Hadoop概述
Hadoop体系也是一个计算框架,在这个框架下,可以使用一种简单的编程模式,通过多台计算机构成的集群,分布式处理大数据集。Hadoop是可扩展的,它可以方便地从单一服务器扩展到数千台服务器,每台服务器进行本地计算和存储。除了依赖于硬件交付的高可用性,软件库本身也提供数据保护,并可以在应用层做失败处理,从而在计算机集群的顶层提供高可用服务。Hadoop核心生态圈组件如图1所示。
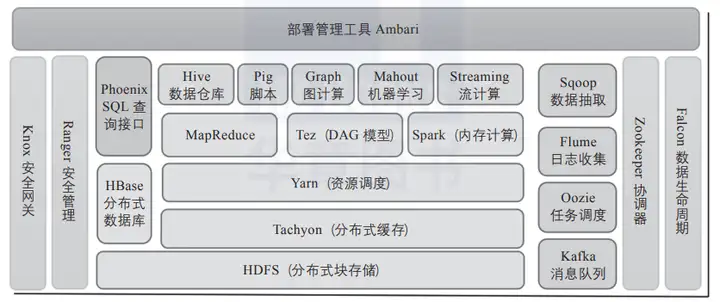
图1 Haddoop开源生态
02
Hadoop生态圈
Hadoop包括以下4个基本模块。
1)Hadoop基础功能库:支持其他Hadoop模块的通用程序包。
2)HDFS:一个分布式文件系统,能够以高吞吐量访问应用中的数据。
3)YARN:一个作业调度和资源管理框架。
4)MapReduce:一个基于YARN的大数据并行处理程序。
除了基本模块,Hadoop还包括以下项目。
1)Ambari:基于Web,用于配置、管理和监控Hadoop集群。支持HDFS、MapReduce、Hive、HCatalog、HBase、ZooKeeper、Oozie、Pig和Sqoop。Ambari还提供显示集群健康状况的仪表盘,如热点图等。Ambari以图形化的方式查看MapReduce、Pig和Hive应用程序的运行情况,因此可以通过对用户友好的方式诊断应用的性能问题。
2)Avro:数据序列化系统。
3)Cassandra:可扩展的、无单点故障的NoSQL多主数据库。
4)Chukwa:用于大型分布式系统的数据采集系统。
5)HBase:可扩展的分布式数据库,支持大表的结构化数据存储。
6)Hive:数据仓库基础架构,提供数据汇总和命令行即席查询功能。
7)Mahout:可扩展的机器学习和数据挖掘库。
8)Pig:用于并行计算的高级数据流语言和执行框架。
9)Spark:可高速处理Hadoop数据的通用计算引擎。Spark提供了一种简单而富有表达能力的编程模式,支持ETL、机器学习、数据流处理、图像计算等多种应用。
10)Tez:完整的数据流编程框架,基于YARN建立,提供强大而灵活的引擎,可执行任意有向无环图(DAG)数据处理任务,既支持批处理又支持交互式的用户场景。Tez已经被Hive、Pig等Hadoop生态圈的组件所采用,用来替代 MapReduce作为底层执行引擎。
11)ZooKeeper:用于分布式应用的高性能协调服务。
除了以上这些官方认可的Hadoop生态圈组件之外,还有很多十分优秀的组件这里没有介绍,这些组件的应用也非常广泛,例如基于Hive查询优化的Presto、Impala、Kylin等。
