发是不懂DBA业务的,他们需要做什么事情呢?他们把用户提交的任务写到数据库的task表中,我们后台的DBA去写一些脚本,去把前端提交的任务拉出来,拉出来之后如果有日志,会反写到task表里,这就是我们1.0版的架构,非常的简单,但是也是非常的实用,右边这个图是我们1.0版的效果,其实我后来加了DML,一开始只有DDL,业务他只需要选择他所需要变更的SQL类型之后,提交到后端DB的task表。后台会有一个常驻内存的进程,扫描这个DB,去发现当前有没有需要我去执行的任务,如果有就拉出去执行,执行的过程中会有一些日志,会回填到这个DB中,前端从DB拉去日志信息,就可以展示了。当时的效果,日均的订单是1840,2015年初,公司正是快速增长期的时候,现在应该比这个稍微少一点,当时使用人数大概600人,虽然是很简单的一套架构,但是使用的人数还是非常多。

构建中的坎坷和思考——1.0版的反思
1.0版的系统做完了之后为什么做2.0版的系统呢?
不是说1.0版的系统不好,或者使用的人少,随着美团的发展你的标准化程度就慢慢得满足不了要求,所以我们会反思1.0版的一些问题,开始去做2.0版的系统。
1.0版有什么问题呢?
首先是前瞻模块重,开发人员很多,因为我们当时都是公用开发人员,开发人员很多,依赖也非常多,其实我开发习惯不太喜欢依赖什么太多的框架、组建,这样的话感觉很重,可能导致你代码的迁移、扩展性差。
第二个是没有接口化,RD不方便接入,很深刻的一个例子就是,有一个业务,他可能到某天的凌晨需要建跟时间相关的表,需要删表、建表,他每次都等到凌晨的时候去平台提交去做,他觉得很辛苦,于是就问我:“你们有没有接口让我去调,我写个脚本到那个时间就把我的表建上,因为每个时间表结构都是一样的”。如果你的平台没有接口化很不方便,特别有一些需要定期跑的业务。
第三个就是开发周期长、成本高,得跟他们沟通,需求调整复杂。当然它主要在高并发、高性能上很差,原因是什么?因为后台是一个常驻内存的进程,我当时只起了大概可能是6个线程就跑了,并发的话只能跑6个,我们2.0版的系统你想跑多少个就跑多少个,我一会儿给大家介绍一下怎么做的,不易扩展,这个也不方便扩展,后台的任务就一个,挂了就挂了,图象化做的也不好,毕竟是找人家帮我们做的,效果也不是太好。这个是我们为什么做2.0下定决心的一个原因吧!
最后就是任务的不可干预性,有一个改表操作,改到一半不想改了,这时候需要DBA上去手动操作,且不能暂停、回滚,2.0版的支持。

构建中的坎坷和思考——2.0版架构设计
随着业务的发展,1.0版系统已经不能满足我们现在的需求,我们就做了2.0版。
2.0版需要遵循三个方面:标准化、自助化、自动化。
第一个标准化,指的是:接口标准、数据标准、流程标准。接口标准。你不能说,我的平台(WEB前端)提交的是一种方式,API接口提交是另一种方式,这是不行的。数据标准,就是CMDB,一定要准,一定要实时得更新,不然整个上层,它是基石,整个上面的框架搭起来都是白费的。流程标准,你需要制定ABCD各种各样的流程,很多DBA,他有自己的方式、方法。比如说对于拆分来说,A有它的方法,B有它的方法,可能都能达到目的,但是标准化,只能用一种方式。
第二个自助化,操作自助,只要能放给RD自主操作的就自主操作。问题定位的自助,RD碰到了数据库相关的问题,不是第一时间找DBA,而是第一时间在你平台上可以看到现在数据库的状况,定位到现在数据库的问题,去操作相关业务逻辑解决问题。
第三个自动化,高可用和报警自动处理。高可用,从库宕机你可以把它剔掉;报警自动处理,对于收到报警看一眼,后台有报警自动处理的程序就给它处掉了。
这是我们需要遵循的三个化,标准化、自助化和自动化。

构建中的坎坷和思考——2.0版架构设计
介绍2.0版系统整体的架构之前,我先给大家介绍一下两个开源的组件,第一个是RabbitMQ,这是一种应用程序对应用程序的通讯方法,这个端对于另一个端的通讯,它是通过这个端来发消息,另一个端接消息,从而连接了两个端,很简单,其实他的作用就是连接消息的桥梁,美团点评现在做的O2O,就是连接人和服务,你不需要自己找,你只需要在APP上操作就行了。对于消息队列,你只需要提交到对应的队列中去就行了。

