整理总结了一些常用分析网站的命令方便大家快速定位故障所在排除故障,最小化的减少故障给业务带来的影响。
1. 背景
有时候会遇到一些疑难杂症,并且监控插件并不能一眼立马发现问题的根源。这时候就需要登录服务器进一步深入分析问题的根源。那么分析问题需要有一定的技术经验积累,并且有些问题涉及到的领域非常广,才能定位到问题。所以,分析问题和踩坑是非常锻炼一个人的成长和提升自我能力。如果我们有一套好的分析工具,那将是事半功倍,能够帮助大家快速定位问题,节省大家很多时间做更深入的事情。
2. 说明
本篇文章主要介绍各种问题定位的工具以及会结合案例分析问题。
3. 分析问题的方法论
套用5W2H方法,可以提出性能分析的几个问题
- What-现象是什么样的
- When-什么时候发生
- Why-为什么会发生
- Where-哪个地方发生的问题
- How much-耗费了多少资源
- How to do-怎么解决问题
4. cpu
4.1 说明
针对应用程序,我们通常关注的是内核CPU调度器功能和性能。
线程的状态分析主要是分析线程的时间用在什么地方,而线程状态的分类一般分为:
- on-CPU:执行中,执行中的时间通常又分为用户态时间user和系统态时间sys。
- off-CPU:等待下一轮上CPU,或者等待I/O、锁、换页等等,其状态可以细分为可执行、匿名换页、睡眠、锁、空闲等状态。
如果大量时间花在CPU上,对CPU的剖析能够迅速解释原因;如果系统时间大量处于off-cpu状态,定位问题就会费时很多。但是仍然需要清楚一些概念:
- 处理器
- 核
- 硬件线程
- CPU内存缓存
- 时钟频率
- 每指令周期数CPI和每周期指令数IPC
- CPU指令
- 使用率
- 用户时间/内核时间
- 调度器
- 运行队列
- 抢占
- 多进程
- 多线程
- 字长
4.2 分析工具
| 工具 | 描述 |
|---|---|
| uptime | 平均负载 |
| vmstat | 包括系统范围的cpu平均负载 |
| mpstat | 查看所有cpu核信息 |
| top | 监控每个进程cpu用量 |
| sar -u | 查看cpu信息 |
| pidstat | 每个进程cpu用量分解 |
| perf | cpu剖析和跟踪,性能计数分析 |
- uptime,vmstat,mpstat,top,pidstat 只能查询到cpu及负载的的使用情况。
- perf可以跟着到进程内部具体函数耗时情况,并且可以指定内核函数进行统计,指哪打哪。
4.3 使用方式
2
3
4
5
6
7
8
9
10
11
12
13
14
top
//查看所有cpu核信息
mpstat -P ALL 1
//查看cpu使用情况以及平均负载
vmstat 1
//进程cpu的统计信息
pidstat -u 1 -p pid
//跟踪进程内部函数级cpu使用情况
perf top -p pid -e cpu-clock
5. 内存
5.1 说明
内存是为提高效率而生,实际分析问题的时候,内存出现问题可能不只是影响性能,而是影响服务或者引起其他问题。同样对于内存有些概念需要清楚:
- 主存
- 虚拟内存
- 常驻内存
- 地址空间
- OOM
- 页缓存
- 缺页
- 换页
- 交换空间
- 交换
- 用户分配器libc、glibc、libmalloc和mtmalloc
- LINUX内核级SLUB分配器
5.2 分析工具
| 工具 | 描述 |
|---|---|
| free | 缓存容量统计信息 |
| vmstat | 虚拟内存统计信息 |
| top | 监视每个进程的内存使用情况 |
| pidstat | 显示活动进程的内存使用统计 |
| pmap | 查看进程的内存映像信息 |
| sar -r | 查看内存 |
| dtrace | 动态跟踪 |
| valgrind | 分析程序性能及程序中的内存泄露错误 |
作者:阳光小蚂蚁
链接:https://www.jianshu.com/p/1e83539875e5
来源:简书
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
说明:
- free,vmstat,top,pidstat,pmap只能统计内存信息以及进程的内存使用情况。
- valgrind 可以分析内存泄漏问题。
- dtrace 动态跟踪。需要对内核函数有很深入的了解,通过D语言编写脚本完成跟踪。
5.3 使用方式
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
free -m
//虚拟内存统计信息
vmstat 1
//查看系统内存情况
top
//1s采集周期,获取内存的统计信息
pidstat -p pid -r 1
//查看进程的内存映像信息
pmap -d pid
//检测程序内存问题
valgrind --tool=memcheck --leak-check=full --log-file=./log.txt ./程序名
利用 ls 查看文件大小
ls -lh
du -sh *
df -h
在一次OOM发生后立刻抓取内存快照,需要执行命令的用户与JAVA进程启动用户是同一个,否则会有异常:
/data/program/jdk/bin/jmap -dump:live,format=b,file=/home/www/jmaplogs/jmap-8001-2.bin 18760
ps -ef|grep store.cn.xml|grep -v grep|awk '{print $2}'|xargs /data/program/jdk-1.8.0_11/bin/jmap -dump:live,format=b,file=api.bin
使用Memory Analyzer解析dump文件,发现有很明显的内存泄漏提示。
2.2.5.1 JVM内存
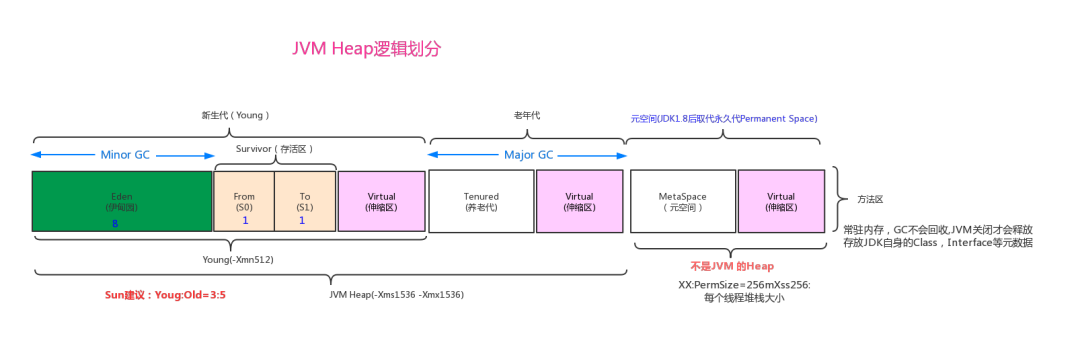
2.2.5.2 内存分配的流程
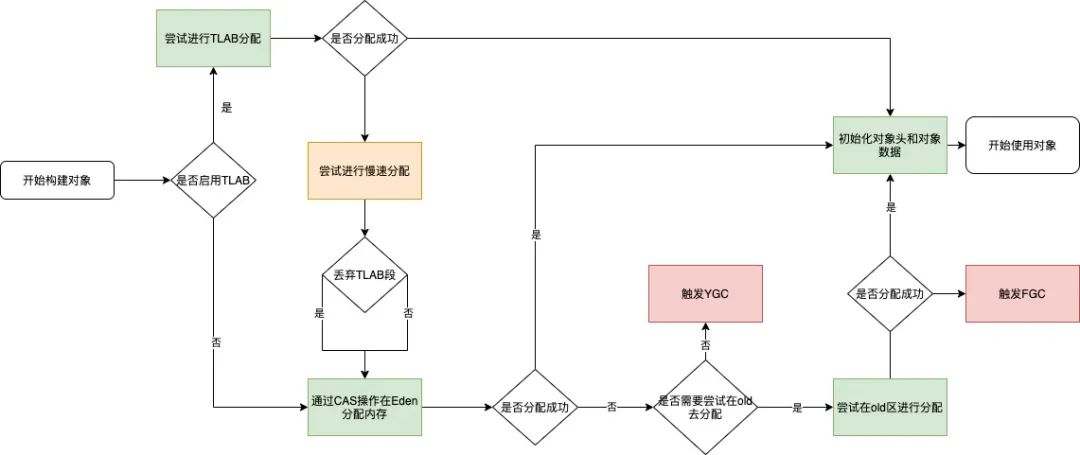
如果通过逃逸分析,则会先在TLAB分配,如果不满足条件才在Eden上分配。
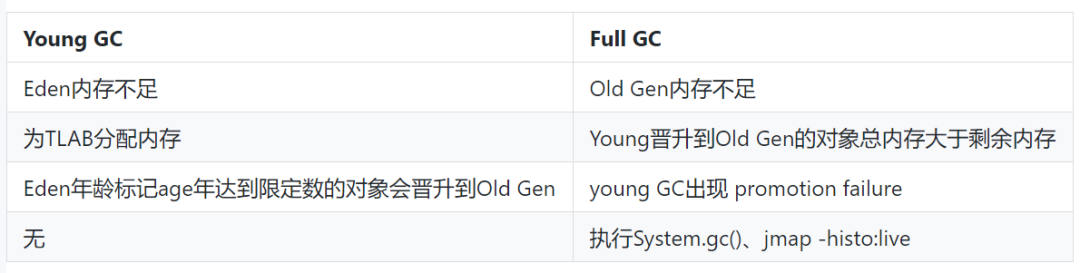
2.2.4.3 GC

(1)GC触发的场景
6. 磁盘IO
6.1 说明
磁盘通常是计算机最慢的子系统,也是最容易出现性能瓶颈的地方,因为磁盘离 CPU 距离最远而且 CPU 访问磁盘要涉及到机械操作,比如转轴、寻轨等。访问硬盘和访问内存之间的速度差别是以数量级来计算的,就像1天和1分钟的差别一样。要监测 IO 性能,有必要了解一下基本原理和 Linux 是如何处理硬盘和内存之间的 IO 的。
在理解磁盘IO之前,同样我们需要理解一些概念,例如:
- 文件系统
- VFS
- 文件系统缓存
- 页缓存page cache
- 缓冲区高速缓存buffer cache
- 目录缓存
- inode
- inode缓存
- noop调用策略
6.2 分析工具
| 工具 | 描述 |
|---|---|
| iostat | 磁盘详细统计信息 |
| iotop | 按进程查看磁盘IO的使用情况 |
| pidstat | 按进程查看磁盘IO的使用情况 |
| perf | 动态跟踪工具 |
6.3 使用方式
2
3
4
5
6
7
8
9
10
11
12
13
iotop
//统计io详细信息
iostat -d -x -k 1 10
//查看进程级io的信息
pidstat -d 1 -p pid
