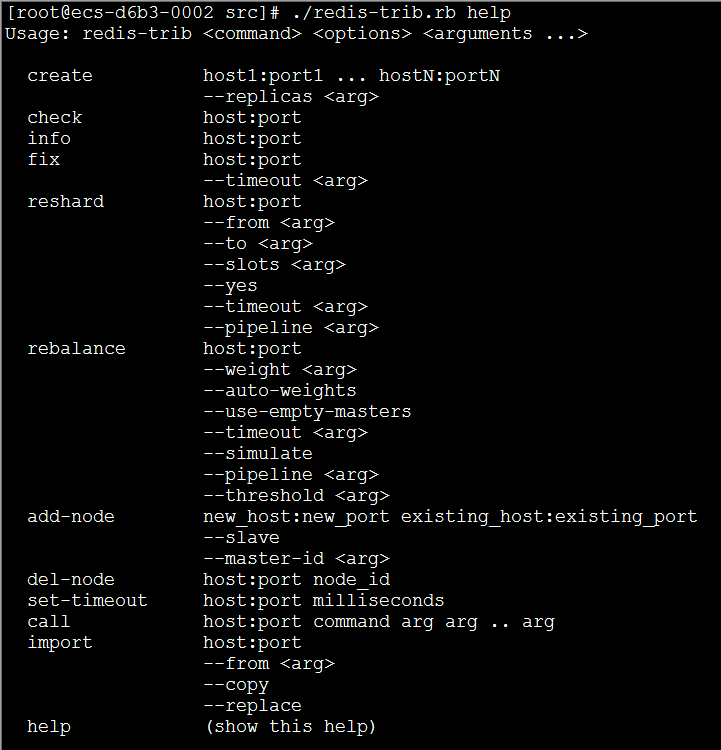
Redis cluster tutorial
Redis集群提供一种方式自动将数据分布在多个Redis节点上。
Redis Cluster provides a way to run a Redis installation where data is automatically sharded across multiple Redis nodes.
1、Redis集群TCP端口(Redis Cluster TCP ports)
每个Redis集群中的节点都需要打开两个TCP连接。一个连接用于正常的给Client提供服务,比如6379,还有一个额外的端口(通过在这个端口号上加10000)作为数据端口,比如16379。第二个端口(本例中就是16379)用于集群总线,这是一个用二进制协议的点对点通信信道。这个集群总线(Cluster bus)用于节点的失败侦测、配置更新、故障转移授权,等等。客户端从来都不应该尝试和这些集群总线端口通信,它们只应该和正常的Redis命令端口进行通信。注意,确保在你的防火墙中开放着两个端口,否则,Redis集群节点之间将无法通信。
命令端口和集群总线端口的偏移量总是10000。
注意,如果想要集群按照你想的那样工作,那么集群中的每个节点应该:
- 正常的客户端通信端口(通常是6379)用于和所有可到达集群的所有客户端通信
- 集群总线端口(the client port + 10000)必须对所有的其它节点是可到达的
也就是,要想集群正常工作,集群中的每个节点需要做到以下两点:
- 正常的客户端通信端口(通常是6379)必须对所有的客户端都开放,换言之,所有的客户端都可以访问
- 集群总线端口(客户端通信端口 + 10000)必须对集群中的其它节点开放,换言之,其它任意节点都可以访问
如果你没有开放TCP端口,你的集群可能不会像你期望的那样工作。集群总线用一个不同的二进制协议通信,用于节点之间的数据交换
2、Redis集群数据分片(Redis Cluster data sharding)
Redis集群不同一致性哈希,它用一种不同的分片形式,在这种形式中,每个key都是一个概念性(hash slot)的一部分。
There are 16384 hash slots in Redis Cluster, and to compute what is the hash slot of a given key, we simply take the CRC16 of the key modulo 16384.
