## 前言
本系列文章计划分三个章节进行讲述,分别是理论篇、基础篇和实战篇。理论篇主要为构建分布式爬虫而储备的理论知识,基础篇会基于理论篇的知识写一个简易的分布式爬虫,实战篇则会以微博为例,教大家做一个比较完整且足够健壮的分布式微博爬虫。通过这三篇文章,希望大家**能掌握如何构建一个分布式爬虫的方法**;能举一反三,将
1 | 1` |
celery
1 | 1` |
用于除爬虫外的其它场景。目前基本上的博客都是教大家使用scrapyd(scrapy/scrapyd)或者scrapy-redis(rolando/scrapy-redis)构建分布式爬虫,本系列文章会从另外一个角度讲述如何用
requests+celery构建一个健壮的、可伸缩并且可扩展的分布式爬虫。
本系列文章属于爬虫进阶文章,期望受众是具有一定Python基础知识和编程能力、有爬虫经验并且希望提升自己的同学。小白要是感兴趣,也可以看看,看不懂的话,可以等有了一定基础和经验后回过头来再看。
另外一点说明,本系列文章
不是旨在构建一个分布式爬虫框架或者分布式任务调度框架,而是利用现有的分布式任务调度工具来实现分布式爬虫,所以请轻喷。
## 分布式爬虫概览
- 何谓分布式爬虫?
通俗的讲,分布式爬虫就是多台机器多个 spider 对多个 url 的同时处理问题,分布式的方式可以极大提高程序的抓取效率。
- 构建分布式爬虫通畅需要考虑的问题
(1)如何能保证多台机器同时抓取同一个URL?
(2)如果某个节点挂掉,会不会影响其它节点,任务如何继续?
(3)既然是分布式,如何保证架构的可伸缩性和可扩展性?不同优先级的抓取任务如何进行资源分配和调度?
基于上述问题,我选择使用celery(Celery – Distributed Task Queue)作为分布式任务调度工具,是分布式爬虫中任务和资源调度的核心模块。它会把所有任务都通过消息队列发送给各个分布式节点进行执行,所以可以很好的保证url不会被重复抓取;它在检测到worker挂掉的情况下,会尝试向其他的worker重新发送这个任务信息,这样第二个问题也可以得到解决;celery自带任务路由,我们可以根据实际情况在不同的节点上运行不同的抓取任务(在实战篇我会讲到)。本文主要就是带大家了解一下celery的方方面面(有celery相关经验的同学和大牛可以直接跳过了)
Celery知识储备
celery基础讲解
按celery官网的介绍来说
Celery 是一个简单、灵活且可靠的,处理大量消息的分布式系统,并且提供维护这样一个系统的必需工具。它是一个专注于实时处理的任务队列,同时也支持任务调度。
下面几个关于celery的核心知识点
-
broker:翻译过来叫做中间人。它是一个消息传输的中间件,可以理解为一个邮箱。每当应用程序调用celery的异步任务的时候,会向broker传递消息,而后celery的worker将会取到消息,执行相应程序。这其实就是消费者和生产者之间的桥梁。
-
backend: 通常程序发送的消息,发完就完了,可能都不知道对方时候接受了。为此,celery实现了一个backend,用于存储这些消息以及celery执行的一些消息和结果。
-
worker: Celery类的实例,作用就是执行各种任务。注意在celery3.1.25后windows是不支持celery worker的!
-
producer: 发送任务,将其传递给broker
-
beat: celery实现的定时任务。可以将其理解为一个producer,因为它也是通过网络调用定时将任务发送给worker执行。注意在windows上celery是不支持定时任务的!
