在前面有一篇文章,我介绍seleinum自动化,如何通过pipeline方式去串联,其中使用了两个变量,一个浏览器类型一个是测试服务器地址。这两个变量,我是在让用户在构建的之前,需要勾选或者填写的。这看起来没有什么问题,那么如果一个项目真的需要很多个参数化变量去构建,那么我们直接这样写肯定不行,本篇就来讨论如下如何优化这个问题。
1.问题场景
之前的场景是这样,相关文章https://blog.csdn.net/u011541946/article/details/85549417
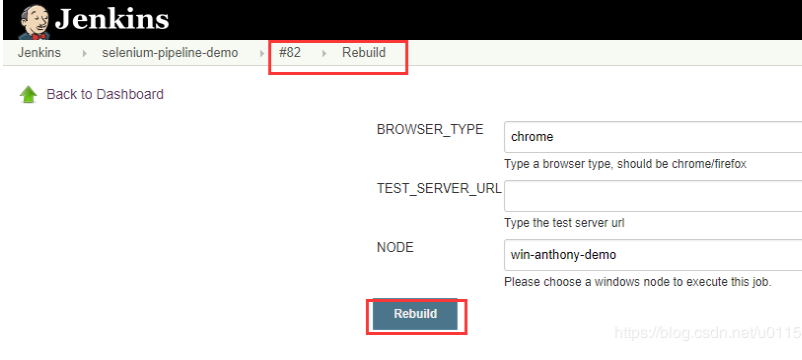
这里有三个变量就有三个文本框或者其他前端元素,需要让用户去选择或者输入条件值,才能进行构建。那么真实的项目,可能远远不止3个变量,如果有十个或者十几个呢。那么是不是也需要一个很长篇幅的构建页面。这种我在想项目中也遇到过,可以实现构建需求,但是不美观,也不友好,很多参数都暴露出来。
2.解决方案
假如有十来个可变的参数,其中有几个是可以提取出来,没必要暴露出来,那么我们就可以把其他参数放入到一个json文件。这个json文件,可以存放在linux服务器上。原则上,每一个有权限去构建这个job的人,需要去linux服务器上创建自己的名称的文件夹,这个文件夹下然后放一个json文件。
我pipeline脚本中,初始化的stage需要读取这个json文件,然后拿到每一个变量的值,赋值给pipeline中的变量,这些变量都是全局变量,任何stage中都可以用到这些全局变量。
这么说,可能不是很明白,没关系,接下来,我一步一步图形和代码来讲明白我的思路。
3.准备一个json文件
重点在于,拿到项目的全部可能需要的参数,如何去做一个json文件。这个文件的路径在服务器哪里没有关系,可以是本地,也可以是远程共享服务地址,这种共享,运维人员很容易提供这种路径。
假如说我们ProjectA需要用到一下几个参数,这里我就不去勉强举例十个或者十个以上的参数在json文件里。随便来几个,能表示这个意思就行。例如,用户名称name, 年龄age,手机phoneNumber, 家庭地址addr, 邮箱地址:xxx@xxx.com, 性别gender, 是否已婚,默认是否。
好了就上面这七个参数,六个可以是字符串变量,是否已婚是布尔型变量。我们可以写成一个扁平的json格式,只有一层,没有json嵌套。
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
2
3 "NAME" : "Lucy",
4
5 "AGE" : "18",
6
7 "PHONE_NUMBER" : "13912345678",
8
9 "ADDRESS" : "Haidian Beijing",
10
11 "EMAIL" : "lucy@demo.com",
12
13 "GENDER" : "male",
14
15 "IS_MARRY" : false
16
17}
18
例如在Jenkins虚拟机里的目录下/tmp/Anthony/test.json写入上面的内容,保存,这个路径下面会用到。
4.修改job成参数化构建
由于我们上面有一个参数是需要提供json文件的路径,所以,我们这里在UI勾选参数化构建,并添加一个字符串参数叫INPUT_JSON.
