一、背景
语言模型
– 在统计自然语言处理中,语言模型指的是计算一个句子的概率模型。
传统的语言模型中词的表示是原始的、面向字符串的。两个语义相似的词的字符串可能完全不同,比如“番茄”和“西红柿”。这给所有NLP任务都带来了挑战——字符串本身无法储存语义信息。该挑战突出表现在模型的平滑问题上:标注语料是有限的,而语言整体是无限的,传统模型无法借力未标注的海量语料,只能靠人工设计平滑算法,而这些算法往往效果甚微。
神经概率语言模型(Neural Probabilistic Language Model)中词的表示是向量形式、面向语义的。两个语义相似的词对应的向量也是相似的,具体反映在夹角或距离上。甚至一些语义相似的二元词组中的词语对应的向量做线性减法之后得到的向量依然是相似的。词的向量表示可以显著提高传统NLP任务的性能,例如《基于神经网络的高性能依存句法分析器》中介绍的词、词性、依存关系的向量化对正确率的提升等。
NLP(自然语言处理)里面,最细粒度的是 词语,词语组成句子,句子再组成段落、篇章、文档。所以处理 NLP 的问题,首先就要拿词语开刀。词语,是人类的抽象总结,是符号形式的(比如中文、英文、拉丁文等等),所以需要**把他们转换成数值形式,或者说——嵌入到一个数学空间里,这种嵌入方式,就叫词嵌入(word embedding)**,而 Word2vec,就是词嵌入( word embedding) 的一种。简单点来说就是把一个词语转换成对应向量的表达形式,来让机器读取数据。
**从向量的角度来看,字符串形式的词语其实是更高维、更稀疏的向量。** 若词汇表大小为N,每个字符串形式的词语字典序为i,则其被表示为一个N维向量,该向量的第i维为1,其他维都为0。汉语的词汇量大约在十万这个量级,十万维的向量对计算来讲绝对是个维度灾难。**而word2vec得到的词的向量形式(下文简称“词向量”,更学术化的翻译是“词嵌入”)则可以自由控制维度,一般是100左右。**
– word2vec作为神经概率语言模型的输入,其本身其实是神经概率模型的副产品,是为了通过神经网络学习某个语言模型而产生的中间结果。具体来说,“某个语言模型”指的是“CBOW”和“Skip-gram”。具体学习过程会用到两个降低复杂度的近似方法——Hierarchical Softmax或Negative Sampling。两个模型乘以两种方法,一共有四种实现。这些内容就是本文理论部分要详细阐明的全部了。
二、理论
1、神经网络语言模型
– 基于神经网络的分布表示又称为词向量或者词嵌入。 2001年, Bengio 等人正式提出神经网络语言模型( Neural Network Language Model ,NNLM),该模型在学习语言模型的同时,也得到了词向量。所以请注意一点:词向量可以认为是神经网络训练语言模型的副产品。
– 上面说,通过神经网络训练语言模型可以得到词向量,那么,究竟有哪些类型的神经网络语言模型呢?个人所知,大致有这么些:
a) Neural Network Language Model ,NNLM
b) Log-Bilinear Language Model, LBL
c) Recurrent Neural Network based Language Model,RNNLM
d) Collobert 和 Weston 在2008 年提出的 C&W 模型
e) Mikolov 等人提出了 CBOW( Continuous Bagof-Words)和 Skip-gram 模型
如今我们主要用到的是CBOW和Skip-gram模型。
我们来梳理一下思路,**要想得到一个词的向量表达方法,并且这个向量的维度很小,而且任意两个词之间是有联系的,可以表示出在语义层面上词语词之间的相关信息。** 我们就需要训练神经网络语言模型,即CBOW和Skip-gram模型。**这个模型的输出我们不关心,我们关心的是模型中第一个隐含层中的参数权重,这个参数矩阵就是我们需要的词向量**。**它的每一行就是词典中对应词的词向量,行数就是词典的大小。**
1.1 模型输入:
首先从语料库中搜集一系列长度为n的文本序列 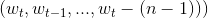 ,然后组成训练集D,我这里的理解是语料库就是我们在特定领域搜集的文本语料,同时还要有一个词典。有了训练数据和词典,下面就来看下模型是怎样进行前向传播的。
,然后组成训练集D,我这里的理解是语料库就是我们在特定领域搜集的文本语料,同时还要有一个词典。有了训练数据和词典,下面就来看下模型是怎样进行前向传播的。
这里先对单个语句序列进行计算,也可以说是单个样本,比如:其中 ,这里的V是所有单词的集合(即词典), 表示词典中的第 i 个单词。
NNLM的目标是训练如下模型:
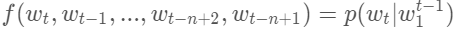
其中表示词序列中第t个单词,表示从第1个词到第t个词组成的子序列。模型需要满足的约束条件是:
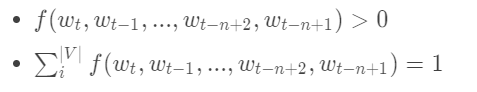
上面模型的意思是当给定一段序列时,由其前面的(t-1)个词预测第n个词的概率。
限制条件一:即是通过网络得到的每个概率值都要大于0。
而对于第二个限制条件:因为我们的神经网络模型最终得到的输出是针对每t-1个词的输入来预测下一个,也即是第t个词是什么。因此模型的实际输出是一个向量,该向量的每一个分量依次对应下一个词为词典中某个词的概率。所以|v|维的概率值中必定有一个最大的概率,而其他的概率较小。