Redis集群中有16384个hash slots,为了计算给定的key应该在哪个hash slot上,我们简单地用这个key的CRC16值来对16384取模。(即:key的CRC16 % 16384)
Every node in a Redis Cluster is responsible for a subset of the hash slots
Redis集群中的每个节点负责一部分hash slots,假设你的集群有3个节点,那么:
- Node A contains hash slots from 0 to 5500
- Node B contains hash slots from 5501 to 11000
- Node C contains hash slots from 11001 to 16383
允许添加和删除集群节点。比如,如果你想增加一个新的节点D,那么久需要从A、B、C节点上删除一些hash slot给到D。同样地,如果你想从集群中删除节点A,那么会将A上面的hash slots移动到B和C,当节点A上是空的时候就可以将其从集群中完全删除。
因为将hash slots从一个节点移动到另一个节点并不需要停止其它的操作,添加、删除节点以及更改节点所维护的hash slots的百分比都不需要任何停机时间。也就是说,移动hash slots是并行的,移动hash slots不会影响其它操作。
Redis支持多个key操作,只要这些key在一个单个命令中执行(或者一个事务,或者Lua脚本执行),那么它们就属于相同的hash slot。你也可以用hash tags俩强制多个key都在相同的hash slot中。
3、Redis集群主从模式(Redis Cluster master-slave model)
In order to remain available when a subset of master nodes are failing or are not able to communicate with the majority of nodes, Redis Cluster uses a master-slave model where every hash slot has from 1 (the master itself) to N replicas (N-1 additional slaves nodes).
当部分master节点失败了,或者不能够和大多数节点通信的时候,为了保持可用,Redis集群用一个master-slave模式,这样的话每个hash slot就有1到N个副本。
在我们的例子中,集群有A、B、C三个节点,如果节点B失败了,那么5501-11000之间的hash slot将无法提供服务。然而,当我们给每个master节点添加一个slave节点以后,我们的集群最终会变成由A、B、C三个master节点和A1、B1、C1三个slave节点组成,这个时候如果B失败了,系统仍然可用。节点B1是B的副本,如果B失败了,集群会将B1提升为新的master,从而继续提供服务。然而,如果B和B1同时失败了,那么整个集群将不可用。
4、Redis集群一致性保证(Redis Cluster consistency guarantees)
Redis Cluster is not able to guarantee strong consistency. In practical terms this means that under certain conditions it is possible that Redis Cluster will lose writes that were acknowledged by the system to the client.
Redis集群不能保证强一致性。换句话说,Redis集群可能会丢失一些写操作。The first reason why Redis Cluster can lose writes is because it uses asynchronous replication.
Redis集群可能丢失写的第一个原因是因为它用异步复制。
写可能是这样发生的:
- 客户端写到master B
- master B回复客户端OK
- master B将这个写操作广播给它的slaves B1、B2、B3
正如你看到的那样,B没有等到B1、B2、B3确认就回复客户端了,也就是说,B在回复客户端之前没有等待B1、B2、B3的确认,这对应Redis来说是一个潜在的风险。所以,如果客户端写了一些东西,B也确认了这个写操作,但是在它将这个写操作发给它的slaves之前它宕机了,随后其中一个slave(没有收到这个写命令)可能被提升为新的master,于是这个写操作就永远丢失了。
这和大多数配置为每秒刷新一次数据到磁盘的情况是一样的。你可以通过强制数据库在回复客户端以前刷新数据,但是这样做的结果会导致性能很低,这就相当于同步复制了。
基本上,需要在性能和一致性之间做一个权衡。
如果绝对需要的话,Redis集群也是支持同步写的,这是通过WAIT命令实现的,这使得丢失写的可能性大大降低。然而,需要注意的是,Redis集群没有实现强一致性,即使用同步复制,因为总是有更复杂的失败场景使得一个没有接受到这个写操作的slave当选为新的master。(however note that Redis Cluster does not implement strong consistency even when synchronous replication is used: it is always possible under more complex failure scenarios that a slave that was not able to receive the write is elected as master.)
