很久没有写博客了,不是因为最近学习松懈,而是因为发现自己以前写的博客大多都比较水,真正有意义、有价值的文章需要大量的学习与时间去积淀。以后尽量提高自己博客的质量,走的再远,工作再忙,也要坚持看书,坚持学习,成长的道路有多长?我想大概是一生。这篇文章算是我这段时间对微服务学习的一个小小成果吧!
微服务是什么?
我第一次接触到这个词汇,以为是一个基于微信的服务,听起来感觉有些low。其实不然。微服务是一种架构模式,一种分布式的架构风格。顾名思义,micro service,将一个庞大的单体应用拆分成若干个“微小”的服务,服务间通过进程通讯完成原本在单体应用中的调用。其中必要的六个基本技术为:1、服务注册与发现;2、进程间通信;3、负载均衡;4、分布式配置中心;5、熔断器;6、网关路由。根据以上六点,以及现有的优秀开源技术,在技术选型上,稍微做下排列组合,你可能好几个月都试不完。之前没有了解的朋友可以阅读一下Chris Richardson 大师的微服务系列文集,对微服务会有一个初步的认识。也欢迎你与我,一同探讨微服务的技术选型,以及高可用方案。
初次尝试——遇见Spring Cloud
国内已经有一些公司使用springcloud实现微服务。我开始调研的时候,也在SpringCloud的体系里花了一些时间,拿出了一套基于SpringCloud+Docker的方案。SpringCloud整合了Netflix公司的一套组件。国外Netflix公司也算是比较早实践微服务的公司了,Netflix的一套开源项目,为微服务提供了比较完善的方案。我之前拿出的SpringCloud微服务实现方案,大部分的技术都是来源于Netflix
- 注册中心——Eureka
之前我是选用Netflix公司提供的eureka作为注册中心。在以前,我接触的分布式体系大多数是一个zookeeper+dubbo的组合。目前国内短期内还是dubbo的天下。zookeeper也常常被用作注册中心,在国内的使用率非常高。注册中心可以说的上是一个微服务体系的核心,它承载了很多的调度与负载。在分布式领域有个著名的CAP定理(C:数据一致性;A:服务可用性;P:服务队网络分区故障的容错性,这三点一般不能同时满足,最多同时满足两个)。为什么不使用zookeeper而使用eureka呢?答案就从CAP定理中去寻找,显然zk是一个CP,为了保证数据的一致性,zk有一个选举leader节点的过程,了解zk的朋友一定知道,zk对于leader的选举,有一个“法定人数”:n+1,如果达不到这个“法定人数”,这个网络分区就会从zk中断开,也就不能提供相应的service发现服务了。显然,这不是我们想要看到的结果。
再来看看Eureka,它是一个典型的客户端发现模式,且是自注册的。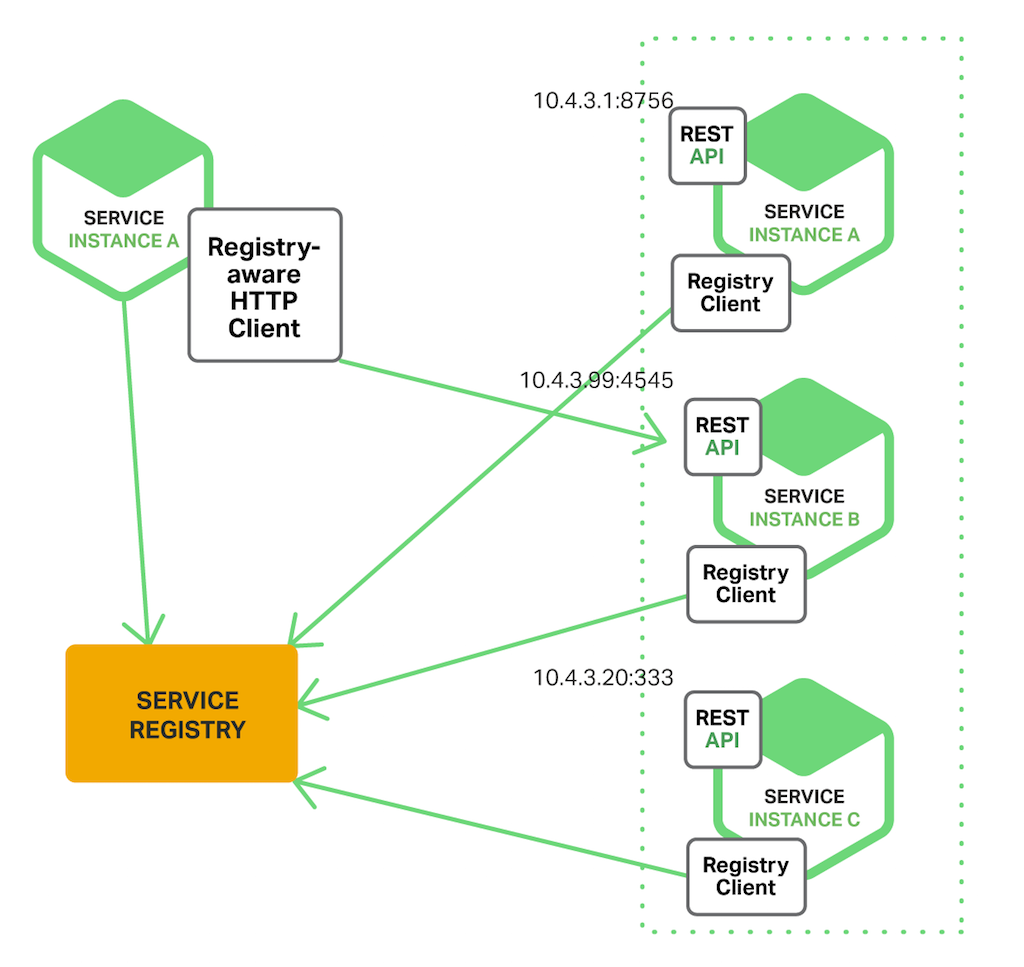
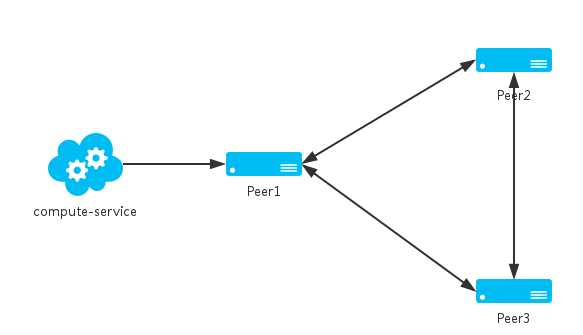
