短视频生产消费监控
短视频带来了全新的传播场域和节目形态,小屏幕、快节奏成为行业潮流的同时,也催生了新的用户消费习惯,为创作者和商户带来收益。而多元化的短视频也可以为品牌方提供营销机遇。
其中对于垂类生态短视频的生产消费热点的监控分析目前成为了实时数据处理很常见的一个应用场景,比如对某个圈定的垂类生态下的视频生产或者视频消费进行监控,对热点视频生成对应的优化推荐策略,促进热点视频的生产或者消费,构建整个生产消费数据链路的闭环,从而提高创作者收益以及消费者留存。
本文将完整分析垂类生态短视频生产消费数据的整条链路流转方式,并基于 Flink 提供几种对于垂类视频生产消费监控的方案设计。通过本文,你可以了解到:
- 垂类生态短视频生产消费数据链路闭环
- 实时监控短视频生产消费的方案设计
- 不同监控量级场景下的代码实现
- flink 学习资料
项目简介
垂类生态短视频生产消费数据链路流转架构图如下,此数据流转图也适用于其他场景:
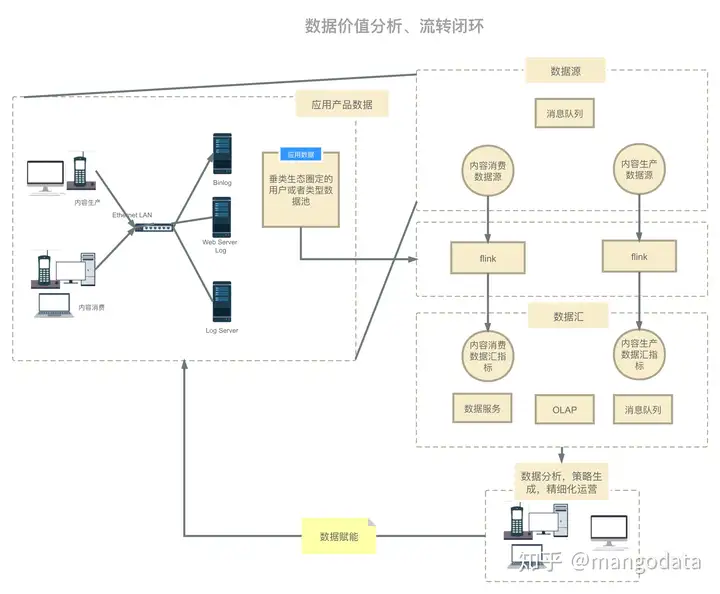
在上述场景中,用户生产和消费短视频,从而客户端、服务端以及数据库会产生相应的行为操作日志,这些日志会通过日志抽取中间件抽取到消息队列中,我们目前的场景中是使用 Kafka 作为消息队列;然后使用 flink 对垂类生态中的视频进行生产或消费监控(内容生产通常是圈定垂类作者 id 池,内容消费通常是圈定垂类视频 id 池),最后将实时聚合数据产出到下游;下游可以以数据服务,实时看板的方式展现,运营同学或者自动化工具最终会帮助我们分析当前垂类下的生产或者消费热点,从而生成推荐策略。
方案设计
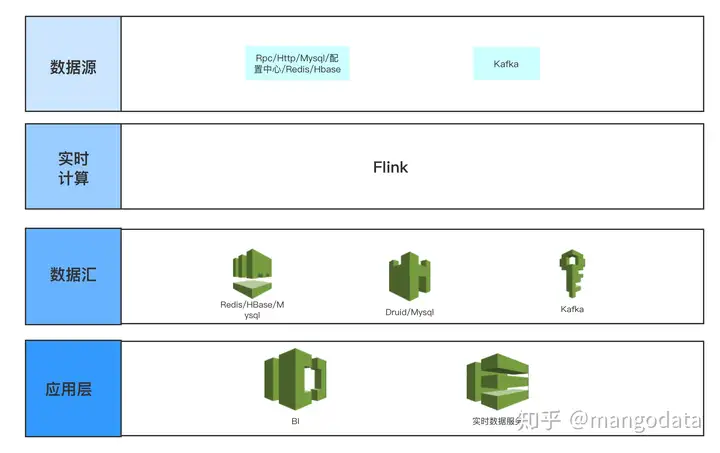
其中数据源如下:
- Kafka 为全量内容生产和内容消费的日志。
- Rpc/Http/Mysql/配置中心/Redis/HBase 为需要监控的垂类生态内容 id 池(内容生产则为作者 id 池,内容消费则为视频 id 池),其主要是提供给运营同学动态配置需要监控的 id 范围,其可以在 flink 中进行实时查询,解析运营同学想要的监控指标范围,以及监控的指标和计算方式,然后加工数据产出,可以支持随时配置,实时数据随时计算产出。
其中数据汇为聚类好的内容生产或者消费热点话题或者事件指标:
- Redis/HBase 主要是以低延迟(Redis 5ms p99,HBase 100ms p99,不同公司的服务能力不同)并且高 QPS 提供数据服务,给 Server 端或者线上用户提供低延迟的数据查询。
- Druid/Mysql 可以做为 OLAP 引擎为 BI 分析提供灵活的上卷下钻聚合分析能力,供运营同学配置可视化图表使用。
- Kafka 可以以流式数据产出,从而提供给下游继续消费或者进行特征提取。
废话不多说,我们直接上方案和代码,下述几种方案按照监控 id 范围量级区分,不同的量级对应着不同的方案,其中的代码示例为 ProcessWindowFunction,也可以使用 AggregateFunction 代替,其中主要监控逻辑都相同。
方案 1
适合监控 id 数据量小的场景(几千 id),其实现方式是在 flink 任务初始化时将需要监控的 id 池或动态配置中心的 id 池加载到内存当中,之后只需要在内存中判断内容生产或者消费数据是否在这个监控池当中。
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
<em>// 配置中心动态 id 池
</em><em></em> private Config<Set<Long>> needMonitoredIdsConfig;
