phoenix简介
我们在之前得文章中已经学习了thrift 以及使用 thrift 对hbase进行访问。
hadoop组件—面向列的开源数据库(三)—hbase的接口thrift简介和安装
hadoop组件—面向列的开源数据库(五)–java–SpringMVC查询hbase
使用过程中 可以感受到 这种访问方式 是 精确到 行列的,操作比较繁琐,如果是进行复杂的运算统计会很麻烦。
phoenix是一款 组件 可以让 我们使用 sql语句对hbase进行 操作。
如果熟悉sql语句的话,我们就能 很方便的对hbase进行 比较复杂的查询统计操作了。
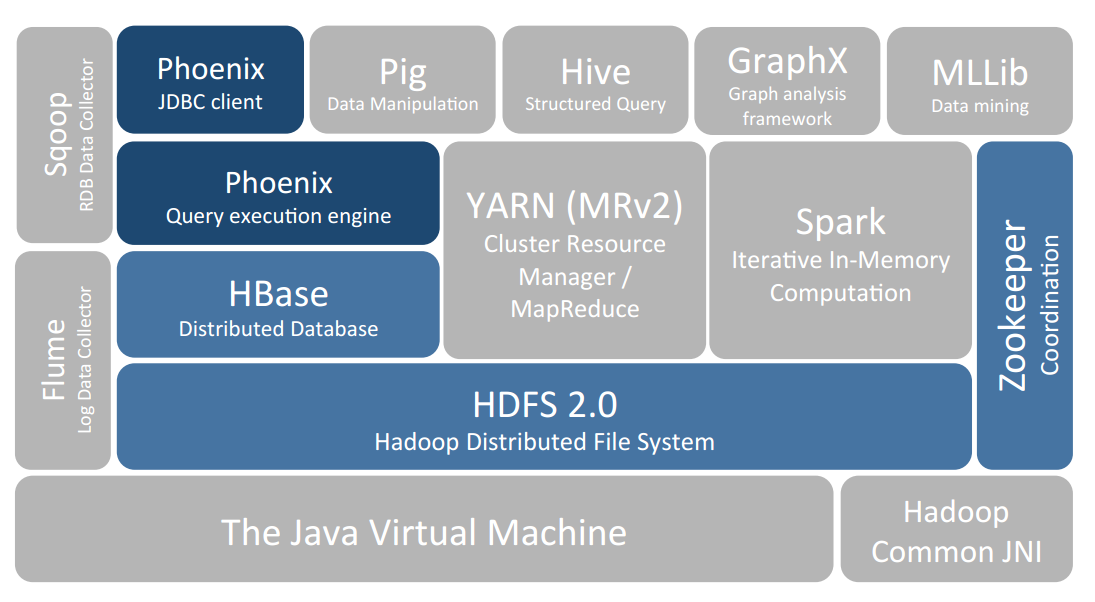
Phoenix最早是saleforce的一个开源项目,后来成为Apache基金的顶级项目。
如上图所示,Apache Phoenix是构建在HBase之上的关系型数据库层,作为内嵌的客户端JDBC驱动用以对HBase中的数据进行低延迟访问。
Apache Phoenix会将用户编写的sql查询编译为一系列的scan操作,最终产生通用的JDBC结果集返回给客户端。
Phoenix会记录SQL语句的版本,作为每次查询的快照,因此Phoenix的每次查询都能采取最优的查询顺序。
小范围的查询在毫秒级响应,千万数据的话响应速度为秒级。
Phoenix通过以下方式使我们可以少写代码,并且性能比我们自己写代码更好:
1、将SQL编译成原生的HBase scans。
2、确定scan关键字的最佳开始和结束
3、让scan并行执行
4、根据WHERE查询条件使用服务端过滤器处理
5、使用协同处理器进行聚合查询
除此之外,Phoenix还做了一些有趣的增强功能来更多地优化性能
实现了二级索引来提升非主键字段查询的性能。
相关链接参考
官网
wiki主页(文档很详细)
快速开始指南
phoenix+hbase 性能和 Hive以及Impala的对比
官方实时性能测试结果
Phoenix(HBase SQL)核心功能原理及应用场景介绍
安装phoenix
安装过程参考官网installation链接
安装好hadoop,hbase集群
安装好 zk 集群,hadoop 集群,hbase 集群。