下面是关于celery的架构示意图,结合上面文字的话应该会更好理解
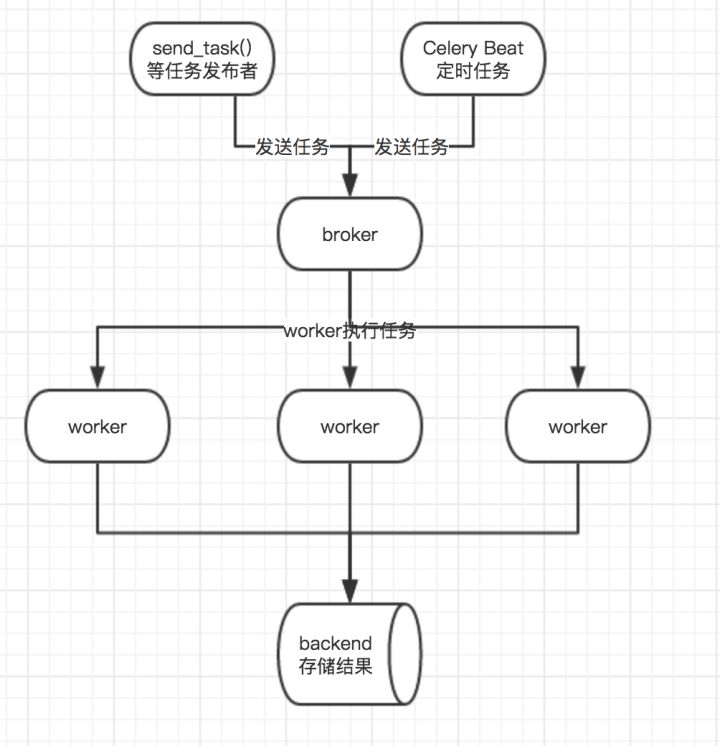
由于celery只是任务队列,而不是真正意义上的消息队列,它自身不具有存储数据的功能,所以broker和backend需要通过第三方工具来存储信息,celery官方推荐的是 RabbitMQ(Messaging that just works)和Redis(Redis),另外mongodb等也可以作为broker或者backend,可能不会很稳定,我们这里选择Redis作为broker兼backend。
关于redis的安装和配置可以查看这里(ResolveWang/WeiboSpider)
实际例子
先安装
celery
pip install celery
我们以官网给出的例子来做说明,并对其进行扩展。首先在项目根目录下,这里我新建一个项目叫做
celerystudy,然后切换到该项目目录下,新建文件
tasks.py,然后在其中输入下面代码
2
3
4
5
6
7
8
9
2
3app = Celery('tasks', broker='redis://:''@223.129.0.190:6379/2', backend='redis://:''@223.129.0.190:6379/3')
4
5@app.task
6def add(x, y):
7 return x + y
8
9
这里我详细讲一下代码:我们先通过
app=Celery()来实例化一个celery对象,在这个过程中,我们指定了它的broker,是redis的db 2,也指定了它的backend,是redis的db3, broker和backend的连接形式大概是这样
redis://:password@hostname:port/db_number
然后定义了一个
add函数,重点是
@app.task,它的作用在我看来就是
将add()
注册为一个类似服务的东西,本来只能通过本地调用的函数被它装饰后,就可以通过网络来调用。这个tasks.py中的app就是一个worker。它可以有很多任务,比如这里的任务函数add。我们再通过
在命令行切换到项目根目录,执行
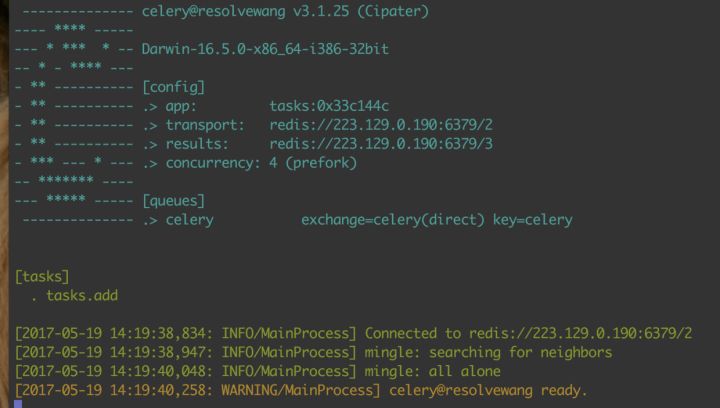
celery -A tasks worker -l info
启动成功后就是下图所示的样子
2
3
2
3
进行查看
将worker启动起来后,我们就可以通过网络来调用
1 | 1` |
add
1 | 1` |
函数了。我们在后面的分布式爬虫构建中也是采用这种方式分发和消费url的。在命令行先切换到项目根目录,然后打开python交互端
from tasks import add
rs = add.delay(2, 2) # 这里的add.delay就是通过网络调用将任务发送给
add
所在的worker执行
这个时候我们可以在worker的界面看到接收的任务和计算的结果。
[2017-05-19 14:22:43,038: INFO/MainProcess] Received task: tasks.add[c0dfcd0b-d05f-4285-b944-0a8aba3e7e61] # worker接收的任务
[2017-05-19 14:22:43,065: INFO/MainProcess] Task tasks.add[c0dfcd0b-d05f-4285-b944-0a8aba3e7e61] succeeded in 0.025274309000451467s: 4 # 执行结果