另一个值得注意的场景,即Redis集群将会丢失写操作,这发生在一个网络分区中,在这个分区中,客户端与少数实例(包括至少一个主机)隔离。
假设这样一个例子,有一个集群有6个节点,分别由A、B、C、A1、B1、C1组成,三个masters三个slaves,有一个客户端我们叫Z1。在分区发生以后,可能分区的一边是A、C、A1、B1、C1,另一边有B和Z1。此时,Z1仍然可用写数据到B,如果网络分区的时间很短,那么集群可能继续正常工作,而如果分区的时间足够长以至于B1在多的那一边被提升为master,那么这个时候Z1写到B上的数据就会丢失。
什么意思呢?简单的来说就是,本来三主三从在一个网络分区中,突然网络分区发生,于是一边是A、C、A1、B1、C1,另一边是B和Z1,这时候Z1往B中写数据,于此同时另一边(即A、C、A1、B1、C1)认为B已经挂了,于是将B1提升为master,当分区回复的时候,由于B1变成了master,所以B就成了slave,于是B就要丢弃它自己原有的数据而从B1那里同步数据,于是乎先去Z1写到B的数据就丢失了。
注意,有一个最大窗口,这是Z1能够向B写的最大数量:如果时间足够的话,分区的多数的那一边已经选举完成,选择一个slave成为master,此时,所有在少数的那一边的master节点将停止接受写。
也就说说,有一个最大窗口的设置项,它决定了Z1在那种情况下能够向B发送多数写操作:如果分隔的时间足够长,多数的那边已经选举slave成为新的master,此后少数那边的所有master节点将不再接受写操作。
在Redis集群中,这个时间数量是一个非常重要的配置指令,它被称为node timeout。在超过node timeout以后,一个master节点被认为已经失败了,并且选择它的一个副本接替master。类似地,如果在过了node timeout时间以后,没有一个master能够和其它大多数的master通信,那么整个集群都将停止接受写操作。
After node timeout has elapsed, a master node is considered to be failing, and can be replaced by one of its replicas. Similarly after node timeout has elapsed without a master node to be able to sense the majority of the other master nodes, it enters an error state and stops accepting writes.
5、Redis集群配置参数(Redis Cluster configuration parameters)
- cluster-enabled <yes/no>: 如果是yes,表示启用集群,否则以单例模式启动
- **cluster-config-file <filename>: **可选,这不是一个用户可编辑的配置文件,这个文件是Redis集群节点自动持久化每次配置的改变,为了在启动的时候重新读取它。
- cluster-node-timeout <milliseconds>: 超时时间,集群节点不可用的最大时间。如果一个master节点不可到达超过了指定时间,则认为它失败了。注意,每一个在指定时间内不能到达大多数master节点的节点将停止接受查询请求。
- cluster-slave-validity-factor <factor>: 如果设置为0,则一个slave将总是尝试故障转移一个master。如果设置为一个正数,那么最大失去连接的时间是node timeout乘以这个factor。
- cluster-migration-barrier <count>: 一个master和slave保持连接的最小数量(即:最少与多少个slave保持连接),也就是说至少与其它多少slave保持连接的slave才有资格成为master。
- cluster-require-full-coverage <yes/no>: 如果设置为yes,这也是默认值,如果key space没有达到百分之多少时停止接受写请求。如果设置为no,将仍然接受查询请求,即使它只是请求部分key。
6、创建并使用Redis集群(Creating and using a Redis Cluster)
为了创建集群,首先我必须有一些以集群模式(cluster mode)运行的Redis实例。
下面是一个最小的Redis集群配置文件:
2
3
4
5
6
2cluster-enabled yes
3cluster-config-file nodes.conf
4cluster-node-timeout 5000
5appendonly yes
6
正如你看到的那样,启用集群模式只需要配置cluster-enabled指令为yes即可。每个实例都包含一个文件,这个文件存储该节点的配置,模式是nodes.conf。这个文件从来不会被手动创建,它是Redis集群实例启动的时候生成的,并且每次在需要的时候自动更新。
Note that the minimal cluster that works as expected requires to contain at least three master nodes.
