
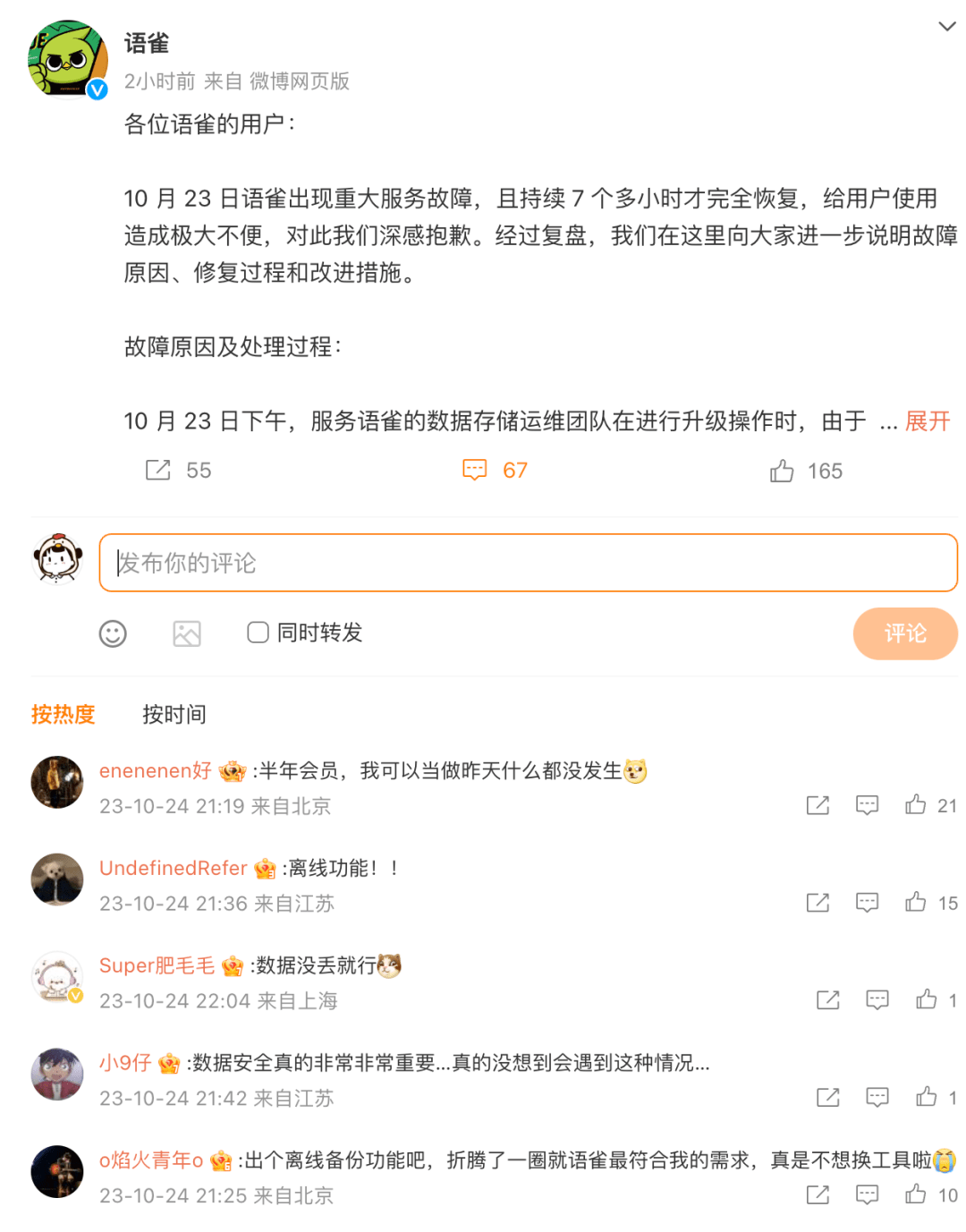
- 故障时间:10月23日下午。
- 故障现象:语雀出现重大服务故障,持续 7 个多小时。
- 直接原因:数据存储运维团队在进行升级操作时,新的运维升级工具出现 bug。
- 具体细节:bug导致华东地区生产环境存储服务器被误下线,使语雀数据服务发生严重故障,造成大面积服务中断。
- 恢复过程:
- 因机器类别较老,无法直接操作上线,只能从备份系统中恢复存储数据。
- 数据恢复过程耗时较长,直到晚上 22 点,语雀的全部服务才得以恢复。
语雀是什么
语雀是蚂蚁集团内部孵化的一款笔记类工具,友好的 Markdown 支持,丰富的绘图模板、简洁的界面和近乎完美的知识库管理使得语雀收获了大量的用户,除去整个阿里和蚂蚁集团内部用户外,保守估计用户量千万级别以上,可谓是非常庞大的用户体系了。
