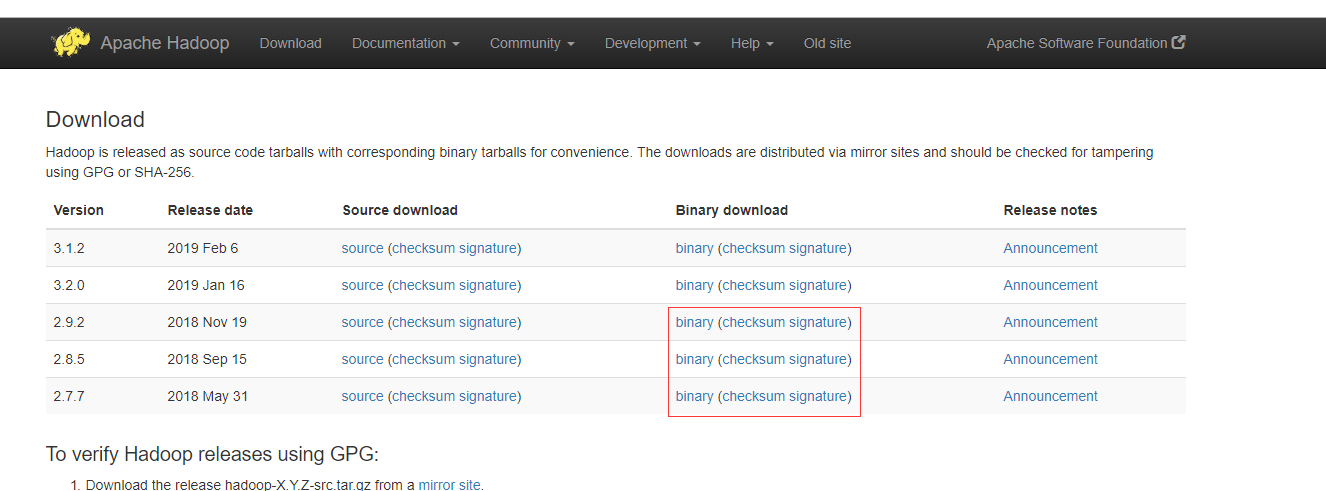
下载地址:http://hadoop.apache.org/releases.html 下载2.X版本
Hadoop的安装分为单机方式、伪分布式方式和完全分布式方式
单机模式
单机模式是Hadoop的默认模式。当首次解压Hadoop的源码包时,Hadoop无法了解硬件安装环境,便保守地选择了最小配置。在这种默认模式下所有3个XML文件均为空。当配置文件为空时,Hadoop会完全运行在本地。因为不需要与其他节点交互,单机模式就不使用HDFS,也不加载任何Hadoop的守护进程。该模式主要用于开发调试MapReduce程序
的应用逻辑。
伪分布模式
Hadoop守护进程运行在本地机器上,模拟一个小规模的的集群。可以使用HDFS和MapReduce b.
全分布模式 Hadoop守护进程运行在一个集群上。
全分布模式,启动所有的守护进程,具有hadoop完整的功能,可以使用HDFS、MapReduce和Yarn,并且这些守护进程运行在集群中,可以
真正的利用集群提供高性能,在生产环境下使用
伪分布式安装
因为日常开发没有那么多的机器可以搭建集群,所以伪分布式已经可以满足开发需要了
1关闭防火墙
2
3
4
2永久关闭:chkconfig iptables off
3
4
2配置主机名
需要注意的是Hadoop的集群中的主机名不能有_。如果存在_会导致Hadoop集群无法找到这群主机,无法启动!