//查看系统IO的请求,比如可以在发现系统IO异常时,可以使用该命令进行调查,就能指定到底是什么原因导致的IO异常
perf record -e block:block_rq_issue -ag
^C
perf report
7. 网络
7.1 说明
网络的监测是所有 Linux 子系统里面最复杂的,有太多的因素在里面,比如:延迟、阻塞、冲突、丢包等,更糟的是与 Linux 主机相连的路由器、交换机、无线信号都会影响到整体网络并且很难判断是因为 Linux 网络子系统的问题还是别的设备的问题,增加了监测和判断的复杂度。现在我们使用的所有网卡都称为自适应网卡,意思是说能根据网络上的不同网络设备导致的不同网络速度和工作模式进行自动调整。
7.2 分析工具
| 工具 | 描述 |
|---|---|
| ping | 主要透过 ICMP 封包 来进行整个网络的状况报告 |
| traceroute | 用来检测发出数据包的主机到目标主机之间所经过的网关数量的工具 |
| netstat | 用于显示与IP、TCP、UDP和ICMP协议相关的统计数据,一般用于检验本机各端口的网络连接情况 |
| ss | 可以用来获取socket统计信息,而且比netstat更快速更高效 |
| host | 可以用来查出某个主机名的 IP,跟nslookup作用一样 |
| tcpdump | 是以包为单位进行输出的,阅读起来不是很方便 |
| tcpflow | 是面向tcp流的, 每个tcp传输会保存成一个文件,很方便的查看 |
| sar -n DEV | 网卡流量情况 |
| sar -n SOCK | 查询网络以及tcp,udp状态信息 |
7.3 使用方式
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
netstat -s
//显示当前UDP连接状况
netstat -nu
//显示UDP端口号的使用情况
netstat -apu
//统计机器中网络连接各个状态个数
netstat -a | awk '/^tcp/ {++S[$NF]} END {for(a in S) print a, S[a]}'
//显示TCP连接
ss -t -a
//显示sockets摘要信息
ss -s
//显示所有udp sockets
ss -u -a
//tcp,etcp状态
sar -n TCP,ETCP 1
//查看网络IO
sar -n DEV 1
//抓包以包为单位进行输出
tcpdump -i eth1 host 192.168.1.1 and port 80
//抓包以流为单位显示数据内容
tcpflow -cp host 192.168.1.1
netstat -nap | grep SYN_RECV
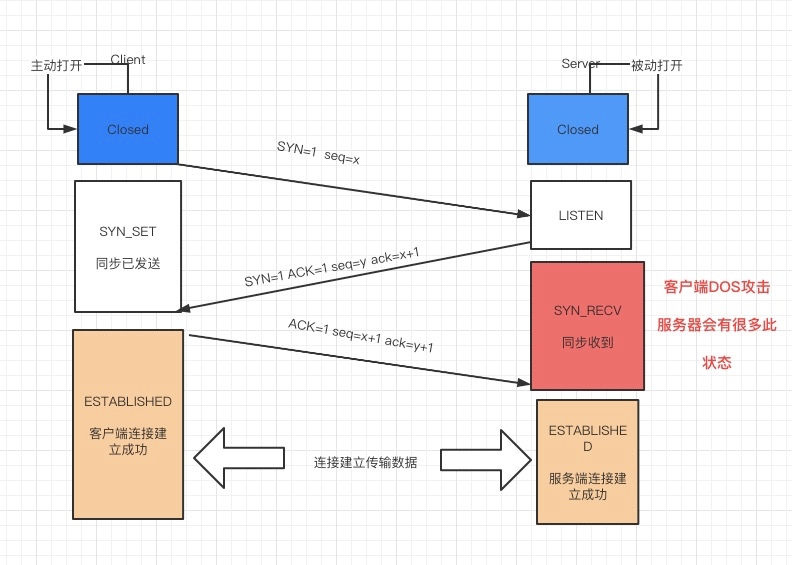
8. 系统负载
8.1 说明
Load 就是对计算机干活多少的度量(WikiPedia:the system Load is a measure of the amount of work that a compute system is doing)简单的说是进程队列的长度。Load Average 就是一段时间(1分钟、5分钟、15分钟)内平均Load。
8.2 分析工具
| 工具 | 描述 |
|---|---|
| top | 查看系统负载情况 |
| uptime | 查看系统负载情况 |
| strace | 统计跟踪内核态信息 |
| vmstat | 查看负载情况 |
| dmesg | 查看内核日志信息 |
8.3 使用方式
2
3
4
5
6
7
8
9
10
11
12
13
14
15
uptime
top
vmstat
//统计系统调用耗时情况
strace -c -p pid
//跟踪指定的系统操作例如epoll_wait
strace -T -e epoll_wait -p pid
//查看内核日志信息
dmesg
利用top查到占用cpu最高的进程pid为14,结果图如下:

查找问题线程
利用 top -H -p 查看进程内占用cpu最高线程,从下图可知,问题线程主要是activeCpu Thread,其pid为417。

查询线程详细信息
- 首先利用 printf “%x \n” 将tid换为十六进制:xid。
- 再利用 jstack | grep nid=0x -A 10 查询线程信息(若进程无响应,则使用 jstack -f ),信息如下:

9. 火焰图
9.1 说明
火焰图(Flame Graph是 Bredan Gregg 创建的一种性能分析图表,因为它的样子近似 ?而得名。
火焰图主要是用来展示 CPU的调用栈。
y 轴表示调用栈,每一层都是一个函数。调用栈越深,火焰就越高,顶部就是正在执行的函数,下方都是它的父函数。
x 轴表示抽样数,如果一个函数在 x 轴占据的宽度越宽,就表示它被抽到的次数多,即执行的时间长。注意,x 轴不代表时间,而是所有的调用栈合并后,按字母顺序排列的。
火焰图就是看顶层的哪个函数占据的宽度最大。只要有”平顶”(plateaus),就表示该函数可能存在性能问题。颜色没有特殊含义,因为火焰图表示的是 CPU 的繁忙程度,所以一般选择暖色调。
常见的火焰图类型有 On-CPU、Off-CPU、Memory、Hot/Cold、Differential等等。
9.2 安装依赖库
2
3
4
5
6
7
8
9
10
11
yum install systemtap systemtap-runtime
//内核调试库必须跟内核版本对应,例如:uname -r 2.6.18-308.el5
kernel-debuginfo-2.6.18-308.el5.x86_64.rpm
kernel-devel-2.6.18-308.el5.x86_64.rpm
kernel-debuginfo-common-2.6.18-308.el5.x86_64.rpm
//安装内核调试库
debuginfo-install --enablerepo=debuginfo search kernel
debuginfo-install --enablerepo=debuginfo search glibc
9.3 安装
2
cd quick_location
9.4 CPU级别火焰图
cpu占用过高,或者使用率提不上来,你能快速定位到代码的哪块有问题吗?
一般的做法可能就是通过日志等方式去确定问题。现在我们有了火焰图,能够非常清晰的发现哪个函数占用cpu过高,或者过低导致的问题。
9.4.1 on-CPU
cpu占用过高,执行中的时间通常又分为用户态时间user和系统态时间sys。
使用方式:
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
sh ngx_on_cpu_u.sh pid
//进入结果目录
cd ngx_on_cpu_u
//on-CPU kernel
sh ngx_on_cpu_k.sh pid
//进入结果目录
cd ngx_on_cpu_k
//开一个临时端口8088
python -m SimpleHTTPServer 8088
//打开浏览器输入地址
127.0.0.1:8088/pid.svg
DEMO:
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
#include <stdlib.h>
void foo3()
{
}
void foo2()
{
int i;