我也是一路见证了语雀的成长,早年间,还只是我们在整个集团内部使用,后面扩展到整个阿里,所有文档的沉淀都在语雀进行。后面因受到集团内一致好评以及从集团毕业后的用户的强烈渴望开放外网使用,于是有了外网的版本,从最初的 web 页面,到后面的 APP 和客户端的支持,到后面的数字花园,语雀产品始终走在同类产品前列,而且这个产品对互联网行业有着天然的支持,他甚至比我们更懂我们。
我离开蚂蚁后,也像大多数人一样,使用习惯了语雀,参加活动得了一年的会员,把所有的知识都从印象笔记移到了语雀,基本是 ALL in 语雀。
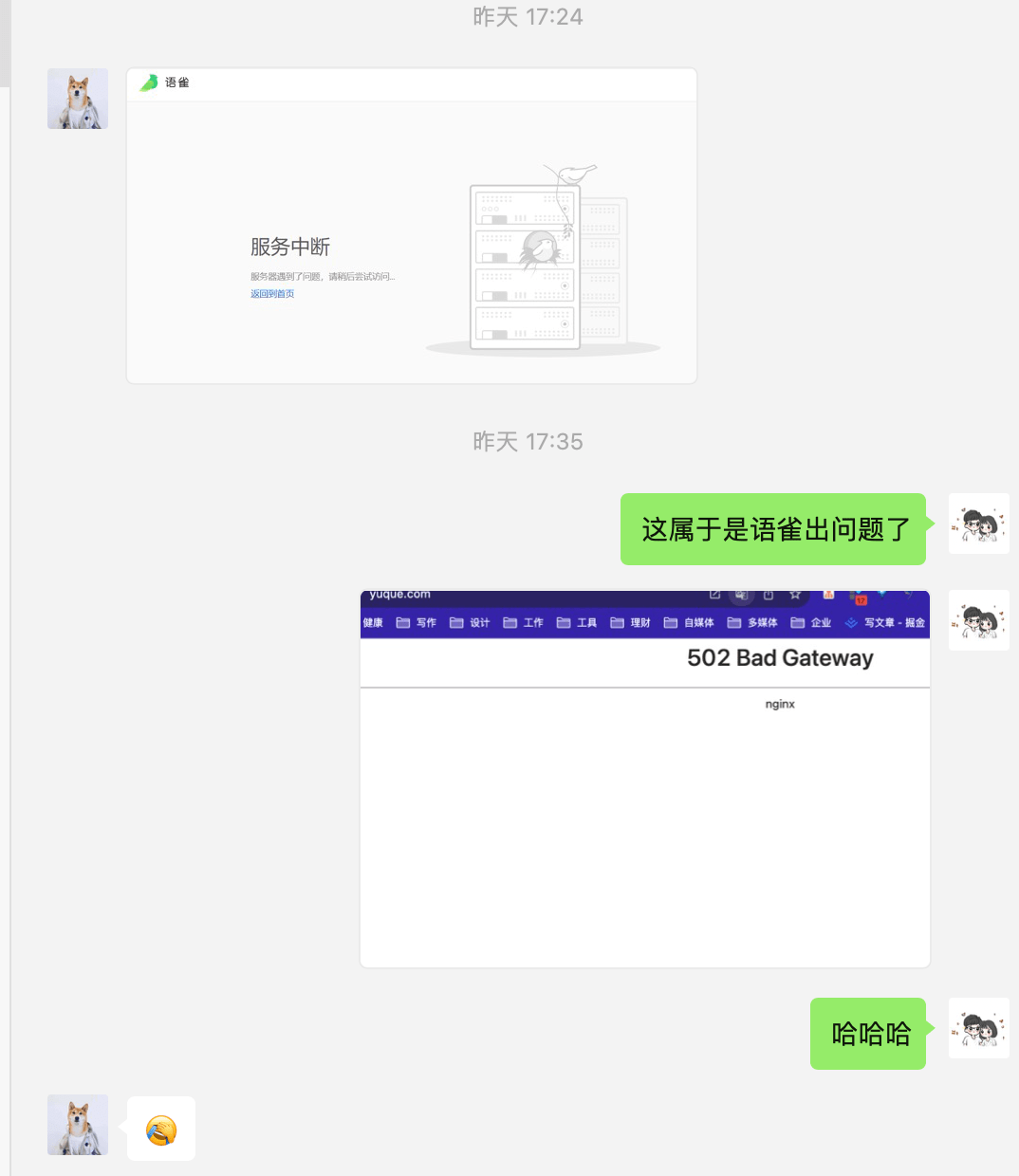
语雀崩了,开发者怎么看?