再者,它是一个AP,可以更好的保证系统的可用性。正常配置下,Eureka内置了心跳服务,用于淘汰一些“濒死”的服务,如果再eureka中注册的服务,它的“心跳”变得迟缓,Eureka会将其剔除管理范围。有的朋友可能就会问,那如果也是因为网络问题,eureka服务器失去了客户端大量的心跳,可怎么办?Netflix充分考虑到了这个问题,Eureka存在自我保护机制,当一段时间内,客户端提供的心跳低于80,将会自动进入自我保护模式,将该分片保护起来。Eureka Server除了单点运行之外,还可以通过运行多个实例,并进行互相注册的方式来实现高可用的部署:
Eureka server1
2
3
4
2eureka.instance.hostname=peer1
3eureka.client.serviceUrl.defaultZone=http://peer2:1112/eureka/
4
Eureka server2
2
3
4
2eureka.instance.hostname=peer2
3eureka.client.serviceUrl.defaultZone=http://peer1:1111/eureka/
4
Client comput-service
2
3
2eureka.client.serviceUrl.defaultZone=http://peer1:1111/eureka/,http://peer2:1112/eureka/
3
- 负载均衡——Ribbon
负载均衡,一个多么耳熟又常见词汇~在我看来,不论是客户端实现还是服务器端的实现,都逃不开那些个负载均衡的常见算法。常见的服务端实现有:Ngnix、HA Proxy等。这里我们主要还是探讨一下客户端等实现,Netflix Ribbon。它的负载均衡策略也很常见:
1.随机选择(RandomRule)
2.线性轮询(RoundRobinRule)
3.重试机制(RetryRule)
4.加权响应(WeightedResponseTimeRule)
5.最小并发数(BestAvailableRule)
- 进程间通信——Restful
终于谈到进程间通信。在分布式体系之中,进程通信的重要程度可以说的上是最基本、最重要的。它承载了进程间的数据交互。在SpringCloud的坑中,多半会使用Restful作为进程通信的方式。基于Http协议,效率你也是可想而知。我们退一步说,当你的服务拆分粒度越来越细,服务间或可能存在链式的调用,效率就成了至关重要的一个问题,所以在我看来,能使用RPC尽量使用RPC,dubbo、thrift、grpc都是非常优秀的rpc技术。
- 分布式配置中心——SpringCloud
既然已经走进了SpringCloud的体系,配置中心自然可以选择一套的,SpringCloud Config,实现配置文件的集中配置化管理。同样,国内也有比较优秀的开源分布式配置管理中心。如:阿里diamond,百度disconf等
