什么是Spring Cloud Sleuth
随着业务的发展,我们的系统规模也会变得越来越大,各微服务间的调用关系也变得越来越错综复杂。这时候对于每个请求全链路调用的跟踪就变得越来越重要,通过实现对请求调用的跟踪可以帮助我们快速的发现错误根源以及监控分析每条请求链路上的性能瓶颈等好处。
针对上面所述的分布式服务跟踪问题,Spring Cloud Sleuth提供了一套完整的解决方案。
快速入门
准备工作
构建一些基础的设施和应用:
服务注册中心:eureka-server。
微服务应用:trace-1,实现一个REST接口/trace-1,调用该接口后将触发对trace-2应用的调用。
创建应用主类,并实现/trace-1接口,并使用RestTemplate调用trace-2应用的接口。
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
2@EnableDiscoveryClient
3@SpringBootApplication
4public class TraceApplication {
5
6 private final Logger logger = Logger.getLogger(getClass());
7
8 @Bean
9 @LoadBalanced
10 RestTemplate restTemplate() {
11 return new RestTemplate();
12 }
13
14 @RequestMapping(value = "/trace-1", method = RequestMethod.GET)
15 public String trace() {
16 logger.info("===call trace-1===");
17 return restTemplate().getForEntity("http://trace-2/trace-2", String.class).getBody();
18 }
19
20 public static void main(String[] args) {
21 SpringApplication.run(TraceApplication.class, args);
22 }
23
24}
25
26
微服务应用:trace-2,实现一个REST接口/trace-2,供trace-1调用。
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
2@EnableDiscoveryClient
3@SpringBootApplication
4public class TraceApplication {
5
6 private final Logger logger = Logger.getLogger(getClass());
7
8 @RequestMapping(value = "/trace-2", method = RequestMethod.GET)
9 public String trace() {
10 logger.info("===<call trace-2>===");
11 return "Trace";
12 }
13
14 public static void main(String[] args) {
15 SpringApplication.run(TraceApplication.class, args);
16 }
17
18}
19
20
2、实现跟踪
为上面的trace-1和trace-2来添加服务跟踪功能。
通过Spring Cloud Sleuth的封装为应用增加服务跟踪能力的操作非常简单,只需要在trace-1和trace-2的pom.xml依赖管理中增加spring-cloud-starter-sleuth依赖
2
3
4
5
6
2 <groupId>org.springframework.cloud</groupId>
3 <artifactId>spring-cloud-starter-sleuth</artifactId>
4</dependency>
5
6
对trace-1的接口发送请求http://localhost:9101/trace-1。此时,我们可以从它们的控制台输出中,看到sleuth的一些内容。
2
3
4
5
6
7
2INFO [trace-1,f410ab57afd5c145,a9f2118fa2019684,false] 25028 --- [nio-9101-exec-1] ication$$EnhancerBySpringCGLIB$$d8228493 : ===<call trace-1>===
3
4-- trace-2
5INFO [trace-2,f410ab57afd5c145,e9a377dc2268bc29,false] 23112 --- [nio-9102-exec-1] ication$$EnhancerBySpringCGLIB$$e6cb4078 : ===<call trace-2>===
6
7
多了 [trace-1,f410ab57afd5c145,a9f2118fa2019684,false]
第一个值:trace-1,它记录了应用的名称,也就是application.properties中spring.application.name参数配置的属性。
第二个值:f410ab57afd5c145,Spring Cloud Sleuth生成的一个ID,称为Trace ID,它用来标识一条请求链路。一条请求链路中包含一个Trace ID,多个Span ID。
第三个值:a9f2118fa2019684,Spring Cloud Sleuth生成的另外一个ID,称为Span ID,它表示一个基本的工作单元,比如:发送一个HTTP请求。
第四个值:false,表示是否要将该信息输出到Zipkin等服务中来收集和展示。
上面四个值中的Trace ID和Span ID是Spring Cloud Sleuth实现分布式服务跟踪的核心。
在一次服务请求链路的调用过程中,会保持并传递同一个Trace ID,从而将整个分布于不同微服务进程中的请求跟踪信息串联起来。
以上面输出内容为例,trace-1和trace-2同属于一个前端服务请求来源,所以他们的Trace ID是相同的,处于同一条请求链路中。
跟踪原理
分布式系统中的服务跟踪在理论上主要包括下面两个关键点:
1、为了实现请求跟踪,当请求发送到分布式系统的入口端点时,只需要服务跟踪框架为该请求创建一个唯一的跟踪标识,同时在分布式系统内部流转的时候,框架始终保持传递该唯一标识,直到返回给请求方为止,这个唯一标识就是前文中提到的Trace ID。通过Trace ID的记录,我们就能将所有请求过程日志关联起来。
2、为了统计各处理单元的时间延迟,当请求达到各个服务组件时,或是处理逻辑到达某个状态时,也通过一个唯一标识来标记它的开始、具体过程以及结束,该标识就是我们前文中提到的Span ID,对于每个Span来说,它必须有开始和结束两个节点,通过记录开始Span和结束Span的时间戳,就能统计出该Span的时间延迟,除了时间戳记录之外,它还可以包含一些其他元数据,比如:事件名称、请求信息等。
通过在工程中引入spring-cloud-starter-sleuth依赖之后, 它会自动的为当前应用构建起各通信通道的跟踪机制,比如:
1、通过诸如RabbitMQ、Kafka(或者其他任何Spring Cloud Stream绑定器实现的消息中间件)传递的请求
2、通过Zuul代理传递的请求
3、通过RestTemplate发起的请求
抽样收集
我们在对接分析系统时就会碰到一个问题:分析系统在收集跟踪信息的时候,需要收集多少量的跟踪信息才合适呢?
