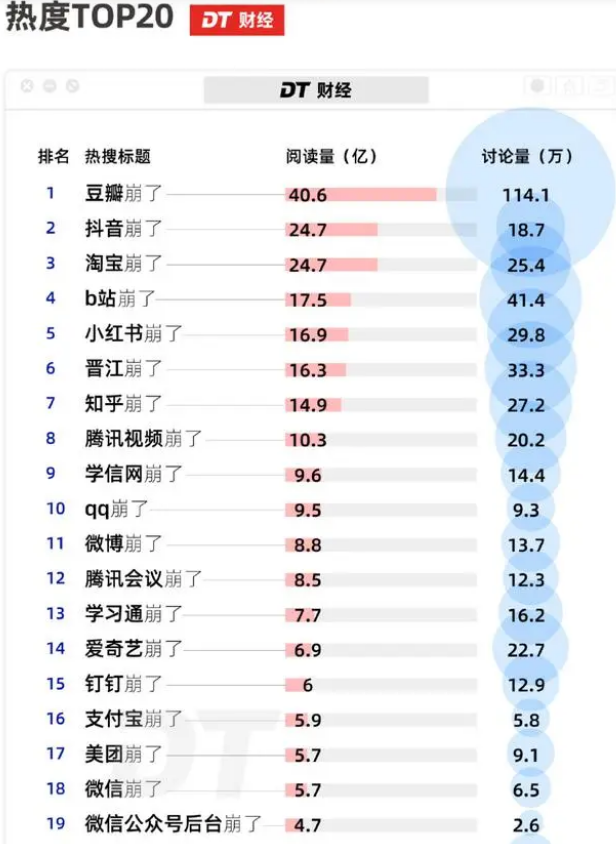
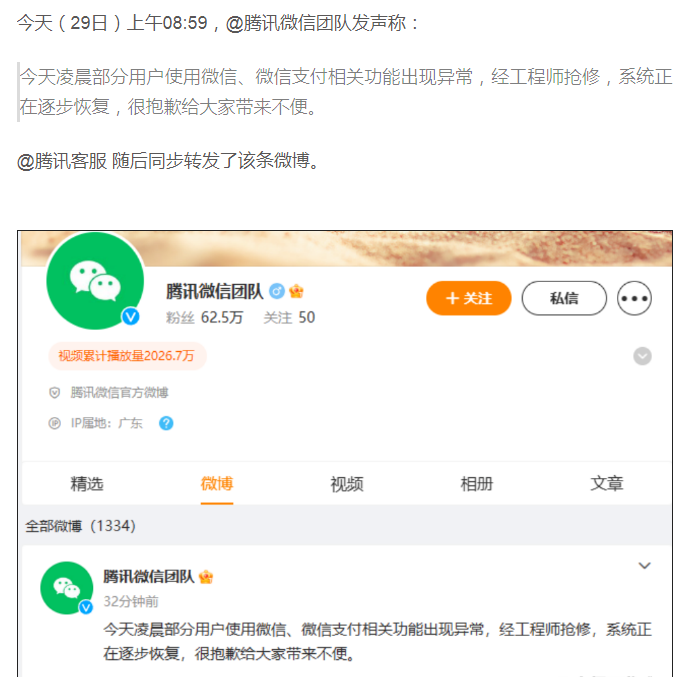
释放双眼,带上耳机,听听看~!
案例01 批量制作数据透视表
- 代码文件:批量制作数据透视表.py – 数据文件:商品销售表(文件夹)
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
import xlwings as xw
import pandas as pd
app=xw.App(visible=True,add_book=False)
file_path=r'd:\\22\商品销售表'
file_list=os.listdir(file_path)
for i in file_list:
if os.path.splitext(i)[1]=='.xlsx':
workbook=app.books.open(file_path+'\'+i)
for j in workbook.sheets:
values=j.range('A1').expand().options(pd.DataFrame).value
pivottable=pd.pivot_table(values,values='销售金额' #汇总字段为销售金额
,index='销售地区' #指定行字段为销售地区
,columns='销售分部' #列字段为销售分部
,aggfunc='sum' #汇总计算方式为求和
,fill_value=0 #缺失值填充0
,margins=True #显示汇总行列
,margins_name='总计' #数据行的名称
)
j.range('J1').value=pivottable
j.autofit()
workbook.save()
workbook.close()
app.quit()
举一反三 为一个工作簿的所有工作表制作数据透视表
- 代码文件:为一个工作簿的所有工作表制作数据透视表.py – 数据文件:商品销售表.xlsx
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
import xlwings as xw
import pandas as pd
app=xw.App(visible=True,add_book=False)
workbook=app.books.open(r'd:\22\商品销售表.xlsx')
for i in workbook.sheets:
values=i.range('A1').expand().options(pd.DataFrame).value
pivottable=pd.pivot_table(values,values='销售金额' #汇总字段为销售金额
,index='销售地区' #指定行字段为销售地区
,columns='销售分部' #列字段为销售分部
,aggfunc='sum' #汇总计算方式为求和
,fill_value=0 #缺失值填充0
,margins=True #显示汇总行列
,margins_name='总计' #数据行的名称
)
i.range('J1').value=pivottable
i.autofit()
workbook.save()
workbook.close()
app.quit()
案例02 使用方差分析对比数据的差异
- 代码文件:使用方差分析对比数据的差异.py – 数据文件:方差分析.xlsx
在Python中做方差分析,要用到与方差分析相关的statsmodels.formula.api模块和statsmodels.stats.anova模块,以及ols()函数和anova_lm()函数。下面一起来看看具体的代码。
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
from statsmodels.formula.api import ols #导入方差分析的模块
from statsmodels.stats.anova import anova_lm
import xlwings as xw
df=pd.read_excel(r'd:\22\方差分析.xlsx')
df=df[['A型号','B型号','C型号','D型号','E型号']] #选取ABCDE的型号的列作为分析
df_melt=df.melt() #将列名转换成列数据
df_melt.columns=['Treat','Value'] #重命名列名
df_describe=pd.DataFrame()
df_describe['A型号']=df['A型号'].describe() #计算A型号的平均值、最大值、最小值
df_describe['B型号']=df['B型号'].describe() #计算A型号的平均值、最大值、最小值
df_describe['C型号']=df['C型号'].describe() #计算A型号的平均值、最大值、最小值
df_describe['D型号']=df['D型号'].describe() #计算A型号的平均值、最大值、最小值
df_describe['E型号']=df['E型号'].describe() #计算A型号的平均值、最大值、最小值
print(df_describe)
model=ols('Value~C(Treat)',data=df_melt).fit() #对样本数据进行最小二乘现行拟合计算
anova_table=anova_lm(model,typ=3) #对样本进行方差分析
print(model)
