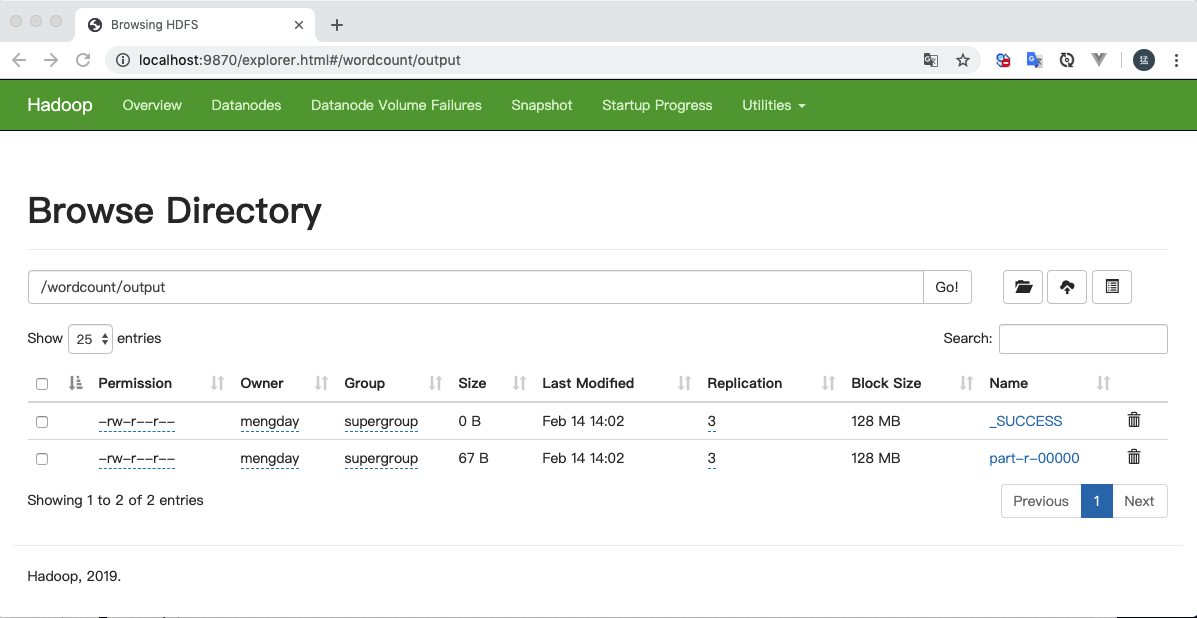
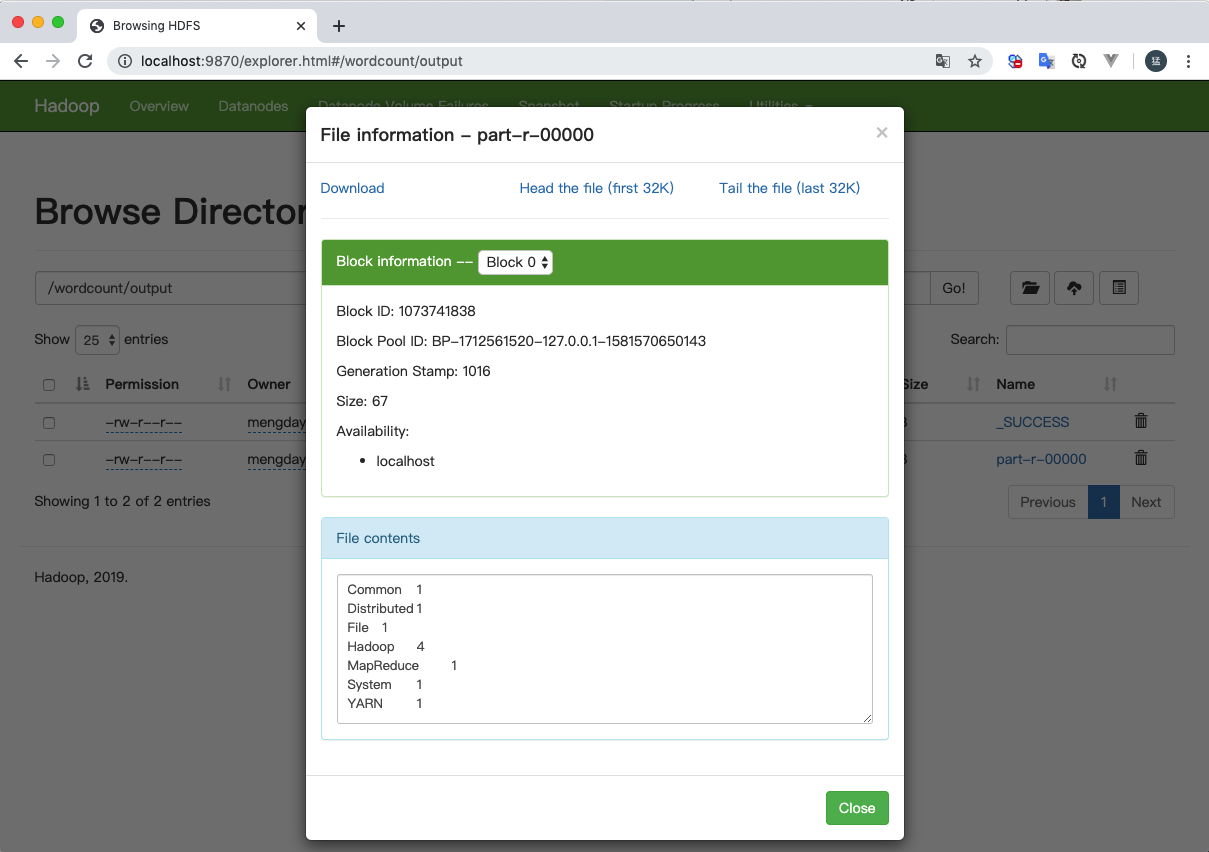
释放双眼,带上耳机,听听看~!
一:简介
MapReduce主要是先读取文件数据,然后进行Map处理,接着Reduce处理,最后把处理结果写到文件中。
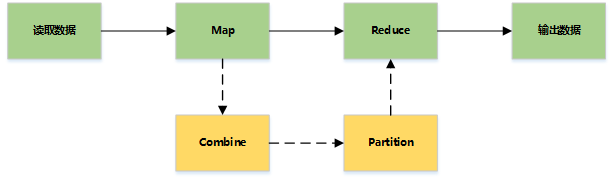
Hadoop读取数据:通过InputFormat决定读取的数据的类型,然后拆分成一个个InputSplit,每个InputSplit(输入分片)对应一个Map处理,RecordReader读取InputSplit的内容给Map
- InputFormat:输入格式,决定读取数据的格式,可以是文件或数据库等
- InputSplit: 输入分片,代表一个个逻辑分片,并没有真正存储数据,只是提供了一个如何将数据分片的方法,通常一个split就是一个block。
- RecordReader:将InputSplit拆分成一个个<key, value>对给Map处理
- Mapper:主要是读取InputSplit的每一个Key,Value对并进行处理
- Shuffle:对Map的结果进行合并、排序等操作并传输到Reduce进行处理
- Combiner:
- Reduce:对map进行统计
- select:直接分析输入数据,取出需要的字段数据即可
- where: 也是对输入数据处理的过程中进行处理,判断是否需要该数据
- aggregation: 聚合操作 min, max, sum
- group by: 通过Reducer实现
- sort:排序
- join: map join, reduce join
- 输出格式: 输出格式会转换最终的键值对并写入文件。默认情况下键和值以tab分割,各记录以换行符分割。输出格式也可以自定义。
二:准备数据
2
3
4
5
2hadoop fs -put /tmp/foobar.txt /wordcount/input
3hadoop fs -cat /wordcount/input/foobar.txt
4
5

三:Word Count
统计文件中每个单词出现的次数。
-
引入依赖
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
2 <groupId>org.apache.hadoop</groupId>
3 <artifactId>hadoop-common</artifactId>
4 <version>3.2.1</version>
5</dependency>
6
7<dependency>
8 <groupId>org.apache.hadoop</groupId>
9 <artifactId>hadoop-mapreduce-client-common</artifactId>
10 <version>3.2.1</version>
11</dependency>
12
13<dependency>
14 <groupId>org.apache.hadoop</groupId>
15 <artifactId>hadoop-mapreduce-client-core</artifactId>
16 <version>3.2.1</version>
17</dependency>
18
19
-
Java
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
2import org.apache.hadoop.fs.Path;
3import org.apache.hadoop.io.IntWritable;
4import org.apache.hadoop.io.Text;
