Node.js
通过对异步IO、异步编程、网络编程的学习,就是在为构建Web打下坚实的基础。接下来就开始深入地学习如何构建Web应用。
一、构建 Web 应用
1. 基础功能
(1)请求方法
在Web应用中除了常见的GET请求,POST请求外还有HEAD、DELETE、PUT、CONNECT等方法。请求方法存在于报文的第一行的第一个单词,通常是一个大写,报文示例如下:
2
3
4
5
6
7
2> Host: 127.0.0.1:8000
3> User-Agent: curl/7.55.1
4> Accept: */*
5>
6
7
HTTP_Parser在解析请求报文时,会将报文头取出,设置为req.method。通常我们只需处理GET与POST两类请求方法,但是在RESTful类Web服务中请求方法十分重要,应为它会决定资源的操作。
- PUT:新建一个资源。
- POST:更新一个资源。
- GET:获取一个资源。
- DELETE:删除一个资源。
(2)路径分析
除了请求会被解析出来外,最常见的请求判断莫过于对路径的判断。路径存在于报文请求方法后,上述示例的路径为/。
完整的url格式应该是这样的:

浏览器会将这个地址解析成报文,将路径和查询部分放在报文的第一行,需要注意的是,hash部分会被丢弃,不会在于报文的任何地方。
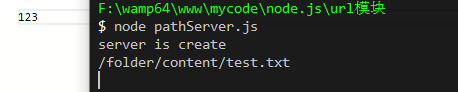
最常见的就是根据路径进行业务处理的应用是静态问及那服务器,它会根据路径去查找磁盘中的文件,然后将其响应给客户端,如下所示:
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
2var fs = require('fs');
3var url = require('url');
4
5var server = http.createServer();
6server.on('request',function(req,res){
7 var pathname = url.parse(req.url).pathname;
8 console.log(pathname); // /folder/content/test.txt
9 fs.readFile('.'+pathname,function(err,datas){
10 if(err){
11 res.writeHead(404);
12 res.end('找不到文件');
13 return;
14 }
15 res.writeHead(200);
16 res.end(datas);
17 });
18});
19server.listen(8000,function(){
20 console.log('server is create')
21});
22
23//./folder/content/test.txt 内容:123
24
25
效果:
使用 postman 进行客户端模拟:
(3)查询字符串
查询字符串位于路径之后,在地址栏中路径后的?foo=bar&baz=val字符串就是查询字符串。
这个字符串会跟随在路径之后,形成请求报文首行的第二部分。这部分内容经常被业务逻辑所用到,Node提供了两种方法处理:
1)querystring模块用于处理这部分数据。
如下所示:
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
2var fs = require('fs');
3var url = require('url');
4var querystring = require('querystring');
5
6var server = http.createServer();
7server.on('request',function(req,res){
8 var query = querystring.parse(url.parse(req.url).query);
9 console.log(query); // { foo: 'bar', baz: 'val' }
10 res.end();
11});
12server.listen(8000,function(){
13 console.log('server is create')
14});
15
16
2)更加简洁的方法就是在url.parse()添加第二个参数。
修改 query变量 如下所示:
2
3
2
3
值得注意的是: 如果查询字符串中的键值出现多次,那么它的值就会以一个数组出现。因此,业务的判断一定要检查值是数组还是字符串,否则会出现TypeError异常。