for(i=0 ; i < 10; i++)
foo3();
}
void foo1()
{
int i;
for(i = 0; i< 1000; i++)
foo3();
}
int main(void)
{
int i;
for( i =0; i< 1000000000; i++) {
foo1();
foo2();
}
}
DEMO火焰图:

9.4.2 off-CPU
cpu过低,利用率不高。等待下一轮CPU,或者等待I/O、锁、换页等等,其状态可以细分为可执行、匿名换页、睡眠、锁、空闲等状态。
使用方式:
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
sh ngx_off_cpu_u.sh pid
//进入结果目录
cd ngx_off_cpu_u
//off-CPU kernel
sh ngx_off_cpu_k.sh pid
//进入结果目录
cd ngx_off_cpu_k
//开一个临时端口8088
python -m SimpleHTTPServer 8088
//打开浏览器输入地址
127.0.0.1:8088/pid.svg
官网DEMO:

9.5 内存级别火焰图
如果线上程序出现了内存泄漏,并且只在特定的场景才会出现。这个时候我们怎么办呢?有什么好的方式和工具能快速的发现代码的问题呢?同样内存级别火焰图帮你快速分析问题的根源。
使用方式:
2
3
4
5
6
7
8
9
10
//进入结果目录
cd ngx_on_memory
//开一个临时端口8088
python -m SimpleHTTPServer 8088
//打开浏览器输入地址
127.0.0.1:8088/pid.svg
官网DEMO:

9.6 性能回退-红蓝差分火焰图
你能快速定位CPU性能回退的问题么?如果你的工作环境非常复杂且变化快速,那么使用现有的工具是来定位这类问题是很具有挑战性的。当你花掉数周时间把根因找到时,代码已经又变更了好几轮,新的性能问题又冒了出来。主要可以用到每次构建中,每次上线做对比看,如果损失严重可以立马解决修复。
通过抓取了两张普通的火焰图,然后进行对比,并对差异部分进行标色:红色表示上升,蓝色表示下降。差分火焰图是以当前(“修改后”)的profile文件作为基准,形状和大小都保持不变。因此你通过色彩的差异就能够很直观的找到差异部分,且可以看出为什么会有这样的差异。
使用方式:
2
3
4
5
6
7
8
9
10
11
12
13
14
//抓取代码修改前的profile 1文件
perf record -F 99 -p pid -g -- sleep 30
perf script > out.stacks1
//抓取代码修改后的profile 2文件
perf record -F 99 -p pid -g -- sleep 30
perf script > out.stacks2
//生成差分火焰图:
./FlameGraph/stackcollapse-perf.pl ../out.stacks1 > out.folded1
./FlameGraph/stackcollapse-perf.pl ../out.stacks2 > out.folded2
./FlameGraph/difffolded.pl out.folded1 out.folded2 | ./FlameGraph/flamegraph.pl > diff2.svg
DEMO:
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
#include <stdio.h>
#include <stdlib.h>
void foo3()
{
}
void foo2()
{
int i;
for(i=0 ; i < 10; i++)
foo3();
}
void foo1()
{
int i;
for(i = 0; i< 1000; i++)
foo3();
}
int main(void)
{
int i;
for( i =0; i< 1000000000; i++) {
foo1();
foo2();
}
}
//test1.c
#include <stdio.h>
#include <stdlib.h>
void foo3()
{
}
void foo2()
{
int i;
for(i=0 ; i < 10; i++)
foo3();
}
void foo1()
{
int i;
for(i = 0; i< 1000; i++)
foo3();
}
void add()
{
int i;
for(i = 0; i< 10000; i++)
foo3();
}
int main(void)
{
int i;
for( i =0; i< 1000000000; i++) {
foo1();
foo2();
add();
}
}
DEMO红蓝差分火焰图:

10. 案例分析
10.1 接入层nginx集群异常现象
通过监控插件发现在 2017.09.25 19 点nginx集群请求流量出现大量的499,5xx状态码。并且发现机器cpu使用率升高,目前一直持续中。
10.2 分析nginx相关指标
a) **分析nginx请求流量:

结论:
通过上图发现流量并没有突增,反而下降了,跟请求流量突增没关系。
b) **分析nginx响应时间

结论:
通过上图发现nginx的响应时间有增加可能跟nginx自身有关系或者跟后端upstream响应时间有关系。
c) **分析nginx upstream响应时间

结论:
通过上图发现nginx upstream 响应时间有增加,目前猜测可能后端upstream响应时间拖住nginx,导致nginx出现请求流量异常。
10.3 分析系统cpu情况
a) **通过top观察系统指标
top

结论:
发现nginx worker cpu比较高
b) **分析nginx进程内部cpu情况
结论:
发现主要开销在free,malloc,json解析上面
10.4 火焰图分析cpu a) **生成用户态cpu火焰图
复制

结论:
发现代码里面有频繁的解析json操作,并且发现这个json库性能不高,占用cpu挺高。
10.5 案例总结
a) 分析请求流量异常,得出nginx upstream后端机器响应时间拉长
b) 分析nginx进程cpu高,得出nginx内部模块代码有耗时的json解析以及内存分配回收操作
10.5.1 深入分析
根据以上两点问题分析的结论,我们进一步深入分析。
后端upstream响应拉长,最多可能影响nginx的处理能力。但是不可能会影响nginx内部模块占用过多的cpu操作。并且当时占用cpu高的模块,是在请求的时候才会走的逻辑。不太可能是upstram后端拖住nginx,从而触发这个cpu的耗时操作。
10.5.2 解决方式
遇到这种问题,我们优先解决已知的,并且非常明确的问题。那就是cpu高的问题。解决方式先降级关闭占用cpu过高的模块,然后进行观察。经过降级关闭该模块cpu降下来了,并且nginx请求流量也正常了。之所以会影响upstream时间拉长,因为upstream后端的服务调用的接口可能是个环路再次走回到nginx。
运维老司机总结:常用的150个命令
线上查询及帮助命令(2个)
- man:查看命令帮助,命令的词典,更复杂的还有info,但不常用。
- help:查看Linux内置命令的帮助,比如cd命令。
文件和目录操作命令(18个)
- ls:全拼list,功能是列出目录的内容及其内容属性信息。