@Override
public void open(Configuration parameters) throws Exception {
this.needMonitoredIdsConfig = ConfigBuilder
.buildSet("needMonitoredIds", Long.class);
}
@Override
public void process(Long bucket, Context context, Iterable<CommonModel> iterable, Collector<CommonModel> collector) throws Exception {
Set<Long> needMonitoredIds = needMonitoredIdsConfig.get();
<em>/**
</em><em> * 判断 commonModel 中的 id 是否在 needMonitoredIds 池中
</em><em> */</em>
}
}
监控的 id 池可以按照固定或者可配置从而分出两种获取方式:第一种是在 flink 任务开始时就全部加载进内存中,这种方式适合监控 id 池不变的情况;第二种是使用动态配置中心,每次都从配置中心访问到最新的监控 id 池,其可以满足动态配置或者更改 id 池的需求,并且这种实现方式通常可以实时感知到配置更改,几乎无延迟。
方案 2
适合监控 id 数据量适中(几十万 id),监控数据范围会不定时发生变动的场景。其实现方式是在 flink 算子中定时访问接口获取最新的监控 id 池,以获取最新监控数据范围。
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
private long lastRefreshTimestamp;
private Set<Long> needMonitoredIds;
@Override
public void open(Configuration parameters) throws Exception {
super.open(parameters);
this.refreshNeedMonitoredIds(System.currentTimeMillis());
}
@Override
public void process(Long bucket, Context context, Iterable<CommonModel> iterable, Collector<CommonModel> collector) throws Exception {
long windowStart = context.window().getStart();
this.refreshNeedMonitoredIds(windowStart);
<em>/**
</em><em> * 判断 commonModel 中的 id 是否在 needMonitoredIds 池中
</em><em> */</em>
}
public void refreshNeedMonitoredIds(long windowStart) {
<em>// 每隔 10 秒访问一次
</em><em></em> if (windowStart - this.lastRefreshTimestamp >= 10000L) {
this.lastRefreshTimestamp = windowStart;
this.needMonitoredIds = Rpc.get(...)