语雀的宕机事件在网络上引发巨大讨论,有网友对在线文档的可靠性提出质疑,有网友调侃语雀的运维手册是不是写在了语雀文档上,也有网友分析语雀创始人玉伯离职后,语雀是否已经走到了“生死局”,有被阿里放弃的可能?
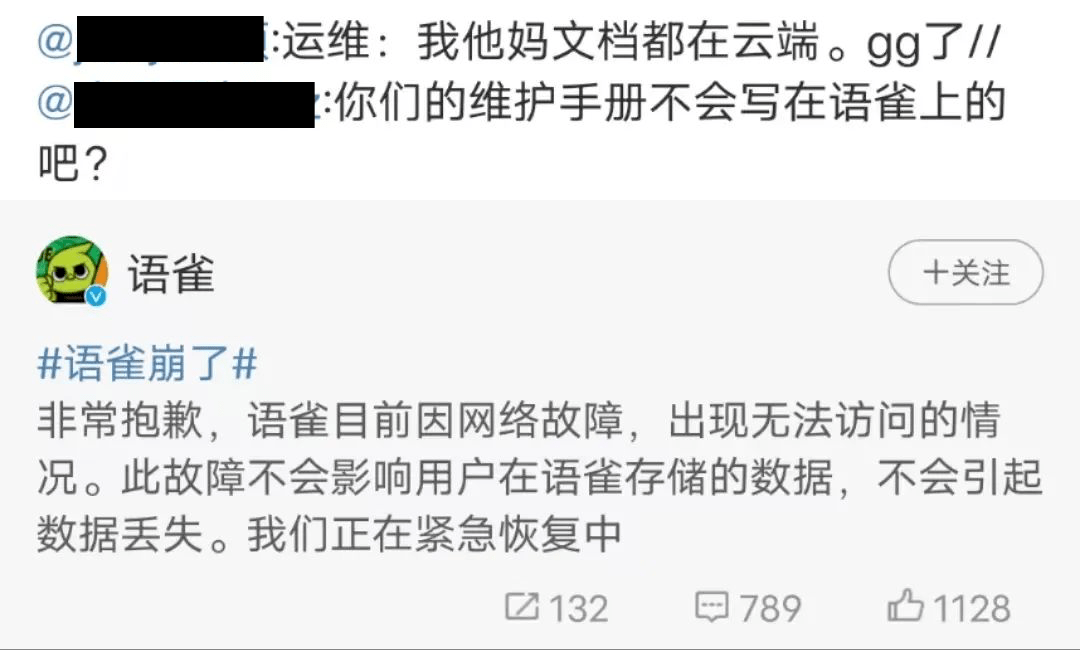
网友想喝阔落 de 阿七认为,最基础的信息安全是知识库类工具最根本的竞争力,如果今后再出现类似情况导致数据丢失,亡羊补牢的赔偿都是无济于事的。而且语雀的后续改进方案中只字未提本地离线存储功能的开发,那么将如何保证用户数据的万无一失?
知乎网友 @段小草从云服务故障角度进行了分析,他认为在线文档的可靠性和信任问题是所有云服务面临的问题:
云服务不可靠性的问题是无解的,只能从理论上讲,用户越多的大厂产品,运维保障能力越强,理论上会越有保障。但这样的时候我们是需要取舍的,比如像 OpenAI 的 API 服务,如果没有任何的一家产品能提供与之相当的服务,那就只能祈祷它不出问题;但如果可以,就要有容灾的备选,甚至做一个本地模型顶上,哪怕性能不如 GPT-4 也可以最大程度地保证业务不中断。
但像笔记软件这种,其实可选产品很多,本地软件也有,再把身家性命系到唯一的在线服务上就没那么明智了。如果没有协作需求,完全可以自己离线。即便有多人联网协作需求,语雀这次的宕机过后,相信笔记软件之间的互相备份,或者像题主提到的本地存储 + 云端备份 + 多人协作的想法,也会有相应的解决方案。
知乎网友 @王半山认为,语雀在蚂蚁体系内是巨大的负担,成本远大于收益:
语雀在未商业化之前,是集团内部代替 confluence 存在的,因为内部的文档资料实在太多,confluence 的性能不够,所以在内部就做了一个 yuque,而且这个东西是前端的团队维护的。团队规模还小的话,用起来还好,但是一旦商业化,大规模用了,那性能就肯定是巨大的瓶颈了。这个产品主要是前端团队主导,大量的后端都是用 NodeJS 写的,这就养了一批独立集团内部 Java 体系之外开发人员,这样无论是现有的集团账号架构、高可用架构都没法直接复用,所有就有了大量需要重复造轮子的事情发生,这些都是要成本的。
如何保证系统发布的稳定性?