我这里使用的是 CDH安装的hadoop集群 自带的hbase。
下载安装包
在官网中找到Download页面
注意版本的对应,选择合适自己环境的包
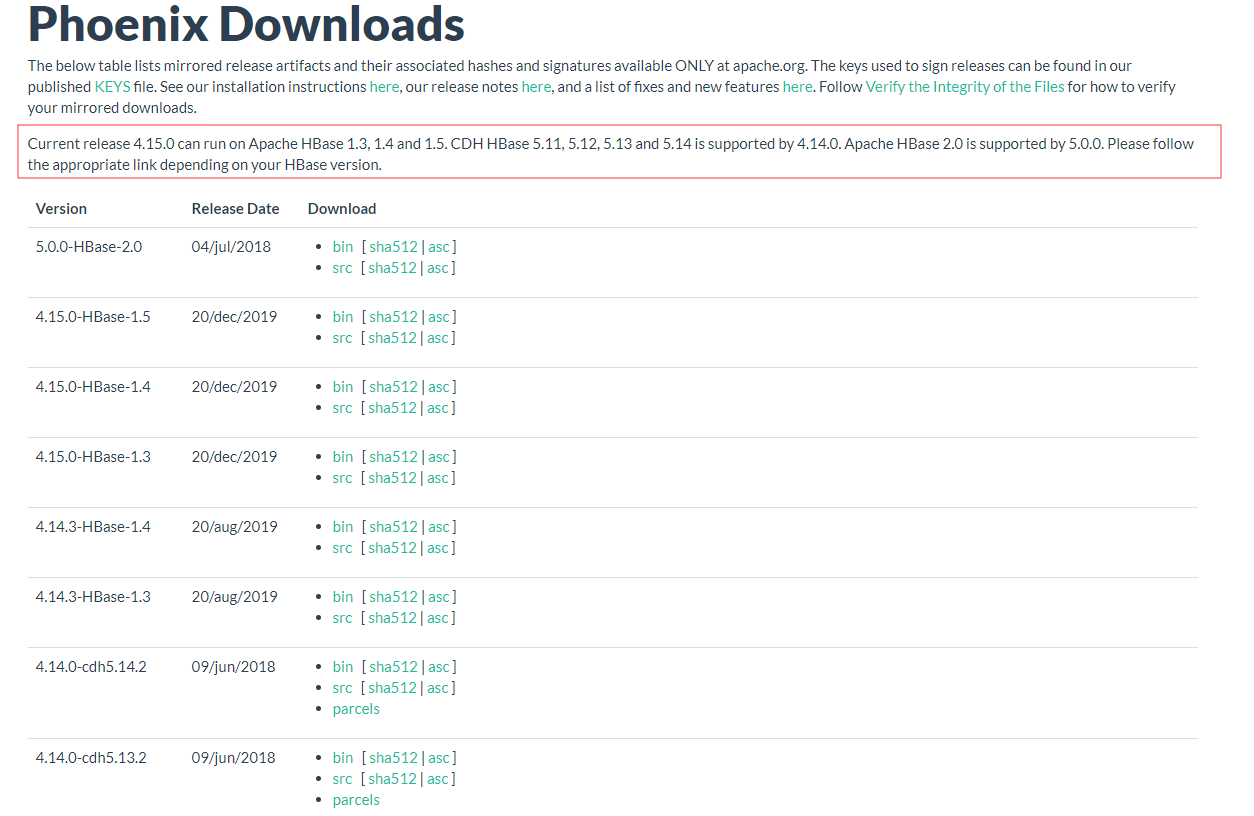
例如 我的环境是 CDH 5.13,则可以使用 4.14以上的版本。
点击bin
跳转到想要界面后可以选择不同来源的 路径进行下载,下的包都是同一个。
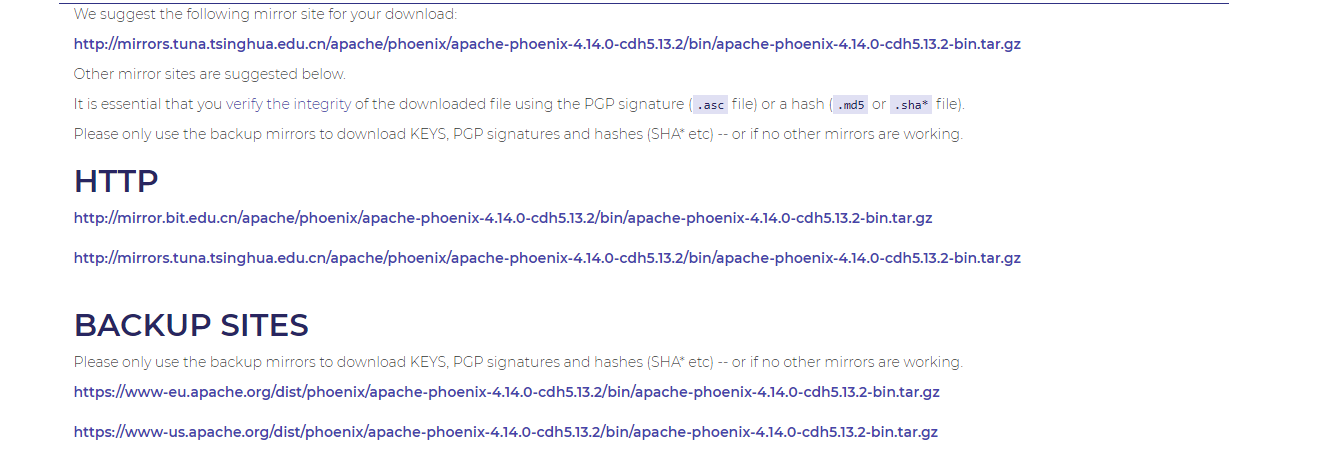
我这里下载到的包名为 apache-phoenix-4.14.0-cdh5.13.2-bin.tar.gz
上传部署
将apache-phoenix-4.14.0-cdh5.13.2-bin.tar.gz上传到服务器解压到/usr/local路径中,
重命名为phoenix-4.14.0
【PHOENIX_HOME】为【/usr/local/phoenix-4.14.0】
使用命令:
2
3
4
5
6
7
8
9
2sudo tar -zxvf apache-phoenix-4.14.0-cdh5.13.2-bin.tar.gz -C /usr/local
3
4#重命名
5cd /usr/local
6sudo mv apache-phoenix-4.14.0-cdh5.13.2-bin phoenix-4.14.0
7
8
9
如图所示

根据不同的版本,需要 使用的包也不同。
普通版本—将phoenix目录下的phoenix-4.14.0-HBase-1.2-server.jar、
phoenix-core-4.14.0-HBase-1.2.jar拷贝到HBase集群的所有regionserver节点的lib目录下
CDH版本–将phoenix目录下的phoenix-4.14.0-cdh5.13.2-server.jar拷贝到HBase集群的所有regionserver节点hbase的lib目录下
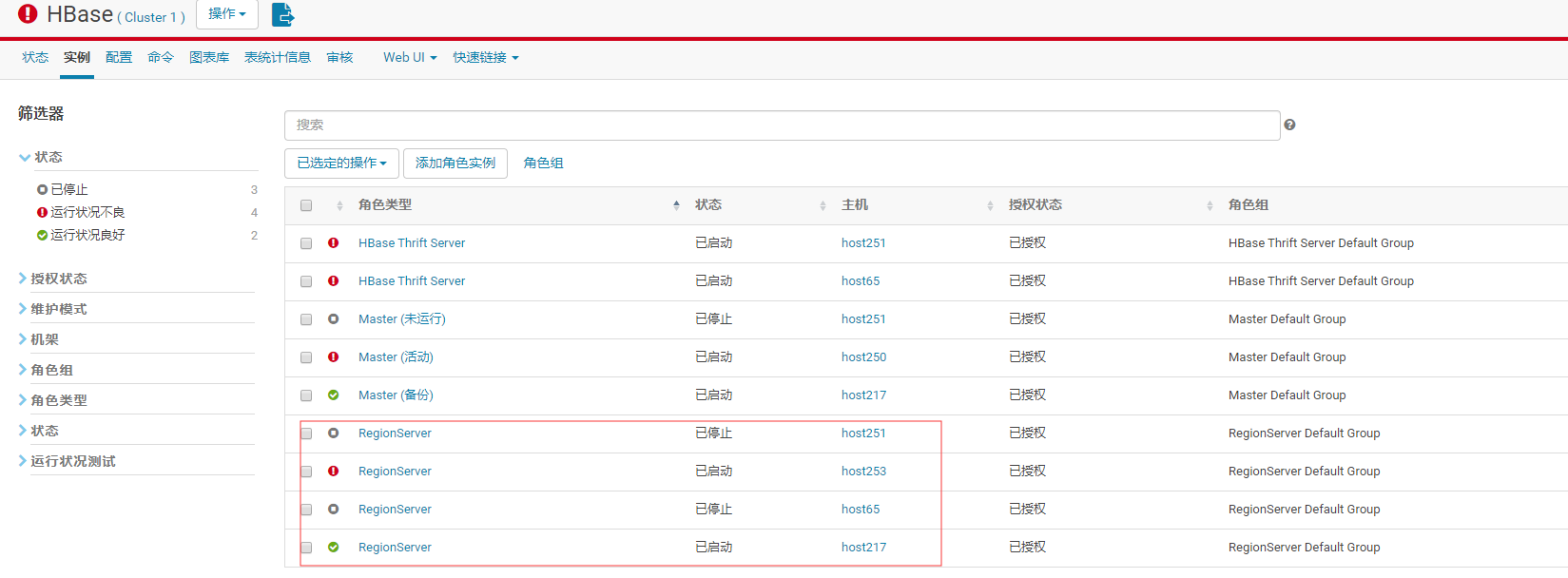
如上图,我需要放置再 host251,host253,host65,host217四台服务器hbase的lib目录中。
hbase的lib目录 需要 明确, CDH版本的目录一般在 /opt/cloudera/parcels/CDH/lib/hbase/lib/