最小的集群至少需要3个master节点。这里,我们为了测试,用三主三从。
2
3
4
2cd cluster-test
3mkdir 7000 7001 7002 7003 7004 7005
4
2
3
4
5
6
7
8
2touch redis.conf
3cp 7000/redis.conf 7001/
4cp 7000/redis.conf 7002/
5cp 7000/redis.conf 7003/
6cp 7000/redis.conf 7004/
7cp 7000/redis.conf 7005/
8
2
2
现在的目录结构应该是这样的:

修改端口,依次启动各个实例:
2
3
4
5
6
7
8
9
10
11
12
13
14
15
2./redis-server 7000/redis.conf
3
4cd 7001
5./redis-server 7001/redis.conf
6
7cd 7002
8./redis-server 7002/redis.conf
9
10cd 7003
11./redis-server 7003/redis.conf
12
13cd 7004
14./redis-server 7004/redis.conf
15



正如你看到的那样,每个Redis实例都有一个ID,在节点的整个生命周期中这个唯一的code是不会变的,我们把它叫做Node ID
6.1、创建集群
最简单的实现是用redis-trib工具,它在src目录下。它是一个ruby程序,所以需要先安装ruby。
2
3
4
2yum install rubygems
3gem install redis
4
这个时候可能会报错,如下:

于是,要升级Ruby版本
2
3
4
5
6
2curl -sSL https://get.rvm.io | bash -s stable
3source /etc/profile.d/rvm.sh
4rvm list known
5rvm install 2.4.1
6
接下来,创建集群
2
3
2./redis-trib.rb create --replicas 1 127.0.0.1:7000 127.0.0.1:7001 127.0.0.1:7002 127.0.0.1:7003 127.0.0.1:7004 127.0.0.1:7005
3
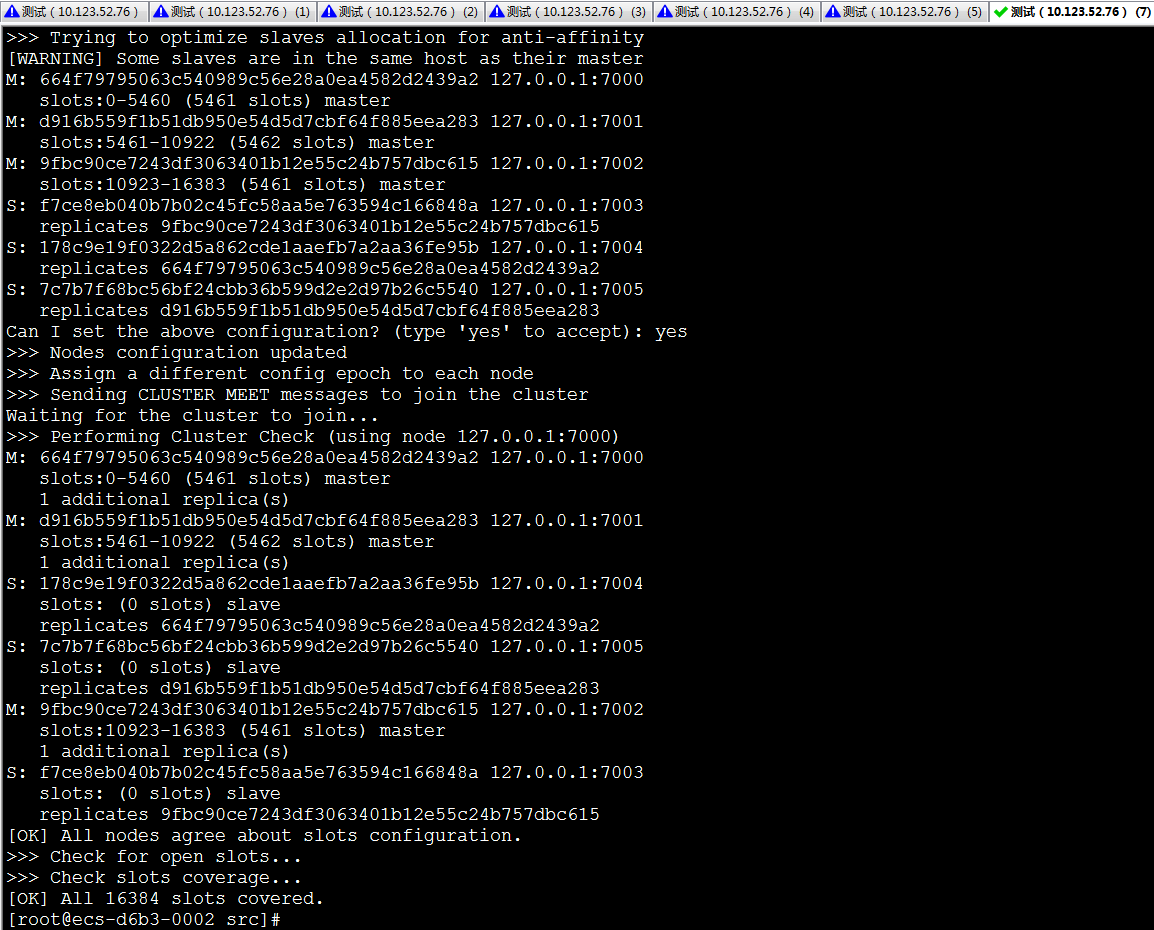
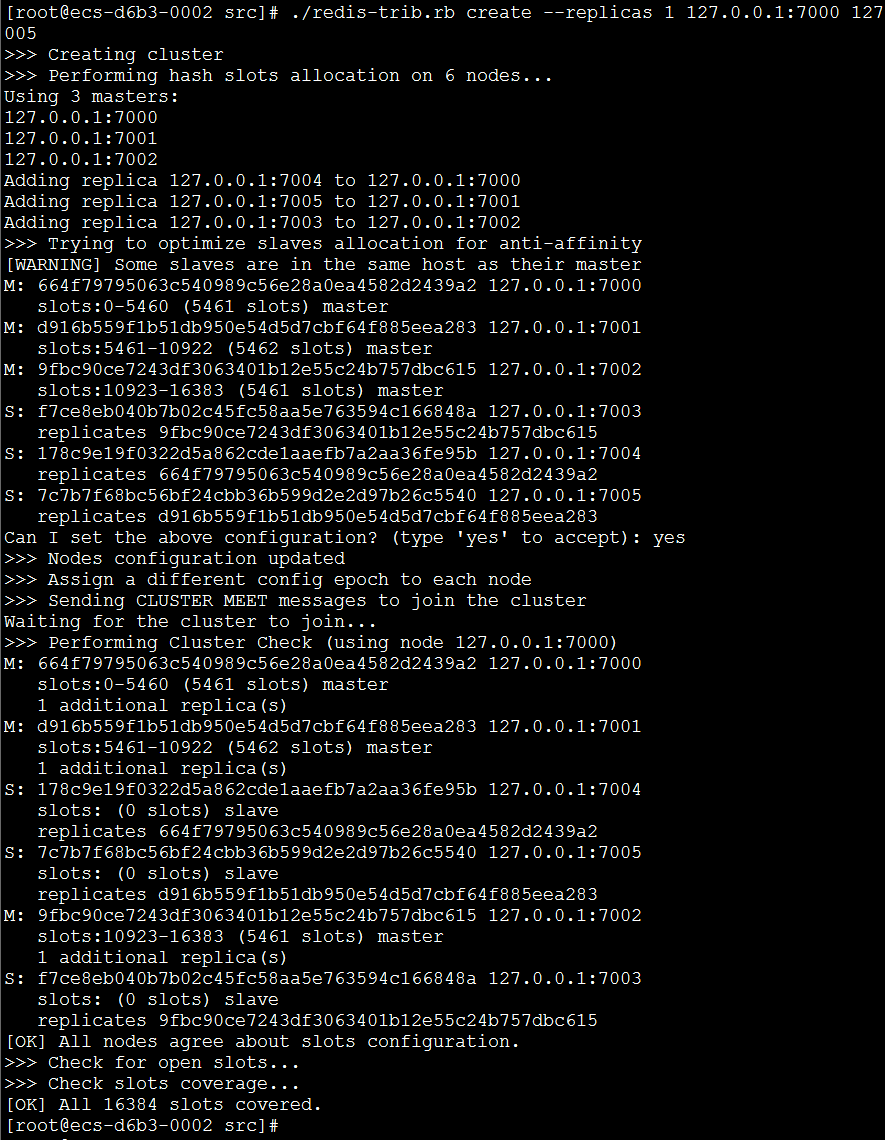
这里,我们使用create命令来创建一个新的集群。选项–replicas 1表示我们想为每个master指定一个slave。其余参数是需要加到集群的实例地址。

我们可以看到,7000、7001、7002是master,7004是7000的slave,7005是7001的slave,7003是7002的slave。
cluster nodes命令的输出格式是这样的:
- Node ID
- ip:port
- flags: master, slave, myself, fail, …
- if it is a slave, the Node ID of the master
- Time of the last pending PING still waiting for a reply.