构建中的坎坷和思考——2.0版架构设计
第二个就是Celery,这个Rabbit的中文翻译是兔子,Celery翻译成中文就是芹菜,兔子和芹菜构建了我们2.0版系统。大家可以这么理解,Celery其实就是封装在消息队列上面一个非常好用的任务调度者,是基于Python开发的,他可以帮你干什么呢?可以帮你发任务,可以帮接任务,可以帮你定时的起任务,我今天凌晨2点拆分,可以白天提交,凌晨Celery帮你调度。它是对于消息中间件上面很好用的封装。

构建中的坎坷和思考——2.0版架构设计
说完了以上两个开源的组建,我们接下来说整个2.0版系统的架构,一点点的放出来,首先是用户,通过前端的Web,他的所有的操作全部打到我们的API层,业务模块:脚本也好,系统也好,也是打到我们的API层,这样做到了接口的统一,后端的处理都是一样的,不管是任何人,对于我来说都是我的一个端。
API层它可以做两个事情,比如我想查询当前数据库的主从架构情况,当前服务里的数据库列表,那么API层直接跟CMDB交互获取数据并返回。第二种是需要后台做任务的,比如搭建,扩容,拆分这些都是任务,它们需要到后台的任务管理模块去做。任务管理模块会把任务分发下去。这中间会有CMDB。任务管理模块可以详细讲一下,这个就是刚才我所说的MQ的消息管道,这里是Celery,这里有两个Celery,你可以理解为它是MQ的封装,你只需要给Celery通信就可以了。TaskControl是挂载到整个消息中间件上面的一个任务处理者。它会生成父子进程去处理任务。

构建中的坎坷和思考——2.0版架构设计
我刚才说的为什么任务是可以无限地增加,前提是在机器可以承载的情况下无限增加。第一步,TaskControl先fork出一个子进程,第二步,子进程1再fork出一个子进程,这个子进程2,是真正得做任务的进程,这个进程再调用任务执行脚本或者模块去进行任务操作。子进程1,它会把子进程2的一些信息,比如进程PID,回填到数据库里,子进程一1就退出了,子进程1退出之后,它跟子进程2的关系就断开了,这里要说一点,子进程1得忽略回收子进程,这时候子进程2就托管给了init进程,这样的话就生成了这么一个任务执行单元。任务执行单元只是需要自己去做任务,比如说它去做DDL,这个子进程2是父进程,会去做子进程的回收操作,任务日志的回填工作等。

构建中的坎坷和思考——2.0版架构设计
最后的效果大家可以看到,就是右下角这样的,这个TaskControl,每次生成父子进程完成之后,它就回去从消息队列去拿新的任务,一台机器上,好多个父子进程,并发高的时候,这些任务会有一百多个,这样的话,大大提升了整个系统的并发性,正常的话,这里起6个子进程就够了,用来监听任务,生成任务执行单元。我看有些公司会起很多很多模块去处理,用这种技巧的话,就可以让任务的执行脱离整个任务系统。
这么做还有什么好处呢?在做升级或者整个系统挂了的时候:我们直接升级好了,系统挂了也没事,任务还是不受影响。机器挂了怎么办?这个就没办法了,机器挂了确实就挂掉了,上面的任务需要重新发起,可能需要人工的干预。

构建中的坎坷和思考——2.0版功能实现案例一:集群搭建
说完了上面的整体架构之后我会给大家讲三个案例:
第一个案例是我们现有的集群的搭建过程,我先说一下我们线上跑的整体数据库的四层架构:第一层是业务层,业务层,访问我们都是通过DNS,DNS下面挂的是虚IP层,虚IP层下面会挂我们的中间件,atlas,每个机房会有并行得部署多个,最下面挂的是数据库主从架构,这个是现在美团用的线上数据库主流架构。

构建中的坎坷和思考——2.0版功能实现案例一:集群搭建
现在开始说搭建流程,我说了这么多,大家没看到我们系统的庐山真面目,这个是我们2.0版本系统的页面。对于搭建,DBA需要先点击一下服务组初始化,首先需要去创建一个服务,我们每一个DB集群在数据库里面都是有一个标识的,被称做服务组。

构建中的坎坷和思考——2.0版功能实现案例一:集群搭建
接着,需要选择你要搭建的类型,我刚才说的四层的架构是这里的A套餐,但是如果说是一些统计、运营类的库,我们可能会用到BCD套餐,后面三个套餐用的比较少。当然因为这里有四个,可能涉及到的情况非常多:有没有atlas、有没有MGW、有无DNS……可能至少得有八种情况。有时候大家做自动化的时候,就会遇到矛盾,这种情况怎么办?现在给DBA的四个套餐其实就是制定标准,就是你搭建的数据库集群,都是按照我的标准来的,只有这四种,DBA就说了:你有时候不满足我的情况,DBA就要手动去做,怎么办?