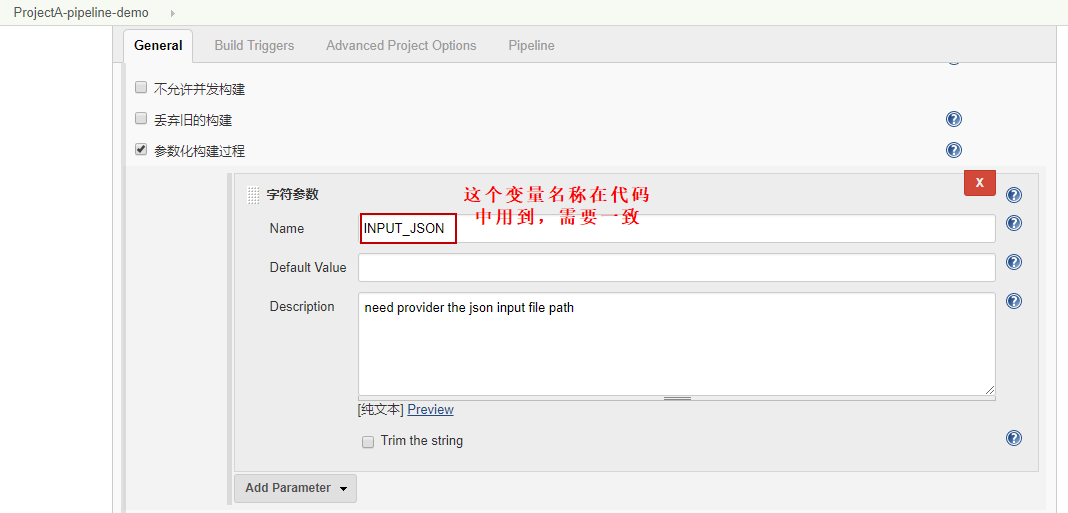
保存之后,立即构建菜单变成参数化构建。
5.写debug代码
上面json文件我们做好了,接下来,我们来写stage.groovy中代码,先来读取json文件,然后打印里面属性NAME的值。如果能打印出一个,那么其他变量也能打印出来。
相关代码如下
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
2
3
4pipeline{
5
6 agent any
7 stages{
8 stage("Hello Pipeline") {
9 steps {
10 script {
11 println "Hello Pipeline!"
12 println env.JOB_NAME
13 println env.BUILD_NUMBER
14 }
15 }
16 }
17
18 stage("Init paramters in json") {
19 steps {
20 script {
21
22 println "read josn input file"
23 json_file = INPUT_JSON? INPUT_JSON.trim() : ""
24 prop = readJSON file : json_file
25 name = prop.NAME? prop.NAME.trim() : ""
26 println "Name:" + name
27 }
28 }
29 }
30 }
31
32}
33
6.测试和调试
在参数化构建,填入之前准备json文件路径:/tmp/anthony/test.json

点击构建,观察控制台日志。
如果提示报错,没有readJSON方法,说明你jenkins环境没有安装插件:Utility Steps, 去插件管理中搜索并安装这个。

7.打印全部参数的值
代码调整如下
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
2
3
4pipeline{
5
6 agent any
7 stages{
8 stage("Hello Pipeline") {
9 steps {
10 script {
11 println "Hello Pipeline!"
