官方github地址: https://github.com/darkrho/scrapy-redis
什么是分布式:略
scrapy-redis:一个三方基于热点redis分布式的爬虫框架,与scrapy一起使用,使用爬虫具有分布式的功能。
分布式爬虫原理:
分布式爬虫一般分两端,一个是服务器端(master),一个是爬虫程序端(slave),
master:为爬虫程序服务者,一般一台,一般用来提供url数据,当然也可以用来爬取数据,但是不推荐。我的是win7系统;
slave:为爬虫程序的执行者,一般多台,从master中拿到url,再爬取数据。我的是虚拟机里的centos系统;
过程:
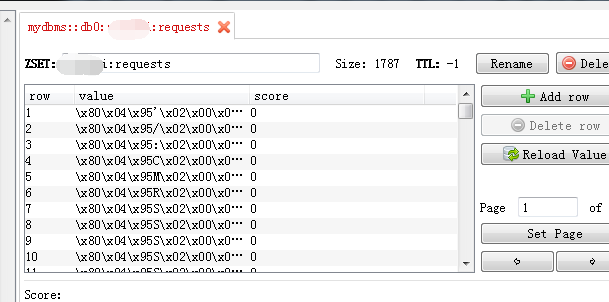
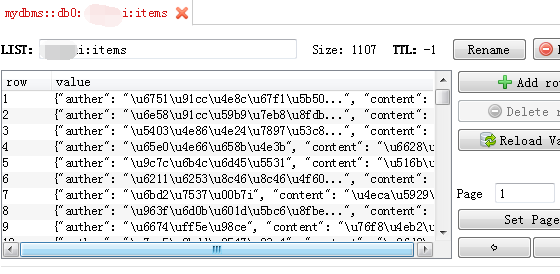
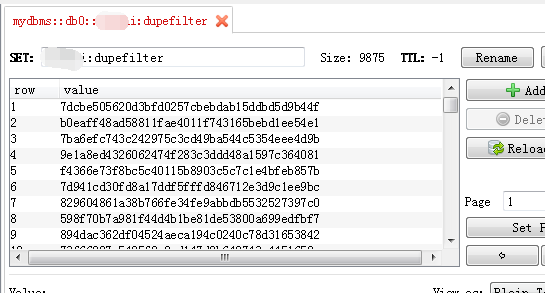
在爬虫有任务的情况下(一般在redis里),redis数据库会产生三个库(dbname:dupefilter,dbname:requests,dbname:items),slave会根据数据库(dbname:dupefilter)中相应的指纹从数据库(dbname:requests)中的提取url进行数据爬取,同也会把相应的数据放入到数据库(dbname:items)中。
数据库说明:
dbname:dupefilter :存储url相应的指纹,用来防止url的重复爬取;
dbname:requests:存储提取到的url;
dbname:items:存储爬取到的数据;
配置前提:
一台master(win7),多台slave(centos7)
master装好redis,python相应的版本与应用库
centos7装好python相应的版本与应用库,并保证与master能连通。
redis配置设置:
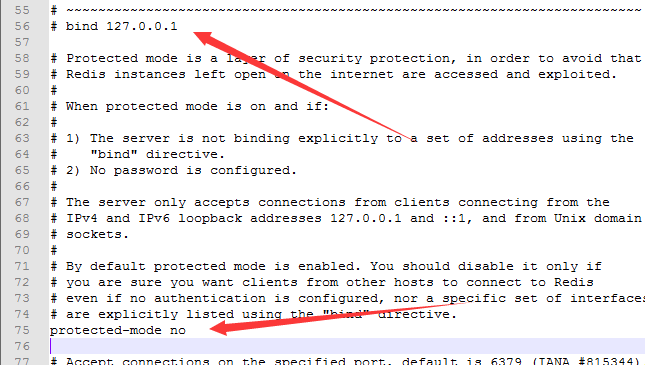
打开:redis.windows.conf文件
注释掉:bind 127.0.0.1
protected-mode yes 改为 no
程序过程:
本文使用的是RedisCrawlSpider类
先保证scrapy程序能正常运行。再进行修改。
以代码做解释:
spider类:
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
2import scrapy
3from scrapy.linkextractors import LinkExtractor
4from scrapy.spiders import CrawlSpider, Rule
5from scrapy_redis.spiders import RedisCrawlSpider
6
7class QiushiSpider(RedisCrawlSpider): # 继承RedisCrawlSpider
8 name = 'xxx'
9 allowed_domains = ['xxx.com']