这里是异步调用,如果我们需要返回的结果,那么要等
1 | 1` |
rs
1 | 1` |
的
1 | 1` |
ready
1 | 1` |
状态
1 | 1` |
true
1 | 1` |
才行。这里
1 | 1` |
add
1 | 1` |
看不出效果,不过试想一下,如果我们是调用的比较占时间的io任务,那么异步任务就比较有价值了
rs # <AsyncResult: c0dfcd0b-d05f-4285-b944-0a8aba3e7e61>
rs.ready() # true 表示已经返回结果了
rs.status # 'SUCCESS' 任务执行状态,失败还是成功
rs.successful() # True 表示执行成功
rs.result # 4 返回的结果
rs.get() # 4 返回的结果
<celery.backends.redis.RedisBackend object at 0x30033ec> #这里我们backend 结果存储在redis里
上面讲的是从Python交互终端中调用
1 | 1` |
add
1 | 1` |
函数,如果我们要从另外一个py文件调用呢?除了通过
1 | 1` ```` ` ```` ` |
import
1 | 1` ```` ` ```` ` |
然后
1 | 1` ```` ` ```` ` |
add.delay()
1 | 1` ```` ` ```` ` |
这种方式,我们还可以通过
1 | 1` ```` ` ```` ` |
send_task()
1 | 1` ```` ` ```` ` |
这种方式,我们在项目根目录另外新建一个py文件叫做
1 | 1` |
excute_tasks.py
1 | 1` |
,在其中写下如下的代码
2
3
4
5
6
2
3if __name__ == '__main__':
4 add.delay(5, 10)
5
6
这时候可以在celery的worker界面看到执行的结果
[2017-05-19 14:25:48,039: INFO/MainProcess] Received task: tasks.add[f5ed0d5e-a337-45a2-a6b3-38a58efd9760]
[2017-05-19 14:25:48,074: INFO/MainProcess] Task tasks.add[f5ed0d5e-a337-45a2-a6b3-38a58efd9760] succeeded in 0.03369094600020617s: 15
此外,我们还可以通过
1 | 1` ```` ` ```` ` |
send_task()
1 | 1` ```` ` ```` ` |
来调用,将
1 | 1` ```` ` ```` ` |
excute_tasks.py
1 | 1` ```` ` ```` ` |
改成这样
2
3
4
5
2if __name__ == '__main__':
3 app.send_task('tasks.add', args=(10, 15),)
4
5
这种方式也是可以的。
1 | 1` |
send_task()
1 | 1` |
还可能接收到为注册(即通过
1 | 1` |
@app.task
1 | 1` |
装饰)的任务,这个时候worker会忽略这个消息
[2017-05-19 14:34:15,352: ERROR/MainProcess] Received unregistered task of type 'tasks.adds'.
