研判银行间资金利率走势,对于分析债券市场而言非常重要。
1 | Facebook |
在2017年开源了一个时间序列预测的算法,叫做
1 | fbprophet |
,其功能包括:
- 为预测设置上下限;
- 设置趋势断点;
- 处理季节性和节假日效应;
- 允许乘法形式的季节性;
- 区间预测;
- 处理异常值;
- 处理非日度数据;
- 模型检测。
我们认为,可以用这个算法,来为银行间资金利率,做出一个基础性的预测。初步探索如下:
一、安装
我们推荐使用conda安装,由于
1 | fbprophet |
需要调用
1 | pyStan |
这个开源工具,因此安装命令为下述两条:
2
3
4
conda config --add channels https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud/conda-forge/
conda config --add channels https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud/msys2/
conda config --set show_channel_urls yes
conda update –force conda
conda install libpython m2w64-toolc
!
1 | conda install -c conda-forge pystan |
1 | conda install -c conda-forge fbprophet |
conda clean -i
conda config –add channels https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud/bioconda
conda安装软件时出现
2
3
4
5
6
7
...
An unexpected error has occurred. Conda has prepared the above report.
If submitted, this report will be used by core maintainers to improve
future releases of conda.
Would you like conda to send this report to the core maintainers?
如果有重装过anaconda,在根目录下,会有一个名叫.condarc的文件会自动生成。
当使用conda install和conda create命令会出现下面的问题:Collecting package metadata (current_repodata.json): failed
2
rm -rf ~/.condarc
二、数据准备
1 | fbprophet |