5import org.apache.hadoop.mapreduce.Job;
6import org.apache.hadoop.mapreduce.Mapper;
7import org.apache.hadoop.mapreduce.Reducer;
8import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
9import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
10
11import java.io.IOException;
12import java.util.Iterator;
13import java.util.StringTokenizer;
14
15public class WordCount {
16
17 public static void main(String[] args) throws Exception {
18 Configuration conf = new Configuration();
19 // core-site.xml中配置的fs.defaultFS
20 conf.set("fs.defaultFS", "hdfs://localhost:8020");
21
22 Job job = Job.getInstance(conf, "word count");
23 job.setJarByClass(WordCount.class);
24 job.setMapperClass(WordCount.TokenizerMapper.class);
25 job.setReducerClass(WordCount.IntSumReducer.class);
26 job.setOutputKeyClass(Text.class);
27 job.setOutputValueClass(IntWritable.class);
28
29
30 FileInputFormat.addInputPath(job, new Path("/wordcount/input/foobar.txt"));
31 FileOutputFormat.setOutputPath(job, new Path("/wordcount/output"));
32
33 // 等待job完成后退出
34 System.exit(job.waitForCompletion(true) ? 0 : 1);
35 }
36
37
38 public static class TokenizerMapper extends Mapper<Object, Text, Text, IntWritable> {
39 private static final IntWritable one = new IntWritable(1);
40 private Text word = new Text();
41
42 /**
43 * map方法会调用多次,每行文本都会调用一次
44 * @param key
45 * @param value 每一行对应的文本
46 * @param context
47 */
48 @Override
49 public void map(Object key, Text value, Mapper<Object, Text, Text, IntWritable>.Context context) throws IOException, InterruptedException {
50 StringTokenizer itr = new StringTokenizer(value.toString());
51
52 while(itr.hasMoreTokens()) {
53 // 每个单词