- 熔断器——Hystrix
熔断器,顾名思义,作用和物理上的保险丝差不多,线路一旦过载,就断开。
在分布式架构中,当某个服务单元发生故障(类似用电器发生短路)之后,通过断路器的故障监控(类似熔断保险丝),向调用方返回一个错误响应,而不是长时间的等待。这样就不会使得线程因调用故障服务被长时间占用不释放,避免了故障在分布式系统中的蔓延。
从图中不难看出其工作流程:
1.检查缓存
2.检查circuit breaker状态
3.执行相应指令
4.记录数据,计算失败比率
- 网关路由 ——Zuul
Zuul是Netflix出品的一个基于JVM路由和服务端的负载均衡器。Zuul使用Ribbon定位服务注册中的实例,
并且所有的请求都在hystrix的command中执行, 所以失败信息将会展现在Hystrix metrics中, 并且一旦断路器打开,代理请求将不会尝试去链接服务。
浅尝辄止——For A Better Idea
在我整理了整套的SpringCloud实现微服务的方案以后,发现了以下的一些问题。
- 非JVM应用的处理
受Netflix Prana的启示,为了更好的兼容一些非JVM应用,SpringCloud提供了一个叫做sidecar的东西。不论是受Prana还是sidecar,其思想都是,都是设计一个JVM程序,和我们非JVM应用跑在同一个容器(主机)里,监测其心跳、健康状态反馈给注册中心。这种思路的出发点很好,但是并没有从根本上解决问题。比如,我要部署一个mycat的服务,我根本没办法为sidecar提供一个健康心跳检测的接口。
- 基于SpringBoot的改造
假设一个乐观的情况,现有的大部分项目都是原生spring,然而总所周知,SpringCloud是基于SpringBoot而来,要使用cloud,必然要进行改造,虽然难度不大,但是这样对程序入侵,真的有必要吗?真的符合我软件开发的原则吗?这还是一个乐观的情况,大部分都还是JVM应用,那如果全是python、php呢?这该如何是好?所以,我开始了新方案的寻找。
- A Better Idea
不能入侵程序,又要达到以上的六个基本要求,这该如何是好?Kubernetes及时闯入了我的视野。
偶然尝试——Kubernetes
Kubernetes(以下简称K8s)不同于SpringCloud,它没有明确的什么客户端服务器的概念,在它的设计理念里:一切皆容器。
Action in Kubernetes
2018.8.16更新
emmm主要是很久不用csdn了,一直在用自己另外搭的博客,没想到这篇我实习期间写的博客访问量还蛮多的…..然后看到评论也有不少噪音,说什么标题党之类的。
好吧….没有完整的写完,确实不应该,可能真的就误人子弟了。