}
}
}
根据上述代码实现方式,按照时间间隔的方式刷新 id 池,其缺点在于不能实时感知监控 id 池的变化,所以刷新时间可能会和需求场景强耦合(如果 id 池会频繁更新,那么就需要缩小刷新时间间隔)。也可根据需求场景在每个窗口开始前刷新 id 池,这样可保证每个窗口中的 id 池中的数据一直保持更新。
方案 3
方案 3 对方案 2 的一个优化(几十万 id,我们生产环境中最常用的)。其实现方式是在 flink 中使用 broadcast 算子定时访问监控 id 池,并将 id 池以广播的形式下发给下游参与计算的各个算子。其优化点在于:比如任务的并行度为 500,每 1s 访问一次,采用方案 2 则访问监控 id 池接口的 QPS 为 500,在使用 broadcast 算子之后,其访问 QPS 可以减少到 1,可以大大减少对接口的访问量,减轻接口压力。
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
@Slf4j
static class NeedMonitorIdsSource implements SourceFunction<Map<Long, Set<Long>>> {
private volatile boolean isCancel;
@Override
public void run(SourceContext<Map<Long, Set<Long>>> sourceContext) throws Exception {
while (!this.isCancel) {
try {
TimeUnit.SECONDS.sleep(1);
Set<Long> needMonitorIds = Rpc.get(...);
<em>// 可以和上一次访问的数据做比较查看是否有变化,如果有变化,才发送出去
</em><em></em> if (CollectionUtils.isNotEmpty(needMonitorIds)) {
sourceContext.collect(new HashMap<Long, Set<Long>>() {{
put(0L, needMonitorIds);
}});
}
} catch (Throwable e) {
<em>// 防止接口访问失败导致的错误导致 flink job 挂掉
</em><em></em> log.error("need monitor ids error", e);
}
}
}
@Override
public void cancel() {
this.isCancel = true;
}
}
public static void main(String[] args) {
ParameterTool parameterTool = ParameterTool.fromArgs(args);
InputParams inputParams = new InputParams(parameterTool);
StreamExecutionEnvironment env = StreamExecutionEnvironment.createLocalEnvironment();
final MapStateDescriptor<Long, Set<Long>> broadcastMapStateDescriptor = new MapStateDescriptor<>(
"config-keywords",
BasicTypeInfo.LONG_TYPE_INFO,
TypeInformation.of(new TypeHint<Set<Long>>() {
}));
<em>/********************* kafka source *********************/</em>
BroadcastStream<Map<Long, Set<Long>>> broadcastStream = env
.addSource(new NeedMonitorIdsSource()) <em>// redis photoId 数据广播
</em><em></em> .setParallelism(1)
.broadcast(broadcastMapStateDescriptor);
DataStream<CommonModel> logSourceDataStream = SourceFactory.getSourceDataStream(...);
<em>/********************* dag *********************/</em>
DataStream<CommonModel> resultDataStream = logSourceDataStream
.keyBy(KeySelectorFactory.getStringKeySelector(CommonModel::getKeyField))
.connect(broadcastStream)
.process(new KeyedBroadcastProcessFunction<String, CommonModel, Map<Long, Set<Long>>, CommonModel>() {
private Set<Long> needMonitoredIds;
@Override
public void open(Configuration parameters) throws Exception {
super.open(parameters);
this.needMonitoredIds = Rpc.get(...)