(以上参考:https://blog.csdn.net/lilong117194/article/details/82018008 )
NNLM参考代码:
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
2import torch
3import torch.nn as nn
4import torch.optim as optim
5from torch.autograd import Variable
6
7dtype = torch.FloatTensor
8
9sentences = [ "i like dog", "i love coffee", "i hate milk"]
10
11#使用空格去分词
12word_list = " ".join(sentences).split()
13word_list = list(set(word_list))
14#获取字典
15word_dict = {w: i for i, w in enumerate(word_list)}
16number_dict = {i: w for i, w in enumerate(word_list)}
17n_class = len(word_dict) # number of Vocabulary
18print("word_dict is:", word_dict)
19print("number_dict is:", number_dict)
20# NNLM Parameter
21n_step = 2 # n-1 in paper
22n_hidden = 2 # h in paper
23m = 2 # m in paper
24
25def make_batch(sentences):
26 input_batch = []
27 target_batch = []
28#选择前两个词预测后一个词
29 for sen in sentences:
30 word = sen.split()
31 input = [word_dict[n] for n in word[:-1]]
32 target = word_dict[word[-1]]
33
34 input_batch.append(input)
35 target_batch.append(target)
36
37 return input_batch, target_batch
38
39# Model
40class NNLM(nn.Module):
41 def __init__(self):
42 super(NNLM, self).__init__()
43 self.C = nn.Embedding(n_class, m)
44 self.H = nn.Parameter(torch.randn(n_step * m, n_hidden).type(dtype))
45 self.W = nn.Parameter(torch.randn(n_step * m, n_class).type(dtype))
46 self.d = nn.Parameter(torch.randn(n_hidden).type(dtype))
47 self.U = nn.Parameter(torch.randn(n_hidden, n_class).type(dtype))
48 self.b = nn.Parameter(torch.randn(n_class).type(dtype))
49
50 def forward(self, X):
51 X = self.C(X)
52 X = X.view(-1, n_step * m) # [batch_size, n_step * n_class]
53 tanh = torch.tanh(self.d + torch.mm(X, self.H)) # [batch_size, n_hidden]
54 output = self.b + torch.mm(X, self.W) + torch.mm(tanh, self.U) # [batch_size, n_class]
55 return output
56
57model = NNLM()
58
59criterion = nn.CrossEntropyLoss()
60optimizer = optim.Adam(model.parameters(), lr=0.001)
61
62input_batch, target_batch = make_batch(sentences)
63input_batch = Variable(torch.LongTensor(input_batch))
64target_batch = Variable(torch.LongTensor(target_batch))
65
66# Training
67for epoch in range(5000):
68
69 optimizer.zero_grad()
70 output = model(input_batch)
71
72 # output : [batch_size, n_class], target_batch : [batch_size] (LongTensor, not one-hot)