的基础输入数据只需要两列,第一列是日期,第二列是要拟合和预测的时间序列数据。在本文中,我们使用3个月的SHIBOR作为案例。要注意的一点是,数据的变量名,一定修改成
1 | ds |
和
1 | y |
。原始数据如下:
三、初步处理
1 | fbprophet |
算法的大概步骤是,先生成一个
1 | Prophet |
实例,然后调用
1 | fit |
方法进行拟合,调用
1 | predict |
方法进行拟合。代码如下:
1 | m = Prophet() m.fit(data) future_time = m.make_future_dataframe(periods=365) forecast = m.predict(future_time) fig1 = m.plot(forecast) fig2 = m.plot_components(forecast) |
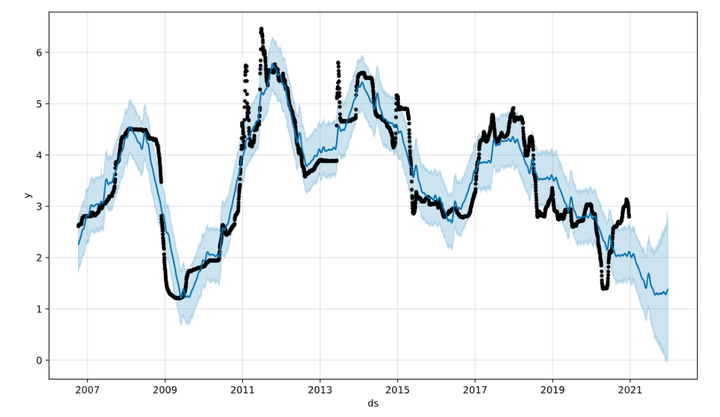
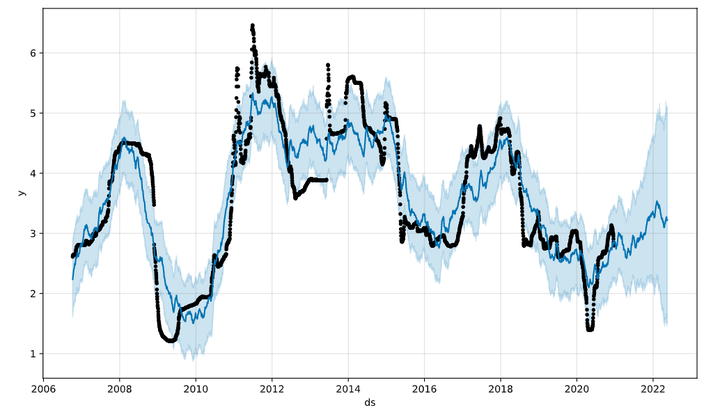
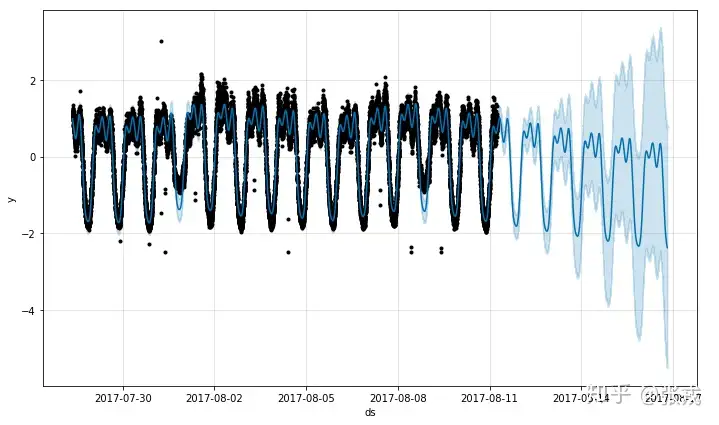
下图就是模型预测的初步结果,其中黑色表示原始数据的离散点,深蓝色线表示通过时间序列模型拟合的值,浅蓝色区域表示预测的置信区间。
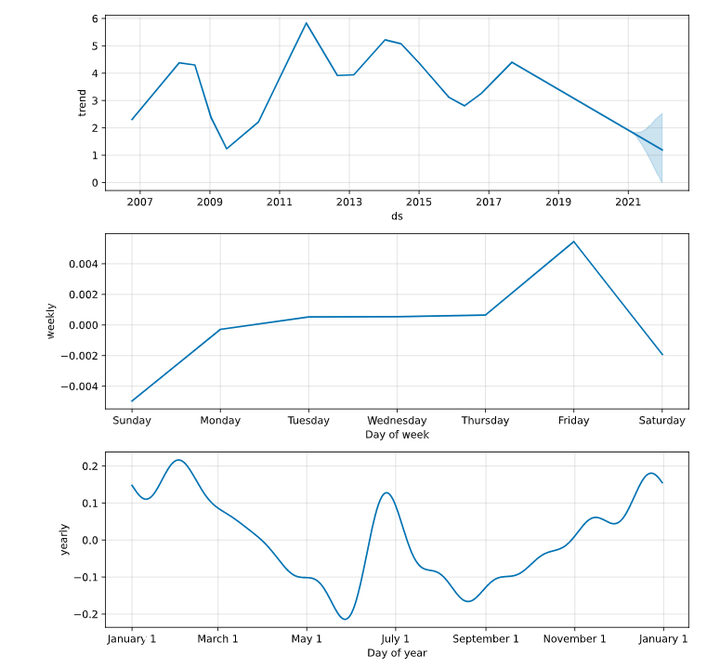
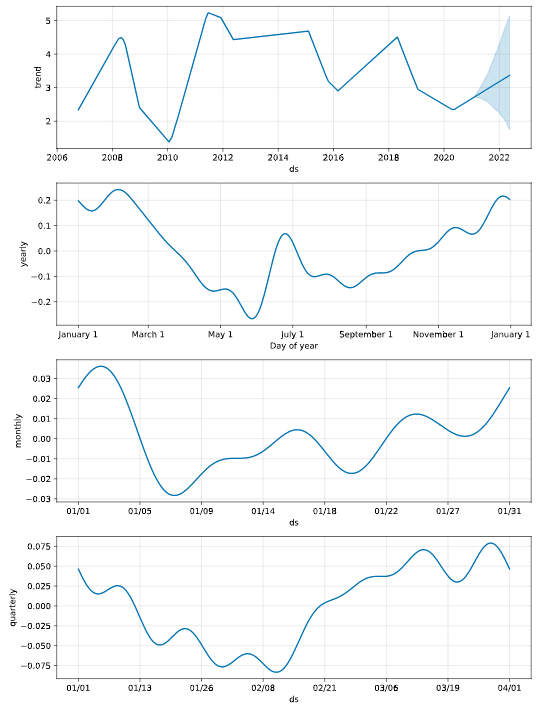
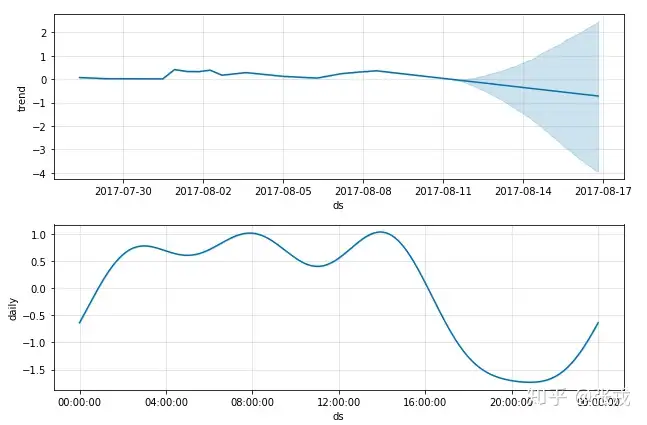
我们来看看模型提取出的时间序列分项,从下图可以看到,模型自2018年之后,对资金利率的趋势预测是线性向下的。从年内各月份的资金利率规律来看,呈现出上半年下行、下半年上行、年中短暂跳升的W型。从周内的规律来看,周五有一个明显的跳升。
四、进一步修正
1、趋势项预测方法的选择。
1 | fbprophet |
模型中,对趋势项的预测有两种方法,第一种是基于逻辑回归函数(
1 | logistic function |
),一般用来拟合单向增长或下降,但是增长或者下降有界限的数据,第二种是基于分段线性函数(
1 | piecewise linear function |
)。我们在本案例中选择第二种方法,这也是
1 | fbprophet |
模型的默认方法,不需要单独设定。
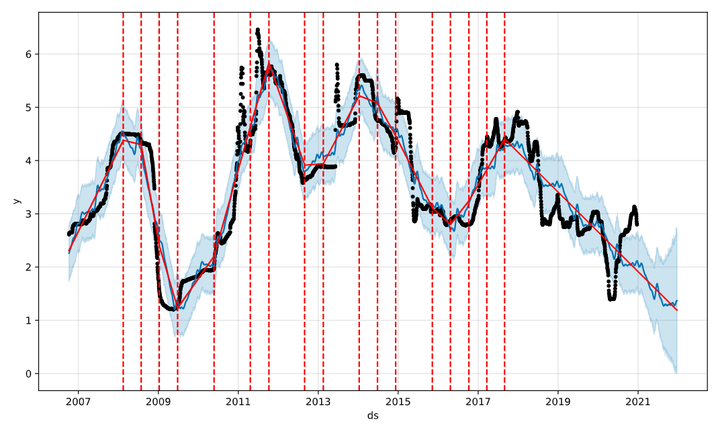
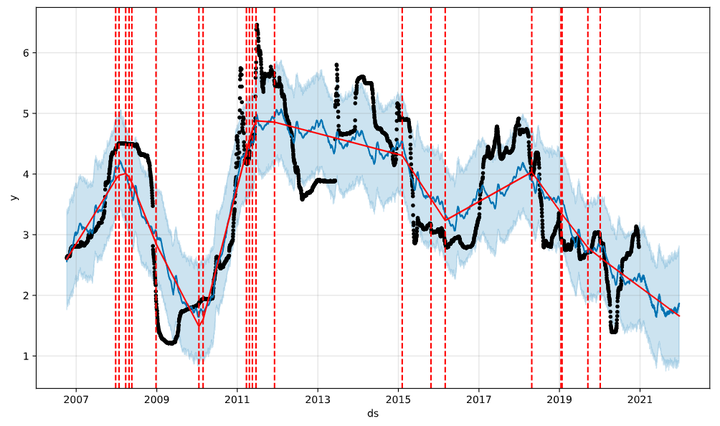
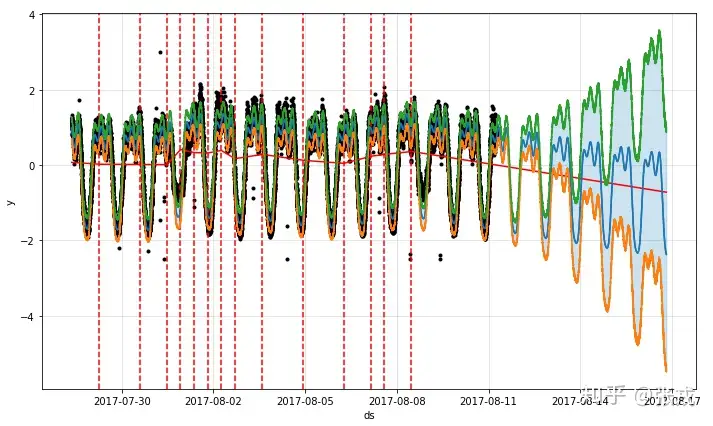
2、趋势变点的设定和检测。 时间序列数据中,趋势的方向可能会出现变化,这就是所谓的“变点”。
1 | fbprophet |
模型会自动识别变点,而且为了避免过拟合的问题,模型默认在前80%的样本中识别变点。下图用红色竖线标识出模型自动识别的变点,根据最新识别的变点,整体趋势预测是下行的:
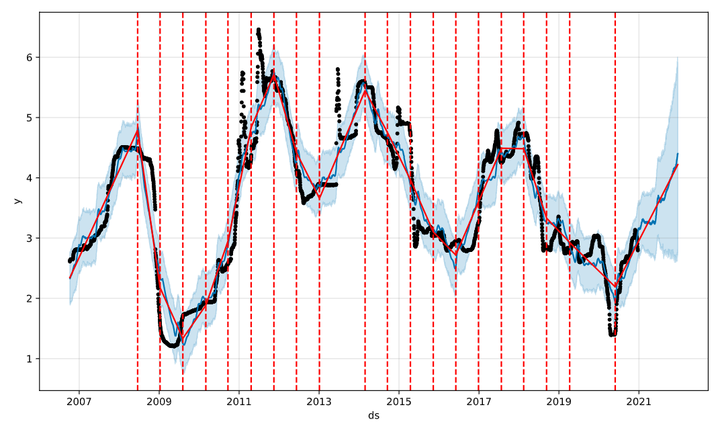
我们可以用
1 | changepoint_range |
来调整设置变点的范围,比如我们修改设置
1 | changepoint_range=1 |
,可以看到,模型将5月份以来的资金面边际收紧,识别为未来的趋势,对未来资金利率的预测整体上行,这就产生了过拟合的问题。
我们也可以手动设置变点的位置,比如我们认为,银行间资金利率,受到准备金率调整的影响特别大,那么就可以把调整准备金率的时间,作为变点进行输入,结果如下:
3、节假日调整。 在很多时间序列中,节假日是很常见的影响因子,我们可以在模型中添加下述语句,来纳入中国的节假日,
1 | fbprophet |
模型中纳入的中国节假日有:元旦、春节、清明节、劳动节、端午节、中秋节 国庆节。由于这些假日银行间市场一般都不交易,所以我们在本案例中不予处理。
1 | m.add_country_holidays(country_name='CN') |
4、季节性设置。
1 | fbprophet |
模型中,默认识别的季节性是周度和年度,但是对于银行间资金利率而言,周度的季节性特征并不明显,但是月度和季度的季节性比较明显,因此我们需要把周度季节性调整成月度和季度季节性。
从季节性分解图上可以看到,资金利率在月内有比较明显的季节性,月初缴准是一个高点,下旬税期是一个高点,月末是一个高点。资金利率在每个季度的最后一个月,利率偏高。
5、工作日调整。 因为银行间资金利率,只有工作日有数据,因此我们需要对预测的工作日进行调整:
1 | future_time = m.make_future_dataframe(periods=365,freq='B') |
五、优缺点分析
1 | fbprophet |
模型速度比较快,而且有一定的灵活度,可以自行设置节假日、淡旺季、工作日、季节性特征、变点等,是一个功能很强大的模型。
但是缺点也比较明显,就是模型仅基于历史数据进行预测,无法引入外部变量,比如央行降准,或者大额超量续作MLF等,都会对资金利率带来明显影响,但是模型无法捕捉这种外生变量。因此笔者认为,
1 | fbprophet |
模型可以基于时间序列特征,提供一个很好的基准情形,然后我们再根据其他外部因素进行调整。
我们对未来1年的资金利率的预测结果和代码如下:
1 | m = Prophet(changepoints=rrr.index.astype(str).tolist(),weekly_seasonality=False) m.add_seasonality(name='monthly', period=30.5, fourier_order=5) m.add_seasonality(name='quarterly', period=90, fourier_order=7) future_time = m.make_future_dataframe(periods=365,freq='B') forecast = m.fit(data).predict(future_time) fig1 = m.plot(forecast) fig2 = m.plot_components(forecast) |