12 println env.JOB_NAME
13 println env.BUILD_NUMBER
14 }
15 }
16 }
17
18 stage("Init paramters in json") {
19 steps {
20 script {
21 println "read josn input file"
22 json_file = INPUT_JSON? INPUT_JSON.trim() : ""
23 prop = readJSON file : json_file
24 name = prop.NAME? prop.NAME.trim() : ""
25 println "Name:" + name
26 age = prop.AGE? prop.AGE.trim() : ""
27 println "Age:" + age
28 phone = prop.PHONE_NUMBER? prop.PHONE_NUMBER.trim() : ""
29 println "Phone:" + phone
30 address = prop.ADDRESS? prop.ADDRESS.trim() : ""
31 println "Address:" + address
32 email = prop.EMAIL? prop.EMAIL.trim() : ""
33 println "Email:" + email
34 gender = prop.GENDER? prop.GENDER.trim() : ""
35 println "Gender:" + gender
36 is_marry = prop.IS_MARRY? prop.IS_MARRY.trim() : false
37 println "is_marry:" + is_marry
38 }
39 }
40 }
41 }
42
43}
44
45
46
测试通过的完整日志
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
2Obtained src/Jenkinsfile/projectA-stages.groovy from git https://github.com/Anthonyliu86/pipeline-skills-demo.git
3Running in Durability level: MAX_SURVIVABILITY
4[Pipeline] Start of Pipeline
5[Pipeline] node
6Running on Jenkins in /var/lib/jenkins/workspace/ProjectA-pipeline-demo
7[Pipeline] {
8[Pipeline] stage
9[Pipeline] { (Declarative: Checkout SCM)
10[Pipeline] checkout
11using credential 03214975-2168-4795-981a-ddd935f62a76
12 > git rev-parse --is-inside-work-tree # timeout=10
13Fetching changes from the remote Git repository
14 > git config remote.origin.url https://github.com/Anthonyliu86/pipeline-skills-demo.git # timeout=10
15Fetching upstream changes from https://github.com/Anthonyliu86/pipeline-skills-demo.git
16 > git --version # timeout=10
17using GIT_ASKPASS to set credentials
18 > git fetch --tags --progress https://github.com/Anthonyliu86/pipeline-skills-demo.git +refs/heads/*:refs/remotes/origin/*
19 > git rev-parse refs/remotes/origin/master^{commit} # timeout=10
20 > git rev-parse refs/remotes/origin/origin/master^{commit} # timeout=10
21Checking out Revision 1c1c552166f9854ee1e16c402de034fbc8517134 (refs/remotes/origin/master)
22 > git config core.sparsecheckout # timeout=10
23 > git checkout -f 1c1c552166f9854ee1e16c402de034fbc8517134
24Commit message: "fix"
25 > git rev-list --no-walk 5b08f84e9f15c2d159aecd136a3a2b072431f3b7 # timeout=10
26[Pipeline] }
27[Pipeline] // stage
28[Pipeline] withEnv
29[Pipeline] {
30[Pipeline] stage
31[Pipeline] { (Hello Pipeline)
32[Pipeline] script
33[Pipeline] {
34[Pipeline] echo
35Hello Pipeline!
36[Pipeline] echo
37ProjectA-pipeline-demo
38[Pipeline] echo
399
40[Pipeline] }
41[Pipeline] // script
42[Pipeline] }
43[Pipeline] // stage
44[Pipeline] stage
45[Pipeline] { (Init paramters in json)
46[Pipeline] script
47[Pipeline] {
48[Pipeline] echo
49read josn input file
50[Pipeline] readJSON
51[Pipeline] echo
52Name:Lucy
53[Pipeline] echo
54Age:18
55[Pipeline] echo
56Phone:13912345678
57[Pipeline] echo
58Address:Haidian Beijing
59[Pipeline] echo
60Email:lucy@demo.com
61[Pipeline] echo
62Gender:male
63[Pipeline] echo
64is_marry:false
65[Pipeline] }
66[Pipeline] // script
67[Pipeline] }
68[Pipeline] // stage
69[Pipeline] }
70[Pipeline] // withEnv
71[Pipeline] }
72[Pipeline] // node
73[Pipeline] End of Pipeline
74Finished: SUCCESS
75
上面多个参数,用JSON方法来处理介绍到这里。其中引出了一些新的代码,例如上面的三元运算符以及局部变量和全局变量的概念,readJSON方法在前面博客完整学习pipeline工具插件的时候介绍过了。这篇,我们有了参数,拿到了多个参数,下面文章,我们详细来介绍下三元运算符在groovvy中的运用和全局变量和局部变量的以及使用map来传参的学习。