构建中的坎坷和思考——2.0版功能实现案例一:集群搭建
你的系统不能够兼容DBA的需求的时候怎么办呢?这个时候确实很麻烦,它手动运维在后面搞一搞,很有可能造成你的CMDB信息缺失等问题,这个就很麻烦。
遇到这种情况,我就告诉他们:“OK,我整个平台兼容你所有的操作”。
很简单,他说了:“我想mysql上面不挂中间件,我想直接挂MGW。”
可以。但是你得分两步做:第一步你是在平台,你先把D套餐给它搭起来,你到我们MGW和DNS里面去申请。你在这个管理功能就可以做。也就是说,做流程化或者是标准化的时候,你把流程制定出来的时候,也要考虑到灵活性,你要兼容它可能存在的所有情况,我们把线上相关的所有组件都做了管理,MGW有管理,DNS有管理,包括其他的日志都有管理,细分的管理都有,你正常情况下按我的标准、按我的流程去走,你万一涉及到特殊情况的话,你也可以在各个分组件的管理里把你想做的事情做完。这样的话,就把整个DBA或者整个ID用户都圈到你的整个平台里面来了,而不是我的平台今天只兼容一部分。这样的话,大家做自动化起来会很费劲。 因为原来也是,原来我线上会有报警校验线上CMDB的准确性,如果线上CMDB的错的话,可能非常麻烦。所以说,DBA在应对RD的时候很苦恼,我们做自动化运维开发在应对DBA的时候,也很苦恼,用这种方式就可以满足他们了。

构建中的坎坷和思考——2.0版功能实现案例一:集群搭建
在大家选完套餐之后就可以到这个界面了,做数据库运维自动化系统有很多流程性的东西,你接下来需要走哪一步,选完套餐之后让他选机器,你的监控是什么,buffer pool多大,下面会给他展示一个实时的拓扑;你要把你的用户当小白鼠,你得告诉他现在长什么样子了,不然的话他提交出错了,又回来找你。

构建中的坎坷和思考——2.0版功能实现案例一:集群搭建
第二个我们去选择atlas,根据分组选择atlas,就是数据库中间件,选择完之后就可以形成这样的图。

构建中的坎坷和思考——2.0版功能实现案例一:集群搭建
第三步就是你去申请这个虚IP和域名了,这个虚IP层正常一个机房会有一个。一个虚IP上会挂多个atlas。

构建中的坎坷和思考——2.0版功能实现案例一:集群搭建
到最后一步可能就是你需要新搭建集群的时候,需要给RD申请一个DB,申请一个帐号,让他可以访问。

构建中的坎坷和思考——2.0版功能实现案例一:集群搭建
这样形成最后一个大的JSON,让DBA去做确认,你申请的服务名称、你当前数据库的机器、中间件的机器、你的虚IP层和域名,包括你的DB,会有一个整体的拓扑图,这样的话。然后把整个的参数,所有的需要你完成这个数据库集群搭建的参数合成一个大的JSON。发到API层,API层会做参数校验,你当前搭建的参数是否满足系统的要求,如果满足要求,就会发到后台的流程引擎中,就是后台系统去做任务。做任务的时候,大家可能说,我需不需要有什么高深的语言,这个无所谓了,你可以是脚本,也可以是程序。我们现在线上,搭建的话用的还是DBA他们一开始写的搭建脚本,只需要把脚本改造一下,输入,输出标准化一下,你能够识别脚本的输出输入就行了。
大家说自动化很艰辛,很艰难。其实身边有很多的资源就是DBA手中平时做的一些脚本,有一些脚本可能DBA自己用,写的不太好。但是他本身,他是有非常大的价值的,因为他是长年累月改过的,可能第一版不行改第二版、第二版不行改第三版,他可能改了一年,他的整个脚本跑起来还是非常流利的,我们脚本搭建很稳定得跑了10个月的时间,主要的原因是因为我们DBA很靠谱,积累的很多实用的脚本。有些纯开发的人去做DBA的自动化系统,他很难理解DBA的需求,有时候DBA也讲不清楚,所以通过你做系统,他做脚本的方式去合作,真的很靠谱。因为做出来的系统是非常稳定的。