}
@Override
public void processElement(CommonModel commonModel, ReadOnlyContext readOnlyContext, Collector<CommonModel> collector) throws Exception {
<em>// 判断 commonModel 中的 id 是否在 needMonitoredIds 池中
</em><em></em> }
@Override
public void processBroadcastElement(Map<Long, Set<Long>> longSetMap, Context context, Collector<CommonModel> collector) throws Exception {
<em>// 需要监控的字段
</em><em></em> Set<Long> needMonitorIds = longSetMap.get(0L);
if (CollectionUtils.isNotEmpty(needMonitorIds)) {
this.needMonitoredIds = needMonitorIds;
}
}
});
<em>/********************* kafka sink *********************/</em>
SinkFactory.setSinkDataStream(...);
env.execute(inputParams.jobName);
}
}
方案 4
适合于超大监控范围的数据(几百万,我们自己的生产实践中使用扩量到 500 万)。其原理是将监控范围接口按照 id 按照一定规则分桶。flink 消费到日志数据后将 id 按照 监控范围接口 id 相同的分桶方法进行分桶 keyBy,这样在下游算子中每个算子中就可以按照桶名称,从接口中拿到对应桶的监控 id 数据,这样 flink 中并行的每个算子只需要获取到自己对应的桶的数据,可以大大减少请求的压力。
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
public static void main(String[] args) {
ParameterTool parameterTool = ParameterTool.fromArgs(args);
InputParams inputParams = new InputParams(parameterTool);
StreamExecutionEnvironment env = StreamExecutionEnvironment.createLocalEnvironment();
final MapStateDescriptor<Long, Set<Long>> broadcastMapStateDescriptor = new MapStateDescriptor<>(
"config-keywords",
BasicTypeInfo.LONG_TYPE_INFO,
TypeInformation.of(new TypeHint<Set<Long>>() {
}));
<em>/********************* kafka source *********************/</em>
DataStream<CommonModel> logSourceDataStream = SourceFactory.getSourceDataStream(...);
<em>/********************* dag *********************/</em>
DataStream<CommonModel> resultDataStream = logSourceDataStream
.keyBy(KeySelectorFactory.getLongKeySelector(CommonModel::getKeyField))
.timeWindow(Time.seconds(inputParams.accTimeWindowSeconds))
.process(new ProcessWindowFunction<CommonModel, CommonModel, Long, TimeWindow>() {
private long lastRefreshTimestamp;
private Set<Long> oneBucketNeedMonitoredIds;
@Override
public void open(Configuration parameters) throws Exception {
super.open(parameters);
}
@Override
public void process(Long bucket, Context context, Iterable<CommonModel> iterable, Collector<CommonModel> collector) throws Exception {
long windowStart = context.window().getStart();
this.refreshNeedMonitoredIds(windowStart, bucket);
<em>/**
</em><em> * 判断 commonModel 中的 id 是否在 needMonitoredIds 池中
</em><em> */</em>
}
public void refreshNeedMonitoredIds(long windowStart, long bucket) {
<em>// 每隔 10 秒访问一次