73 loss = criterion(output, target_batch)
74 if (epoch + 1)%1000 == 0:
75 print('Epoch:', '%04d' % (epoch + 1), 'cost =', '{:.6f}'.format(loss))
76#反向传播,参数寻优
77 loss.backward()
78 optimizer.step()
79
80# Predict
81predict = model(input_batch).data.max(1, keepdim=True)[1]
82
83# Test
84print([sen.split()[:2] for sen in sentences], '->', [number_dict[n.item()] for n in predict.squeeze()])
85
2、Hierarchical Softmax
无论是哪种模型,其基本网络结构都是在下图的基础上,省略掉hidden layer:

模型基本结构
为什么要去掉这一层呢?据说是因为word2vec的作者嫌从hidden layer到output layer的矩阵运算太多了。于是两种模型的网络结构是:
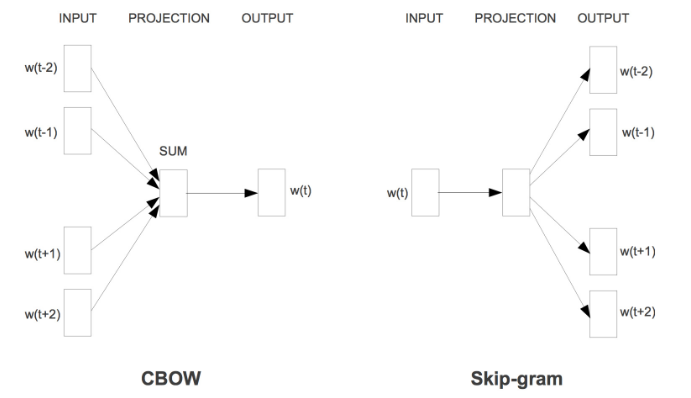
其中w(t)代表当前词语位于句子的位置t,同理定义其他记号。在窗口内(上图为窗口大小为5),除了当前词语之外的其他词语共同构成上下文。
2.1、CBOW
原理
CBOW 是 Continuous Bag-of-Words Model 的缩写,是一种根据上下文的词语预测当前词语的出现概率的模型。其图示如上图左。
CBOW是已知上下文,估算当前词语的语言模型。其学习目标是最大化对数似然函数:
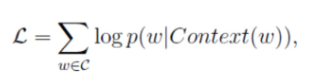
其中,w表示语料库C中任意一个词。从上图可以看出,对于CBOW,
输入层是上下文的词语的词向量(什么!我们不是在训练词向量吗?不不不,我们是在训练CBOW模型,词向量只是个副产品,确切来说,是CBOW模型的一个参数。训练开始的时候,词向量是个随机值,随着训练的进行不断被更新)。
投影层对其求和,所谓求和,就是简单的向量加法。
输出层输出最可能的w。由于语料库中词汇量是固定的|C|个,所以上述过程其实可以看做一个多分类问题。给定特征,从|C|个分类中挑一个
对于神经网络模型多分类,最朴素的做法是softmax回归:

softmax回归需要对语料库中每个词语(类)都计算一遍输出概率并进行归一化,在几十万词汇量的语料上无疑是令人头疼的。
不用softmax怎么样?比如SVM中的多分类,我们都知道其多分类是由二分类组合而来的:
这是一种二叉树结构,应用到word2vec中被作者称为Hierarchical Softmax:
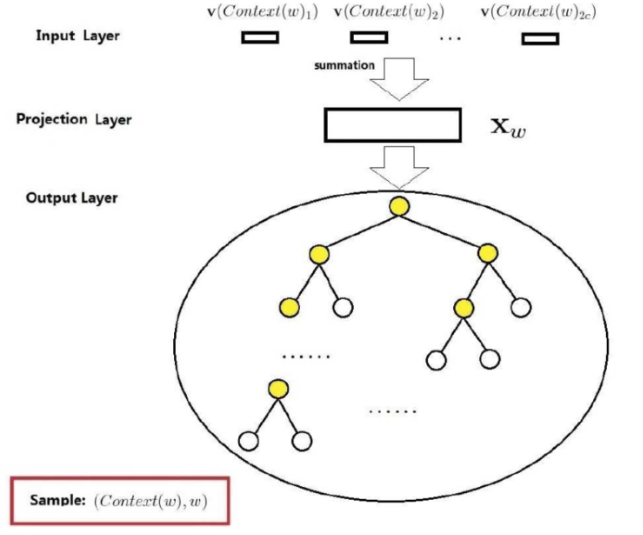
上图输出层的树形结构即为Hierarchical Softmax。
2.2、Skip-gram
原理
Skip-gram只是逆转了CBOW的因果关系而已,即已知当前词语,预测上下文。
其网络结构如下图所示:
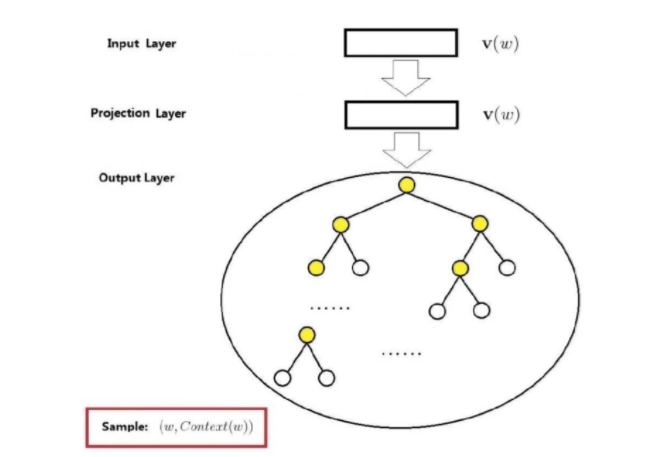
上图与CBOW的两个不同在于
输入层不再是多个词向量,而是一个词向量
投影层其实什么事情都没干,直接将输入层的词向量传递给输出层
(以上参考:http://www.hankcs.com/nlp/word2vec.html)
代码示例(skip gram):
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
2import numpy as np
3import torch
4import torch.nn as nn
5import torch.optim as optim
6from torch.autograd import Variable
7import matplotlib.pyplot as plt
8
9dtype = torch.FloatTensor
10
11# 3 Words Sentence
12sentences = [ "i like dog", "i like cat", "i like animal",
13 "dog cat animal", "apple cat dog like", "dog fish milk like",
14 "dog cat eyes like", "i like apple", "apple i hate",
15 "apple i movie book music like", "cat dog hate", "cat dog like"]
16
17word_sequence = " ".join(sentences).split()
18word_list = " ".join(sentences).split()
19word_list = list(set(word_list))
20word_dict = {w: i for i, w in enumerate(word_list)}
21
22# Word2Vec Parameter