CDH的目录如下图:
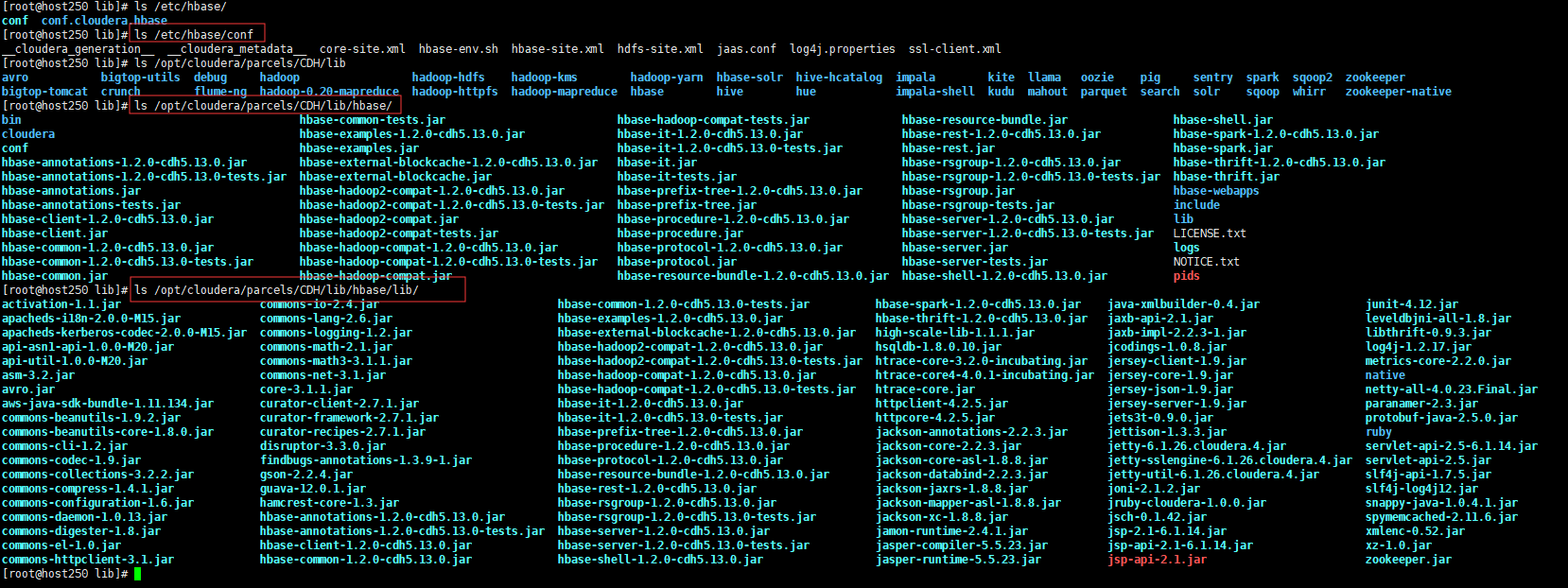
可以参考文章 :
hadoop基础—-hadoop实战(十一)—–hadoop管理工具—CDH的目录结构了解
其他版本的hbase需要自己找一下。
使用命令如下:
2
3
4
5
6
7
2/var/lib/hbase
3/var/lib/alternatives/hbase
4/var/log/hbase
5/opt/cloudera/parcels/CDH/lib/hbase/lib/
6
7
明确目录后使用命令把phoenix-4.14.0-cdh5.13.2-server.jar拷贝到hbase的lib目录下
2
3
2
3
注意每一台regionserver节点服务器 都需要执行同样的操作,保证hbase的lib目录下有phoenix的对应包。
配置启动
将hbase的配置文件hbase-site.xml、core-site.xml 、hdfs-site.xml放到/usr/local/phoenix-4.14.0/bin目录下,替换phoenix原来的配置文件。
具体路径还是需要自己查找明确一下。
使用命令如下:
2
3
4
5
2[root@host253 lib]# find / -name core-site.xml
3[root@host253 lib]# find / -name hdfs-site.xml
4
5
CDH版本的目录一般在 /etc/hbase/conf
CDH的目录如下图:

可以参考文章 :
hadoop基础—-hadoop实战(十一)—–hadoop管理工具—CDH的目录结构了解
使用命令复制到/usr/local/phoenix-4.14.0/bin目录下
2
3
4
5
2\cp -rf /etc/hbase/conf/core-site.xml /usr/local/phoenix-4.14.0/bin
3\cp -rf /etc/hbase/conf/hdfs-site.xml /usr/local/phoenix-4.14.0/bin
4
5
重启hbase集群,使Phoenix的jar包生效。
验证是否安装成功