理论上来说,我们收集的跟踪信息越多就可以更好的反映出系统的实际运行情况,并给出更精准的预警和分析,但是在高并发的分布式系统运行时,大量的请求调用会产生海量的跟踪日志信息,如果我们收集过多的跟踪信息将会对我们整个分布式系统的性能造成一定的影响,同时保存大量的日志信息也需要不少的存储开销。
所以,在Sleuth中采用了抽象收集的方式来为跟踪信息打上收集标记,也就是我们之前在日志信息中看到的第四个boolean类型的值,它代表了该信息是否要被后续的跟踪信息收集器获取和存储。
在Sleuth中的抽样收集策略是通过Sampler接口实现的
通过实现isSampled方法,Spring Cloud Sleuth会在产生跟踪信息的时候调用它来为跟踪信息生成是否要被收集的标志。需要注意的是,即使isSampled返回了false,它仅代表该跟踪信息不被输出到后续对接的远程分析系统(比如:Zipkin),对于请求的跟踪活动依然会进行,所以我们在日志中还是能看到收集标识为false的记录。
默认情况下,Sleuth会使用PercentageBasedSampler实现的抽样策略,以请求百分比的方式配置和收集跟踪信息,我们可以通过在application.properties中配置下面的参数对其百分比值进行设置,它的默认值为0.1,代表收集10%的请求跟踪信息。
2
3
2
3
由于跟踪日志信息的数据价值往往仅在最近的一段时间内非常有用。那么我们在设计抽样策略时,主要考虑在不对系统造成明显性能影响的情况下,以在日志保留时间窗内充分利用存储空间的原则来实现抽样策略。
整合logstash
由于日志文件都离散的存储在各个服务实例的文件系统之上,仅仅通过查看日志文件来分析我们的请求链路依然是一件相当麻烦的差事,所以我们还需要一些工具来帮助我们集中的收集、存储和搜索这些跟踪信息。引入基于日志的分析系统是一个不错的选择,比如:ELK平台,它可以轻松的帮助我们来收集和存储这些跟踪日志,同时在需要的时候我们也可以根据Trace ID来轻松地搜索出对应请求链路相关的明细日志。
Logstash是一个完全开源的工具,他可以对你的日志进行收集、过滤,并将其存储供以后使用。
Spring Cloud Sleuth在与ELK平台整合使用时,实际上我们只要实现与负责日志收集的Logstash完成数据对接即可,所以我们需要为Logstash准备json格式的日志输出。
由于Spring Boot应用默认使用了logback来记录日志,而Logstash自身也有对logback日志工具的支持工具,所以我们可以直接通过在logback的配置中增加对logstash的appender,就能非常方便的将日志转换成以json的格式存储和输出了。
在pom.xml依赖中引入logstash-logback-encoder依赖
2
3
4
5
6
7
2 <groupId>net.logstash.logback</groupId>
3 <artifactId>logstash-logback-encoder</artifactId>
4 <version>4.6</version>
5</dependency>
6
7
在工程/resource目录下创建bootstrap.properties配置文件,将spring.application.name=trace-1配置移动到该文件中去。
在工程/resource目录下创建logback配置文件logback-spring.xml
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
2<configuration>
3 <include resource="org/springframework/boot/logging/logback/defaults.xml"/>
4
5 <springProperty scope="context" name="springAppName" source="spring.application.name"/>
6 <!-- 日志在工程中的输出位置 -->
7 <property name="LOG_FILE" value="${BUILD_FOLDER:-build}/${springAppName}"/>
8 <!-- 控制台的日志输出样式 -->
9 <property name="CONSOLE_LOG_PATTERN"
10 value="%clr(%d{yyyy-MM-dd HH:mm:ss.SSS}){faint} %clr(${LOG_LEVEL_PATTERN:-%5p}) %clr([${springAppName:-},%X{X-B3-TraceId:-},%X{X-B3-SpanId:-},%X{X-Span-Export:-}]){yellow} %clr(${PID:- }){magenta} %clr(---){faint} %clr([%15.15t]){faint} %clr(%-40.40logger{39}){cyan} %clr(:){faint} %m%n${LOG_EXCEPTION_CONVERSION_WORD:-%wEx}"/>