此外,在Hadoop生态圈的周边,还聚集了一群“伙伴”,它们虽然未曾深入融合Hadoop生态圈,但是和Hadoop有着千丝万缕的联系,并且在各自擅长的领域起到了不可替代的作用。图2是阿里云E-MapReduce平台整合的Hadoop生态体系中的组件,比Apache提供的组合更为强大。
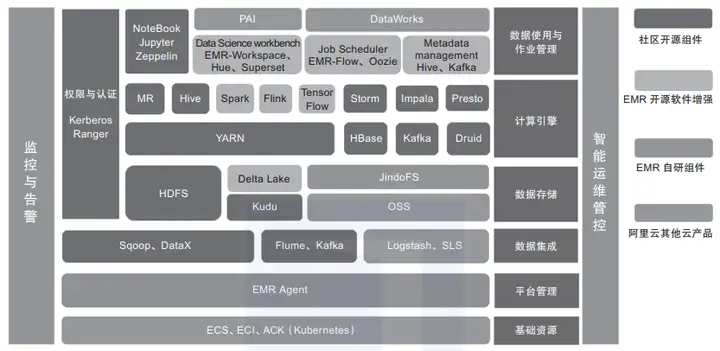
图2 阿里云E-MapReduce的产品架构
下面简单介绍其中比较重要的成员。
1)Presto:开源分布式SQL查询引擎,适用于交互式分析查询,数据量支持GB到PB级。Presto可以处理多数据源,是一款基于内存计算的MPP架构查询引擎。
2)Kudu:与HBase类似的列存储分布式数据库,能够提供快速更新和删除数据的功能,是一款既支持随机读写,又支持OLAP分析的大数据存储引擎。
3)Impala:高效的基于MPP架构的快速查询引擎,基于Hive并使用内存进行计算,兼顾ETL功能,具有实时、批处理、多并发等优点。
4)Kylin:开源分布式分析型数据仓库,提供Hadoop/Spark之上的SQL查询接口及多维分析(OLAP)能力,支持超大规模数据的压秒级查询。
5)Flink:一款高吞吐量、低延迟的针对流数据和批数据的分布式实时处理引擎,是实时处理领域的新星。
6)Hudi:Uber开发并开源的数据湖解决方案,Hudi(Hadoop updates and incrementals)支持HDFS数据的修改和增量更新操作。
03
Hadoop的优缺点
如今,Hadoop已经演化成了一个生态系统,系统内的组件千差万别,有的还是孵化阶段,有的风华正茂,有的垂垂老矣。其中,最经久不衰的当属HDFS和Hive两大组件,昙花一现的包括HBase、MapReduce、Presto等,风华正茂的当属Spark和Flink。
古语有云,“成也萧何,败也萧何”。大数据成功最核心的原因是开源,但它存在的最大的问题也是开源。很多组件虽然依靠开源可以快速成熟,但是一旦成熟,就会出现生态紊乱和版本割裂的情况,其中最典型的就是Hive。
Hive 1.x之前的版本功能不完善,1.x版和2.x版算是逐步优化到基本可用了,到了3.x版又出现了各种问题,并且大部分云平台Hive版本都停留在2.x版,新版本推广乏力。另外,Hive的计算引擎也是饱受争议的,Hive支持的计算引擎主要有MapReduce、Tez、Spark、Presto。十多年来MapReduce的计算速度并没有提升;Tez虽然计算速度快,但是安装需要定制化编译和部署;Spark的计算速度最快,但是对JDBC支持不友好;Presto计算速度快并且支持JDBC,但是语法又和Hive不一致。申明一下,这里说的快只是相对MapReduce引擎而言的,跟传统数据库的速度相比仍然相差1到2个数量级。