- cd:全拼change directory,功能是从当前工作目录切换到指定的工作目录。
- cp:全拼copy,其功能为复制文件或目录。
- find:查找的意思,用于查找目录及目录下的文件。
- mkdir:全拼make directories,其功能是创建目录。
- mv:全拼move,其功能是移动或重命名文件。
- pwd:全拼print working directory,其功能是显示当前工作目录的绝对路径。
- rename:用于重命名文件。
- rm:全拼remove,其功能是删除一个或多个文件或目录。
- rmdir:全拼remove empty directories,功能是删除空目录。
- touch:创建新的空文件,改变已有文件的时间戳属性。
- tree:功能是以树形结构显示目录下的内容。
- basename:显示文件名或目录名。
- dirname:显示文件或目录路径。
- chattr:改变文件的扩展属性。
- lsattr:查看文件扩展属性。
- file:显示文件的类型。
- md5sum:计算和校验文件的MD5值。
查看文件及内容处理命令(21个)
- cat:全拼concatenate,功能是用于连接多个文件并且打印到屏幕输出或重定向到指定文件中。
- tactac:是cat的反向拼写,因此命令的功能为反向显示文件内容。
- more:分页显示文件内容。
- less:分页显示文件内容,more命令的相反用法。
- head:显示文件内容的头部。
- tail:显示文件内容的尾部。
- cut:将文件的每一行按指定分隔符分割并输出。
- split:分割文件为不同的小片段。
- paste:按行合并文件内容。
- sort:对文件的文本内容排序。
- uniq:去除重复行。oldboy
- wc:统计文件的行数、单词数或字节数。
- iconv:转换文件的编码格式。
- dos2unix:将DOS格式文件转换成UNIX格式。
- diff:全拼difference,比较文件的差异,常用于文本文件。
- vimdiff:命令行可视化文件比较工具,常用于文本文件。
- rev:反向输出文件内容。
- grep/egrep:过滤字符串,三剑客老三。
- join:按两个文件的相同字段合并。
- tr:替换或删除字符。
- vi/vim:命令行文本编辑器。
文件压缩及解压缩命令(4个)
- tar:打包压缩。oldboy
- unzip:解压文件。
- gzipgzip:压缩工具。
- zip:压缩工具。
信息显示命令(11个)
- uname:显示操作系统相关信息的命令。
- hostname:显示或者设置当前系统的主机名。
- dmesg:显示开机信息,用于诊断系统故障。
- uptime:显示系统运行时间及负载。
- stat:显示文件或文件系统的状态。
- du:计算磁盘空间使用情况。
- df:报告文件系统磁盘空间的使用情况。
- top:实时显示系统资源使用情况。
- free:查看系统内存。
- date:显示与设置系统时间。
- cal:查看日历等时间信息。
搜索文件命令(4个)
- which:查找二进制命令,按环境变量PATH路径查找。
- find:从磁盘遍历查找文件或目录。
- whereis:查找二进制命令,按环境变量PATH路径查找。
- locate:从数据库 (/var/lib/mlocate/mlocate.db) 查找命令,使用updatedb更新库。
用户管理命令(10个)老男孩
- useradd:添加用户。
- usermod:修改系统已经存在的用户属性。
- userdel:删除用户。
- groupadd:添加用户组。
- passwd:修改用户密码。
- chage:修改用户密码有效期限。
- id:查看用户的uid,gid及归属的用户组。
- su:切换用户身份。
- visudo:编辑/etc/sudoers文件的专属命令。
- sudo:以另外一个用户身份(默认root用户)执行事先在sudoers文件允许的命令。
基础网络操作命令(11个)老男孩
- telnet:使用TELNET协议远程登录。
- ssh:使用SSH加密协议远程登录。
- scp:全拼secure copy,用于不同主机之间复制文件。
- wget:命令行下载文件。
- ping:测试主机之间网络的连通性。
- route:显示和设置linux系统的路由表。
- ifconfig:查看、配置、启用或禁用网络接口的命令。
- ifup:启动网卡。
- ifdown:关闭网卡。
- netstat:查看网络状态。
- ss:查看网络状态。
深入网络操作命令(9个)
- nmap:网络扫描命令。
- lsof:全名list open files,也就是列举系统中已经被打开的文件。
- mail:发送和接收邮件。
- mutt:邮件管理命令。
- nslookup:交互式查询互联网DNS服务器的命令。
- dig:查找DNS解析过程。
- host:查询DNS的命令。
- traceroute:追踪数据传输路由状况。
- tcpdump:命令行的抓包工具。
有关磁盘与文件系统的命令(16个)
- mount:挂载文件系统。
- umount:卸载文件系统。
- fsck:检查并修复Linux文件系统。
- dd:转换或复制文件。
- dumpe2fs:导出ext2/ext3/ext4文件系统信息。
- dumpe:xt2/3/4文件系统备份工具。
- fdisk:磁盘分区命令,适用于2TB以下磁盘分区。
- parted:磁盘分区命令,没有磁盘大小限制,常用于2TB以下磁盘分区。
- mkfs:格式化创建Linux文件系统。
- partprobe:更新内核的硬盘分区表信息。
- e2fsck:检查ext2/ext3/ext4类型文件系统。
- mkswap:创建Linux交换分区。
- swapon:启用交换分区。
- swapoff:关闭交换分区。
- sync:将内存缓冲区内的数据写入磁盘。
- resize2fs:调整ext2/ext3/ext4文件系统大小。
系统权限及用户授权相关命令(4个)
- chmod:改变文件或目录权限。
- chown:改变文件或目录的属主和属组。
- chgrp:更改文件用户组。
- umask:显示或设置权限掩码。
查看系统用户登陆信息的命令(7个)
- whoami:显示当前有效的用户名称,相当于执行id -un命令。
- who:显示目前登录系统的用户信息。
- w:显示已经登陆系统的用户列表,并显示用户正在执行的指令。
- last:显示登入系统的用户。
- lastlog:显示系统中所有用户最近一次登录信息。
- users:显示当前登录系统的所有用户的用户列表。
- finger:查找并显示用户信息。
内置命令及其它(19个)
- echo:打印变量,或直接输出指定的字符串
- printf:将结果格式化输出到标准输出。
- rpm:管理rpm包的命令。
- yum:自动化简单化地管理rpm包的命令。
- watch:周期性的执行给定的命令,并将命令的输出以全屏方式显示。
- alias:设置系统别名。
- unalias:取消系统别名。
- date:查看或设置系统时间。
- clear:清除屏幕,简称清屏。
- history:查看命令执行的历史纪录。
- eject:弹出光驱。
- time:计算命令执行时间。
- nc:功能强大的网络工具。
- xargs:将标准输入转换成命令行参数。
- exec:调用并执行指令的命令。
- export:设置或者显示环境变量。
- unset:删除变量或函数。
- type:用于判断另外一个命令是否是内置命令。