- Time of the last PONG received.
- Configuration epoch for this node (see the Cluster specification).
- Status of the link to this node.
- Slots served…
接下来,设置一个key试试:
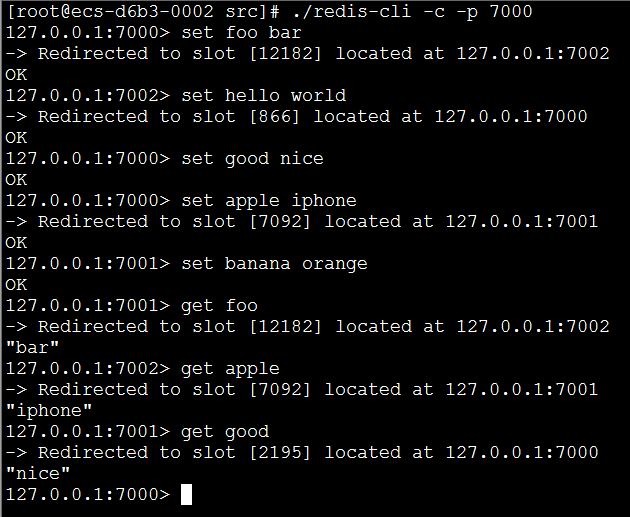
6.2、添加一个新节点(Adding a new node)
添加一个新节点基本上就是添加一个空节点,然后将一些数据移动到其中,在这种情况下,它是一个新的master,或者你明确的设置它作为副本,那么这种情况下它就是一个slave。
2
3
4
5
6
2[root@ecs-d6b3-0002 cluster-test]# cp -R 7005 7006
3[root@ecs-d6b3-0002 cluster-test]# vi 7006/redis.conf
4[root@ecs-d6b3-0002 cluster-test]# cd 7006
5[root@ecs-d6b3-0002 7006]# ../redis-server redis.conf
6
现在,我们用redis-trib来添加一个节点到已存在的集群:
2
2
As you can see I used the add-node command specifying the address of the new node as first argument, and the address of a random existing node in the cluster as second argument.