总的来说,基于Hadoop开发出来的大数据平台,通常具有以下特点。
1)扩容能力:能够可靠地存储和处理PB级的数据。Hadoop生态基本采用HDFS作为存储组件,吞吐量高、稳定可靠。
2)成本低:可以利用廉价、通用的机器组成的服务器群分发、处理数据。这些服务器群总计可达数千个节点。
3)高效率:通过分发数据,Hadoop可以在数据所在节点上并行处理,处理速度非常快。
4)可靠性:Hadoop能自动维护数据的多份备份,并且在任务失败后能自动重新部署计算任务。
Hadoop生态同时也存在不少缺点。
1)因为Hadoop采用文件存储系统,所以读写时效性较差,至今没有一款既支持快速更新又支持高效查询的组件。
2)Hadoop生态系统日趋复杂,组件之间的兼容性差,安装和维护比较困难。
3)Hadoop各个组件功能相对单一,优点很明显,缺点也很明显。
4)云生态对Hadoop的冲击十分明显,云厂商定制化组件导致版本分歧进一步扩大,无法形成合力。
5)整体生态基于Java开发,容错性较差,可用性不高,组件容易挂掉。
HDFS 分布式文件存储架构
我们知道,Google 大数据“三驾马车”的第一驾是 GFS(Google 文件系统),而 Hadoop 的第一个产品是 HDFS,可以说分布式文件存储是分布式计算的基础,也可见分布式文件存储的重要性。如果我们将大数据计算比作烹饪,那么数据就是食材,而 Hadoop 分布式文件系统 HDFS 就是烧菜的那口大锅。
厨师来来往往,食材进进出出,各种菜肴层出不穷,而不变的则是那口大锅。大数据也是如此,这些年来,各种计算框架、各种算法、各种应用场景不断推陈出新,让人眼花缭乱,但是大数据存储的王者依然是 HDFS。
为什么 HDFS 的地位如此稳固呢?在整个大数据体系里面,最宝贵、最难以代替的资产就是数据,大数据所有的一切都要围绕数据展开。HDFS 作为最早的大数据存储系统,存储着宝贵的数据资产,各种新的算法、框架要想得到人们的广泛使用,必须支持 HDFS 才能获取已经存储在里面的数据。所以大数据技术越发展,新技术越多,HDFS 得到的支持越多,我们越离不开 HDFS。HDFS 也许不是最好的大数据存储技术,但依然最重要的大数据存储技术。
之前在 前方高能 | HDFS 的架构,你吃透了吗?这篇文章中,我们就已经谈到了 HDFS 的架构 ,如下图所示:
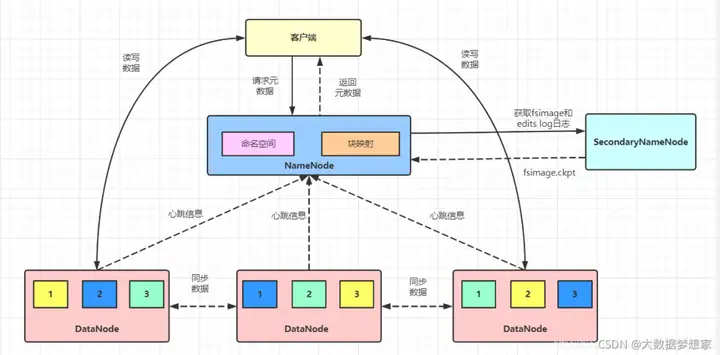
HDFS 可以将数千台服务器组成一个统一的文件存储系统,其中 NameNode 服务器充当文件控制块的角色,进行文件元数据管理,即记录文件名、访问权限、数据存储地址等信息,而真正的文件数据则存储在 DataNode 服务器上。
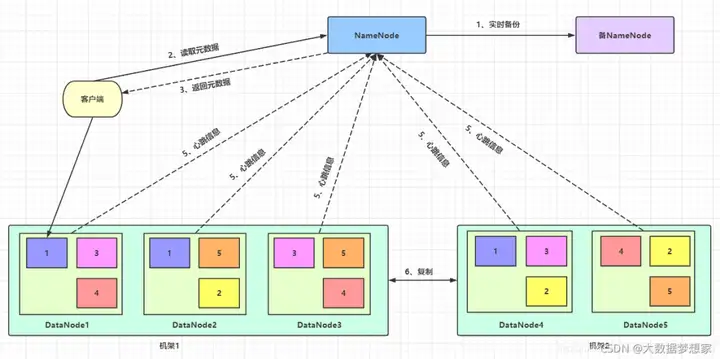
DataNode 以块为单位存储数据,所有的块信息,比如 块 ID、块所在的服务器 IP 地址等,都记录在 NameNode 服务器上,而具体的块数据存储在 DataNode 服务器上。理论上,NameNode 可以将所有 DataNode 服务器上的所有数据块都分配给一个文件,也就是说,一个文件可以使用所有服务器的硬盘存储空间 。
此外,HDFS 为了保证不会因为磁盘或者服务器损坏而导致文件损坏,还会对数据块进行复制,每个数据块都会存储在多台服务器上,甚至多个机架上。
MapReduce 大数据计算架构
大数据计算的核心思路是 移动计算比移动数据更划算。既然计算方法跟传统计算方法不一样,移动计算而不是移动数据,那么用传统的编程模型进行大数据计算就会遇到很多困难,因此 Hadoop 大数据计算使用了一种叫作 MapReduce 的编程模型。
其实 MapReduce 编程模型并不是 Hadoop 原创,甚至也不是 Google 原创,但是 Google 和 Hadoop 创造性地将 MapReduce 编程模型用到大数据计算上,立刻产生了神奇的效果,看似复杂的各种各样的机器学习、数据挖掘、SQL 处理等大数据计算变得简单清晰起来。
就好比数据存储在 HDFS 上的最终目的还是为了计算,通过数据分析或者机器学习获得有益的结果。但是如果像传统的应用程序那样,把 HDFS 当做普通文件,从文件中读取数据后进行计算,那么对于需要一次计算数百 TB 数据的大数据计算场景,就不知道要算到什么时候了。
大数据处理的经典计算框架是 MapReduce 。MapReduce 的核心思想是对数据进行分片计算。既然数据是以块为单位分布存储在很多服务器组成的集群上,那么能不能就在这些服务器上针对每个数据块进行分布式计算呢 ?
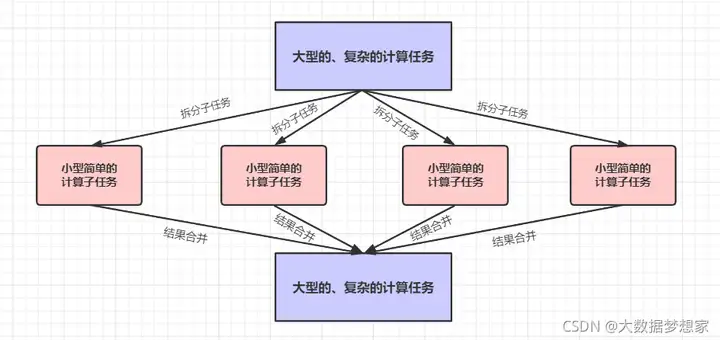
事实上,MapReduce 可以在分布式集群的多台服务器上启动同一个计算程序,每个服务器上的程序进程都可以读取本服务器上要处理的数据块进行计算,因此,大量的数据就可以同时进行计算了。但是这样一来,每个数据块的数据都是独立的,如果这些数据块需要进行关联计算怎么办?