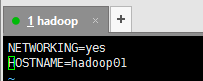
编辑network文件:vim /etc/sysconfig/network
将HOSTNAME属性改为指定的主机名,例如:HOSTNAME=hadoop01
让network文件重新生效:source /etc/sysconfig/network
3配置hosts文件,将主机名和ip地址进行映射
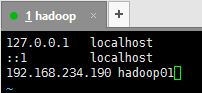
编辑hosts文件:vim /etc/hosts
将主机名和ip地址对应,例如:192.168.234.190 hadoop01
4配置ssh进行免密互通
生成自己的公钥和私钥,生成的公私钥将自动存放在/root/.ssh目录下:ssh-keygen
把生成的公钥拷贝到远程机器上,格式为:ssh-copy-id [user]@host,例如:ssh-copy-id root@hadoop01
5重启Linux让主机名的修改生效:reboot
6上传或者下载Hadoop安装包到Linux中
7解压安装包:tar -xvf hadoop-2.7.1_64bit.tar.gz
8进入Hadoop的安装目录的子目录etc/hadoop
进入配置文件夹Hadoop:cd hadoop2.7.1/etc/hadoop
9编辑 hadoop-env
2
3
4
5
6
7
2修改JAVA_HOME的路径,修改成具体的路径。例如:export JAVA_HOME=/home/software/jdk1.8
3修改HADOOP_CONF_DIR的路径,修改为具体的路径,例如:export HADOOP_CONF_DIR=/home/software/hadoop-2.7.1/etc/hadoop
4保存退出文件
5重新加载生效:source hadoop-env.sh
6
7
10配置 core-site.xml
编辑core-site.xml:vim core-site.xml
添加如下内容:
2
3
4
5
6
7
8
9
10
11
12
13
14
2 <property>
3 <!-- 指定HDFS中的主节点 - namenode -->
4 <name>fs.defaultFS</name>
5 <value>hdfs://hadoop01:9000</value>
6 </property>
7 <property>
8 <!-- 执行Hadoop运行时的数据存放目录 -->
9 <name>hadoop.tmp.dir</name>
10 <value>/home/software/hadoop-2.7.1/tmp</value>
11 </property>
12</configuration>
13
14
11配置 hdfs-site.xml
编辑hdfs-site.xml:vim hdfs-site.xml
添加如下配置:
2
3
4
5
6
7
8
9
10
2 <property>
3 <!-- 设置HDFS中的复本数量 -->
4 <!-- 在伪分布式下,值设置为1 -->
5 <name>dfs.replication</name>
6 <value>1</value>
7 </property>
8</configuration>
9
10
12配置 mapred-site.xml
将mapred-site.xml.template复制为mapred-site.xml:
2
3
2
3
编辑mapred-site.xml:
2
3
2
3
添加如下配置:
2
3
4
5
6
7
8
9
2 <property>
3 <!-- 指定将MapReduce在Yarn上运行 -->
4 <name>mapreduce.framework.name</name>
5 <value>yarn</value>
6 </property>
7</configuration>
8
9
13配置 yarn-site.xml
编辑yarn-site.xml:
2
3
2
3
添加如下内容:
2
3
4
5
6
7
8
9
10
11
12
13
14
2 <!-- 指定Yarn的主节点 - resourcemanager -->
3 <property>
4 <name>yarn.resourcemanager.hostname</name>
5 <value>hadoop01</value>
6 </property>
7 <!-- NodeManager的数据获取方式 -->
8 <property>
9 <name>yarn.nodemanager.aux-services</name>
10 <value>mapreduce_shuffle</value>
11 </property>
12</configuration>
13
14
14配置slaves
编辑slaves:
2
3
2
3
添加从节点信息,例如:hadoop01
保存退出
15配置hadoop的环境变量
编辑profile文件:
2
3
2
3
在最后添加Hadoop的环境变量,例如:
2
3
4
2export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
3
4
保存退出
重新生效:
2
3
2
3
16格式化namenode
配置完环境变量后可以直接使用hadoop命令
2
3
2
3
17启动hadoop
启动后可以访问hadoop
2
3
2
3
注意事项
1、如果Hadoop的配置没有生效,那么需要重启Linux 1.