23batch_size = 20 # To show 2 dim embedding graph
24embedding_size = 2 # To show 2 dim embedding graph
25voc_size = len(word_list)
26
27def random_batch(data, size):
28 random_inputs = []
29 random_labels = []
30 random_index = np.random.choice(range(len(data)), size, replace=False)
31
32 for i in random_index:
33 random_inputs.append(np.eye(voc_size)[data[i][0]]) # target
34 random_labels.append(data[i][1]) # context word
35
36 return random_inputs, random_labels
37
38# Make skip gram of one size window
39skip_grams = []
40for i in range(1, len(word_sequence) - 1):
41 target = word_dict[word_sequence[i]]
42 context = [word_dict[word_sequence[i - 1]], word_dict[word_sequence[i + 1]]]
43
44 for w in context:
45 skip_grams.append([target, w])
46
47# Model
48class Word2Vec(nn.Module):
49 def __init__(self):
50 super(Word2Vec, self).__init__()
51
52 # W and WT is not Traspose relationship
53 self.W = nn.Parameter(-2 * torch.rand(voc_size, embedding_size) + 1).type(dtype) # voc_size > embedding_size Weight
54 self.WT = nn.Parameter(-2 * torch.rand(embedding_size, voc_size) + 1).type(dtype) # embedding_size > voc_size Weight
55
56 def forward(self, X):
57 # X : [batch_size, voc_size]
58 hidden_layer = torch.matmul(X, self.W) # hidden_layer : [batch_size, embedding_size]
59 output_layer = torch.matmul(hidden_layer, self.WT) # output_layer : [batch_size, voc_size]
60 return output_layer
61
62model = Word2Vec()
63
64criterion = nn.CrossEntropyLoss()
65optimizer = optim.Adam(model.parameters(), lr=0.001)
66
67# Training
68for epoch in range(5000):
69
70 input_batch, target_batch = random_batch(skip_grams, batch_size)
71
72 input_batch = Variable(torch.Tensor(input_batch))
73 target_batch = Variable(torch.LongTensor(target_batch))
74
75 optimizer.zero_grad()
76 output = model(input_batch)
77
78 # output : [batch_size, voc_size], target_batch : [batch_size] (LongTensor, not one-hot)
79 loss = criterion(output, target_batch)
80 if (epoch + 1)%1000 == 0:
81 print('Epoch:', '%04d' % (epoch + 1), 'cost =', '{:.6f}'.format(loss))
82
83 loss.backward()
84 optimizer.step()
85
86for i, label in enumerate(word_list):
87 W, WT = model.parameters()
88 x,y = float(W[i][0]), float(W[i][1])
89 plt.scatter(x, y)
90 plt.annotate(label, xy=(x, y), xytext=(5, 2), textcoords='offset points', ha='right', va='bottom')
91plt.show()
92