- bc:命令行科学计算器
系统管理与性能监视命令(9个)
- chkconfig:管理Linux系统开机启动项。
- vmstat:虚拟内存统计。
- mpstat:显示各个可用CPU的状态统计。
- iostat:统计系统IO。
- sar:全面地获取系统的CPU、运行队列、磁盘 I/O、分页(交换区)、内存、 CPU中断和网络等性能数据。
- ipcs:用于报告Linux中进程间通信设施的状态,显示的信息包括消息列表、共享内存和信号量的信息。
- ipcrm:用来删除一个或更多的消息队列、信号量集或者共享内存标识。
- strace:用于诊断、调试Linux用户空间跟踪器。我们用它来监控用户空间进程和内核的交互,比如系统调用、信号传递、进程状态变更等。
- ltrace:命令会跟踪进程的库函数调用,它会显现出哪个库函数被调用。
关机/重启/注销和查看系统信息的命令(6个)
- shutdown:关机。
- halt:关机。
- poweroff:关闭电源。
- logout:退出当前登录的Shell。
- exit:退出当前登录的Shell。
- Ctrl+d:退出当前登录的Shell的快捷键。
进程管理相关命令(15个)
- bg:将一个在后台暂停的命令,变成继续执行 (在后台执行)。
- fg:将后台中的命令调至前台继续运行。
- jobs:查看当前有多少在后台运行的命令。
- kill:终止进程。
- killall:通过进程名终止进程。
- pkill:通过进程名终止进程。
- crontab:定时任务命令。
- ps:显示进程的快照。
- pstree:树形显示进程。
- nice/renice:调整程序运行的优先级。
- nohup:忽略挂起信号运行指定的命令。
- pgrep:查找匹配条件的进程。
- runlevel:查看系统当前运行级别。
- init:切换运行级别。
- service:启动、停止、重新启动和关闭系统服务,还可以显示所有系统服务的当前状态。
1.shell脚本不执行
问题:某天研发某同事找我说帮他看看他写的shell脚本,死活不执行,报错。我看了下,脚本很简单,也没有常规性的错误,报“:badinterpreter:Nosuchfileordirectory”错。
看这错,我就问他是不是在windows下编写的脚本,然后在上传到linux服务器的……果然。
原因:在DOS/windows里,文本文件的换行符为rn,而在*nix系统里则为n,所以DOS/Windows里编辑过的文本文件到了*nix里,每一行都多了个^M。
解决:
1)重新在linux下编写脚本;
2)vi:%s/r//g:%s/^M//g(^M输入用Ctrl+v,Ctrl+m)
附:sh-x脚本文件名,可以单步执行并回显结果,有助于排查复杂脚本问题。
2.crontab输出结果控制
问题:
/var/spool/clientmqueue目录占用空间超过100G
原因:
cron中执行的程序有输出内容,输出内容会以邮件形式发给cron的用户,而sendmail没有启动所以就产生了/var/spool/clientmqueue目录下的那些文件,日积月累可能撑破磁盘。
解决:
1)直接手动删除:ls|xargsrm-f;
2)彻底解决:在cron的自动执行语句后加上>/dev/null2>&1
3.telnet很慢/ssh很慢
问题:
某天研发某同事说10.50访问10.52memcached服务异常,让我们检查下看网络/服务/系统是否有异常。检查发现系统正常,服务正常,10.50ping10.52也正常,但10.50telnet10.52很慢。同时发现该机器的namesever是不起作用的。
原因:
becauseyourPCdoesn’tdoareverseDNSlookuponyourIPthen…whenyoutelnet/ftpintoyourlinuxbox,it’lldoadnslookuponyou。
解决:
1)修改/etc/hosts使hostname和ip对应;
2)在/etc/resolv.conf注释掉nameserver或者找一个“活的”nameserver。
4.Read-onlyfilesystem
问题:
同事在mysql里建表建不成功,提示如下:
mysql>createtablewosontest(colddname1char(1));
ERROR1005(HY000):Can’tcreatetable‘wosontest’(errno:30)
经检查mysql用户权限以及相关目录权限没问题;用perror30提示信息为:OSerrorcode30:Read-onlyfilesystem
可能原因:
1)文件系统损坏;
2)磁盘又坏道;
3)fstab文件配置错误,如分区格式错误错误(将ntfs写成了fat)、配置指令拼写错误等。
解决:
1)由于是测试机,重启机器后恢复;
2)网上说用mount可解决。
5.文件删了磁盘空间没释放
问题:
某天发现某台机器df-h已用磁盘空间为90G,而du-sh/*显示所有使用空间加起来才30G,囧。
原因:
可能某人直接用rm删除某个正在写的文件,导致文件删了但磁盘空间没释放的问题
解决:
1)最简单重启系统或者重启相关服务。
2)干掉进程
/usr/sbin/lsof|grepdeleted
ora25575data33uREG65,654294983680/oradata/DATAPRE/UNDOTBS009.dbf(deleted)
从lsof的输出中,我们可以发现pid为25575的进程持有着以文件描述号(fd)为33打开的文件/oradata/DATAPRE/UNDOTBS009.dbf。在我们找到了这个文件之后可以通过结束进程的方式来释放被占用的空间:echo>/proc/25575/fd/33
3)删除正在写的文件一般用cat/dev/null>file
6.find文件提升性能
问题:
在tmp目录下有大量包含picture_*的临时文件,每天晚上2:30对一天前的文件进行清理。之前在crontab下跑如下脚本,但是发现脚本效率很低,每次执行时负载猛涨,影响到其他服务。
#!/bin/sh
find/tmp-name“picture_*”-mtime+1-execrm-f{};
原因:
目录下有大量文件,用find很耗资源。
解决:
#!/bin/sh
cd/tmp
time=`date-d“2dayago”“+%b%d”`
ls-l|grep“picture”|grep“$time”|awk‘{print$NF}’|xargsrm-rf
7.获取不了网关mac地址
问题:
从2.14到3.65(映射地址2.141)网络不通,但是从3端的其他机器到3.65网络OK。
原因:
#arp
AddressHWtypeHWaddressFlagsMaskIface
192.168.3.254etherincompletCMbond0
表面现象是机器自动获取不了网关MAC地址,网络工程师说是网络设备的问题,具体不清。
解决:
arp绑定,arp-ibond0-s192.168.3.25400:00:5e:00:01:64
8.http服务无法启动一例
问题:某天研发某同事说网站前端环境http无法启动,我上去看了下。报如下错:
/etc/init.d/httpdstart
Startinghttpd:[SatJan2917:49:002011][warn]moduleantibot_moduleisalreadyloaded,skipping
Useproxyforwardasremoteip:true.