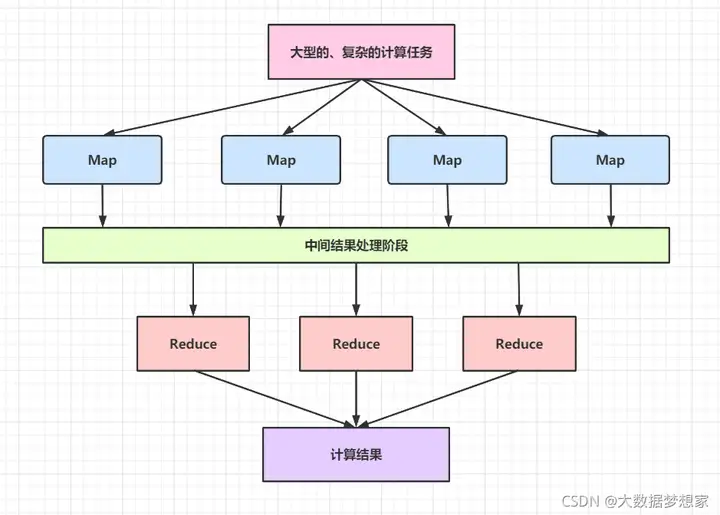
MapReduce 将计算过程分成了两个部分:一部分是 map 过程,每个服务器上会启动多个 map 进程,map 优先读取本地数据进行计算,计算后输出一个 <key,value> 集合;另一部分是 reduce 部分,MapReduce 在每个服务器上都会启动多个 reduce 进程,然后对所有 map 输出的 <key,value> 集合进行 shuffle 操作。所谓的 shuffle 就是将相同的 key 发送到同一个 reduce 进程中,在 reduce 中完成数据关联计算 。
为了更直观的展示这个过程,下面以经典的 WordCount ,即统计所有数据中相同单词的词频数据为例,来认识 map 和 reduce 的处理过程 。
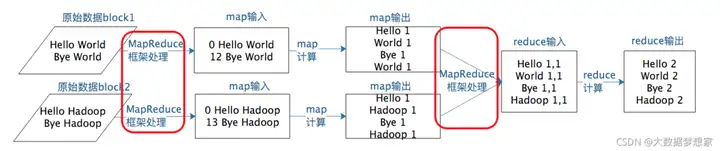
图片来源:极客时间
假设原始数据有两个数据块,MapReduce 框架启动了两个 map 进程进行处理,它们分别读入数据 。map 函数会对输入数据进行分词处理,然后针对每个单词输出 < 单词,1 > 这样的 < key,value > 结果 。然后 MapReduce 框架进行 shuffle 操作,相同的 key 发送给同一个 reduce 进程,reduce 的输入就是 < key ,value 的列表>这样的结构,即相同 key 的 value 合并成了一个列表。
在这个示例中,这个 value 列表就是由很多个 1 组成的列表。reduce 对这些 1 进行求和操作,就得到了每个单词的词频结果了。
示例代码如下:
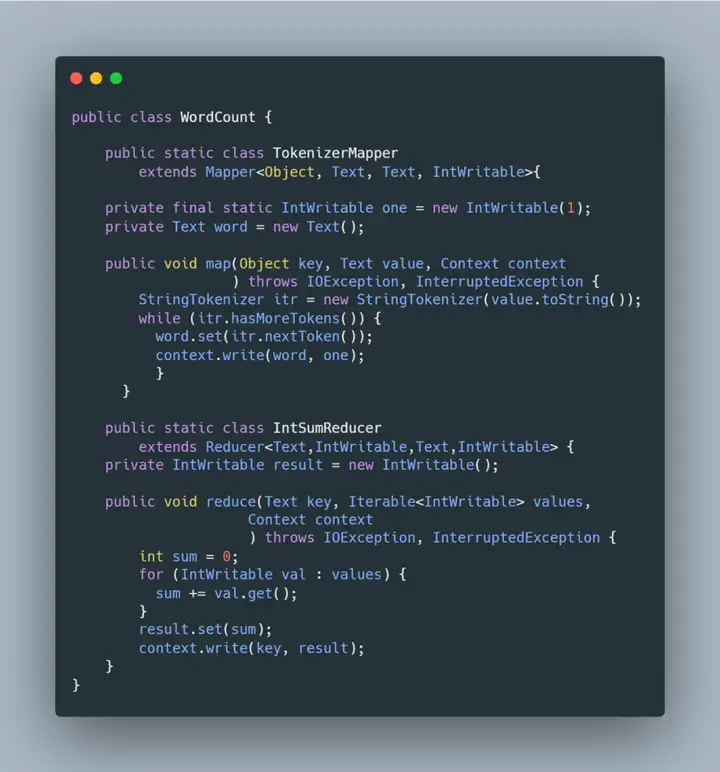
上面的源代码描述的是 map 和 reduce 进程合作完成数据处理的过程,那么这些进程是如何在分布式的服务器集群上启动的呢?数据是如何流动并最终完成计算的呢?