(4)Cookie
cookie 的实现流程
由于http是一个无状态的协议,现实中的业务却是需要一定的状态的,否则无法区分用户之间的身份。如何标识和认证一个用户,最早的方案就是Cookie。
Cookie的处理分为如下几步:
- 服务器向客户端发送Cookie
- 浏览器将Cookie保存
- 之后每次浏览器都会将Cookie发向服务端
因此HTTP_Parser会将所有的报文字段解析到req.headers上,那么Cookie就是req.headers.cookie。根据规范中的定义,Cookie值的格式是key=value;key2=value2形式,如果有需要Cookie,解析它也很方便。
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
2
3var server = http.createServer();
4server.on('request', function (req, res) {
5/* 将cookie挂载在req对象上 */
6 req.cookies = parseCookie(req.headers.cookie);
7 /* 业务代码 */
8 var handle = function (req, res) {
9 res.writeHead(200);
10 if (!req.cookies.isVisit) {
11 res.end('first')
12 } else {
13 res.end('second')
14 }
15 }
16 handle(req, res);
17});
18server.listen(8000, function () {
19 console.log('server is create')
20});
21
22var parseCookie = function (cookie) {
23 var cookies = {};
24 if (!cookie) {
25 return cookies;
26 }
27 var list = cookie.split(';');
28 for (var i = 0; i < list.length; i++) {
29 var pair = list[i].split('=');
30 cookies[pair[0].trim()] = pair[1];
31 }
32 return cookies;
33}
34
35
使用命令
curl -v -H "Cookie: foo=bar; baz=val" "http://127.0.0.1:1337/path?foo=bar&foo=baz"查看结果:
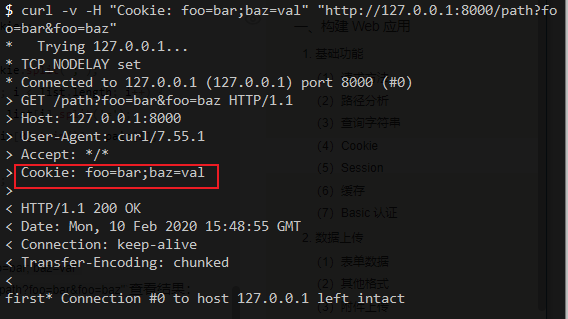
但是值得注意的是,如果Cookie值没有isVisit,都会收到first这样的响应。这里就提出了一个问题,如果识别到用户(客户端)没有访问过我们的站点(服务器),那么我们的站点(服务器)是否有义务告述用户(客户端)已经访问过了的表示呢?鉴于性能方面想这个问题,这个操作是必然的。告述客户端的方式是通过响应报文实现的,响应的Cookie值在Set-Cookie字段中。 它的格式上述Cookie的格式大不相同,规范对于它的定义如下所示:
Set-Cookie: name=value; Path=/; Expires=Sun, 23-Apr-23 09:01:35 GMT; Domain=.domain.com;
其中name=value是必须包含的部分,其余皆是可选参数。这些参数将会影响后续浏览器发送Cookie到服务器的行为,参数说明如下:
- path:表示Cookie影响到的路径,当前路径不满足该匹配时,浏览器不会发送这个Cookie。
- Expires和Max-Age:用来告诉浏览器这个Cookie何时过期,如果不设置该选项,在关闭浏览器时会丢失这个Cookie。Expires的值是一个UTC格式的时间字符串,告诉浏览器此Cookie何时将会过期,Max-Age则告诉浏览器此Cookie多久过期。前者一般不会存在问题,但是如果服务端的时间和客户端的时间不匹配,这种时间设置就会存在偏差,所以需要使用Max-Age来告诉浏览器这条Cookie多久之后过期,而不是一个具体的时间。
- HttpOnly:告诉浏览器不允许通过脚本document.cookie去更改这个Cookie值。
- Secure:当Secure值为true时,在HTTP中无效,在HTTPS中才有效,表示创建Cookie只能通过HTTPS连接中被浏览器传递到服务器端进行会话验证,如果是HTTP连接则不会传递给信息,所以很难被窃听到。