所以无论如何,先把这篇博客完善掉吧,之前k8s我没有贴出来,是觉得网上的资料实在是太多了,关于K8s的微服务落地方案也确实不少,毕竟写这篇博客的初衷只是对自己学习的一个小结,主要是记录从试着使用springCloud到最后切到k8s的一个过程。
现在使用K8s实践微服务一年,效果挺不错的,支撑了非常庞大的微服务体系。很多非JVM的应用,也可以很好的融合到体系之中。同时基于k8s集群,搭建了一键部署平台,就连UED不用学习任何相关专业知识,都能快速部署应用。
所以这一次的完善,我不会去从微服务的六个理念去探讨具体在k8s里面怎么落地,毕竟网上这样的资料一Google要多少有多少。
主要是分享一下实践过程中的一些心得。实践过程中,发现理论确实是理论,还是要结合自身的很多情况去落地方案。
写在前面
关于k8s的集群搭建,在很早以前1.5的时候我写过一版,k8s的迭代更新很快,现在的搭建会有些许不同。但是最重要的是,官方发布了minikube,支持本地实验,对于初学者来说更加友好了。而且环境搭建什么的,也更简单了。
PS:minikube毕竟是mini版,玩玩指令还行,有条件的还是凑两三台机器自己搭一个吧,也不费劲。我就在vultr上用自己搭vpn的机器搭了个,vultr挺便宜的,而且是按分钟收费,玩完再把多余的机器删掉也不亏。
## 微服务与K8s
谈到微服务有六个理念还是要提及的。也正如上文所提到的,1、服务注册与发现;2、进程间通信;3、负载均衡;4、分布式配置中心;5、熔断器;6、网关路由。
关于这六个要点在SpringCloud都有很好的体现。在K8s里面也是一样。接下来,就谈谈实践于k8s中的一些心得。
注册与发现
任何的微服务体系,注册中心都是至关重要的。在实践过程中,我们并没有引入新的注册中心。使用的就是k8s的kube-dns。k8s将Service的名称当做域名注册到kube-dns中,通过Service的名称就可以访问其提供的服务。
2
3
4
2spring.redis.port=6379
3spring.redis.password=thisispwd
4
进程间通信
关于进程间通信,如果说注册与发现是最重要的,那么在我看来,第二重要的就是进程间通信。注册与发现保证了服务间便捷的调用,那么进程间通信则保证了服务间的调用能走通,且调用是稳定高效的。
显然,在这个问题的选择上RPC的优于HTTP的。尤其是在内部链路复杂的情况下,RPC的性能会有明显的优势。
再看看RPC的选择上。曾经在Thrift和GRPC上犹豫不决。
经过调研与实践,落地是Thrift。实践一年,稳定、高效,而且已然沉淀出了成熟的调用组件(有机会开源到GitHub和大家分享一下)。性能优于GRPC。唯一的缺点,就是对于初学者而言文档并不是那么的丰富、友好。反观GRPC就友好的多。如果实在不喜欢thrift的朋友,也可以选择GRPC。
负载均衡
再谈谈负载均衡。
负载均衡其实有非常多的手段能够实现。从不同的维度、角度都可以去做负载均衡。这里主要谈谈k8s里面service到pod调度这一层的负载均衡吧!