</em><em></em> if (windowStart - this.lastRefreshTimestamp >= 10000L) {
this.lastRefreshTimestamp = windowStart;
this.oneBucketNeedMonitoredIds = Rpc.get(bucket, ...)
}
}
});
<em>/********************* kafka sink *********************/</em>
SinkFactory.setSinkDataStream(...);
env.execute(inputParams.jobName);
}
}
总结
本文首先介绍了,在短视频领域中,短视频生产消费数据链路的整个闭环,并且其数据链路闭环一般情况下也适用于其他场景;以及对应的实时监控方案的设计和不同场景下的代码实现,包括:
- 垂类生态短视频生产消费数据链路闭环:用户操作行为日志的流转,日志上传,实时计算,以及流转到 BI,数据服务,最后数据赋能的整个流程
- 实时监控方案设计:监控类实时计算流程中各类数据源,数据汇的选型
- 监控 id 池在不同量级场景下具体代码实现
技术架构
回顾上一节的「技术架构」图。
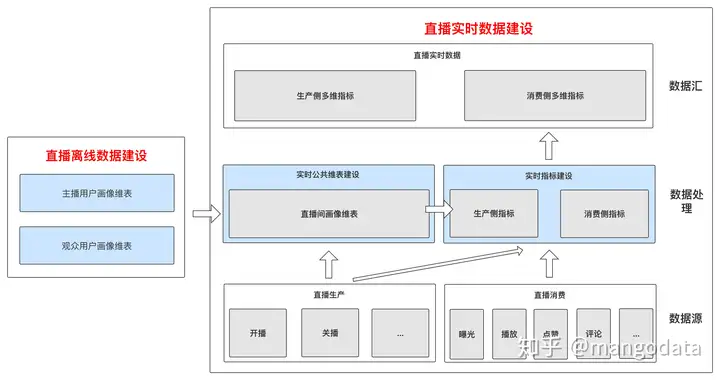
整个架构相对来说是比较好理解的。从数据源到数据处理以及最后到数据汇部分。
但是大家的疑惑点可能就集中在三个维表的建设上,包含「主播用户画像维表,观众用户画像维表,直播间画像维表」
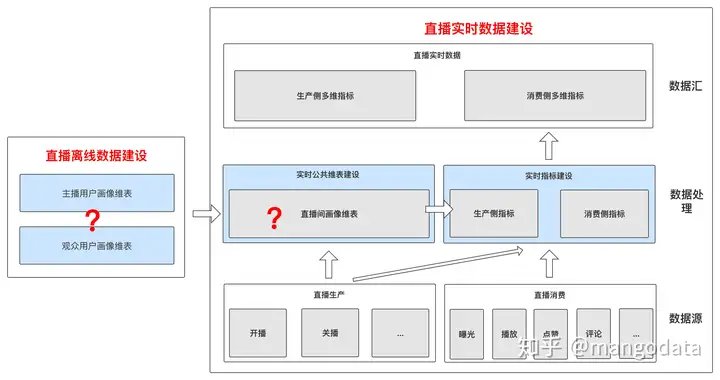
我们依然从以下几个角度的问题出发,通过分析场景,解答这几个问题来给大家介绍以上三个维表的建设过程。
Question
- 「WHAT:直播实时公共画像维表是指什么?离线公共画像维表又指什么?区别?」
- 「WHY:为什么架构图中的三类公共画像维表要按照实时和离线进行划分?为什么需要建设实时公共画像维表,离线公共画像维表不能满足需求?」
- 「HOW:怎样才能建设满足直播实时数据的实时公共画像维表?」
- 「WHO:需要使用什么样的组件建设直播实时公共画像维表?为什么选用这些组件进行建设?」
WHAT:实时 & 离线公共画像维表?
概念
首先简单介绍下,「实时 & 离线公共画像维表」中存储的内容就是实体的固有属性(比如用户的年龄等),我理解这两个词本身是高层抽象的概念,本文中介绍的「主播用户画像维表,观众用户画像维表,直播间画像维表」是其具体实现。
其他大佬的文章解释中会对「实时公共画像维表」 & 「离线公共画像维表」有更加深度的理解,这里我只说明我在直播实时数据建设过程中的理解~
区别
其实这两个词的区别从名字上就可以区分出来,实时公共画像维表和离线公共画像维表的最大区别就是数据建设和应用场景要求的时效性不同。
离线公共画像维表
特点:
- 「场景」:适合离线场景,「时效性要求比较弱」的场景,为指标提供画像维度填充或者打标服务
- 「建设」:一般都是以离线 t + 1 的方式进行建设
- 「应用」:使用的数据为离线 t + 1 的数据
- 「举例」:数据仓库中的用户画像维表,为应用层数据提供画像服务;比如不但需要统计总 uv,还需要统计分年龄段的 uv。
实时公共画像维表
特点:
- 「场景」:适合实时场景,「时效性要求比较强」的场景,为指标提供画像维度填充或者打标服务
- 「建设」:实时的进行建设,延迟一般在秒级别
- 「应用」:使用的数据都是实时建设好的,必须可以实时获取(秒级别延迟后获取到)并使用
WHY:为什么建设实时公共画像维表?
为什么架构图中的三类公共画像维表要按照实时和离线进行划分?为什么需要建设实时公共画像维表,离线公共画像维表不能满足需求?
这几个问题其实围绕着我们的直播实时数据建设以及应用的场景就可以展开解答。
接上篇技术架构图,其中直播实时数据需要建设的公共维表分为以下三类:
- 「直播间画像维表」:包含直播对应的直播类别、开播客户端、标题、开播地址等信息
- 「主播画像维表」:主播对应的主播名、主播类别、性别、年龄段等
- 「观众画像维表」:观众对应的观众性别、年龄段等
直播间画像维表
首先抛出结论:「直播间画像都是直播间的固有属性画像,直播间画像维表的建设过程是实时的」。
由于大多数直播的时长都在几小时不等,随着直播的开始,主播域观众的互动也随即产生,从而直播生产和消费的指标也开始产出,随着直播的结束,主播和观众的互动也就结束了,对应的直播生产和消费指标也就不存在了,因此直播间画像的所能提供给其他指标作为维表的价值也就快速消失了,所以直播间画像(标题,开播地址)的应用场景特点就是「时效性很强」。 因此直播间画像维表对于直播生产消费指标的建设和应用来说,需要满足可实时建设、可实时查询获取的要求。
主播 & 观众用户画像维表
结论:「这类画像都是用户的固有属性画像,而非直播间固有属性,和直播间是非强相关的。主播 & 观众用户画像维表的建设过程可以是离线的」。
无论直播间的开播关播,直播过程中的生产消费,主播画像和观众画像基本上不会产生变动。 (举例:大多数情况下,当已经判定一个用户的年龄段画像为 18 – 23 时,即使这个用户开了 10 场直播,或者这个用户观看了 10 场直播,其年龄段判定也基本不会有变化)。 因此主播用户画像维表 & 观众用户画像维表对于直播生产消费指标的建设和应用来说,可以满足离线 t + 1 建设,提供数据服务进行实时获取的要求。
❝ Notes:
主播 & 观众用户画像需要根据用户生产消费行为以及其他信息,使用到机器学习进行性别和年龄段等的用户画像信息判定产出。 也有非常多的场景将这类画像进行实时建设,用于实时个性化推荐等。只不过本文的直播实时数据建设对于这两类画像的时效性要求较弱,所以采用了离线的方式进行建设。
❞
HOW + WHO:怎样建设?用什么建设?