54 String item = itr.nextToken();
55 this.word.set(item);
56 context.write(this.word, one);
57 }
58 }
59 }
60
61
62 public static class IntSumReducer extends Reducer<Text, IntWritable, Text, IntWritable> {
63 private IntWritable result = new IntWritable();
64
65 /**
66 * @param key 相同单词归为一组
67 * @param values 根据key分组的每一项
68 */
69 @Override
70 public void reduce(Text key, Iterable<IntWritable> values, Reducer<Text, IntWritable, Text, IntWritable>.Context context) throws IOException, InterruptedException {
71 System.out.println(key.toString());
72 int sum = 0;
73
74 Iterator iter = values.iterator();
75 while (iter.hasNext()) {
76 int value = ((IntWritable) iter.next()).get();
77 sum += value;
78 }
79
80 this.result.set(sum);
81 context.write(key, this.result);
82 }
83 }
84}
85
86
四:执行.jar
在执行jar文件时需要指定mainClass, 否则会报错 RunJar jarFile [mainClass] args…
方式一:在命令行参数中指定mainClass
指定mainClass类的完全限定名hadoop jar xxx.jar <mainClass类的完全限定名>
2
3
4
2hadoop jar target/hadoop-mapreduce-wordcount-1.0-SNAPSHOT.jar org.example.WordCount
3
4
方式二:使用maven插件指定mainClass
配置maven-jar-plugin插件, 在插件中指定mainClass,在插件中配置了mainClass在命令行中就不需要再指定mainClass了。
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
2 <plugins>
3 <plugin>
4 <groupId>org.apache.maven.plugins</groupId>
5 <artifactId>maven-jar-plugin</artifactId>
6 <configuration>
7 <archive>
8 <manifest>
9 <addClasspath>true</addClasspath>
10 <classpathPrefix></classpathPrefix>
11 <mainClass>org.example.WordCount</mainClass>
12 </manifest>
13 </archive>
14 </configuration>
15 </plugin>
16 </plugins>
17</build>
18
19
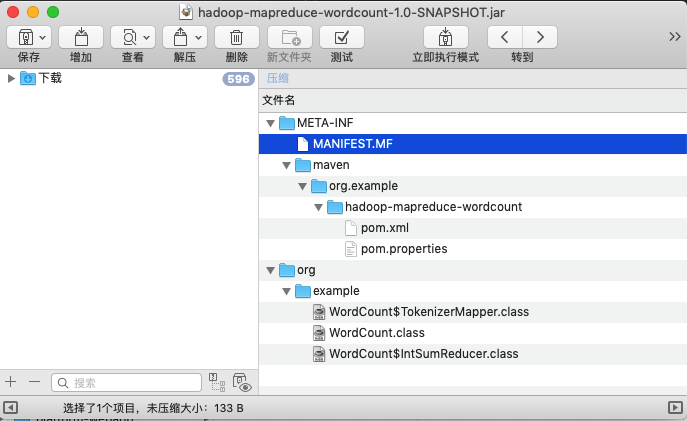
2
3
4
2hadoop jar target/hadoop-mapreduce-wordcount-1.0-SNAPSHOT.jar
3
4