我们以 Hadoop 1 为例,带领大家一起看下这个过程。
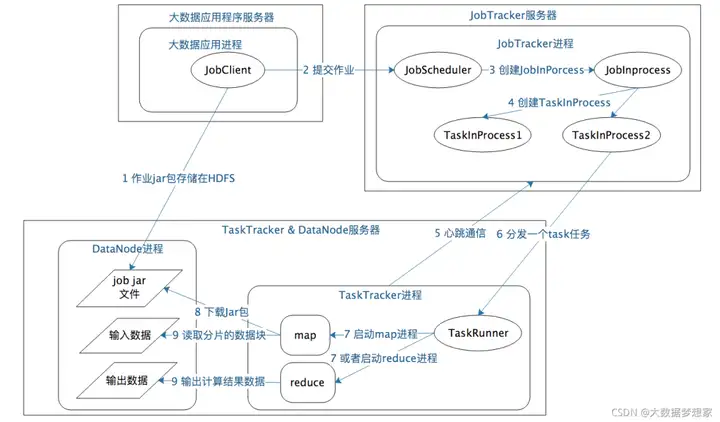
MapReduce1 主要有 JobTracker 和 TaskTracker 这两种角色,JobTracker 在 MapReduce 的集群只有一个,而 TaskTracker 则和 DataNode 一起启动在集群的所有服务器上。
MapReduce 应用程序 JobClient 启动后,会向 JobTracker 提交作业,JobTracker 根据作业中输入的文件路径分析需要在哪些服务器上启动 map 进程,然后就在这些服务器上的 TaskTracker 发送任务命令。
图片来源:极客时间
TaskTracker 收到任务后,启动一个TaskRunner 进程下载任务对应的程序,然后反射加载程序中的 map 函数,读取任务中分配的数据块,并进行map计算。map计算结束后,TaskTracker会对 map 输出进行shuffle 操作,然后 TaskRunner 加载 reduce 函数进行后续计算 。
Yarn 资源调度框架
在 MapReduce 应用程序的启动过程中,最重要的就是要把 MapReduce 程序分发到大数据集群的服务器上,在上文介绍的 Hadoop 1 中,这个过程主要是通过 TaskTracker 和 JobTracker 通信来完成。
但是这种架构方案有什么缺点呢?
服务器集群资源调度管理和 MapReduce 执行过程耦合在一起,如果想在当前集群中运行其他计算任务,比如 Spark 或者 Storm,就无法统一使用集群中的资源了。
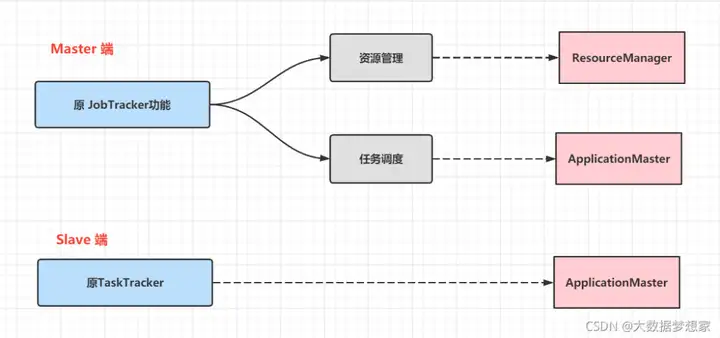
在 Hadoop 早期的时候,大数据技术就只有 Hadoop 一家,这个缺点并不明显。但随着大数据技术的发展,各种新的计算框架不断出现,我们不可能为每一种计算框架部署一个服务器集群,而且就算能部署新集群,数据还是在原来集群的 HDFS 上。所以我们需要把 MapReduce 的资源管理和计算框架分开,这也是 Hadoop 2 最主要的变化,就是将 Yarn 从 MapReduce 中分离出来,成为一个独立的资源调度框架。
Yarn 的设计思路也非常有趣。
首先,为了避免功能的高度耦合,你得将原 JobTracker 的功能进行拆分