构建中的坎坷和思考——2.0版功能实现案例二:在线表变更
说完了数据库集群搭建这个案例,我们说第二个案例:在线表变更是怎么做的。首先批量的DDL或者DML打造我们的API层,我们API层会做两个事情,第一个是语法检测,语法检测有两种方式,一种是测试库,一种是sqlparser;比如,对于autoddl的create操作,你可以在测试库上建一下这个表,你就知道语法对不。或者是说alter操作,你可能先从线上把表结构拉到测试环境,在测试库上先建上,再把alter语句用到这个表上,你看alter能不能通过,这样很方便就绕过了sqlparser。
但是,在这个时候,因为在做在线的DML的时候,你是需要给用户备份的,方便用户,万一我误操作了,可以去恢复,就必须进行sqlparser。第一步:你必须把update或者delete语句改写成select,然后会去线上做查询计划,看一下explain的结果是否满足我的要求,如果不满足的话,就提示选择,不是直接拒绝掉,没有那么暴力,这个后面会说。所以说这个sqlparser,应该也是一个比较基础的难题,大家可以尝试一下在源码把这个sqlparser抽离出来,或者大家可以考虑去找一些已经开源的sqlparser。第二个就是语义的检测,是什么呢?也是标准化,就是RD提交的SQL是否满足你的要求,比如命名的要求、必须要有主键索引,而且不能有重复的索引,对于DML来说,因为对于互联网应用来说会有很多的比如说客服给我们运营人员说,我的什么什么错了,这个时候运营的人都会改这个数据库,改动一般都是一两行这种,所以我们设定一千行基本上能够满足大部分人的需求。然后在语法、语义提交通过之会到后台的提交任务,刚才所说的2.0的系统,由后台的任务执行者去执行,然后做在线的DDL。我们选择的是开源的pt-online-schema-change,这个是一个开源工具,它做操作的时候,可以做到在线改表的时候不锁表,当然还会有一些其他的问题,这里不是我们今天所说的重点,大家如果以后有遇到这个工具有什么相关的问题都可以找我们,美团还是踩了非常多的坑,有比较多的经验。

构建中的坎坷和思考——2.0版功能实现案例二:在线表变更
大家可以看看这是我们现在的在线表变更的提交页面。这里也是先选业务,选完相关的业务,你选库,选操作类型,我们这里会有一个业务高峰的描述,比如对于pt-online-schema-change在做表变更的时候,他会有一个数据拷贝的过程,所以说我们会有一个业务高峰,在业务高峰的时候RD发起的任务是不能被执行的。还有任务操作时间区间,RD也可以选,比如我选今天晚上凌晨变更或者什么时候变更都是OK的,RD把他的SQL批量粘到这里。对于在线的分表,粘一个母表就行了,下面我们自动生成带数字的语句会给他操作。这样也方便我们后台的处理,对于512的分表,我们只校验第一个语法语义就行了,不然的话,会产生很多性能问题。

构建中的坎坷和思考——2.0版功能实现案例二:在线表变更
讲到这里大家肯定会有疑问,如果你在语法检测或者语义检测出问题的时候应该怎么办?我们不是非常暴力的把RD的请求直接拒绝掉。而是在这里,给了RD一个选择:也就是说我们现在,大部分在线的表变更都是自动的,当然有一些不满足语法语义的单子,语法当然不用说了,直接报错给RD让修改,对于语义来说,有些RD说,你帮我删或者帮我改,我们可以接受延迟,这个时候我们让RD选择,你可以点继续,把这个单子发给DBA,如果DBA说能执行就可以执行了,我们的在线表变更是手自一体的。我们要把RD所有的操作,都得圈到我们的平台里去做,而不是说我语义不支持了,就找DBA手动去做。

构建中的坎坷和思考——2.0版功能实现案例二:在线表变更
这里可以看到,遇到了语法或者语义检测失败之后,我们的平台会给他报错,并会给他一个详细原因的解释,你不能说错了,而且你要直白得告诉RD为什么错了;这样的话可以提升RD的DBA能力。比如说这里长度,SQL语法问题,都会告诉他;这样的话,他可能用问一次两次,后面如果用多了,他就不会问了。