Antibotexcludepattern:.*.[(js|css|jpg|gif|png)]
Antibotseedcheckpattern:login
(98)Addressalreadyinuse:make_sock:couldnotbindtoaddress[::]:7080
(98)Addressalreadyinuse:make_sock:couldnotbindtoaddress0.0.0.0:7080
nolisteningsocketsavailable,shuttingdown
Unabletoopenlog[FAILED]
原因:
1)端口被占用:表面看是7080端口被占用,于是netstat-npl|grep7080看了下发现7080没有占用;
2)在配置文件中重复写了端口,如果在以下两个文件同时写了Listen7080
/etc/httpd/conf/http.conf
/etc/httpd/conf.d/t.10086.cn.conf
解决:
注释掉/etc/httpd/conf.d/t.10086.cn.conf的Listen7080,重启,OK。
9.toomanyopenfile
问题:
报toomanyopenfile错误
解决:
终极解决方案
echo“”>>/etc/security/limits.conf
echo“*softnproc65535″>>/etc/security/limits.conf
echo“*hardnproc65535″>>/etc/security/limits.conf
echo“*softnofile65535″>>/etc/security/limits.conf
echo“*hardnofile65535″>>/etc/security/limits.conf
echo“”>>/root/.bash_profile
echo“ulimit-n65535″>>/root/.bash_profile
echo“ulimit-u65535″>>/root/.bash_profile
最后重启机器或者执行ulimit-u655345&&ulimit-n65535
10.ibdata1和mysql-bin致磁盘空间问题
问题:
2.51磁盘空间报警,经查发现ibdata1和mysql-bin日志占用空间太多(其中ibdata1超过120G,mysql-bin超过80G)
原因:
ibdata1是存储格式,在INNODB类型数据状态下,ibdata1用来存储文件的数据和索引,而库名的文件夹里的那些表文件只是结构而已。
innodb存储引擎有两种表空间的管理方式,分别是:
1)共享表空间(可拆分为多个小的表空间文件),这个是我们目前多数数据库使用的方法;
2)独立表空间,每一个表有一个独立的表空间(磁盘文件)
对于两种管理方式,各有优劣,具体如下:
①共享表空间:
优点:可以将表空间分成多个文件存放到不同的磁盘上(表空间文件大小不受表大小的限制,一个表可以分布在不同步的文件上)
缺点:所有数据和索引存放在一个文件中,则随着数据的增加,将会有一个很大的文件,虽然可以把一个大文件分成多个小文件,但是多个表及索引在表空间中混合存储,这样如果对于一个表做了大量删除操作后表空间中将有大量空隙。对于共享表空间管理的方式下,一旦表空间被分配,就不能再回缩了。当出现临时建索引或是创建一个临时表的操作表空间扩大后,就是删除相关的表也没办法回缩那部分空间了。
②独立表空间:在配置文件(my.cnf)中设置:innodb_file_per_table
特点:每个表都有自已独立的表空间;每个表的数据和索引都会存在自已的表空间中。
优点:表空间对应的磁盘空间可以被收回(Droptable操作自动回收表空间,如果对于删除大量数据后的表可以通过:altertabletbl_nameengine=innodb;回缩不用的空间。
缺点:如果单表增加过大,如超过100G,性能也会受到影响。在这种情况下,如果使用共享表空间可以把文件分开,但有同样有一个问题,如果访问的范围过大同样会访问多个文件,一样会比较慢。如果使用独立表空间,可以考虑使用分区表的方法,在一定程度上缓解问题。此外,当启用独立表空间模式时,需要合理调整innodb_open_files参数的设置。
解决:
1)ibdata1数据太大:只能通过dump,导出建库的sql语句,再重建的方法。
2)mysql-binLog太大:
①手动删除:
删除某个日志:mysql>PURGEMASTERLOGSTO‘mysql-bin.010′;
删除某天前的日志:mysql>PURGEMASTERLOGSBEFORE’2010-12-2213:00:00′;
②在/etc/my.cnf里设置只保存N天的bin-log日志
expire_logs_days=30//BinaryLog自动删除的天数
系统出问题,通常我们怎么办?
做运维工作的同学,在日常的工作中总免不了跟各种各样的问题打交道,于是在身经百战之后,总结出了一套在日常工作中解决问题的流程:
- 发现问题,通过开发、编辑、客户、老板、监控系统等发现系统有问题了;
- 接下来就想要看问题是否可以重现,这点非常重要,因为有些问题很难重现,例如某些空指针异常或者内存泄露等问题,是需要累计运行到一定阶段之后才能发现;
- 接着不管是否重现与否,都要尽快查看是否有错误日志,通常在日志中会包含非常关键的信息提示;
- 接下来会进行判断,如果是运维能够自行解决的话,例如由于运行环境的版本有bug,或者某个软件的依赖库版本不对,或者某个配置不对,这种问题运维通常通过升级或者更新库,修改配置就可以解决;
- 如果发现是系统本身有Bug,则就需要开发介入进行解决了。
一般过程如下所示:
插图")
问题排查各阶段,看起来就是一个圈
在发现系统有异常现象的时候,我只简单的进行处理,不去解决。
我会先对问题进行简要的分析,尽量保留现场,以便分清楚哪些是干扰因素,哪些才是导致问题真正的原因,然后根据分析结果判断要采取什么行动,不过有时候老司机也有掉坑里的时候,这时候只能想办法重新回到正途中。
这时候往往现象比较棘手,分析就会陷入僵局,只好求助网上大神,然后各种分析工具齐上阵,貌似进展神速,但其实往往最终的效果是一般的,还是没有办法定位到根本原因。
这时候就需要重新梳理思路,去想办法定位到问题的关键,想想看有没有办法能让问题重现,经过一番尝试发现居然重现了问题,并且现象一致,那真是万幸啊,然后经过各种分析源码+一点点运气,心中就有底了,然后给代码打补丁,通过验证,终于一颗心可以落地了。
这个圈如下所示:
插图1")
1、如何发现问题根因?
