故障发生时在故障发生时,最重要的是快速恢复故障。
而快速恢复故障的前提是快速定位故障源。因为在很多分布式系统中,一旦发生故障就会出现“多米诺骨牌效应”。也就是说,系统会随着一个故障开始一点一点地波及到其它系统,而且这个过程可能会很快。
一旦很多系统都在报警,要想快速定位到故障源就不是一件简单的事了。
在亚马逊内部,每个开发团队至少都会有一位 oncall 的工程师。在 oncall 的时候,工程师要专心处理线上故障,轮换周期为每人一周。
一旦发生比较大的故障,比如,S1 全部不可用,或 S2 某功能不可用,而且找不到替代方案,那么这个故障就会被提交到一个工单系统里。几乎所有相关团队 oncall 的工程师都会被叫到线上处理问题。
眼疾手快 悬崖勒马 故障发生时 做紧急处理
亚马逊能够快速定位故障源,被影响的团队做处理 控制故障的范围不被扩散
出现故障时,最重要的不是 debug 故障,而是尽可能地减少故障的影响范围, 并尽可能快地修复问题。
恢复系统的手段
- 重启限流:解决可用性问题
- 回滚:解决新代码 BUG
- 降级:停止服务故障公告 不把事态扩大
- 紧急更新:需要有自动化系统 进行 自动化测试 自动化发布
运维团队通常只能处理一些基础设施方面的问题,或是非功能性的问题。对于一些功能性的问题,运维团队是完全 没有能力处理的,只能通过相应的联系人,把相关的开发人员叫到线上来看。
居安思危 未雨绸缪 做故障前的准备
- 以用户功能为索引的服务和资源的全视图 为各个服务指定关键指标 一套运维流程和工具 应急方案 有导航仪 有章法 就不会混乱
- 设置故障等级
- 全站不可用
- 功能不可用 不可替代
- 功能不可用 可替代
- 非功能故障
- 故障演练 见得多了 驾轻就熟
- 灰度发布系统 或 A/B 测试
反躬自省 进行 故障复盘
解决一个故障可以通过 技术和管理两个方面入手
技术方面 亚马逊COE
亚马逊会编写 COE(Correction of Errors)文档
- 故障处理过程 log
- 故障原因分析
- Ask 5 Whys 至少问五个为什么
- 整改计划:举一反三 根本上解决所有问题
管理方面 阿里故障责任人机制
- 阿里会将向上操作改成两个人完成 一人操作一人检查 增加审批环节
- 阿里会 编写一个新的系统 监控原来不好的系统
- 阿里也会 通过灰度发布减少故障
不认同 阿里 惩罚故障责任人 的机制
- 做的越多错的越多 只会让人更保守
- 惩罚责任人对 解决故障没有帮助
故障整改方法
慢 SQL 的故障复盘
- 为什么从故障发生到系统报警花了 27 分钟?为什么只发邮件,没有短信?
- 为什么花了 15 分钟,开发的同学才知道是慢 SQL 问题?
- 为什么监控系统没有监测到 Nginx 499 错误,以及 Nginx 的 upstream_response_time 和 request_time?
- 为什么在一开始按 DDoS 处理?
- 为什么要重启数据库?
- 为什么这个故障之前没有发生?因为以前没有上首页,最近上的。
- 为什么上首页时没有做性能测试?
- 为什么使用这个高危的 SQL 语句?
- 上线过程中为什么没有 DBA 评审?
提出问题的逻辑
第一,优化故障获知和故障定位的时间。
- 从故障发生到我们知道的时间是否可以优化得更短?
- 定位故障的时间是否可以更短?
- 有哪些地方可以做到自动化?
第二,优化故障的处理方式。
- 故障处理时的判断和章法是否科学,是否正确?
- 故障处理时的信息是否全透明?
- 故障处理时人员是否安排得当? 第三,优化开发过程中的问题。
- Code Review 和测试中的问题和优化点。
- 软件架构和设计是否可以更好?
- 对于技术欠债或是相关的隐患问题是否被记录下来,是否有风险计划? 第四,优化团队能力。
- 如何提高团队的技术能力?
- 如何让团队有严谨的工程意识?