11
12 <!-- 控制台Appender -->
13 <appender name="console" class="ch.qos.logback.core.ConsoleAppender">
14 <filter class="ch.qos.logback.classic.filter.ThresholdFilter">
15 <level>INFO</level>
16 </filter>
17 <encoder>
18 <pattern>${CONSOLE_LOG_PATTERN}</pattern>
19 <charset>utf8</charset>
20 </encoder>
21 </appender>
22
23 <!-- 为logstash输出的json格式的Appender -->
24 <appender name="logstash" class="ch.qos.logback.core.rolling.RollingFileAppender">
25 <file>${LOG_FILE}.json</file>
26 <rollingPolicy class="ch.qos.logback.core.rolling.TimeBasedRollingPolicy">
27 <fileNamePattern>${LOG_FILE}.json.%d{yyyy-MM-dd}.gz</fileNamePattern>
28 <maxHistory>7</maxHistory>
29 </rollingPolicy>
30 <encoder class="net.logstash.logback.encoder.LoggingEventCompositeJsonEncoder">
31 <providers>
32 <timestamp>
33 <timeZone>UTC</timeZone>
34 </timestamp>
35 <pattern>
36 <pattern>
37 {
38 "severity": "%level",
39 "service": "${springAppName:-}",
40 "trace": "%X{X-B3-TraceId:-}",
41 "span": "%X{X-B3-SpanId:-}",
42 "exportable": "%X{X-Span-Export:-}",
43 "pid": "${PID:-}",
44 "thread": "%thread",
45 "class": "%logger{40}",
46 "rest": "%message"
47 }
48 </pattern>
49 </pattern>
50 </providers>
51 </encoder>
52 </appender>
53
54 <root level="INFO">
55 <appender-ref ref="console"/>
56 <appender-ref ref="logstash"/>
57 </root>
58</configuration>
59
60
整合zipkin
我们已经能够利用ELK平台提供的收集、存储、搜索等强大功能,对跟踪信息的管理和使用已经变得非常便利。但是,在ELK平台中的数据分析维度缺少对请求链路中各阶段时间延迟的关注。对于这样的问题,我们就可以引入Zipkin来解决。
Zipkin可以使用它来收集各个服务器上请求链路的跟踪数据,并通过它提供的REST API接口来辅助我们查询跟踪数据以实现对分布式系统的监控程序,从而及时地发现系统中出现的延迟升高问题并找出系统性能瓶颈的根源。
除了面向开发的API接口之外,它也提供了方便的UI组件来帮助我们直观的搜索跟踪信息和分析请求链路明细。
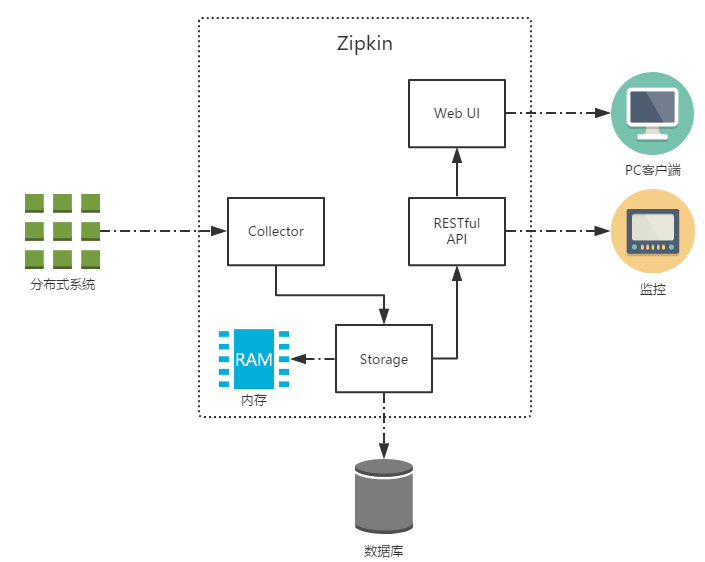
上图展示了Zipkin的基础架构,它主要有4个核心组件构成:
Collector: 收集器组件,它主要用于处理从外部系统发送过来的跟踪信息,将这些信息转换为Zipkin内部处理的Span格式,以支持后续的存储、分析、展示等功能。
Storage: 存储组件,它主要对处理收集器接收到的跟踪信息,默认会将这些信息存储在内存中,我们也可以修改此存储策略,通过使用其他存储组件将跟踪信息存储到数据库中。
RESTful API: API组件,它主要用来提供外部访问接口。比如给客户端展示跟踪信息,或是外接系统访问以实现监控等。
Web UI: UI组件,基于API组件实现的上层应用。通过UI组件用户可以方便而有直观地查询和分析跟踪信息。
HTTP收集
在Spring Cloud Sleuth中对Zipkin的整合进行了自动化配置的封装
第一步:搭建Zipkin Server