在hadoop集群中任意 解压安装有 phoenix得服务器中,进入到安装得目录 /usr/local/phoenix-4.14.0/bin
2
3
2
3
在/usr/local/phoenix-4.14.0/bin下输入命令:
2
3
4
5
2或者
3./sqlline.py host217:2181
4
5
端口可以省略
2
3
4
5
2或者
3./sqlline.py host217
4
5
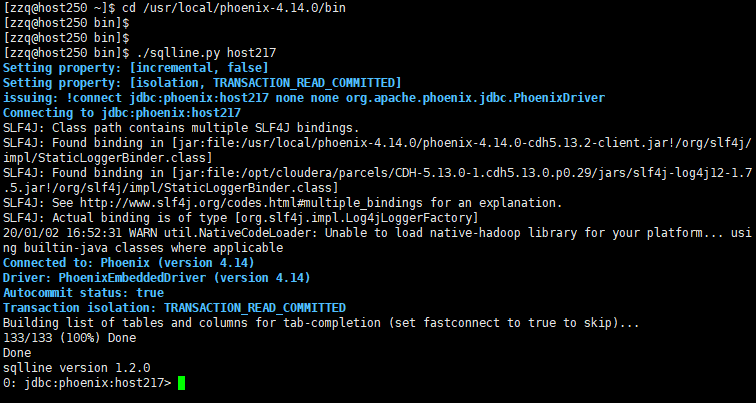
输入
2
3
2
3
查看都有哪些表。红框部分是用户建的表,其他为Phoenix系统表,系统表中维护了用户表的元数据信息。
本地安装好 Phoenix 之后,用 phoenix 的 !talblse 命令列出所有表,会发现 HBase 原有的表没有被列出来。而使用 Phoenix sql 的 CREATE 语句创建的一张新表,则可以通过 !tables 命令展示出来。
这是因为 Phoenix 无法自动识别 HBase 中原有的表,所以需要将 HBase 中已有的做映射,才能够被 Phoenix 识别并操作。说白了就是要需要告诉 Phoenix 一声 xx 表的 xx 列是主键,xx 列的数据类型。
详情可以参考 下篇文章
hadoop组件—面向列的开源数据库(七)–phoenix查询hbase
退出 phoenix ,输入
2
3
2
3

可能遇到的问题
参考 Phoenix 构建cdh版hbase遇到的坑
特性和更新
Transactions (beta) 事务
该特性还处于beta版,并非正式版。通过集成Tephra,Phoenix可以支持ACID特性。Tephra也是Apache的一个项目,是事务管理器,它在像HBase这样的分布式数据存储上提供全局一致事务。HBase本身在行层次和区层次上支持强一致性,Tephra额外提供交叉区、交叉表的一致性来支持可扩展性。
要想让Phoenix支持事务特性,需要以下步骤:
配置客户端hbase-site.xml
2
3
4
5
6
2 <name>phoenix.transactions.enabled</name>
3 <value>true</value>
4</property>
5
6