实践操作:
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
from fbprophet import Prophet
from pandas.plotting import register_matplotlib_converters
from fbprophet.plot import add_changepoints_to_plot
df = pd.read_csv('csv.csv')
# Z-score标准化归一
#df['y'] = (df['y'] - df['y'].mean()) / (df['y'].std())
print(df.head())
special_days = pd.DataFrame({
'holiday': 'holiday_or_discount',
'ds': pd.to_datetime(['2022-01-15', '2022-02-14']),
'lower_window': -1,
'upper_window': 1,
})
discountday = pd.DataFrame({
'holiday': 'discountday',
'ds': pd.to_datetime(['2022-08-01']),
'lower_window': -1,
'upper_window': 2,
})
#holidays = pd.concat((special_days, discountday))
holidays = special_days
m = Prophet(yearly_seasonality=False,
weekly_seasonality=True,
holidays= holidays,
daily_seasonality=False,
#自动的潜在改变点的灵活性调节参数,较大值将允许更多的潜在改变点,较小值将允许更少的潜在改变点,即变化速率灵活性
changepoint_prior_scale=0.15,
#changepoint_prior_scale=0.35,
#调整模型对于季节性的拟合程度
seasonality_prior_scale=10,
holidays_prior_scale=10
# 不确定性区间宽度
#interval_width=0.50,
)
#m.add_seasonality(name='monthly', period=30.5, fourier_order=5)
m.fit(df)
# 预测天数
fday = 14
future = m.make_future_dataframe(periods=fday)
future['cap'] = 200
future['floor'] = 0