首先,这几点都是企业正式线上项目需要重点关注的能力,所以大家在校自学时一般是很少能接触到的。
但如果你知道并实践过这些,前途不可限量啊!
可监控
可监控是指能够实时地收集和展示系统运行时的数据和指标,以便开发和运维同学可以及时发现系统问题、更快进行故障排查和性能调优。需要监控的信息可以包括系统性能指标(内存、CPU、带宽等)、业务日志、错误信息等。
还有一个与之相关的术语 “可观测性”,就是指一个系统状态对开发维护者的透明程度。举个例子,我不需要每次打开服务器看日志或者用什么 jmap 命令分析 gc,而是直接通过一个面板整体查看系统的状态,甚至是自动提示问题和解决方案。
AIOps 智能运维也是现在很流行的一种技术,用 AI 帮忙运维诊断系统,大大提高开发运维效率。
可灰度
指灰度发布能力(又叫金丝雀发布)。将系统的新版本全量部署给所有用户之前,先仅对一小部分用户进行试用。这样可以通过收集这部分用户的反馈和监控数据就能评估新版本的稳定性,并及时进行调整和修复,从而减少对全体用户的潜在风险。
灰度发布又有很多策略。比如经典的按流量阶段性发布,先随机给 5% 的用户使用新版本,验证没问题后,再给 20%、50%、75% 的用户使用新版本逐渐放量,直到覆盖 100% 的用户。
还有很多策略,列举几个常见的:
1)按照用户的业务属性灰度,比如 VIP 用户先用、老用户先用。
2)按人群灰度,比如特定地域、特定年龄、特定偏好、特定客户端的用户。
3)按渠道灰度,比如通过某平台注册的用户先体验等等。
灰度做的好,可以避免很多线上问题,及时控制影响。因此很多知名产品发布时都会采用灰度或者内测的策略,这也就是为什么有些同学能第一时间体验到微信新功能,有些同学却没有。
可回滚
就像 Git 版本控制系统回滚写错的代码一样,系统的版本也是可以回滚的。
线上系统出现问题时,可以将已经部署的新版本回退到之前的稳定版本。这样做可以快速恢复系统,减少对用户的影响,并给开发同学足够的时间来排查和修复问题。而不是线上一直故障,每分钟都是损失。
网上收录小结:
通过这次的事件,也有一些思考。
1. 强化预防措施:
- 在进行任何系统升级或修改之前,应确保有详尽的预案和充分的测试。
- 加强运维工具的质量保障和测试,确保工具的稳定性和可靠性。
- 始终坚持三板斧原则:即“可监控,可灰度,可回滚”,
2. 优化故障应对机制:
- 在故障发生时,能够迅速准确地定位问题,缩短故障恢复时间。
- 建立健全的故障应急响应机制和流程,以便在出现问题时能够迅速、有序地进行处理。
3. 完善系统架构:
- 考虑系统的高可用性和灾备设计,减少单点故障的风险。
- 考虑到机器的更新换代,避免因硬件陈旧导致的操作限制。
4. 增强用户沟通:
- 在故障发生时,及时、准确地通知用户,降低用户的不确定感和焦虑感。
- 在故障恢复后,向用户说明故障原因和改进措施,增加用户的信任感。
5. 持续改进和学习:
- 从故障中吸取教训,总结经验,避免类似问题的再次发生。
- 定期进行故障演练,提高团队的应对能力。
通过这次故障,相信语雀团队也能更清晰地认识到自身在服务稳定性和应急响应方面的不足,从而采取更加全面和有效的措施,不断优化和提高服务质量,为用户带来更好的使用体验。