配置服务端hbase-site.xml
2
3
4
5
6
7
8
9
10
11
12
2 <name>data.tx.snapshot.dir</name>
3 <value>/tmp/tephra/snapshots</value>
4</property>
5
6<property>
7 <name>data.tx.timeout</name>
8 <value>60</value>
9 <description> set the transaction timeout (time after which open transactions become invalid) to a reasonable value.</description>
10</property>
11
12
配置$HBASE_HOME并启动Tephra
2
3
4
2
3
4
通过以上配置,Phoenix已经支持了事务特性,但创建表的时候默认还是不支持的。如果想创建一个表支持事务特性,需要显示声明,如下:
2
3
2
3
就是在建表语句末尾增加 TRANSACTIONAL=true。
原本存在的表也可以更改成支持事务的,需要注意的是,事务表无法改回非事务的,因此更改的时候要小心。一旦改成事务的,就改不回去了。
2
3
2
3
User-defined functions(UDFs) 用户定义函数
Phoenix从4.4.0版本开始支持用户自定义函数。
用户可以创建临时或永久的用户自定义函数。这些用户自定义函数可以像内置的create、upsert、delete一样被调用。临时函数是针对特定的会话或连接,对其他会话或连接不可见。永久函数的元信息会被存储在一张叫做SYSTEM.FUNCTION的系统表中,对任何会话或连接均可见。
配置hive-site.xml
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
2<property>
3 <name>phoenix.functions.allowUserDefinedFunctions</name>
4 <value>true</value>
5</property>
6<property>
7 <name>fs.hdfs.impl</name>
8 <value>org.apache.hadoop.hdfs.DistributedFileSystem</value>
9</property>
10<property>
11 <name>hbase.rootdir</name>
12 <value>${hbase.tmp.dir}/hbase</value>
13 <description>The directory shared by region servers and into
14 which HBase persists. The URL should be 'fully-qualified'
15 to include the filesystem scheme. For example, to specify the
16 HDFS directory '/hbase' where the HDFS instance's namenode is
17 running at namenode.example.org on port 9000, set this value to:
18 hdfs://namenode.example.org:9000/hbase. By default, we write
19 to whatever ${hbase.tmp.dir} is set too -- usually /tmp --
20 so change this configuration or else all data will be lost on
21 machine restart.</description>
22</property>
23<property>
24 <name>hbase.dynamic.jars.dir</name>
25 <value>${hbase.rootdir}/lib</value>
26 <description>
27 The directory from which the custom udf jars can be loaded
28 dynamically by the phoenix client/region server without the need to restart. However,