直播间生命周期 & 数据流转
直播间整个生命周期如图所示。
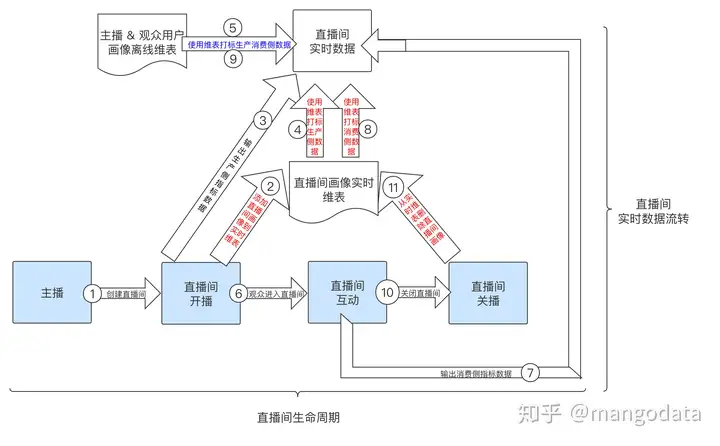
- 1.主播创建直播间,直播间进入开播的状态;
- 2.观众进入直播间后,在直播间内与主播进行互动;
- 3.最后就是主播对直播间进行关播,标识着直播间生命周期的结束状态。
直播间画像维表-实时
实时画像维表的建设。上图中「红色」的字体为实时画像维表的建设和应用过程。
直播间画像实时数据流转
- 1.当主播开播,直播间进行直播后,直播间产生了直播间画像信息,这时可以将画像信息实时的建设到直播间画像实时维表中。 并且可以同时建设生产侧的实时指标,利用建设好的「直播间画像实时维表 + 主播 & 观众画像离线维表」进行生产侧指标的维度填充;
- 2.当观众进入直播间后,与主播进行互动,产生一系列的消费行为,随即可以建设消费侧的实时指标,利用建设的「直播间画像实时维表 + 主播 & 观众画像离线维表」进行消费侧指标的维度填充;
- 3.当主播对直播间进行关播的时候,从直播间画像实时维表中就可以对该直播间的画像进行删除。
组件选型
通过上文的分析,可以了解到直播间画像实时维表建设的要求如下:
- 实时画像:首先需要支持实时建设,实时访问;
- 实时画像:建设的数据都为实时指标,即要求低延迟的请求响应时间;
- 公共画像:需要支撑多个大流量生产消费实时任务的访问请求,即提供高 QPS 画像数据服务;
- 公共画像:高稳定性。
因此组件选型就自然落在了高速缓存的范畴中,我们最后经过方案对比之后,选择了 redis 作为我们的实时维表的存储引擎。
使用了 redis 中的 hash 作为维表存储结构,其中直播间画像维度存储设计如下图。
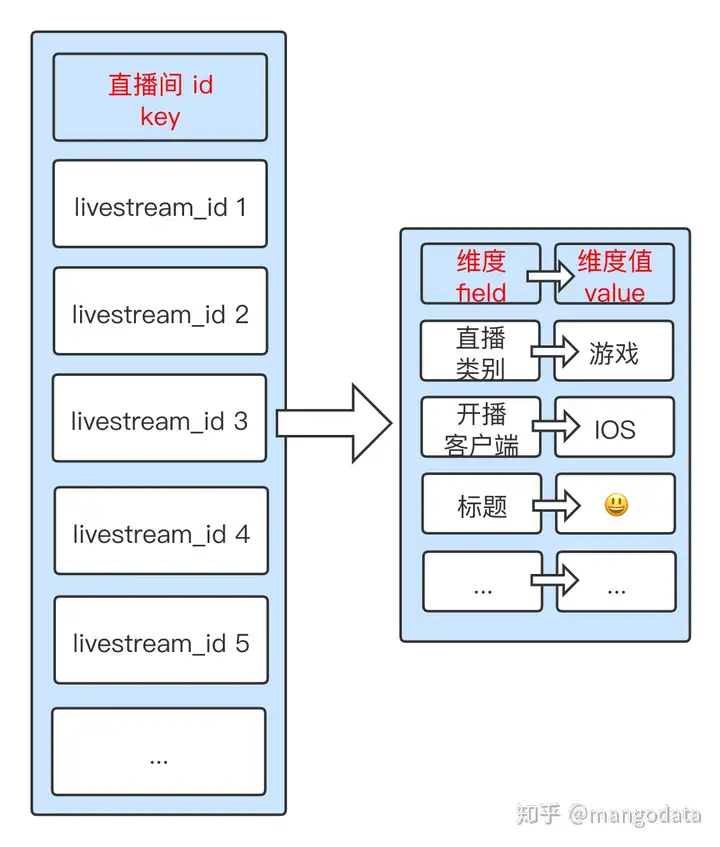
flink 实时维表建设代码示例
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
public static void main(String[] args) throws Exception {
final StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
DataStream<byte[]> source = SourceFactory.getSourceDataStream();
source.process(new ProcessFunction<byte[], String>() {
@Override
public void processElement(byte[] bytes, Context context, Collector<String> collector) throws Exception {
CommonModel c = CommonModel.parseFrom(bytes);
// 开播