将Cookie序列化成符合规范的字符串:
将上述的业务处理替换成:
2
3
4
5
6
7
8
9
10
11
12
2 if (!req.cookies.isVisit) {
3 res.setHeader('Set-Cookie', serialize('isVisit', '1'));
4 res.writeHead(200);
5 res.end('first');
6 } else {
7 res.writeHead(200);
8 res.end('second');
9 }
10 };
11
12
添加:
Cookie规范功能函数:
2
3
4
5
6
7
8
9
10
11
12
13
2 var pairs = [name + '=' + encodeURI(val)];
3 opt = opt || {};
4 if (opt.maxAge) pairs.push('Max-Age=' + opt.maxAge);
5 if (opt.domain) pairs.push('Domain=' + opt.domain);
6 if (opt.path) pairs.push('Path=' + opt.path);
7 if (opt.expires) pairs.push('Expires=' + opt.expires.toUTCString());
8 if (opt.httpOnly) pairs.push('HttpOnly');
9 if (opt.secure) pairs.push('Secure');
10 return pairs.join('; ');
11};
12
13
结果如下:
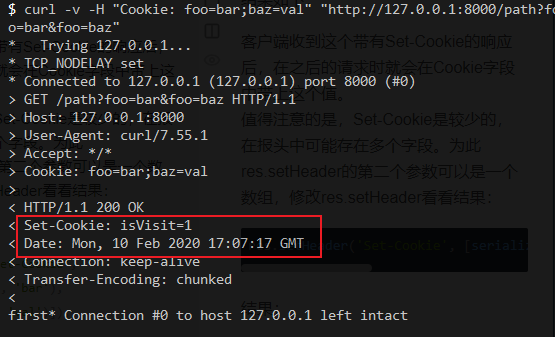
客户端收到这个带有Set-Cookie的响应后,在之后的请求时就会在Cookie字段中带上这个值。
值得注意的是,Set-Cookie是较少的,在报头中可能存在多个字段。为此res.setHeader的第二个参数可以是一个数组,修改res.setHeader看看结果:
2
3
2
3
结果:
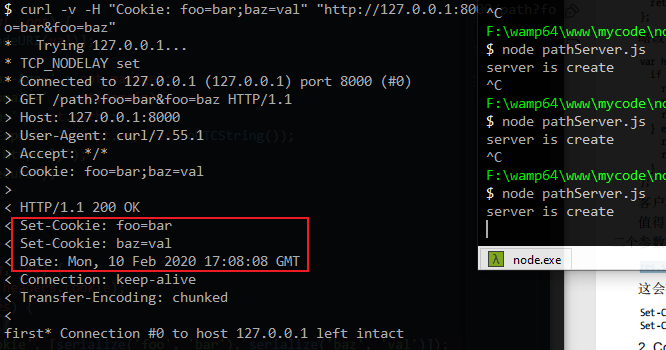
方法二:
直接按照Cookie式规范创建Cookie:
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
2const http = require("http");
3
4// 创建服务
5http.createServer((req, res) => {
6 if (req.url === "/read") {
7 // 读取 cookie
8 console.log(req.headers.cookie);
9 res.end(req.headers.cookie);
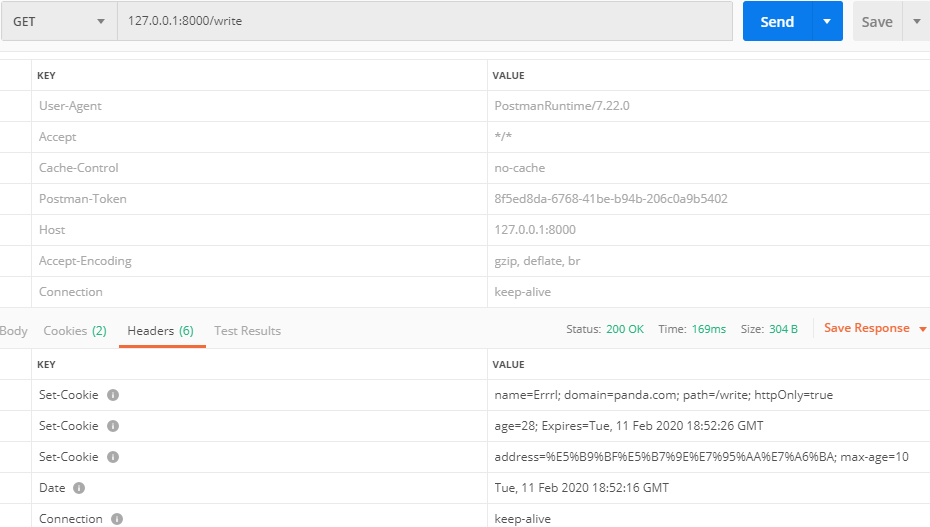
10 } else if (req.url === "/write") {
11 // 设置 cookie
12 res.setHeader("Set-Cookie", [
13 "name=Errrl; domain=panda.com; path=/write; httpOnly=true",
14 `age=28; Expires=${new Date(Date.now() + 1000 * 10).toGMTString()}`,
15 `address=${encodeURIComponent("广州番禺")}; max-age=10`
16 ]);
17 res.end("isDone");
18 } else {
19 res.end("Not Found");
20 }
21}).listen(8000,()=>{
22 console.log('server is create')
23});
24
25
效果:
cookie 的性能优化
由于Cookie的实现机制,一旦服务器向客户端发送设置Cookie的意图,除非Cookie过期,否则客户端每次请求都会发送这些Cookie到服务器端,一旦设置过多,将会导致报头较大。大多数的Cookie并不需要每次都用上,一次会造成带宽的部分浪费。所以在YSlow的性能优化中有一条:
- 减少Cookie的大小
更严重的是,如果域名的根节点设置了Cookie,那么几乎所有的子路径下请求都会带上这些Cookie,这些Cookie在某些情况下有用某些情况下无用。其中以静态文件最为典型。解决办法:
- 为静态组件使用不同的域名
简而言之就是,为不需要Cookie的组件换个域名可以实现减少无效Cookie的传输,所以很多网站的静态文件会有特别的域名,使得业务相关的Cookie不再影响静态资源。
总结: 目前,广告和在线统计领域是最为依赖Cookie,通过嵌入的第三方广告和统计脚本,将Cookie和当前页面绑定,这样就可以标识用户,得到用户的浏览行为。尽管这样的行为很可怕,但是从Cookie的原理来说,
它只能做到标记,而不能做到具有破坏性的事情。所以如果担心自己站点的用户被记录下行为,那就不要挂任何的第三方脚本。
(5)Session
通过Cookie,浏览器和服务器可以实现状态记录,但是Cookie并不是非常完美,上述已经提及Cookie体积过大就是一个显著的问题,最为严重的问题是Cookie可以在前后端进行修改,因此数据就极易被篡改和伪造。
为了解决Cookie的敏感数据问题,Session应运而生,应为Session的数据只保存在服务器中,客户端无法修改,这样的数据安全性才能得到保障,并且数据也无须在协议中重复传递。
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
2const http = require("http");
3const uuid = require('uuid/v1'); // 生成随字符串,npm install uuid
4const querystring = require("querystring");
5
6// 存放 session ,注:正常的Session是放在数据库或者缓存中,为了方便操作先用一个对象模拟。
7const session = {};
8
9// 创建服务
10http.createServer((req, res) => {
11 if (req.url === "/user") {
12 // 取出 cookie 存储的用户 ID
13 let userId = querystring.parse(req.headers["cookie"], "; ")["study"];
14
15 if (userId) {
16 if (session[userId].studyCount === 0) res.end("次数已用尽");
17 session[userId].studyCount--;
18 } else {
19 // 生成 userId
20 userId = uuid();
21 // 将用户信息存入 session
22 session[userId] = { studyCount: 30 };
23 // 设置 cookie
24 res.setHeader("Set-Cookie", [`study=${userId}`]);
25 }
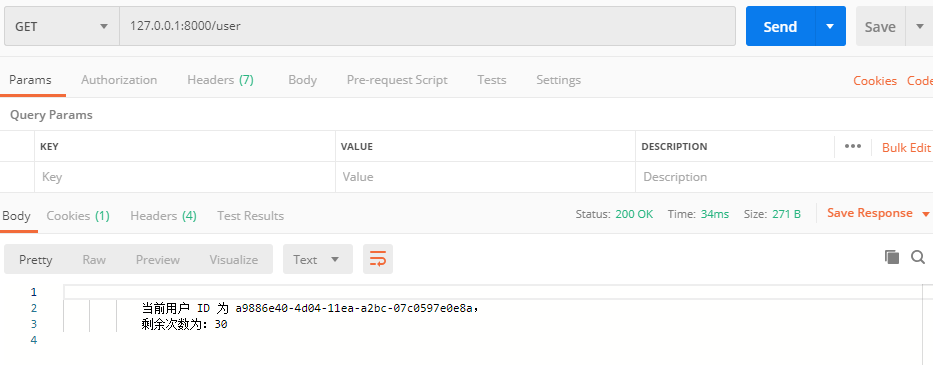
26 // 响应信息
27 res.end(`
28 当前用户 ID 为 ${userId},
29 剩余次数为:${session[userId].studyCount}
30 `);
31 } else {
32 res.end("Not Found");
33 }
34}).listen(8000,()=>{
35 console.log('server is create')
36});
37
38
结果:
(6)缓存
传统的客户端在安装后的应用过程中仅仅需要传输数据,Web应用还需传输构成界面的组件(HTML、JavaScript、CSS文件)。这部分内容在大多数的场景下并不经常改变,却需要在每次的应用中像客户端传递,如果不进行处理,那么他将会造成不必要的宽带浪费。如果网络网速较差,就需要花费更多的时间来打开页面,对于用户来说就是体验性极差。因此节省不必要的传输,对用户和对服务器来说都是一种好处。
缓存规则:
- 添加Expires或者Cache-Control到报文中。
- 配置ETags。
- 使用Ajax进行缓存。
对于请求来说:
通常来说,POST、DELETE、PUT这种行为性的请求操作一般不会进行任何缓存,大多数缓存之应用在GET请求中。
缓存策略
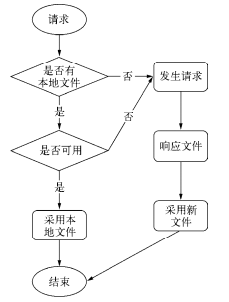
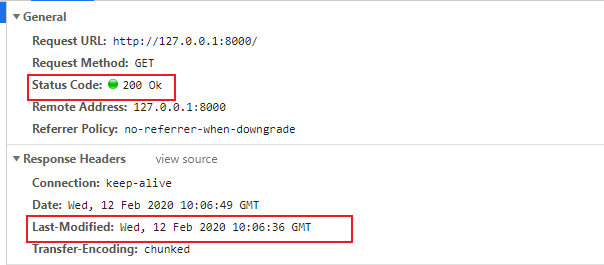
简单来说就是,本地没有文件时,浏览器必然会请求服务器端的内容,并将这部分把内容缓存到本地的某个缓存文件之中。第二次请求时,它将会对本地文件进行一次地毯式搜索,如果不能确定这份本地文件是否可以直接使用,它将会再一次发起请求。所谓的条件请求,就是普通的GET请求报文中附带的If-Modified-Since字段,比如:
2
3
2
3
它将询问服务器端是否有更新的版本,本地文件的最后一次修改时间。如果服务器端没有新的版本,只需响应一个304状态码,客户端使用本地缓存文件,如果服务器端存在更新了的版本,就将新的内容响应给客户端返回状态码200。
测试:
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
2var fs = require('fs');
3var server = http.createServer();
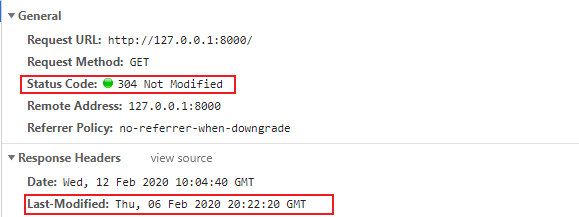
4server.on('request', (req, res) => {
5 fs.stat('./test2.txt', function (err, stat) {
6 var lastModified = stat.mtime.toUTCString();
7 if (lastModified === req.headers['if-modified-since']) {
8 res.writeHead(304, "Not Modified");
9 res.end();
10 } else {
11 fs.readFile('./test2.txt', function (err, file) {
12 var lastModified = stat.mtime.toUTCString();
13 res.setHeader("Last-Modified", lastModified);
14 res.writeHead(200, "Ok");
15 res.end(file);
16 });
17 }
18 })
19}).listen(8000, () => {
20 console.log('server is create')
21})
22
23
结果:

刷新、关闭浏览器再打开,观测结果:
修改文件内容:
TXT:(./test2.txt)后观察结果:
这里的条件请求采用的就是时间戳的方式实现,但是时间戳有一定的缺陷:
- 文件时间戳改动但内容并不一定改动。
- 时间戳只能精确到秒级,更新频繁的内容可能就无法适应,生效。
针对上面的问题,ETag就是来解决这个问题的,ETag由服务器端生成,服务器端可以决定它的生成规则。如果根据文件内容生成散列值,那么条件请求将不会受到时间戳的改动造成的宽带浪费,下面是根据内容生成散列值的方法:
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
2var crypto = require('crypto');
3var http = require('http');
4var fs = require('fs');
5var getHash = function (str) {
6 var shasum = crypto.createHash('sha1');
7 return shasum.update(str).digest('base64')
8}
9var server = http.createServer();
10server.on('request', function (req, res) {
11 fs.readFile('./test2.txt', function (err, file) {
12 var hash = getHash(file);
13 var noneMatch = req.headers['if-none-match'];
14 if (hash === noneMatch) {
15 res.writeHead(304, "Not Modified");
16 res.end();
17 } else {
18 res.setHeader("ETag", hash);
19 res.writeHead(200, "Ok");
20 res.end(file);
21 }
22 });
23}).listen(8000,()=>{
24 console.log('server is create')
25})
26
27
效果:
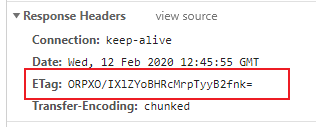
第二次请求:

也就是说,浏览器在收到Etag:ORPXO/IXlZYoBHRcMrpTyyB2fnk=这样的响应后,在下一次请求时,会将其放置在请求头中:If-None-Match: ORPXO/IXlZYoBHRcMrpTyyB2fnk=。