29 an already loaded udf class would not be un-loaded. See
30 HBASE-1936 for more details.
31 </description>
32</property>
33
34
后两个配置需要跟hbse服务端的配置一致。
以上配置完后,在JDBC连接时还需要执行以下语句:
2
3
4
5
2props.setProperty("phoenix.functions.allowUserDefinedFunctions", "true");
3Connection conn = DriverManager.getConnection("jdbc:phoenix:localhost", props);
4
5
以下是可选的配置,用于动态类加载的时候把jar包从hdfs拷贝到本地文件系统
2
3
4
5
6
7
8
2 <name>hbase.local.dir</name>
3 <value>${hbase.tmp.dir}/local/</value>
4 <description>Directory on the local filesystem to be used
5 as a local storage.</description>
6</property>
7
8
Secondary Indexing 二级索引
在HBase中,只有一个单一的按照字典序排序的rowKey索引,当使用rowKey来进行数据查询的时候速度较快,但是如果不使用rowKey来查询的话就会使用filter来对全表进行扫描,很大程度上降低了检索性能。
而Phoenix提供了二级索引技术来应对这种使用rowKey之外的条件进行检索的场景。
Covered Indexes
只需要通过索引就能返回所要查询的数据,所以索引的列必须包含所需查询的列(SELECT的列和WHRER的列)
Functional Indexes
从Phoeinx4.3以上就支持函数索引,其索引不局限于列,可以合适任意的表达式来创建索引,当在查询时用到了这些表达式时就直接返回表达式结果
Global Indexes
Global indexing适用于多读少写的业务场景。
使用Global indexing的话在写数据的时候会消耗大量开销,因为所有对数据表的更新操作(DELETE, UPSERT VALUES and UPSERT SELECT),会引起索引表的更新,而索引表是分布在不同的数据节点上的,跨节点的数据传输带来了较大的性能消耗。在读数据的时候Phoenix会选择索引表来降低查询消耗的时间。在默认情况下如果想查询的字段不是索引字段的话索引表不会被使用,也就是说不会带来查询速度的提升。
Local Indexes
Local indexing适用于写操作频繁的场景。
与Global indexing一样,Phoenix会自动判定在进行查询的时候是否使用索引。使用Local indexing时,索引数据和数据表的数据是存放在相同的服务器中的避免了在写操作的时候往不同服务器的索引表中写索引带来的额外开销。使用Local indexing的时候即使查询的字段不是索引字段索引表也会被使用,这会带来查询速度的提升,这点跟Global indexing不同。一个数据表的所有索引数据都存储在一个单一的独立的可共享的表中。
Statistics Collection 统计信息收集
UPDATE STATISTICS可以更新某张表的统计信息,以提高查询性能
Row timestamp 时间戳
从4.6版本开始,Phoenix提供了一种将HBase原生的row timestamp映射到Phoenix列的方法。这样有利于充分利用HBase提供的针对存储文件的时间范围的各种优化,以及Phoenix内置的各种查询优化。
Paged Queries 分页查询
Phoenix支持分页查询:
Row Value Constructors (RVC)
OFFSET with limit
Salted Tables 散步表
如果row key是自动增长的,那么HBase的顺序写会导致region server产生数据热点的问题,Phoenix的Salted Tables技术可以解决region server的热点问题
Skip Scan 跳跃扫描
可以在范围扫描的时候提高性能
Views 视图
标准的SQL视图语法现在在Phoenix上也支持了。这使得能在同一张底层HBase物理表上创建多个虚拟表。
Multi tenancy 多租户
通过指定不同的租户连接实现数据访问的隔离
Dynamic Columns 动态列
Phoenix 1.2, specifying columns dynamically is now supported by allowing column definitions to included in parenthesis after the table in the FROM clause on a SELECT statement. Although this is not standard SQL, it is useful to surface this type of functionality to leverage the late binding ability of HBase.
Bulk CSV Data Loading 大量CSV数据加载
加载CSV数据到Phoenix表有两种方式:1. 通过psql命令以单线程的方式加载,数据量少的情况下适用。 2. 基于MapReduce的bulk load工具,适用于数据量大的情况
Query Server 查询服务器
Phoenix4.4引入的一个单独的服务器来提供thin客户端的连接
Tracing 追踪
从4.1版本开始Phoenix增加这个特性来追踪每条查询的踪迹,这使用户能够看到每一条查询或插入操作背后从客户端到HBase端执行的每一步。
Metrics 指标
Phoenix提供各种各样的指标使我们能够知道Phoenix客户端在执行不同SQL语句的时候其内部发生了什么。这些指标在客户端JVM中通过两种方式来收集:
Request level metrics – collected at an individual SQL statement level
Global metrics – collected at the client JVM level
版本更新-最新实现的特性
Phoenix优缺点与其他框架的对比
Phoenix 的团队用了一句话概括 Phoenix:“We put the SQL back in NoSQL”
这边说的 NoSQL 专指 HBase ,意思是可以用 SQL 语句来查询 Hbase
实现SQL 语句查询 Hbase的 组件还有很多,比如 Hive 和 Impala。
但是 Hive 和 Impala 还可以查询文本文件。
Phoenix 的特点是它只能查 Hbase,别的类型都不支持!