其次,一个集群多个框架,即在一个集群上部署一个统一的资源调度框架YARN,在YARN之上可以部署各种计算框架。
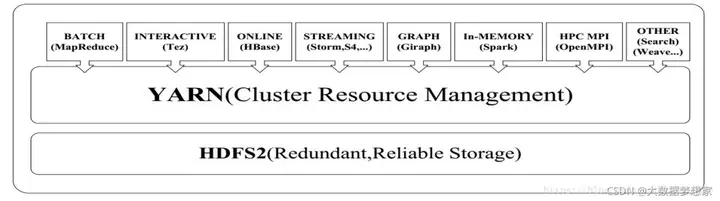
最终形成 Yarn 的整体架构如下所示:
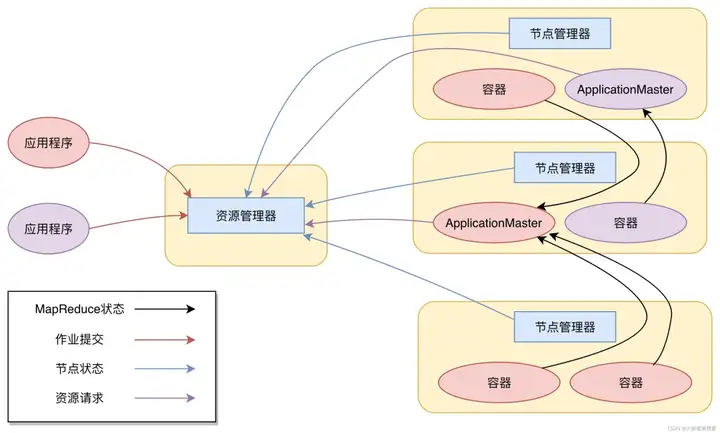
图片来源:极客时间
从图上看,Yarn 包括两个部分:一个是资源管理器(Resource Manager),一个是节点管理器(Node Manager)。这也是 Yarn 的两种主要进程:ResourceManager 进程负责整个集群的资源调度管理,通常部署在独立的服务器上;NodeManager 进程负责具体服务器上的资源和任务管理,在集群的每一台计算服务器上都会启动,基本上跟 HDFS 的 DataNode 进程一起出现。
具体说来,资源管理器又包括两个主要组件:调度器和应用程序管理器。调度器其实就是一个资源分配算法,根据应用程序(Client)提交的资源申请和当前服务器集群的资源状况进行资源分配。
Yarn 内置了几种资源调度算法,包括 Fair Scheduler、Capacity Scheduler 等,你也可以开发自己的资源调度算法供 Yarn 调用。Yarn 进行资源分配的单位是容器(Container),每个容器包含了一定量的内存、CPU 等计算资源,默认配置下,每个容器包含一个 CPU 核心。容器由 NodeManager 进程启动和管理,NodeManger 进程会监控本节点上容器的运行状况并向 ResourceManger 进程汇报。
应用程序管理器负责应用程序的提交、监控应用程序运行状态等。应用程序启动后需要在集群中运行一个 ApplicationMaster,ApplicationMaster 也需要运行在容器里面。每个应用程序启动后都会先启动自己的 ApplicationMaster,由 ApplicationMaster 根据应用程序的资源需求进一步向 ResourceManager 进程申请容器资源,得到容器以后就会分发自己的应用程序代码到容器上启动,进而开始分布式计算。
巨人的肩膀
1、《从零开始学大数据》
2、《架构师的自我修炼》
3、 https://www.cnblogs.com/yszd/p/10885222.htm
4、 http://hadoop.apache.org/