print(future.tail(fday))
forecast = m.predict(future)
print(forecast[['ds', 'yhat', 'yhat_lower', 'yhat_upper']].tail(fday))
# add_regressor
#a = add_changepoints_to_plot(fig1.gca(), m, forecast)
register_matplotlib_converters()
#AttributeError: module 'PIL.Image' has no attribute 'register_extensions'
#pip install pillow==4.1.1
fig1 = m.plot(forecast)
fig1.show()
fig2 = m.plot_components(forecast)
fig2.show()
Prophet 中可以设置的参数
在 Prophet 中,用户一般可以设置以下四种参数:
- Capacity:在增量函数是逻辑回归函数的时候,需要设置的容量值。
- Change Points:可以通过 n_changepoints 和 changepoint_range 来进行等距的变点设置,也可以通过人工设置的方式来指定时间序列的变点。
- 季节性和节假日:可以根据实际的业务需求来指定相应的节假日。
- 光滑参数: τ= changepoint_prior_scale 可以用来控制趋势的灵活度, σ= seasonality_prior_scale 用来控制季节项的灵活度, v= holidays prior scale 用来控制节假日的灵活度。
如果不想设置的话,使用 Prophet 默认的参数即可。
Prophet 的实际使用
Prophet 的简单使用
因为 Prophet 所需要的两列名称是 ‘ds’ 和 ‘y’,其中,’ds’ 表示时间戳,’y’ 表示时间序列的值,因此通常来说都需要修改 pd.dataframe 的列名字。如果原来的两列名字是 ‘timestamp’ 和 ‘value’ 的话,只需要这样写:
如果 ‘timestamp’ 是使用 unixtime 来记录的,需要修改成 YYYY-MM-DD hh:mm:ss 的形式:
在一般情况下,时间序列需要进行归一化的操作,而 pd.dataframe 的归一化操作也十分简单:
然后就可以初始化模型,然后拟合模型,并且进行时间序列的预测了。
2
3
4
5
6
拟合模型:m.fit(df)
计算预测值:periods 表示需要预测的点数,freq 表示时间序列的频率。
future = m.make_future_dataframe(periods=30, freq='min')
future.tail()
forecast = m.predict(future)