识微见几 药到病除 根除问题的本质
技术问题 隐藏着工程能力的问题 工程能力的问题背后是 公司管理的问题 公司管理问题 隐藏着 公司文化 创始人的问题
三条原则
- 举一反三解决当下故障。 赢得更多时间
- 简化负责不合理的技术架构、流程、组织 无法在复杂环境解决根本的问题
- 全面改善优化系统 组织 根本上 改善调整整体结构
要想本质解决问题 就需要 大扫除 但要想做到简化 非常难 在烂摊子中解决问题 几乎不可能
第二个版本:思路一样,描述会更细
——————————————————–
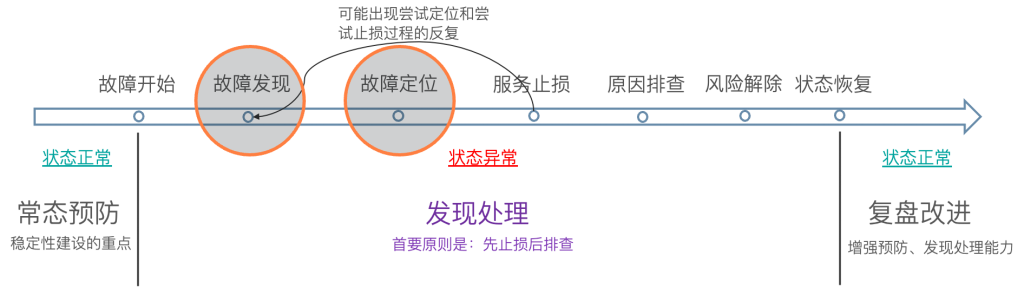
生产环境故障总共可分为三个阶段,故障发生前,故障发生时,故障发生后。
故障发生前
为了能够在故障发生时,有条不紊的处理线上故障,做到事乱而人不乱的目的。可以提前做以下准备。
- 以用户功能为索引的服务和资源的全视图。
- 前端
- 用户操作
- 后台服务
- 服务与服务之间的调用关系
- 中间件
- 服务涉及到的中间件
- 硬件
- 服务以及中间件 所涉及到的硬件资源
- 网络
- 整体部署网络拓扑图
- 前端
- 为地图中的各个服务制定关键指标,以及一套运维流程和工具,包括应急方案。
- 服务指标
- 以用户功能为索引,为每个用户功能的服务都制定一个服务故障的检测、处理和恢复手册,以及相关的检测、查错或是恢复的运维工具。
- 中间件指标
- 检查其健康运行状态
- 硬件指标
- 链接数等
- 检查其健康运行状态
- 应急方案
- 常见故障处理
- 服务不可用处理
- 服务回滚处理
- 服务指标
- 设定故障的等级:制定故障等级,主要是为了确定该故障要牵扯进多大规模的人员来处理。故障级别越高,牵扯进来的人就越多,参与进来的管理层级别也就越高。
- 亚马逊定级
- 全站不可用
- 某功能不可用,且无替代方案
- 某功能不可用,但有替代方案
- 非功能性故障,或是用户不关心的故障
- 其他定级
- 通用型:包含受影响用户数、受影响商家数、客诉增量、资金损失等通用指标。通用型故障场景在业务线型故障场景未覆盖情况下兜底。
- 业务型:基于用户视角共同定义。
- 亚马逊定级
- 故障演练:故障是需要演练的。因为故障并不会时常发生,但我们又需要不断提升处理故障的能力,所以需要经常演练。
- 比如:
- Chaos Monkey
- 混沌工程
- 比如:
- 灰度发布/ AB Test
故障发生时
在故障发生时,最重要的是快速恢复故障。而快速恢复故障的前提是快速定位故障源。因为在很多分布式系统中,一旦发生故障就会出现“多米诺骨牌效应”。也就是说,系统会随着一个故障开始一点一点地波及到其它系统,而且这个过程可能会很快。一旦很多系统都在报警,要想快速定位到故障源就不是一件简单的事了。
这里 郝哥建议使用亚马逊故障处理方式,每个开发团队至少都会有一位 oncall 的工程师。在 oncall 的时候,工程师要专心处理线上故障,轮换周期为每人一周。自查自己的服务,如果自己的服务没有问题,那么就可以在旁边待命(standby),以备在需要时进行配合。
故障源团队通常会有以下几种手段来恢复系统。
- 重启和限流。重启和限流主要解决的是可用性的问题,不是功能性的问题。重启还好说,但是限流这个事就需要相关的流控中间件了。
- 回滚操作。回滚操作一般来说是解决新代码的 bug,把代码回滚到之前的版本是快速的方式。
- 降级操作。并不是所有的代码变更都是能够回滚的,如果无法回滚,就需要降级功能了。也就是说,需要挂一个停止服务的故障公告,主要是不要把事态扩大。
- 紧急更新。紧急更新是常用的手段,这个需要强大的自动化系统,尤其是自动化测试和自动化发布系统。假如你要紧急更新 1000 多台服务器,没有一个强大的自动化发布系统是很难做到的。
在处理故障中,一定要做好服务版本控制,便于回滚,同时也建议与 运维人员一起整理或者更新应急故障手册。
故障发生后
在故障排除后,如何做故障复盘及整改优化则更为重要。
无论是哪个公司 相对的复盘点如下:
- 故障处理的整个过程。就像一个 log 一样,需要详细地记录几点几分干了什么事,把故障从发生到解决的所有细节过程都记录下来。
- 故障原因分析。需要说明故障的原因和分析报告。
- Ask 5 Whys。需要反思并反问至少 5 个为什么,并为这些“为什么”找到答案。
- 故障后续整改计划。需要针对上述的“Ask 5 Whys”说明后续如何举一反三地从根本上解决所有的问题。
复盘最终的目的就是要找到以下几点优化方案
- 优化故障获知和故障定位的时间
- 从故障发生到我们知道的时间是否可以优化得更短?
- 定位故障的时间是否可以更短?
- 有哪些地方可以做到自动化?
- 优化故障的处理方式
- 故障处理时的判断和章法是否科学,是否正确?
- 故障处理时的信息是否全透明?
- 故障处理时人员是否安排得当?
- 优化开发过程中的问题
- Code Review 和测试中的问题和优化点
- 软件架构和设计是否可以更好?
- 对于技术欠债或是相关的隐患问题是否被记录下来,是否有风险计划?
- 优化团队能力
- 如何提高团队的技术能力?
- 如何让团队有严谨的工程意识?
计算公式: 全年可用性目标 =(365*24*60 – 全年故障时长配额)/ (365*24*60) * 100% = 99.**% 全年故障时长配额 = 365*24*60 * (1- 全年可用性目标)= x分钟