创建一个基础的Spring Boot应用,命名为zipkin-server,并在pom.xml中引入Zipkin Server的相关依赖
2
3
4
5
6
7
8
9
10
2 <groupId>io.zipkin.java</groupId>
3 <artifactId>zipkin-server</artifactId>
4 </dependency>
5 <dependency>
6 <groupId>io.zipkin.java</groupId>
7 <artifactId>zipkin-autoconfigure-ui</artifactId>
8 </dependency>
9
10
创建应用主类ZipkinApplication,使用@EnableZipkinServer注解来启动Zipkin Server
2
3
4
5
6
7
8
9
10
11
2@SpringBootApplication
3public class ZipkinApplication {
4
5 public static void main(String[] args) {
6 SpringApplication.run(ZipkinApplication.class, args);
7 }
8
9}
10
11
在application.properties中做一些简单配置
2
3
4
2server.port=9411
3
4
访问http://localhost:9411/,可以看到Zipkin管理页
第二步:为应用引入和配置Zipkin服务
在完成了Zipkin Server的搭建之后,还需要对应用做一些配置,以实现将跟踪信息输出到Zipkin Server。
在trace-1和trace-2的pom.xml中引入spring-cloud-sleuth-zipkin依赖
2
3
4
5
6
2 <groupId>org.springframework.cloud</groupId>
3 <artifactId>spring-cloud-sleuth-zipkin</artifactId>
4</dependency>
5
6
在trace-1和trace-2的application.properties中增加Zipkin Server的配置信息
2
3
2
3
消息中间件收集
Spring Cloud Sleuth在整合Zipkin时,不仅实现了以HTTP的方式收集跟踪信息,还实现了通过消息中间件来对跟踪信息进行异步收集的封装。
通过结合Spring Cloud Stream,可以让应用客户端将跟踪信息输出到消息中间件上,同时Zipkin服务端从消息中间件上异步地消费这些跟踪信息。
第一步:修改客户端trace-1和trace-2
加入如下依赖
2
3
4
5
6
7
8
9
10
11
2 <groupId>org.springframework.cloud</groupId>
3 <artifactId>spring-cloud-sleuth-stream</artifactId>
4</dependency>
5
6<dependency>
7 <groupId>org.springframework.cloud</groupId>
8 <artifactId>spring-cloud-starter-stream-rabbit</artifactId>
9</dependency>
10
11
在application.properties配置中去掉HTTP方式实现时使用的spring.zipkin.base-url参数,并根据实际部署情况,增加消息中间件的相关配置
2
3
4
5
6
2spring.rabbitmq.port=5672
3spring.rabbitmq.username=springcloud
4spring.rabbitmq.password=123456
5
6
第二步:修改zipkin-server服务端
在依赖中增加如下内容:
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
2 <groupId>org.springframework.cloud</groupId>
3 <artifactId>spring-cloud-sleuth-zipkin-stream</artifactId>
4</dependency>
5
6<dependency>
7 <groupId>org.springframework.cloud</groupId>
8 <artifactId>spring-cloud-starter-stream-rabbit</artifactId>
9</dependency>
10
11<dependency>
12 <groupId>io.zipkin.java</groupId>
13 <artifactId>zipkin-autoconfigure-ui</artifactId>
14</dependency>
15
16