尽管条件请求可以在文件内容没有被修改的情况下节省宽带,但是它依然会发起一个HTTP请求,使得客户端依然会花一定的时间来等待响应,可见最好的方案就是连条件请求都不用发起。那如何使浏览器知晓是否能直接使用本地版本呢?答案就是服务器端在响应时,让浏览器明确地将内容缓存起来,所以这就是上面YSlow提到的Expires和Cache-Control。浏览器就是根据该值进行缓存的。
两者的区别如下:
Expires
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
2var http = require('http');
3var fs = require('fs');
4
5var server = http.createServer();
6server.on('request', function (req, res) {
7 fs.readFile('./test2.txt', function (err, file) {
8 var expires = new Date();
9 expires.setTime(expires.getTime() + 10 * 365 * 24 * 60 * 60 * 1000);
10 res.setHeader("Expires", expires.toUTCString());
11 res.writeHead(200, "Ok");
12 res.end(file);
13 });
14}).listen(8000, () => {
15 console.log('server is create')
16})
17
18
效果:
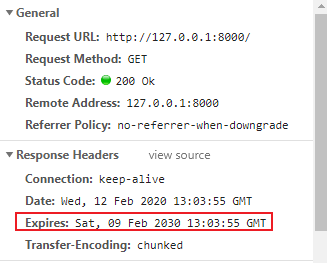
Expires是一个GMT格式的字符串,浏览器在接到这个过期值后,只要本地还存在这个缓存文件,在到期时间之前她就不会再次发起请求。上述Expires设置了10年。但是Expires的缺陷在于浏览器与服务器之间的时间可能不一致,这可能会带来一些问题。比如文件提前过期,或者到期后没有被删除,这种情况,Cache-Control以更丰富的形式,实现相同的功能:
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
2var http = require('http');
3var fs = require('fs');
4
5var server = http.createServer();
6server.on('request', function (req, res) {
7 fs.readFile('./test2.txt', function (err, file) {
8 res.setHeader("Cache-Control", "max-age=" + 10 * 365 * 24 * 60 * 60 * 1000);
9 res.writeHead(200, "Ok");
10 res.end(file);
11 });
12}).listen(8000, () => {
13 console.log('server is create')
14})
15
16
效果:
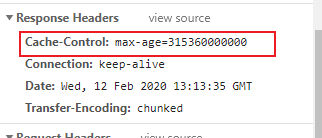
上面的代码为Cache-Control设置了max-age值,它比Expires优秀的地方在于,Cache-Control能够避免服务器端与浏览器端时间不同步带来的不一致性问题,只要进行类似的倒计时的方式计算过期时间即可。除此之外,Cache-Control的值还有public、private、no-cache、no-store等能够更加精细控制缓存的选项。
值得注意的是:由于HTTP1.0时还不支持max-age,如今的服务器端在模块的支持下多半同时对Expires和Cache-Control进行支持。在浏览器中如果两个值同时存在,且被同时支持时,max-age会覆盖Expires。
清除缓存
出现情况:缓存被设置,服务器意外更新内容,却无法通知客户端进行更新。这使得我们在使用缓存时也要同时为其设置版本号,所幸的是浏览器会根据URL进行缓存,难么一旦内容有所更新,我们就会让浏览器发起新的URL请求,使得新内容能够被用户端更新,更新机制如下:
- 每一次发布,路径中跟随Web应用的版本号:http://url.com/?version=20200212。
- 每一次发布,路径中跟随文件内容的hash值:http://url.com/?hash=afadfadwe。(推荐)