而 freq 指的是 pd.dataframe 里面的一个指标,’min’ 表示按分钟来收集的时间序列。具体参见文档:http://pandas.pydata.org/pandas-docs/stable/timeseries.html#offset-aliases
在进行了预测操作之后,通常都希望把时间序列的预测趋势画出来:
2
3
4
m.plot(forecast)
画出时间序列的分量:
m.plot_components(forecast)
如果要画出更详细的指标,例如中间线,上下界,那么可以这样写:
2
3
4
5
6
7
8
y1 = forecast['yhat']
y2 = forecast['yhat_lower']
y3 = forecast['yhat_upper']
plt.plot(x1,y1)
plt.plot(x1,y2)
plt.plot(x1,y3)
plt.show()
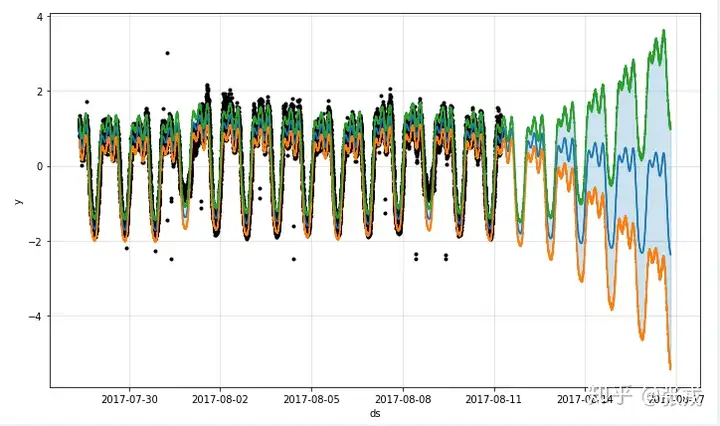
其实 Prophet 预测的结果都放在了变量 forecast 里面,打印结果的话可以这样写:第一行是打印所有时间戳的预测结果,第二行是打印最后五个时间戳的预测结果。
2
print(forecast[['ds', 'yhat', 'yhat_lower', 'yhat_upper']].tail())
Prophet 的参数设置
Prophet 的默认参数可以在 forecaster.py 中看到:
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
self,
growth='linear',
changepoints=None,
n_changepoints=25,
changepoint_range=0.8,
yearly_seasonality='auto',
weekly_seasonality='auto',
daily_seasonality='auto',
holidays=None,
seasonality_mode='additive',
seasonality_prior_scale=10.0,
holidays_prior_scale=10.0,
changepoint_prior_scale=0.05,
mcmc_samples=0,
interval_width=0.80,
uncertainty_samples=1000,
):
增长函数的设置
在 Prophet 里面,有两个增长函数,分别是分段线性函数(linear)和逻辑回归函数(logistic)。而 m = Prophet() 默认使用的是分段线性函数(linear),并且如果要是用逻辑回归函数的时候,需要设置 capacity 的值,i.e. df[‘cap’] = 100,否则会出错。
2
3
m = Prophet(growth='linear')
m = Prophet(growth='logistic')
变点的设置