构建中的坎坷和思考——2.0版功能实现案例二:在线表变更
这个就是我们整个任务执行的一个详情的单子,就是RD在提交完任务之后在这个页面看到他任务执行的详细的信息,这上面是一些元信息,包括他提交的时间,他服务的信息,下面会有一个详细的执行日志发给他,你在做任务操作的时候,你把你的任务相关的数据实时回填到任务表里,前端只需要读这个任务表就行了。

构建中的坎坷和思考——2.0版功能实现案例三:高可用解决方案(MHA)
第三个案例是什么呢?就是我们的高可用的解决方案,上面已经列了,美团现在用的是开源的MHA,一个很牛的日本人写的。我这里大概介绍一下切换的过程,原理大家可以回去自己看,左边是我们四层的架构,我们现在整个MHA只运用于这四层的架构,如果你不是这四层的架构切换过程是不满足的。对于主从的结构这里会有监控的哨兵,比如这个哨兵他发现现在主库连不上了,这个时候,他不是说我就切换了,他是先联系其他哨兵,不能相信谣言嘛,也要先打听打听我自己的判断是不是对的,他会去联系其他几个哨兵,你们帮我看看当前主库是不是挂了,其他几个哨兵跑回来跟他说主库确实挂了,他便开始切换。
到了第2步,调MHA去做主从切换。切换完之后呢,他会通过API去改CMDB的信息,CMDB里面会描述数据库的主从的架构,描述完之后,他会去调接口,通知中间件变更主从信息,那么到3.2为止服务就恢复了。我们现在自动和手动做切换,时间都在10秒左右,如果RD程序有数据库重试的话应该是没有影响的。切换完之后会到第4步,其实这里很简单,就是告诉哨兵主从结构变了,告诉他重新监听新的主从结构就OK,这是我们现在平台去做切换的过程,大家可以借鉴一下。

构建之后的效果和后期计划——构建之后的效果
说完我们整体的1.0版的数据库自动化运维系统、2.0版的系统,以及三个案例之后我们来看一下现在整个线上构建之后的效果,以及我们后期的计划。这个统计图是一个开源组件统计的,他可以分析每天我们的一个用户量,我们每天在这个平台上跑的RD的用户量大概是在三百多。每天会有三百多RD在我们的平台上做操作,累计的RD数目大概是1461个,这些是需要跟DB打交道的RD数量。这个是我们整体平台跑的效果,你的自动化运维系统做出来之后做的怎么样?不是嘴说的,还是要有质量运营的数据。我们做质量运营,包括用户数,任务的成功率,平台的接入率,功能的覆盖率去衡量整个平台的指标。

构建之后的效果和后期计划——后期计划
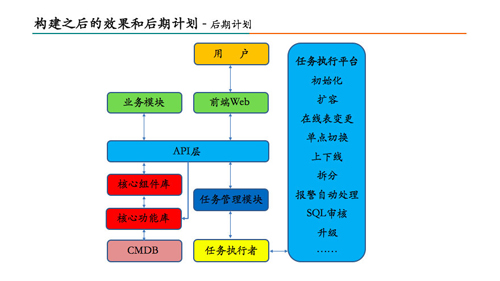
这个图,也是我们,我刚才前面已经讲过了,这个架构。我们在使用这个架构的过程中,很好用,非常好。但是也会存在一些问题,存在什么问题呢?首先这个API层,随着前端的功能越来越多,我们API会有200多个,很多很多,维护起来比较麻烦。第二个是CMDB,谁都可以去写。
第三个这个任务执行者现在用不着重,因为他现在需要处理后端的各种各样的任务,他会越来越重,DBA可能想要加一个功能,也只能找我加或者我们组内的人去加这个功能,这里能不能让DBA也参与进来

构建之后的效果和后期计划——wew后期计划
在这个做完之后我们会有一个后期的计划,我们需要把整个的架构改造成这样的,加入两个东西,一个是核心功能库和核心组件库,这两个东西包含了API基础的核心功能,包括日志,包括统计,包括权限校验都放在核心功能里,核心组件包括一些DNS组件,Atlas组件、监控都放在这里操作,API层只需要负责他的逻辑就行了。
任务执行者也是只做通用,我只帮你分发任务,帮你做任务的子进程生成,具体谁去做,去调任务执行平台去做,这样的话,我只要任务平台做的足够好,DBA或者RD只需要把你的脚本放在这个平台的下面的目录里,就能调用整个系统,这样的话非常方便,让更多的人参与你整个平台的建设、开发和改造的过程中来。
转载请注明:安全专题