service和pod可以说是k8s又基础又关键的两个概念。
pod是k8s中最小的部署单元,方便理解的话,你可以以容器的概念去理解pod(实际上pod是大于容器的,pod包含容器、存储、网络等其相关资源)。可以理解为你的应用跑在一个又一个的容器里,容器被k8s包装成了一个叫做pod的东西。pod是临时性的,用完即丢弃的,当pod中的进程结束、node故障,或者资源短缺时,
service顾名思义,就是服务。或者粗略的说,一群应用副本(pod)聚在一起,称之为service。
在我看来,要真正理解service和pod,理解k8s关乎微服务的理念。必然要弄清楚一点——K8s的网络模型。这一点在《Kubernetes权威指南》里,用了三两句话就解释清楚了。为了更好的描述,以下关于K8s网络模型的介绍是参考网上的一篇文章,Kubernetes的网络模型。
- Pod内部容器所在的网络
- Pod所在的网络
- Pod和Service之间通信的网络
外界与Service之间通信的网络
Kubernetes里的Pod不是一个“长生”的家伙,它会由于各种原因被销毁和创造。比如在垂直扩容和滚动更新过程中,旧的Pod会被销毁,被新的Pod代替。这期间,Pod的IP地址甚至会发生变化。所以Kubernetes引进了Service。Service是一个抽象的实体,Kubernetes在创建Service实体时,为其分配了一个虚拟的IP,当我们需要访问Pod里的容器提供的功能时,我们不直接使用Pod的IP地址和端口,而是访问Service的这个虚拟IP和端口,由Service把请求转发给它背后的Pod。
简而言之,一群应用(pod)凑在一起提供出了一个服务(service)。外界是无法直接访问到你的应用的(pod),只能通过service去访问。
所以service就像一个调度员,每当收到请求,service会分配一个pod来处理请求。这个”调度“正是负载均衡。
Kubernetes中最基本的负载均衡类型实际上是负载分配(load distribution),这在调度层面是容易实现的。Kubernetes使用了两种负载分配的方法,都通过kube-proxy这一功能执行,该功能负责管理服务所使用的虚拟IPs。
Kube-proxy的默认模式是iptables,它支持相当复杂的基于规则的IP管理。iptables模式下,负载分配的本地方法是随机选择——由一个传入的请求去随机选择一个服务中的pod。早先版本(以及原来的默认模式)的kube-proxy模式是userspace,它使用循环的负载分配,在IP列表上来分配下一个可以使用的pod,然后更换(或置换)该列表。
然而,这些并不是真正的负载均衡。为了实现真正的负载均衡,当前最流行、最灵活、应用于很多领域的方法是Ingress,它通过在专门的Kubernetes pod中的控制器进行操作。控制器包括一个Ingress资源——一组管理流量的规则和一个应用这些规则的守护进程。
控制器有自己内置的负载均衡特性,具备一些相当复杂的功能。你还可以让Ingress资源包含更复杂的负载均衡规则,来满足对具体系统或供应商的负载均衡功能和需求。
当前Ingress是首选的负载均衡方法。因为它是作为一个基于pod的控制器在Kubernetes内部执行,因此对Kubernetes功能的访问相对不受限制(不同于外部负载均衡器,它们中的一些可能无法在pod层面访问)。Ingress资源中包含的可配置规则支持非常详细和高度细化的负载均衡,可以根据应用程序的功能要求极其运行条件进行定制。
分布式配置中心
关于分布式配置中心,在任何应用中都是需要的。一些敏感信息,配置在代码的配置文件中显然是不合适的。应当加密后存储在配置中心。
当时关于Kubernetes配置中心的调研并没有投入太多。调研时候有看到一些方案说通过ConfigMap去做…..然而,我觉得真的不合适。
实践过程中,我们直接基于zk开发了一款配置中心,适用于我们的实际情况。如果有更好的公有方案,欢迎大家留言分享。
熔断器
熔断器的话并没有找到一个非常完美的手段去解决,只是用了替代方案勉强达到了应有的效果,如:从应用层解决熔断问题,增加集群监控等。
实际上,从应用层去解决这个问题也不麻烦,而且灵活度也更高。毕竟要结合自身的业务场景。
当然,如果有更好的公有方案,欢迎大家留言分享。
网关路由
在实践过程中,也调研过不少网关路由。后来结合自身的业务需求,用Go开发了一款网关。
最近有准备把Kong落地的想法,初步调研已经开始了,但是还没有真正投入到生产环境。所以也无法给出评价。
小结
综上,大家应该可以看出,关于微服务的六个要点,真正说依赖k8s的只有注册发现与少部分的负载均衡。当然,k8s远不仅于此,本身还是有着很多出色的特性,同时坑也确实不少。
其他的点,我们或多或少都从选择别的开源技术、自己开发等手段解决了。虽然因此带来了一定的工作量,但是也更加切合实际上的一些场景。
当然,还是那句话。如果有更好的公有方案,欢迎大家留言分享。