2、在格式化的时候,会有这样的输出:Storage directory /tmp/hadoop-root/dfs/name has been successfully formatted。如果出现这句话,说明格式化成功
3、Hadoop如果启动成功,会出现5个进程:Namenode,Datanode,Secondarynamenode,ResourceManager,NodeManager
jps:显示jvm进程。
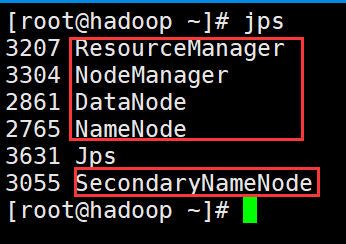
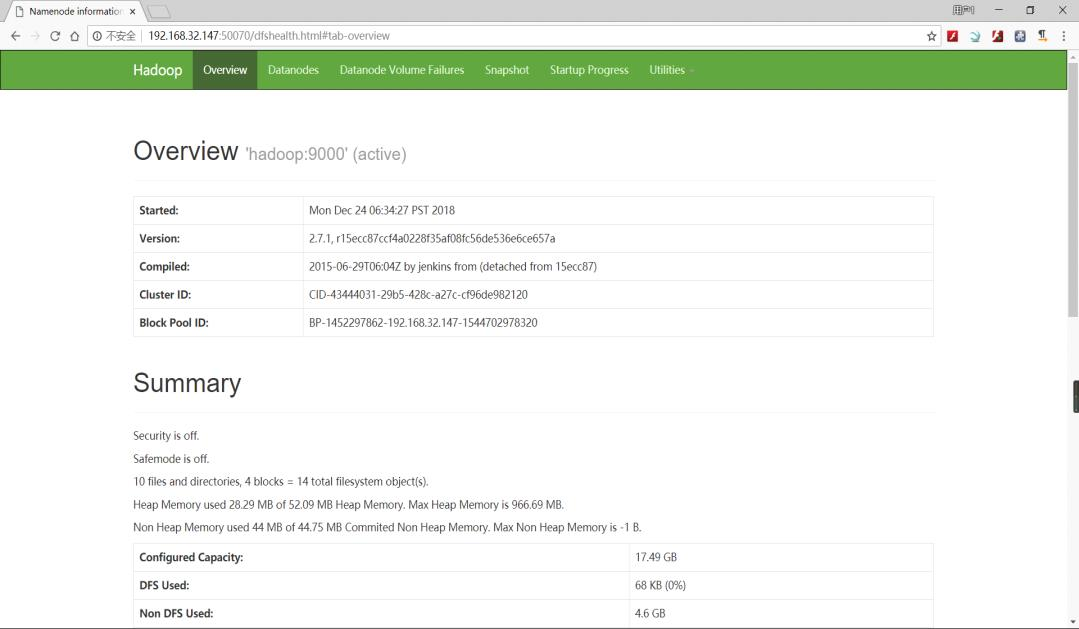
4、Hadoop启动成功后,可以通过浏览器访问HDFS的页面,访问地址为:IP地址:50070
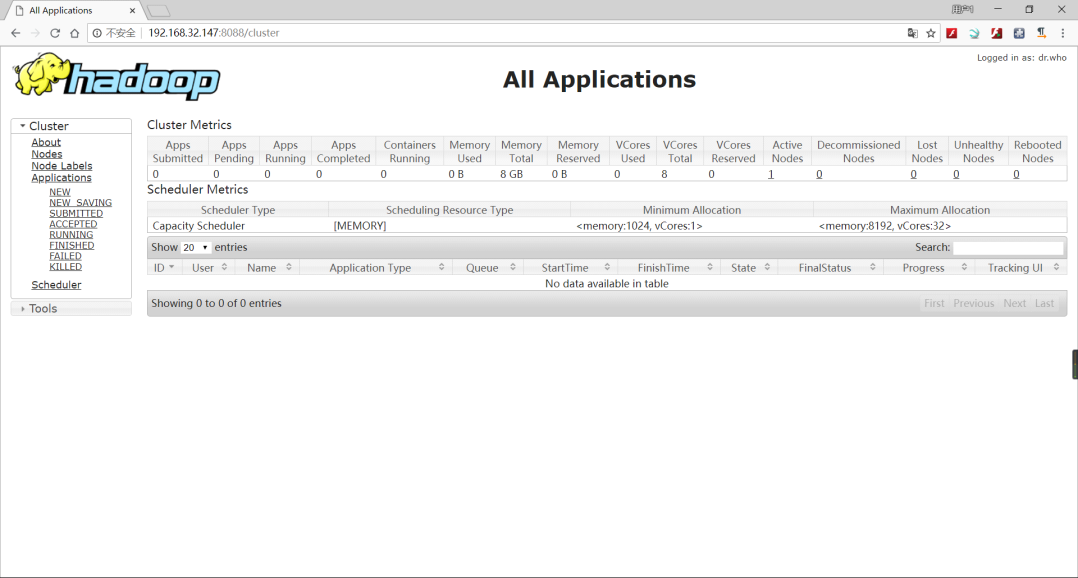
5、Hadoop启动成功后,可以通过浏览器访问Yarn的页面,访问地址为:http://IP地址:8088
常见问题
1、执行Hadoop指令,比如格式化:hadoop namenode -format 出现:command找不到错误
解决方案:检查:/etc/profile的Hadoop配置
2、少HFDS相关进程,比如少namenode,datanode
解决方案:可以去Hadoop 安装目录下的logs目录,查看对应进程的启动日志文件。
方式一:①先停止HDFS相关的所有的进程(stop-dfs.sh 或 kill -9)②再启动HDFS(start-dfs.sh)
方式二:①先停止HDFS相关的所有的进程 ②删除元数据目录 ③重新格式化:hadoop namenode -format④启动Hadoop:start-all.sh