The message has been ignored and discarded.
定时任务
上面部分讲了怎么启动worker和调用worker的相关函数,这里再讲一下celery的定时任务。
爬虫由于其特殊性,可能需要定时做增量抓取,也可能需要定时做模拟登陆,以防止cookie过期,而celery恰恰就实现了定时任务的功能。在上述基础上,我们将
1 | 1` |
tasks.py
1 | 1` |
文件改成如下内容
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
2app = Celery('add_tasks', broker='redis:''//223.129.0.190:6379/2', backend='redis:''//223.129.0.190:6379/3')
3app.conf.update(
4 # 配置所在时区
5 CELERY_TIMEZONE='Asia/Shanghai',
6 CELERY_ENABLE_UTC=True,
7 # 官网推荐消息序列化方式为json
8 CELERY_ACCEPT_CONTENT=['json'],
9 CELERY_TASK_SERIALIZER='json',
10 CELERY_RESULT_SERIALIZER='json',
11 # 配置定时任务
12 CELERYBEAT_SCHEDULE={
13 'my_task': {
14 'task': 'tasks.add', # tasks.py模块下的add方法
15 'schedule': 60, # 每隔60运行一次
16 'args': (23, 12),
17 }
18 }
19)
20@app.task
21def add(x, y):
22 return x + y
23
24
然后先通过
1 | 1` |
ctrl+c
1 | 1` |
停掉前一个worker,因为我们代码改了,需要重启worker才会生效。我们再次以
1 | 1` |
celery -A tasks worker -l info
1 | 1` |
这个命令开启worker。
这个时候我们只是开启了worker,如果要让worker执行任务,那么还需要通过beat给它定时发送,我们再开一个命令行,切换到项目根目录,通过
celery beat -A tasks -l info
celery beat v3.1.25 (Cipater) is starting.
__ – … __ – _
Configuration ->
. broker -> redis://223.129.0.190:6379/2
. loader -> celery.loaders.app.AppLoader
. scheduler -> celery.beat.PersistentScheduler
. db -> celerybeat-schedule
. logfile -> [stderr]@%INFO
. maxinterval -> now (0s)
[2017-05-19 15:56:57,125: INFO/MainProcess] beat: Starting…
这样就表示定时任务已经开始运行了。
眼尖的同学可能看到我这里celery的版本是
1 | 1` |
3.1.25
1 | 1` |
,这是因为celery支持的
1 | 1` |
windows
1 | 1` |
最高版本是3.1.25。由于我的分布式微博爬虫的worker也同时部署在了windows上,所以我选择了使用
1 | 1` |
3.1.25
1 | 1` |
。如果全是linux系统,建议使用celery4。
此外,还有一点需要注意,在celery4后,定时任务(通过schedule调度的会这样,通过crontab调度的会马上执行)会在当前时间再过定时间隔执行第一次任务,比如我这里设置的是60秒的间隔,那么第一次执行
1 | 1` |
add
1 | 1` |
会在我们通过
1 | 1` |
celery beat -A tasks -l info
1 | 1` |
启动定时任务后60秒才执行;celery3.1.25则会马上执行该任务。
关于定时任务更详细的请看官方文档celery定时任务(Periodic Tasks – Celery 4.0.2 documentation)
至此,我们把构建一个分布式爬虫的理论知识都讲了一遍,主要就是对于
1 | 1` |
celery
1 | 1` |
的了解和使用,这里并未涉及到celery的一些高级特性,实战篇可能会讲解一些我自己使用的特性。
下一篇我将介绍如何使用celery写一个简单的分布式爬虫,希望大家能有所收获。
此外,打一个广告,我写了一个分布式的微博爬虫(ResolveWang/WeiboSpider),主要就是利用celery做的分布式实战篇我也将会以该项目其中一个模块进行讲解,有兴趣的可以点击看看,也欢迎有需求的朋友试用。