我将整个问题排查到解决的过程分成了4个阶段,将前4个步骤,定义为第1 阶段,下面我从两个案例,来讲讲在这个阶段做的一些事情,先讲讲案例:
案例1:汽车论坛发现系统异常现象
- 汽车论坛PHP升级+LVS改造后,通过auto.qq.com访问论坛页面出现“服务器暂时无法响应,请稍后再试”。
- 汽车开发收到论坛的URL扫描报警监控。
查询httpd的error.log日志,有如下的错误记录:
插图2")
案例2: 房产后台发现系统异常现象
- 房产后台2台机器升级完PHP5.3.10后,测试均正常,上线运行一段时间编辑反应无法登入系统,重启PHP-FPM后,恢复正常。
- 经过1日又出现类似现象,查询nginx的error.log有明显报错。
插图3")
这些情况怎么破?且听我徐徐道来。
1.1 问题排查第1阶段
插图4")
1.1.1、简单处理不解决
针对汽车论坛,房产后台进行重启后服务均恢复正常,但运行一段时间后又出现类似的问题。
再次重启的时候,查看了ulimit –a选项,发现默认情况只有1024打开文件数,调整到ulimit –SHn 65535之后再次重启相关服务。
运行一段时间后又出现类似无法打开页面的问题。通过下面命令查询到当前系统已经打开的文件句柄数,可用的句柄数,最大句柄数。
cat /proc/sys/fs/file-nr
系统当前状态打开文件也达到10多万了。虽然没有这到最大的可用数了,但有可能是会出现无法打开页面的问题。这种问题的重现概率非常高。
插图5")
插图6")
sockets: used:已使用的所有协议套接字总量
TCP:inuse:正在使用(正在侦听)的TCP套接字数量。其值≤ netstat –lnt | grep ^tcp | wc –l
TCP:orphan:无主(不属于任何进程)的TCP连接数(无用、待销毁的TCP socket数)
TCP:tw:等待关闭的TCP连接数。其值等于netstat –ant | grep TIME_WAIT | wc –l
TCP:alloc(allocated):已分配(已建立、已申请到sk_buff)的TCP套接字数量。其值等于netstat –ant | grep ^tcp | wc –l
TCP:mem:套接字缓冲区使用量(单位不详)
1.1.2、干扰因素问题简要分析
根据以前工作经验判断,打开文件过多问题,一般是打开文件没有close靠成的。代码问题可能是居多,但这些都只是猜测,还没有拿得出手的任何证据。近期同时操作了PHP升级和LVS改造,所以这3方面入手进行思考:
- 代码没有更新的背景上,还是怀疑PHP升级造成的可能性要大一些,但还觉是不是特别认可这个怀疑,但无法从PHP.net获得更多信息。
- 另一方面,LVS是非常成熟的技术,只涉及数据包的转发,只是为了验证RS是否存活,会周期性探测80端口是否有响应,会增加一定的访问量,但也只是一次简单GET访问,不会造成WEB无响应的问题。
同时监控LVS并未有异常的连接数的增加。 - 还有就是php加载了过多的公司自已独有的so文件,使整个事件事情的关键点过多,而且需要跨部门协调开发人员,增加了问题分析的复杂度。
1.1.3、解决问题方向判断错误
由于干扰因素过多,并且接手业务时间不长,所以增加了方向判断失误可能性。主要因素为出问题前做过PHP升级和LVS改造,还是在一定程序上增加了迷惑性。
一度只是简单通过strace分析,并没有认真的研究strace的具体调用细节。判断是连接数据库超时等原因造成的socket释放异常。
并且想通过“时间+used socket+参数优化”三个方面综合进行逆向查询入手查找。但由于涉及到系统各方面操作因素太多,而且对系统理解有限,也导致处理前期有了判断问题的方向性错误。
1.2 问题排查第2阶段
经过前面的判断,发现第一阶段的方向错误了,于是进入第二个阶段:
插图7")
1.2.1、重回正途利用现有工具
短时间从PHP升级和LVS改造上面无法寻找到突破口。
决定利用LINUX现在提供的工具,如strace,gdb,netstat,lsof,/proc提供的各种系统分析工具进行排查问题。
计划准备使用的工具:
- strace – trace system calls and signals
- lsof – list open files
- gdb – The GNU Debugger
- netstat – Print network connections, routing tables, interface statistics, masquerade connections, and multicast member-ships
- Proc – 文件系统是一个伪文件系统,它只存在内存当中,文件可以用于访问有关内核的状态、计算机的属性、正在运行的进程的状态等信息
1.2.2、现象棘手分析迷茫
插图8")
- 从架构入手:将RS服务器从LVS掉,恢复正常DNS指向, 问题依旧。
- 从PHP入手:将PHP恢复到原有版本,问题依旧,只是socketd速度增长没有新版本快(这点令我很奇怪)。
- 从系统入手:系统负载不高,连接数正常,IO压力正常,dmesg无报错。
- 从web应用入手:httpd日志正常,发现httpd进程打开大量的socket。
通过lsof命令将httpd进程的打开文件都列出来:
插图9")
插图10")
1.2.3、系统状态乱查一气
插图11")
插图12")
一度查到这条strace记录 时候,都开始怀疑数据库连接上面的问题。
刚开始对strace的输出内容一时也没有理清头绪,但随着查询文档的增多,也随步加深了对strace输出信息的理解。
1.2.4、求助网上大神
所谓大神,即伟大的Google.com,使用各种关键字进行搜索相关文章。
相对靠谱的文章,关于can’t identify protocol问题定位问题定位步骤:
- 用root帐户 遍历 /proc/进程ID/fd目录,如果该目录下文件数比较大(如果大于10,一般就属于socket泄漏),根据该进程ID,可以确认该进程ID所对应的名称。
- 重启程序恢复服务,以便后续查找问题。
- strace 该程序并记录strace信息。strace –p 进程ID >>/tmp/stracelog.log 2>&1 。
- 查看 /proc/进程ID/fd 下的文件数目是否有增加,如果发现有增加,记录上一个socket编号,停止strace 。
- 确认问题代码的位置。
打开/tmp/stracelog.log,从尾部向上查找close(socket编号)所在行,可以确认在该次close后再次创建的socket没有关闭,根据socket连接的server ip可以确认问题代码的位置。