正如你看到的那样,add-node命令的第一个参数是新节点的地址,第二个参数是已存在的集群中的任意节点地址。事实上,redis-trib只是发了一个cluster meet消息给这个节点。
(PS:我在操作的过程中发现,不用add-node命令,直接启动7006以后它就直接加入集群了,不知道是不是因为我是同一台机器上操作,或者是因为只有一个集群,我猜测可能是因为这是一个伪集群,哈哈哈,先不管了。。。)
6.3、添加一个节点作为副本(Adding a new node as a replica)
2
2

6.4、删除一个节点(Removing a node)
2
2
2
2
6.5、重新分片(Resharding the cluster)
2
2
2
2
6.6、杀死Redis实例
2
2
6.7、停止集群/删除集群
删除集群就是依次删除集群中的所有节点,但在此之前需要将带删除的节点上的数据迁移到其它节点上,因此需要重新分片。
后来想想,其实也没有必要停止集群
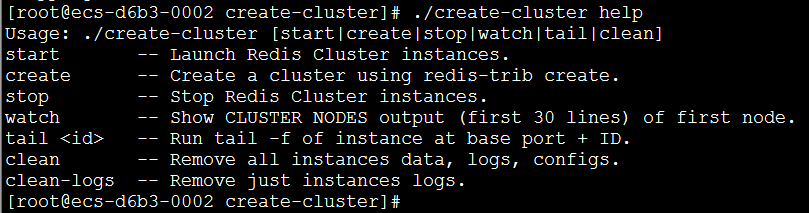
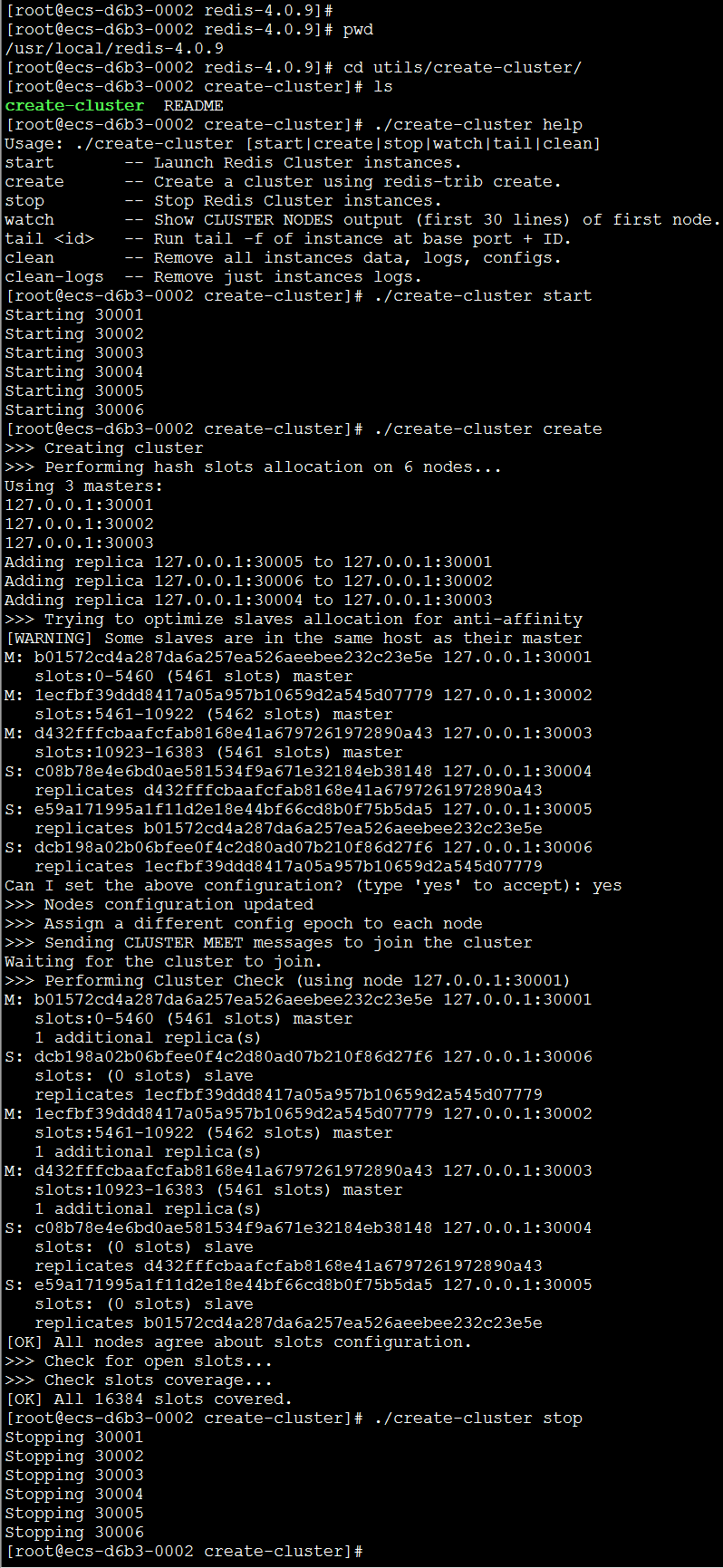
6.8、用create-cluster创建集群
之前我们创建集群用的是redis-trib,现在我们用create-cluster来创建集群。
- 进入utils/create-cluster,可以看README
- create-cluster start
- create-cluster create
7、help