但是也因为这种专一的态度,让 Phoenix 在 Hbase 上查询的性能超过了 Hive 和 Impala!
优点
1:命令行和java客户端使用都很简单。尤其是java客户端直接面向JDBC接口编程,封装且优化了Hbase很多细节。
2:在单表操作上性能比Hive Handler好很多(但是Hive handler也有可能会升级加入斜处理器相关聚合等特性)
3:支持多列的二级索引,列数不限。其中可变索引时列数越多写入速度越慢,不可变索引不影响写入速度(参考:https://github.com/forcedotcom/phoenix/wiki/Secondary-Indexing\#mutable-indexing)。
4:对Top-N查询速度远超Hive(参考:https://github.com/forcedotcom/phoenix/wiki/Performance\#top-n)
5:提供对rowkey分桶的特性,可以实现数据在各个region的均匀分布(参考:https://github.com/forcedotcom/phoenix/wiki/Performance\#salting)
6:低侵入性,基本对原Hbase的使用没什么影响
7:提供的函数基本都能cover住绝大多数需求了
8:与Hive不同的是,Phoenix的sql语句更接近标准sql规范。
缺点
1:Phoenix创建的表Hbase可以识别并使用,但是使用Hbase创建的表,Phoenix不能识别,因为Phoenix对每张表都有其相应的元数据信息。需要做映射。
2:3.0之前的版本不支持多表join操作。 参考http://phoenix.apache.org/joins.html
扩展其他类似的组件
sql for hbase(Phoenix、Impala、Drill): http://www.orzota.com/sql-for-hbase/
SQL on Hadoop的最新进展及7项相关技术分享:http://www.csdn.net/article/2013-10-18/2817214-big-data-hadoop
对比华为HBase二级索引
缺点:华为二级索引需要在建表时指定列(及不支持动态修改),同时华为代码对Hbase本身侵入性太大(比如balancer要用华为的),难以升级维护。
优点:但是索引建好后,在对Hbase的scan、Puts、Deletes操作时使用Hbase原生代码(无需任何改动)即可享受到索引的效果。也不需要指定使用哪个索引,它会自己使用最优索引。
也就是说如果加上华为索引,Hive-hbase-handler无需改动即可使用二级索引。但是phoenix目前只支持通过phoenix sql方式使用二级索引。
性能对比:暂未测试,估计差不太多
综合看移植phoenix比移植华为更靠谱,phoenix侵入性小,功能更强大,且升级维护方面也比华为要靠谱。但是移植phoenix难度也相对比较大。
但是如果只是想短期起效果,可以尝试下华为索引。
淘宝开源项目Lealone
是一个可用于HBase的分布式SQL引擎,主要功能就是能用SQL方式(JDBC)查询Hbase,避免了HBase使用的繁琐操作。相对与Phoenix的功能弱多了。
支持高性能的分布式事务
使用一个非常新颖的基于局部时间戳的多版本冲突与有效性检测的分布式事务模型
是对H2关系数据库SQL引擎的改进和扩展
HBase建的表Lealone只能读;Lealone建的表Lealone可以读写。
基于Solr的HBase多条件查询
ApacheSolr 是一个开源的搜索服务器,Solr 使用 Java 语言开发,主要基于 HTTP 和Apache Lucene 实现。
原理:基于Solr的HBase多条件查询原理很简单,将HBase表中涉及条件过滤的字段和rowkey在Solr中建立索引,通过Solr的多条件查询快速获得符合过滤条件的rowkey值,拿到这些rowkey之后在HBASE中通过指定rowkey进行查询。
缺点:
1:ApacheSolr本身并不是专为HBase设计的。需要专门针对ApacheSolr写Hbase的相关应用,比如HBase写数据时同步更新索引的过程需要我们自己写协处理器。
2:ApacheSolr本身是一个WebService服务,需要额外维护一个或多个ApacheSolr服务器。
参考链接
https://www.xuebuyuan.com/3268524.html
1:基于Solr的HBase多条件查询http://www.cnblogs.com/chenz/articles/3229997.html
2:http://blog.csdn.net/chenjia3615349/article/details/8112289\#t40
中文wiki:https://github.com/codefollower/Lealone