Lsof FAQ
插图13")
1.3 问题排查第3阶段
接下来进入非常关键第3 阶段
插图14")
1.3.1、分析工具齐上场
插图15")
以nginx+php-cgi场景开始重复测试工具,抓取有用信息:
上面抓取的信息,在一定程度上影响了我的判断,因为19u,20u是因为连接完数据库后,状态才生成的can’t identify protocol,所以我的关注点转向了数据库连接上面。
再另一个终端上面查strace ,根据FD进行从下往上查询,查询FD19,20连接完数据库后,已经进行 正常close()操作了。
但查询到下面4个系统调用是最后使用19,20句柄,就没有下文了。而且没有正常close();
插图16")
下面没有19和20的任何输出了,当然也没有包括close()的操作。
下面是一个标准的open,close操作记录,便于对比参考。
插图17")
http://kasicass.blog.163.com/blog/static/3956192010101994124701/
根据这篇文章的介绍,can‘t identify protocol是lsof的源码,我也在dsock.c查到这个定义。
在 openbsd 下:
插图18")
在 debian 下:
插图19")
很奇怪哦,正确创建的 socket fd 居然显示 “can‘t identify protocol”。
PS:
根据TCP的状态迁移图。应用程序主动打开后,没有进行任何SYN及后续的ESTABLISED,CLOSE_WAIT。直接被应用程序关闭或超时,才会状态直接变成生CLOSED。
插图20")
1.3.2、进展神速,效果一般
通过多次测试,监控系统调用,已经可以定位FD问题是由于socket和ioctl两个系统调产生的,并且处理正确处理造成socket没有释放。
插图21")
一直在处纠结了很长时间,很长时间… … …
1.3.3、重理思路定位关键
排查的重点工作转向这2条系统调和是如何产生的,由于这个系统调和是比较独立的,所以并不知道是哪个文件,以何种方式进行调用,排查陷入困境。
分析系统调用:
插图22")
函数解释:
socket() 为通信创造一个端点并返回一个文件描述符。 socket() 由三个参数:
- domain, 确定协议族。例如:
PF_INET 是IPv4 或者
PF_INET6 是 IPv6
PF_UNIX 是本地(用一个文件)
- type, 是下面中的一个:
SOCK_STREAM (可靠的面向连接的服务或者 Stream Sockets)
SOCK_DGRAM (数据包服务或者 Datagram Sockets)
SOCK_SEQPACKET (可靠的有序的分组服务),或者
SOCK_RAW (网络层的原始协议)。
- protocol 确定实际使用的运输层。最常见的是 IPPROTO_TCP, IPPROTO_SCTP, IPPROTO_UDP, IPPROTO_DCCP。这些协议是在
中定义的。如果 domain 和 type已经确定,“0” 可以用来选择一个默认的协议。
ioctl 主要参数SIOCGIFADDR 获取接口地址。
1.3.4、问题重现现象一致
经过上面的函数分析,得知是获取eth1的IP系统调用。
由于本人不是开发出身,所以了为避免出错,我需要通过另一种方法验证我的分析:
插图23")
2、如何正确解决问题
在定位到问题之后,剩下的其实相对来说就容易的多了
插图24")
2.1、分析源码运气稍好
- 先要查出PHP是如何调用,查询eth1网关,调和这个IP做什么。
传统方法:grep –R eth1./*结果很给力,多个.php文件都有调一个geteth1_ip_str**函数(实属运气,如果函数没写eth1类似的名称,还可能查不到哪. ^^) - 通过php源代码查到此函数,是公司t_common.so里面定义实现。手头正好有这个源码,查到get_eth1_ip_str这个函数,很简单就是返回一个eth1的IP地址。
插图25")
问题总结的时候想到脚本,可以列出来所有加载扩展库的支持函数列表:
插图26")
输出内容:
插图27")
2.2、心中有底略显激动
通过简单分析,以及咨询同事,觉是应该是申请了sock,没有进行close造成的。但真的是这样吗?我们还要验证一下。
插图28")
sleep(10000); sleep函数是要进程进行阻塞(sleep可以实现一种比较特殊的阻塞,这点跟IO阻塞不太一致),这样有时间可以提取这个进程运行状态。
心中有底略显激动
插图29")
2.3、代码补丁验证通过
再次执行测试程序
/usr/local/php/bin/php test.php xxx.xxx.169.114
同时监控lsof 和/proc/pid/fd下面都没有出现socket不释放(can’t identify protocol)的问题。
插图30")
更新扩展so后,线上测试均正常。没有再出现因为调用这个函数不释放socket句柄的问题。
至此整个问题都就都解决,世界又恢复了平静(大笑)
3、经验总结
对于本次问题处理的经验,归纳提炼成如下4句话:
- 收集信息,随时记录。
- 冷静判断,积极分析。
- 大胆假设,大胆尝试。
- 积极总结,以备后用。
当然,总结我这几年处理问题的思路及经验,可以提炼成以下这三点:
- 要有明确的数据流和业务流的概念,例如:通常对于Web数据流处理起来较简单,而对于Mail数据流则较复杂;
- 要能准确切入关键流节点,要敢于迅速的切入这些关键流,必要的时候进行快速模拟,以得到一手数据。
- 要掌握程序运行的状态,可以从两方面着手,第一是掌握输出日志内容;第二是进行strace跟踪程序运行状态等
数据库排查
查询数据库死锁日志
利用 show engine innodb status 命令获取到如下死锁信息

# 查看autocommit配置 select @@autocommit; # 同上 show variables like 'autocommit'; #设置SQL自动提交模式 1:默认,自动提交 0:需要手动触发commit,否则不会生效 set autocommit=1; # 查看默认的搜索引擎 show variables like '%storage_engine%';
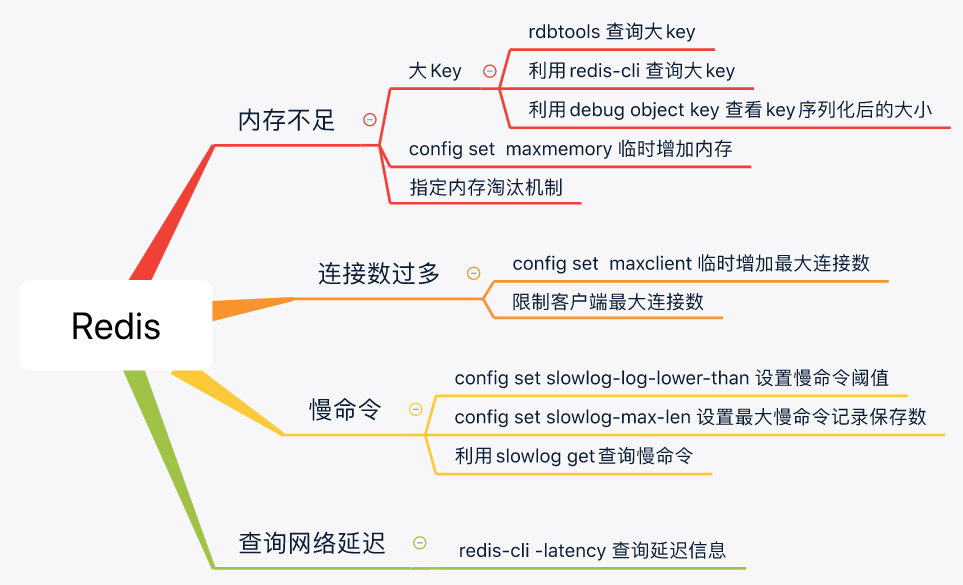
查看大key
安装工具dbatools redisTools,列出最大的前N个key
2
3
slowlog get