print(anova_table)
app=xw.App(visible=True,add_book=False)
workbook=app.books.open(r'C:\Users\Administrator\Desktop\22\方差分析.xlsx')
worksheet=workbook.sheets['单因素方差分析'] #选中工作表‘单因素方差分析’
worksheet.range('H2').value=df_describe.T #将计算出的平均值、最小值、最大值等数据xieru
worksheet.range('H14').value='方差分析'
worksheet.range('H15').value=anova_table #将方差分析的结果写入工作表
workbook.save()
workbook.close()
app.quit()
知识延伸
- 第7行代码中的melt()是pandas模块中DataFrame对象的函数,用于将列名转换为列数据,效果如下图所示,以满足后续使用的ols()函数对数据结构的要求。- 第10~14行代码中的describe()是pandas模块中DataFrame对象的函数,用于总结数据集分布的集中趋势,生成描述性统计数据。该函数的语法格式和常用参数含义如下。-
第15行代码中的ols()是statsmodels.formula.api模块中的函数,用于对数据进行最小二乘线性拟合计算。该函数的语法格式和常用参数含义如下。
- 第16行代码中的anova_lm()是statsmodels.stats.anova模块中的函数,用于对数据进行方差分析并输出结果。该函数的语法格式和常用参数含义如下。
举一反三 绘制箱形图识别异常值
- 代码文件:绘制箱形图识别异常值.py – 数据文件:方差分析.xlsx
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
import matplotlib.pyplot as plt
from statsmodels.formula.api import ols #导入方差分析的模块
from statsmodels.stats.anova import anova_lm
import xlwings as xw
df=pd.read_excel(r'd:\\22\方差分析.xlsx')
df=df[['A型号','B型号','C型号','D型号','E型号']] #选取ABCDE的型号的列作为分析
figure=plt.figure()
plt.rcParams['font.sans-serif']=['SimHei']
df.boxplot(grid=False)
app=xw.App(visible=True,add_book=False)
workbook=app.books.open(r'C:\Users\Administrator\Desktop\22\方差分析.xlsx')
worksheet=workbook.sheets['单因素方差分析'] #选中工作表‘单因素方差分析’
worksheet.pictures.add(figure,name='图片1',update=True,left=500,top=10)
workbook.save('箱型图.xlsx')
workbook.close()
app.quit()

案例03 使用描述统计和直方图制定目标
- 代码文件:使用描述统计和直方图制定目标.py – 数据文件:描述统计.xlsx
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
import matplotlib.pyplot as plt
import xlwings as xw
#构造月销售额数据列
df=pd.read_excel(r'C:\Users\Administrator\Desktop\22\描述统计.xlsx')
df.columns=['序号','员工姓名','月销售额'] #重命名数据列
df=df.drop(columns=['序号','员工姓名']) #删除序号和员工姓名列
df_describe=df.astype('float').describe() #对月销售额数据进行描述性统计
df_cut=pd.cut(df['月销售额'],bins=7,precision=2) #将月销售额分成7个区间
cut_count=df['月销售额'].groupby(df_cut).count() #统计各区间的个数
df_all=pd.DataFrame() #创建一个空的DateFrame用于汇总数据
df_all['计数']=cut_count
df_all_new=df_all.reset_index() #将索引重置
df_all_new['月销售额']=df_all_new['月销售额'].apply(lambda x:str(x)) #将月销售额转换成字符串类型
#绘图
fig=plt.figure() #创建绘图窗口
plt.rcParams['font.sans-serif']=['SimHei'] #解决中文乱码问题
n,bins,patches=plt.hist(df['月销售额'],bins=7,edgecolor='black',linewidth=0.5)
plt.xticks(bins) #将直方图x轴的刻度标签设置为各区间的端点值
plt.title('月度销售额频率分析') #标题
plt.xlabel('月销售额') #x轴标题
plt.ylabel('频数') #y轴标题
#将图放进表里