在 Prophet 里面,变点默认的选择方法是前 80% 的点中等距选择 25 个点作为变点,也可以通过以下方法来自行设置变点,甚至可以人为设置某些点。
2
3
4
m = Prophet(changepoint_range=0.8)
m = Prophet(changepoint_prior_scale=0.05)
m = Prophet(changepoints=['2014-01-01'])
而变点的作图可以使用:
2
3
fig = m.plot(forecast)
a = add_changepoints_to_plot(fig.gca(), m, forecast)
周期性的设置
通常来说,可以在 Prophet 里面设置周期性,无论是按月还是周其实都是可以设置的,例如:
2
3
4
m.add_seasonality(name='monthly', period=30.5, fourier_order=5)
m = Prophet(weekly_seasonality=True)
m.add_seasonality(name='weekly', period=7, fourier_order=3, prior_scale=0.1)
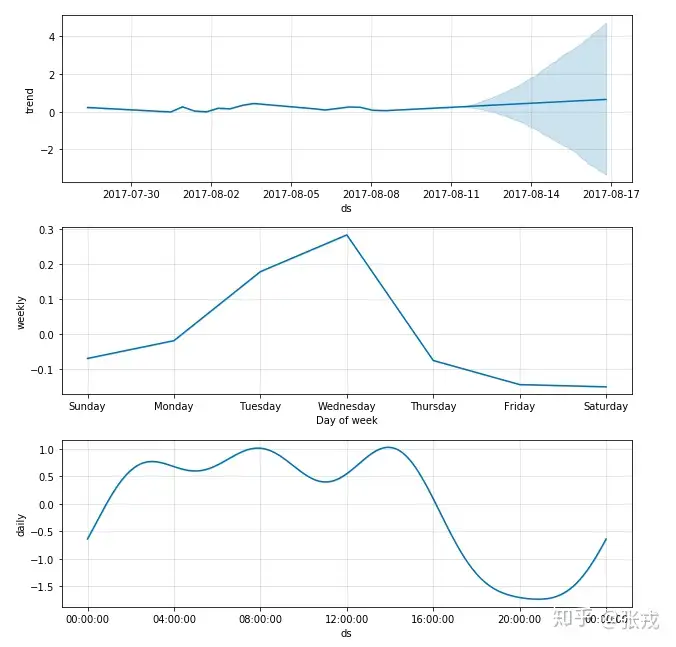
节假日的设置
有的时候,由于双十一或者一些特殊节假日,我们可以设置某些天数是节假日,并且设置它的前后影响范围,也就是 lower_window 和 upper_window。
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
'holiday': 'playoff',
'ds': pd.to_datetime(['2008-01-13', '2009-01-03', '2010-01-16',
'2010-01-24', '2010-02-07', '2011-01-08',
'2013-01-12', '2014-01-12', '2014-01-19',
'2014-02-02', '2015-01-11', '2016-01-17',
'2016-01-24', '2016-02-07']),
'lower_window': 0,
'upper_window': 1,
})
superbowls = pd.DataFrame({
'holiday': 'superbowl',
'ds': pd.to_datetime(['2010-02-07', '2014-02-02', '2016-02-07']),
'lower_window': 0,
'upper_window': 1,
})
holidays = pd.concat((playoffs, superbowls))
m = Prophet(holidays=holidays, holidays_prior_scale=10.0)
参考:https://zhuanlan.zhihu.com/p/52330017