10 # start_urls = ['https://www.xxx.com/text/']
11 redis_key = 'qiushi:start_urls' # 设置start_url
12
13 # 提取对应的url规则
14 rules = (
15 Rule(LinkExtractor(allow=r'/article/\d+'), callback='parse_item', follow=True),
16 Rule(LinkExtractor(allow=r'/text/page/\d+/'), callback='parse_item', follow=True),
17 )
18
19 def parse_item(self, response):
20 auther = response.xpath('//span[@class="side-user-name"]').extract_first().strip()
21 content = response.xpath('//div[@class="content"]').extract_first().strip()
22
23 yield {
24 "auther": auther,
25 "content": content
26 }
27
28
settings设置:
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
2DUPEFILTER_CLASS = "scrapy_redis.dupefilter.RFPDupeFilter"
3SCHEDULER = "scrapy_redis.scheduler.Scheduler"
4SCHEDULER_PERSIST = True # 是否允许暂停
5#SCHEDULER_QUEUE_CLASS = "scrapy_redis.queue.SpiderPriorityQueue"
6#SCHEDULER_QUEUE_CLASS = "scrapy_redis.queue.SpiderQueue"
7#SCHEDULER_QUEUE_CLASS = "scrapy_redis.queue.SpiderStack"
8
9ITEM_PIPELINES = {
10 'scrapy_redis.pipelines.RedisPipeline': 400,
11}
12
13LOG_LEVEL = 'DEBUG'
14
15REDIS_HOST = '192.168.8.101' # 访问master的主机ip
16REDIS_PORT = '6379' # reids端口
17
18
19
其它不用改。
将程序拷贝到centos里面。并切换到spiders目录中
运行对应的爬虫命令:
2
2
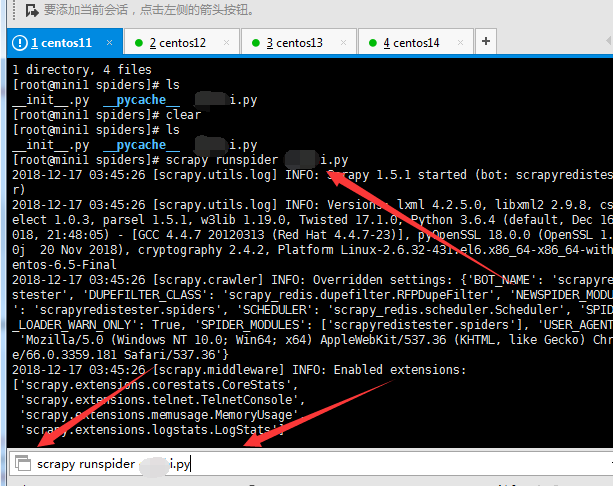
数据:
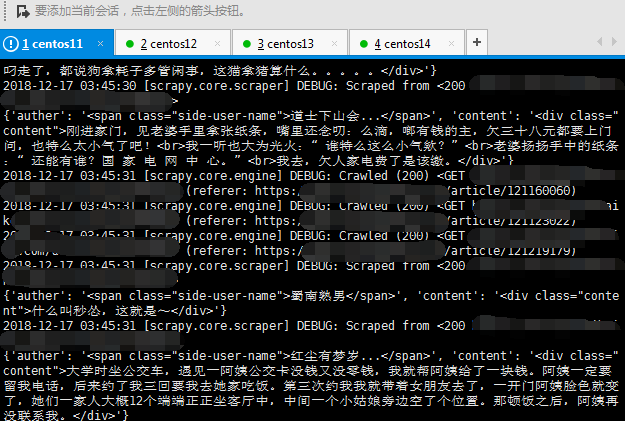
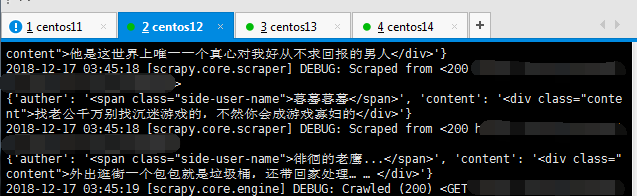
可以看到数据在正常爬取。看看redis里的数据