app=xw.App(visible=True,add_book=False)
workbook=app.books.open(r'C:\Users\Administrator\Desktop\22\描述统计.xlsx')
worksheet=workbook.sheets['业务员销售额统计表'] #选中工作表‘单因素方差分析’
worksheet.range('E2').value=df_describe #将描述性统计数据写入表中
worksheet.range('H2').value=df_all_new #将分类后的表写入表中
worksheet.pictures.add(fig,name='图片1',update=True,left=400,top=200)
worksheet.autofit()
workbook.save(r'C:\Users\Administrator\Desktop\22\描述统计-直方图.xlsx')
workbook.close()
app.quit()
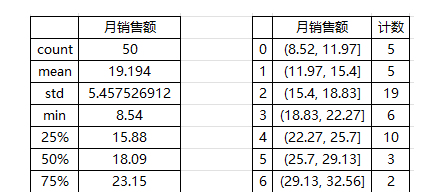
描述统计数据中几个比较重要的值分别为平均值(mean)19.194、标准差(std)5.46、中位数(50%)18.09、最小值8.54、最大值32.56。在工作簿中还可以看到如下图所示的直方图,根据直方图可以看出,月销售额基本上以18为基数向两边递减,即18最普遍。
知识延伸
- 第8行代码中的cut()是pandas模块中的函数,用于对数据进行离散化处理,也就是将数据从最大值到最小值进行等距划分。该函数的语法格式和常用参数含义如下。
- 第12行代码中的reset_index()是pandas模块中DataFrame对象的函数,用于重置DataFrame对象的索引。在3.5.1节中曾简单介绍过reset_index()函数的用法,这里再详细介绍一下该函数的语法格式和常用参数含义。
- 第14行代码中的figure()是matplotlib.pyplot模块中的函数,用于创建一个绘图窗口。在3.7.2节中曾使用过figure()函数,这里再详细介绍一下该函数的语法格式和常用参数含义。- 第16行代码中的hist()是Matplotlib模块中的函数,用于绘制直方图。该函数的语法格式和常用参数含义如下。
举一反三 使用自定义区间绘制直方图
- 代码文件:使用自定义区间绘制直方图.py – 数据文件:描述统计.xlsx
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
import matplotlib.pyplot as plt
import xlwings as xw
#构造月销售额数据列
df=pd.read_excel(r'C:\Users\Administrator\Desktop\22\描述统计.xlsx')
df.columns=['序号','员工姓名','月销售额'] #重命名数据列
df=df.drop(columns=['序号','员工姓名']) #删除序号和员工姓名列
df_describe=df.astype('float').describe() #对月销售额数据进行描述性统计
df_cut=pd.cut(df['月销售额'],bins=range(8,37,4)) #将月销售额分成7个区间
cut_count=df['月销售额'].groupby(df_cut).count() #统计各区间的个数
df_all=pd.DataFrame() #创建一个空的DateFrame用于汇总数据
df_all['计数']=cut_count
df_all_new=df_all.reset_index() #将索引重置
df_all_new['月销售额']=df_all_new['月销售额'].apply(lambda x:str(x)) #将月销售额转换成字符串类型
#绘图
fig=plt.figure() #创建绘图窗口
plt.rcParams['font.sans-serif']=['SimHei'] #解决中文乱码问题
n,bins,patches=plt.hist(df['月销售额'],bins=range(8,37,4),edgecolor='black',linewidth=0.5)
plt.xticks(bins) #将直方图x轴的刻度标签设置为各区间的端点值
plt.title('月度销售额频率分析') #标题
plt.xlabel('月销售额') #x轴标题
plt.ylabel('频数') #y轴标题
#将图放进表里
app=xw.App(visible=True,add_book=False)
workbook=app.books.open(r'C:\Users\Administrator\Desktop\22\描述统计.xlsx')
worksheet=workbook.sheets['业务员销售额统计表'] #选中工作表‘单因素方差分析’
worksheet.range('E2').value=df_describe #将描述性统计数据写入表中
worksheet.range('H2').value=df_all_new #将分类后的表写入表中
worksheet.pictures.add(fig,name='图片1',update=True,left=400,top=200)
worksheet.autofit()
workbook.save(r'C:\Users\Administrator\Desktop\22\描述统计-直方图2.xlsx')
workbook.close()
app.quit()