if (c.isStartLiveStream()) {
RedisConfig
.get()
.hmset(c.getLiveStreamId()
, ImmutableMap.<String, String>builder()
.put("type", c.getType())
.put("client", c.getClient())
.put("title", c.getTitle())
.put("address", c.getAddress())
.build()
);
RedisConfig
.get()
.expire(c.getLiveStreamId(), 30 * 24 * 60 * 60);
} else if (c.isEndLiveStream()) {
// 关播
RedisConfig
.get()
.expire(c.getLiveStreamId(), 2 * 24 * 60 * 60);
}
}
});
env.execute();
}
@Data
public static class CommonModel {
private String liveStreamId; // 直播间 id
private String type; // 直播间类型
private String client; // 开播客户端
private String title; // 直播间标题
private String address; // 直播间开播地址
public static CommonModel parseFrom(byte[] bytes) {
// 逻辑根据业务逻辑判定
return null;
}
public boolean isStartLiveStream() {
// 逻辑根据业务逻辑判定
return false;
}
public boolean isEndLiveStream() {
// 逻辑根据业务逻辑判定
return false;
}
}
}
主播 & 观众用户画像维表-离线
离线画像维表的建设。主要包含主播和观众的用户画像,性别,年龄等信息。如下图「蓝色」的字体为离线画像维表的应用过程。
主播 & 观众画像数据流转
在产出直播间生产侧、消费侧实时数据时,使用主播 & 观众画像进行了画像维度填充。
存储组件
其中离线画像维表的存储组件选型与实时相同,同为 redis,画像信息存储方式也是使用 redis hash 结构进行存储。
以 t + 1 的方式进行画像数据建设并进行数据同步,将建设好的全量主播和观众用户画像同步到 redis 高速缓存当中。
总结
本文衔接上文,主要介绍直播间实时维表的建设过程。提出几个建设的问题,以这几个问题出发,引出了一下三小节。
第一节简单介绍了实时 & 离线公共画像维表的概念。
第二节从数据应用场景的角度出发,介绍了为什么需要建设实时的公共画像维表。
第三节主要介绍了实时画像维表的建设过程以及详细的技术方案。
最后一节对本文进行了总结。
